| |
| |
| Comprendre la mémoire HBM introduite par AMD Cartes Graphiques Publié le Jeudi 21 Mai 2015 par Damien Triolet URL: /focus/109/.html Alors que la sortie de son prochain GPU haut de gamme approche, AMD prépare le terrain et affute sa stratégie de communication en débutant par une présentation sur la mémoire HBM. L'occasion d'expliquer en détail en quoi consiste cette dernière qui, au-delà des GPU haut de gamme, va accompagner de plus en plus de processeurs de tous types à partir de 2016.  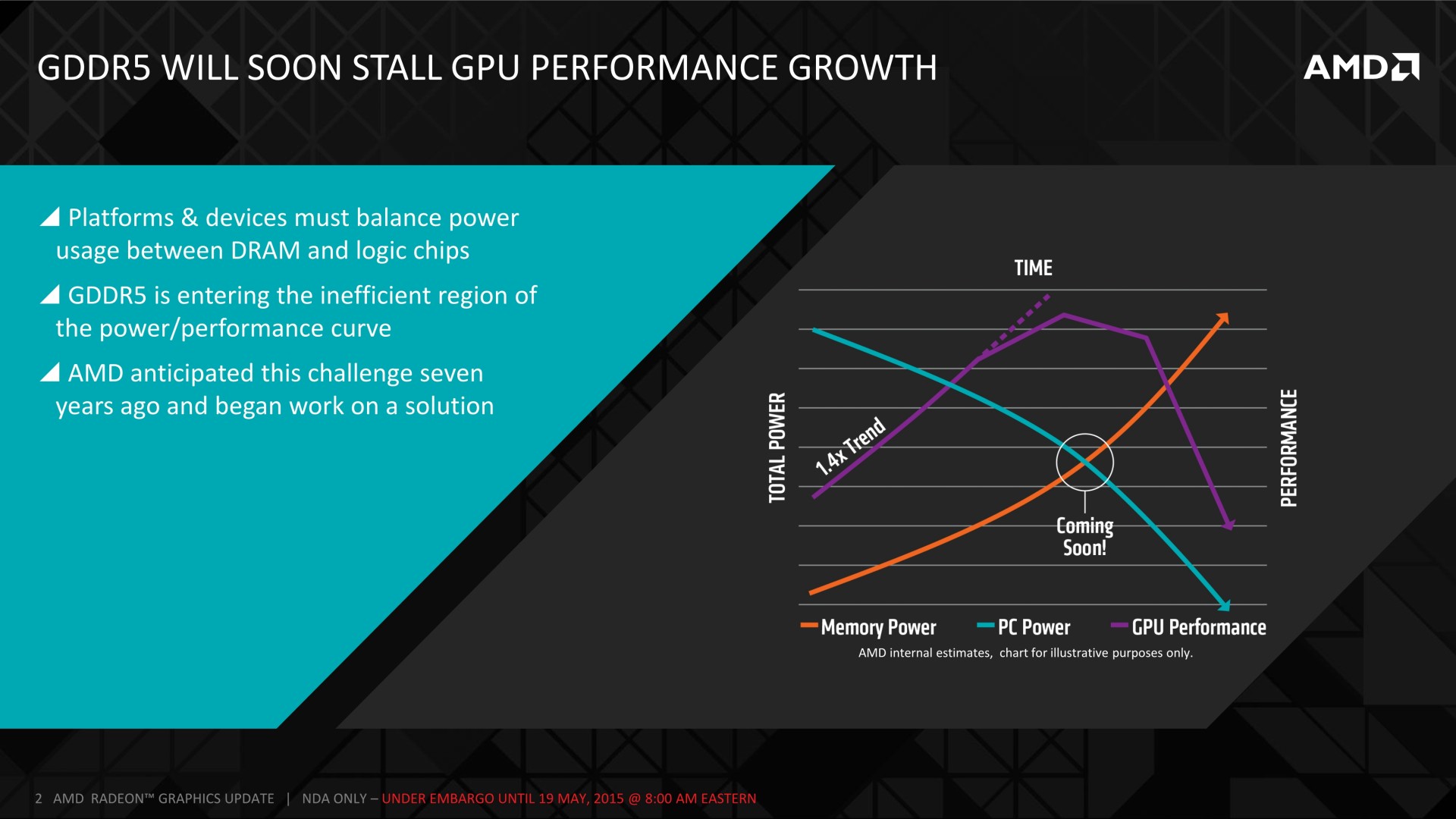  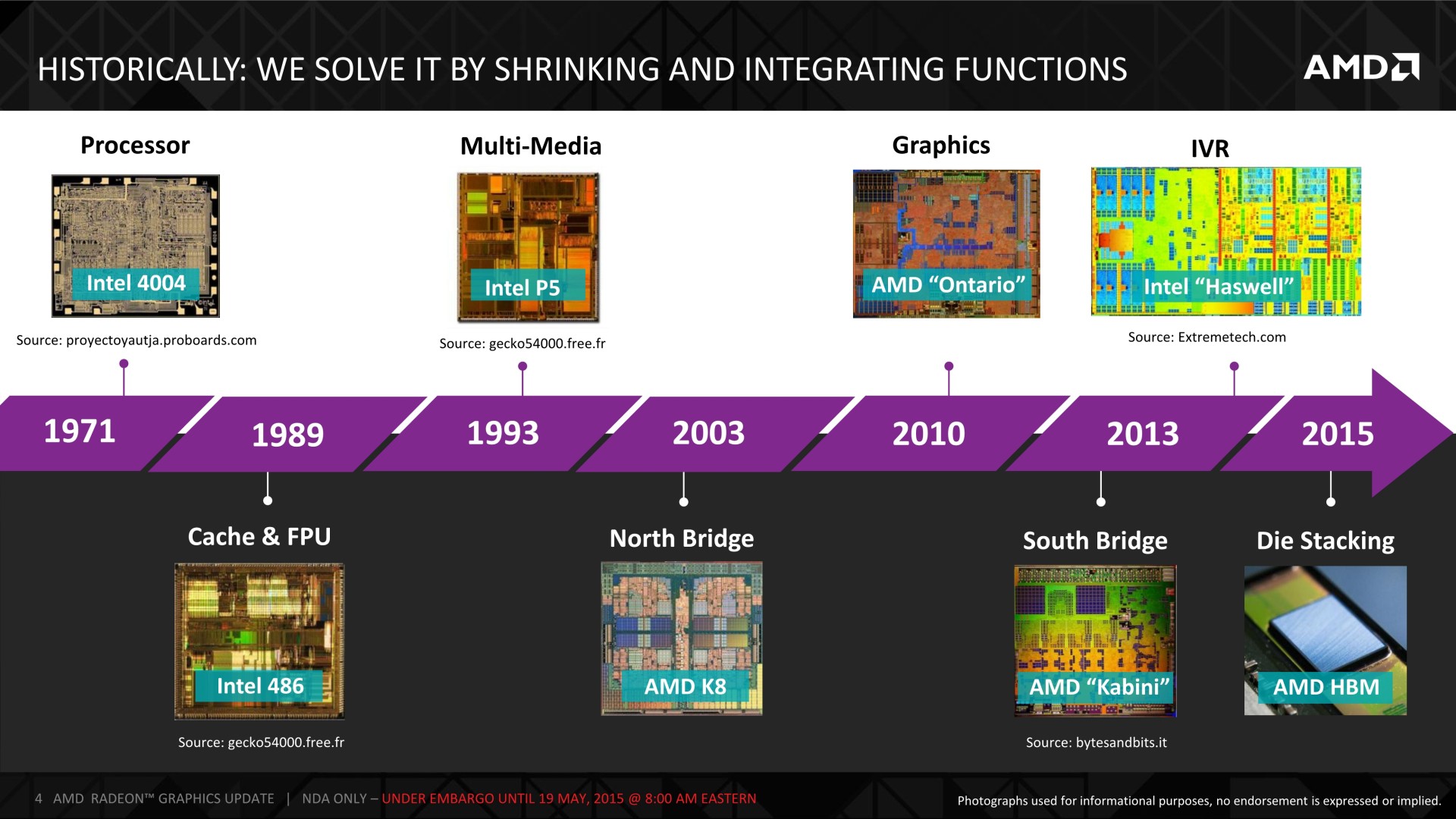   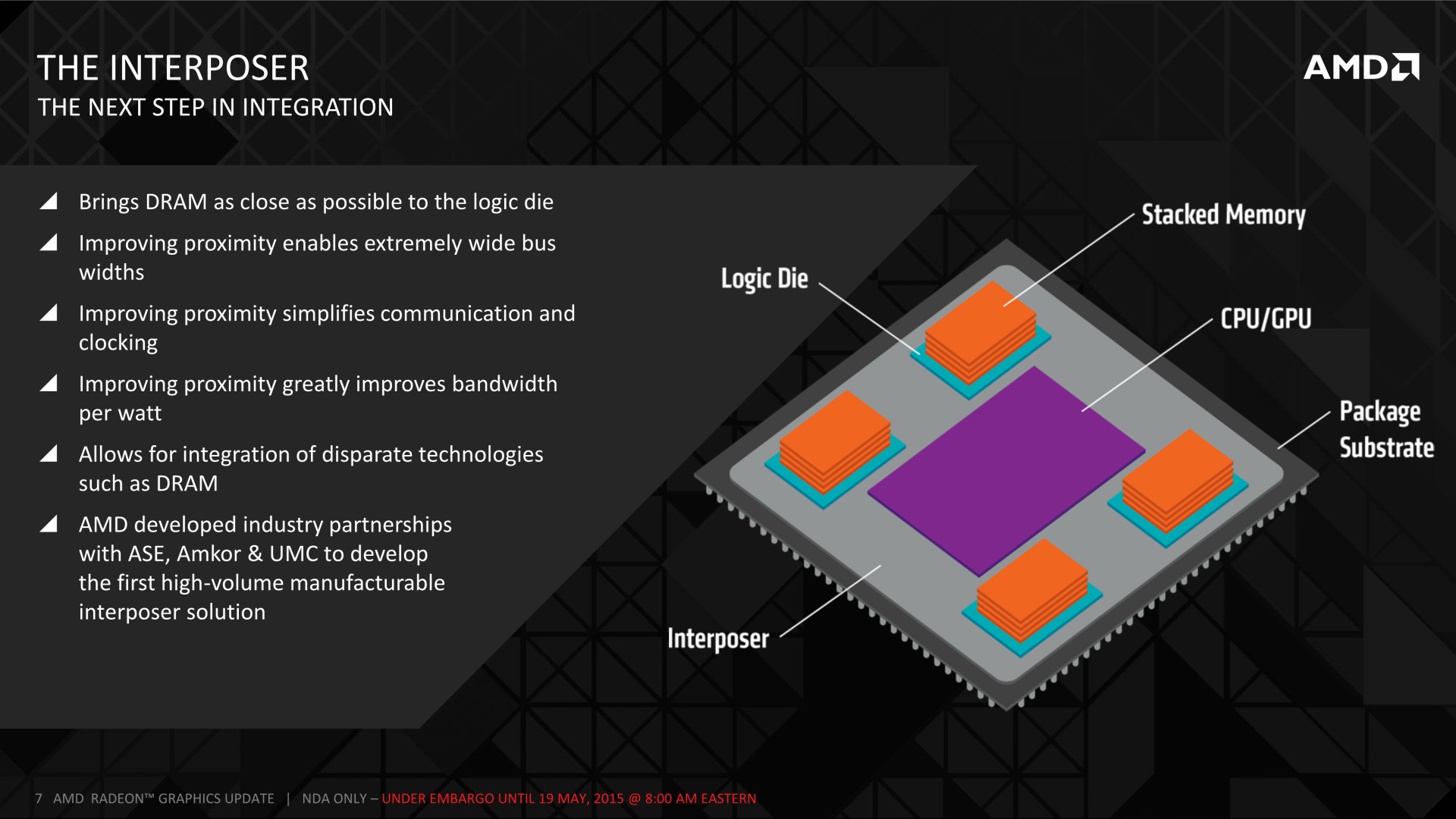   