| |
| |
| Nvidia présente Denver Processeurs Publié le Mercredi 13 Août 2014 par Guillaume Louel URL: /news/13846/nvidia-presente-denver.html Après une annonce quelque peu confuse au CES d'un Tegra K1 en deux versions, Nvidia a profité de la conférence Hotchips pour donner quelques petits détails sur son architecture processeur Denver.  Pour rappel, Denver est une implémentation customisée de l'architecture 64 bits ARMv8. Il s'agira des premiers cores ARM custom proposés par Nvidia qui utilisait jusqu'ici des curs génériques ARM (Cortex-A9 dans Tegra 3, Cortex-A15 dans Tegra 4, etc ) dans ses puces Tegra. Il s'agit de la seconde architecture ARMv8 custom présentée pour l'instant, la première étant celle d'Apple (Cyclone) utilisée dans les ses SoC A7. En pratique, une version spéciale des Tegra K1 sera disponible avec deux curs Denver (contre quatre curs Cortex-A15 pour la version 32 bits du Tegra K1). La présentation de Nvidia ne rentre pas forcément dans un très haut niveau de détails, mais l'on y trouve quelques grandes lignes intéressantes. D'abord sur les unités d'exécution : 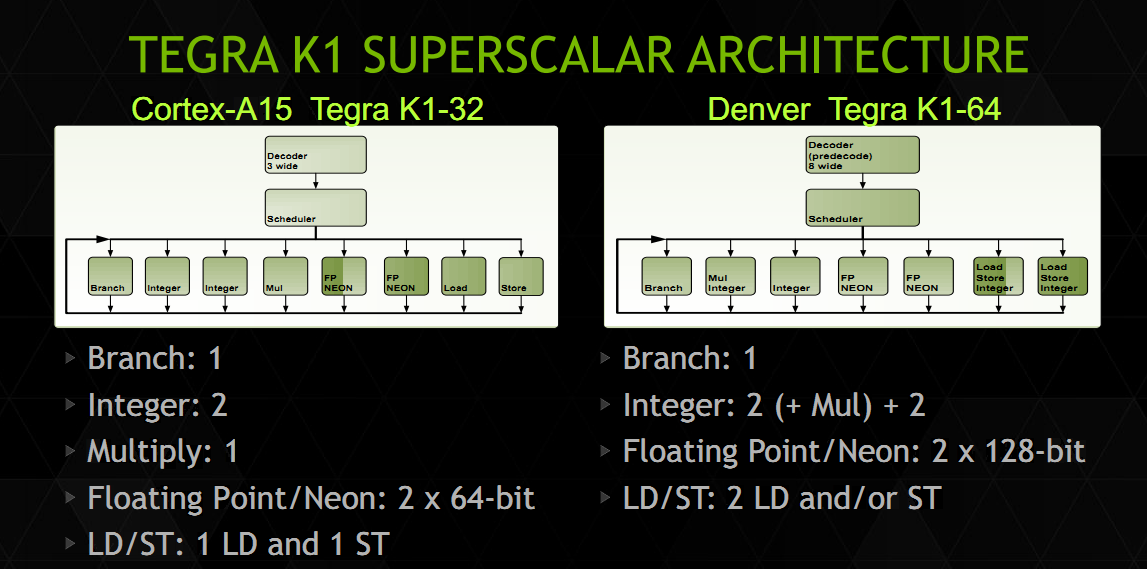 Nvidia présente ce slide qui met face à face les unités d'exécution d'un cur Cortex-A15 et d'un cur Denver. On retrouve certains changements liés à ARMv8 comme le passage des unités Neon/FP (les instructions SIMD d'ARM) de 64 à 128 bits, et d'autres plus intéressants. On retrouve sept ports qui incluent un plus grand nombre d'unités, par exemple au lieu d'un seul port pour les Load et les Stores, les deux ports sont capables d'effectuer les deux types d'opération, et aussi des instructions entières. Le détail le plus important concerne surement le décodeur qui indique une phase de « prédécodage ». De manière classique sur les Cortex-A, les instructions ARM sont décodés, réordonnées, (le principe de l'OoO, Out of Order), les registres sont renommés, puis les instructions sont dispatchées aux unités d'exécution. A l'inverse chez Intel, le jeu d'instruction x86 étant très large, les instructions x86 sont traduites en micro opérations - une sorte de jeu d'instruction réduit, interne aux unités d'exécutions avant de subir les mêmes opérations de changement d'ordre, renommage de registres et de dispatch. Le prédécodage laisse penser que Denver utilise lui aussi un jeu d'instruction interne différent. Plus surprenant, Denver pourrait être une architecture hardware in-order. C'est en tout cas ce que laisse penser la fonctionnalité la plus originale de Denver, ce que Nvidia appelle « Dynamic Code Optimization ». En pratique, il s'agit d'une couche logicielle qui fonctionne dans un espace mémoire (128 Mo) protégé, géré directement par le firmware et qui n'est pas accessible au système d'exploitation. Ce code logiciel fait tourner des threads cachés du reste du système dans ce que Nvidia appelle des « hidden time slices », on suppose qu'il s'agit d'un contexte dédié à l'utilisation de DCO. Que fait donc cet optimiseur ? 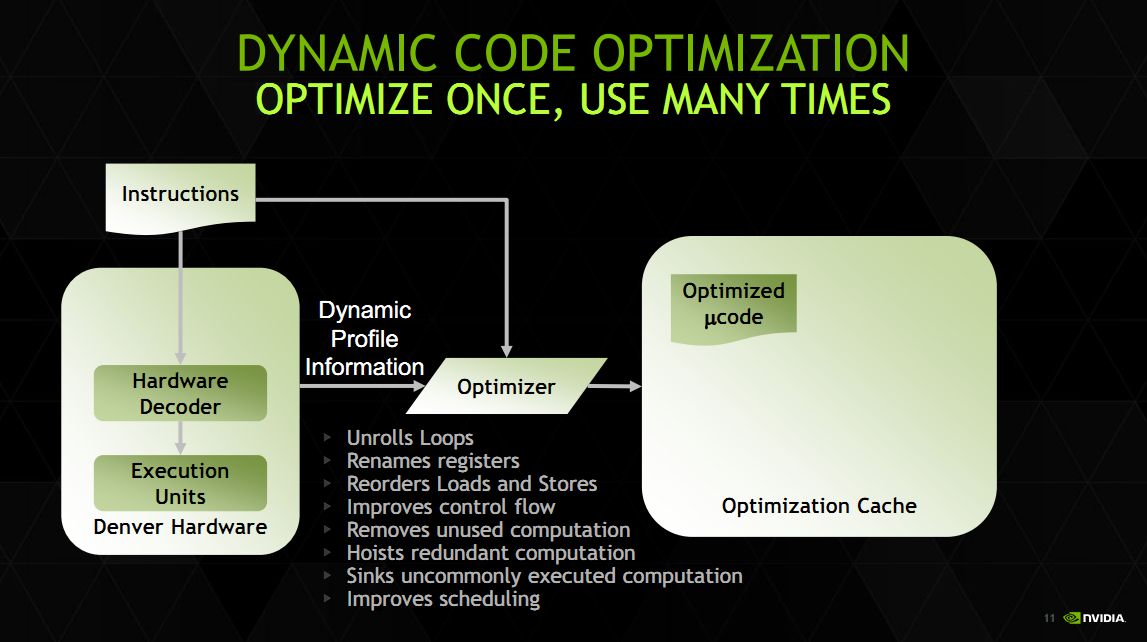 La liste des opérations ne trompe pas, on retrouve ici toutes les opérations effectuées par les frontend des processeurs Out of Order modernes, comme le réordonnancement d'instructions ou le renommage de registre. On trouve même quelques fonctionnalités un peu plus avancées que l'on a déjà vues chez Intel et AMD comme le dépliage de boucles. 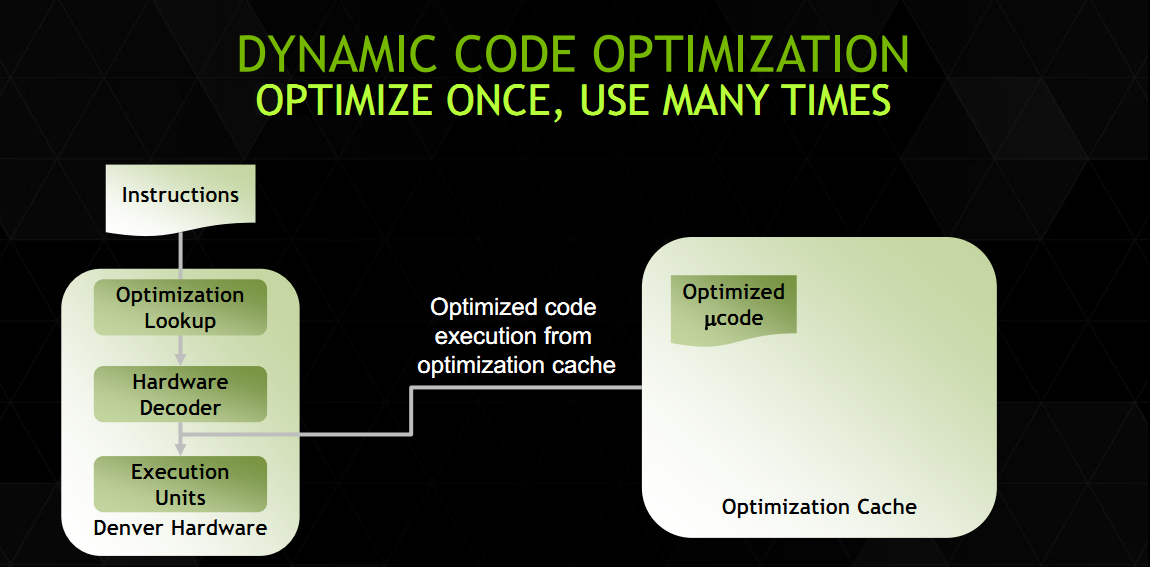 En pratique le fonctionnement est d'après les informations que nous avons - ainsi : le code ARM est décodé en micro instructions puis envoyé directement aux unités d'exécution. En parallèle, ce code est envoyé aux threads cachés DCO qui vont effectuer un décodage « OoO » optimisé du code ARM en micro instructions (l'optimisation est effectuée en profitant d'informations de profilage statique récupérées par l'exécution du code). Ce code est ensuite stocké dans le cache en mémoire principale de 128 Mo que nous évoquions plus tôt. La prochaine fois que ce segment de code se représentera, le code optimisé en micro instructions est récupéré du cache mémoire et exécuté directement à la place du code décodé en hardware. Pour résumer tout cela en une phrase, Denver implémente de manière logicielle l'OoO d'habitude implémentée de manière matérielle dans les autres processeurs. Si cela vous dit quelque chose, c'est probablement parce que ce type de design avait été utilisé par Transmeta pour ses Crusoe. Une différence notable avec les Crusoe est que Denver peut exécuter directement le code ARM via un décodeur matériel (de manière moins performante, et nous le supposons, in-order). En supprimant un frontend couteux en transistors, on peut sur le papier disposer d'une plus grande marge de transistors à placer ailleurs (unités d'exécution ou même GPU), ou réduire la consommation. A l'inverse, une architecture « in-order » n'est pas, lorsqu'elle est en fonctionnement, particulièrement efficace d'un point de vue énergétique lorsqu'elle doit attendre après des instructions mémoires. Reste que si ce genre d'architecture peut être très efficace dans des benchmarks arithmétiques, en pratique tout dépendra de la variété de code utilisée et de l'efficacité de cet « OoO » logiciel. DCO semble capable de travailler sur des blocs de taille variables pouvant aller jusqu'à 1000 micro opérations. Nvidia a ajouté un cache d'instruction de niveau 1 de 128 Ko qui peut contenir les blocs les plus utilisés, tandis que les autres seront stockés en mémoire (beaucoup plus lente) en attente d'être exécutés de nouveau. 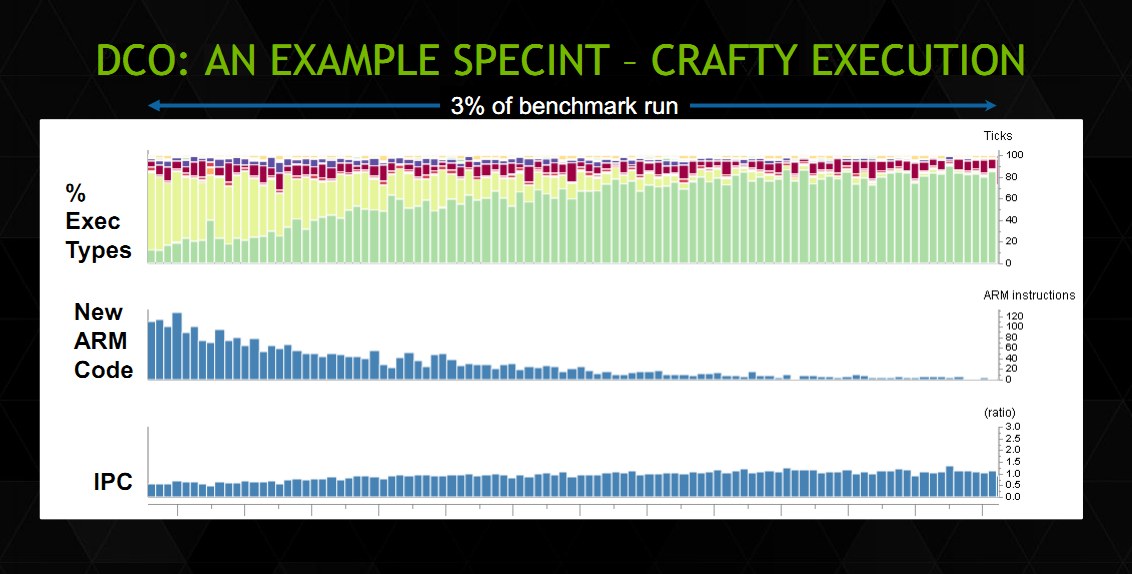 Nvidia donne un exemple du fonctionnement en pratique. Sur ce schéma, on peut voir en haut en vert le « type » d'exécutions qui ont lieu sur les curs Denver durant le début d'un benchmark SpecINT 2k. Malheureusement, il n'y a pas d'échelle de temps mais l'on note en vert les instructions optimisées, en vert pale les instructions décodées en hard, et en pourpre/violet les instructions exécutées par DCO. Leur nombre est non négligeable particulièrement en début de benchmark. La proportion d'instructions issues du décodeur matériel décroit au fur et à mesure, remplacées au fur et à mesure par des instructions « optimisées ». On peut voir l'augmentation de l'IPC au fur et à mesure en bas. L'architecture de Denver est pour le moins originale et les quelques détails donnés durant la conférence Hot Chips ne permettent pas vraiment de se faire une idée des performances réelles de la puce. Nvidia avance quelques benchmarks ou il place, dans des tests arithmétiques (et donc répétitifs, le cas le plus avantageux pour ce type d'architecture), Denver au niveau d'un Celeron Haswell 2955U (1.4 GHz, 15 watts) sans préciser le TDP ou la fréquence du Denver utilisé. Les performances dans un environnement réel ou cohabitent de multiples applications dont le code n'est pas forcément fait de traitements répétitifs dépendront de l'efficacité de cet OoO logiciel. La taille du cache d'instruction et sa rapidité pouvant devenir une ressource critique pour les performances. La disponibilité des K1 Denver n'a pas été précisée, indiquée simplement à « plus tard cette année » par le constructeur. Copyright © 1997-2026 HardWare.fr. Tous droits réservés. |