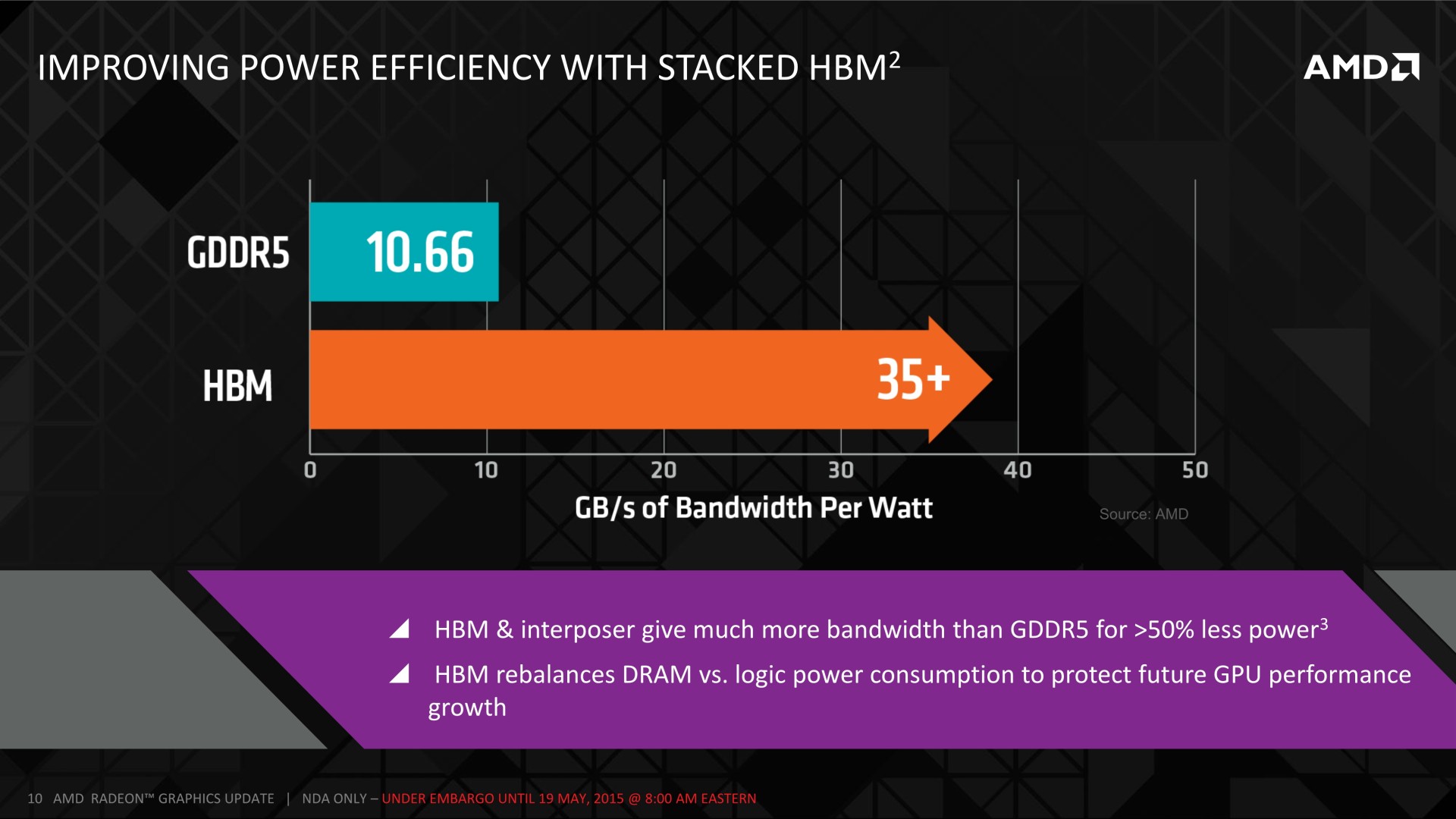 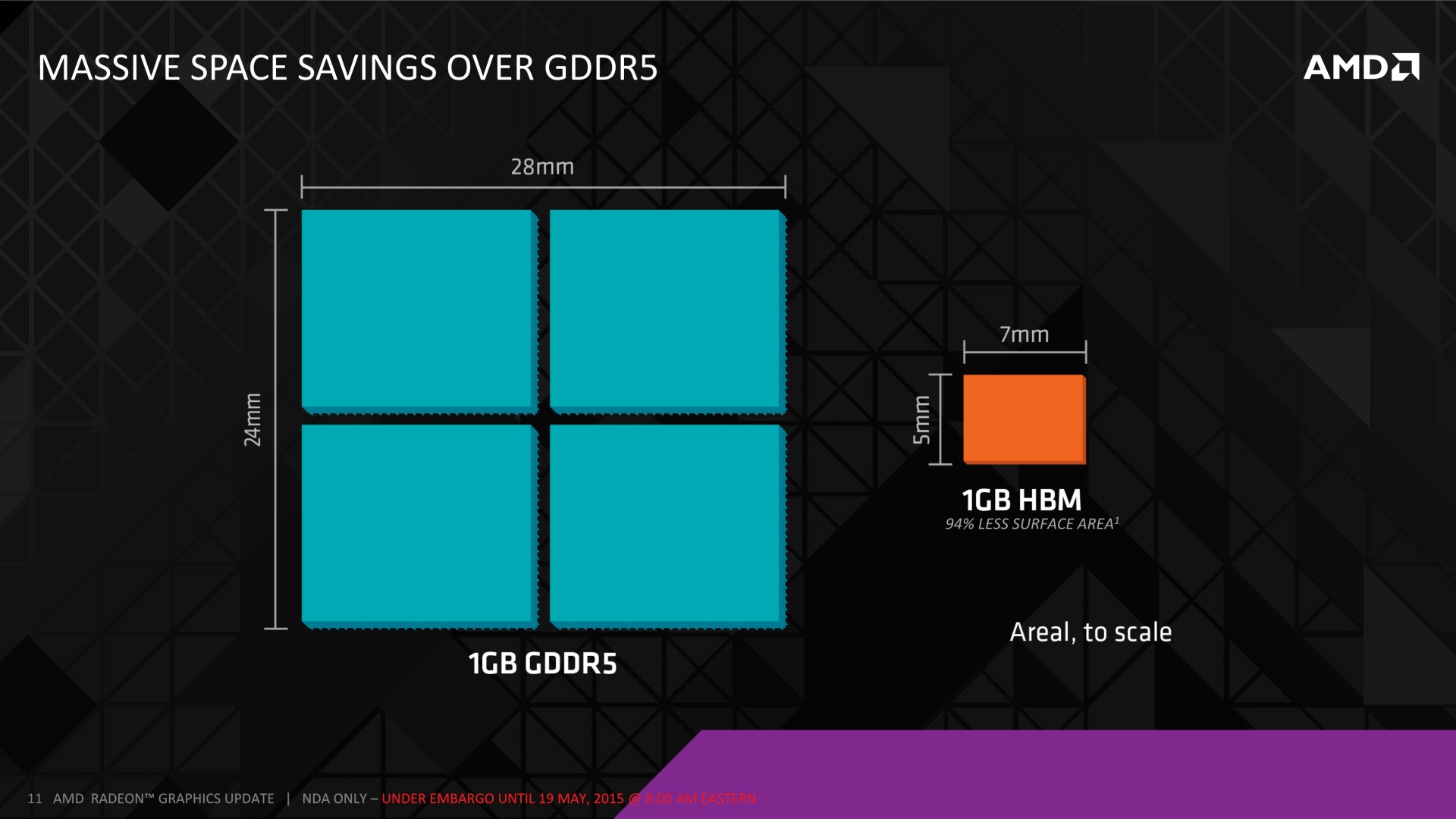    
Pourquoi la HBM ? Introduite par AMD au cours de l'été 2008, la GDDR5 a évolué progressivement en partant d'un débit par pin de 3.6 Gbps pour atteindre 7 à 8 Gbps aujourd'hui. Une évolution, relativement lente, qui aurait pu se poursuivre via différentes techniques mais qui se serait heurtée au mur de la consommation.
Comme dans bien d'autres domaines, la course à la fréquence est une mauvaise idée, son impact sur la consommation est trop important, que ce soit au niveau de la mémoire elle-même ou du bus de communication et des interfaces du GPU. C'est d'autant plus vrai quand l'enveloppe thermique des GPU est strictement contrôlée : plus la mémoire est gourmande, moins il y a de marge de manœuvre pour le GPU. C'est d'ailleurs en partie pour cette raison qu'AMD s'est contenté de GDDR5 5 Gbps pour ses Radeon R9 290.
  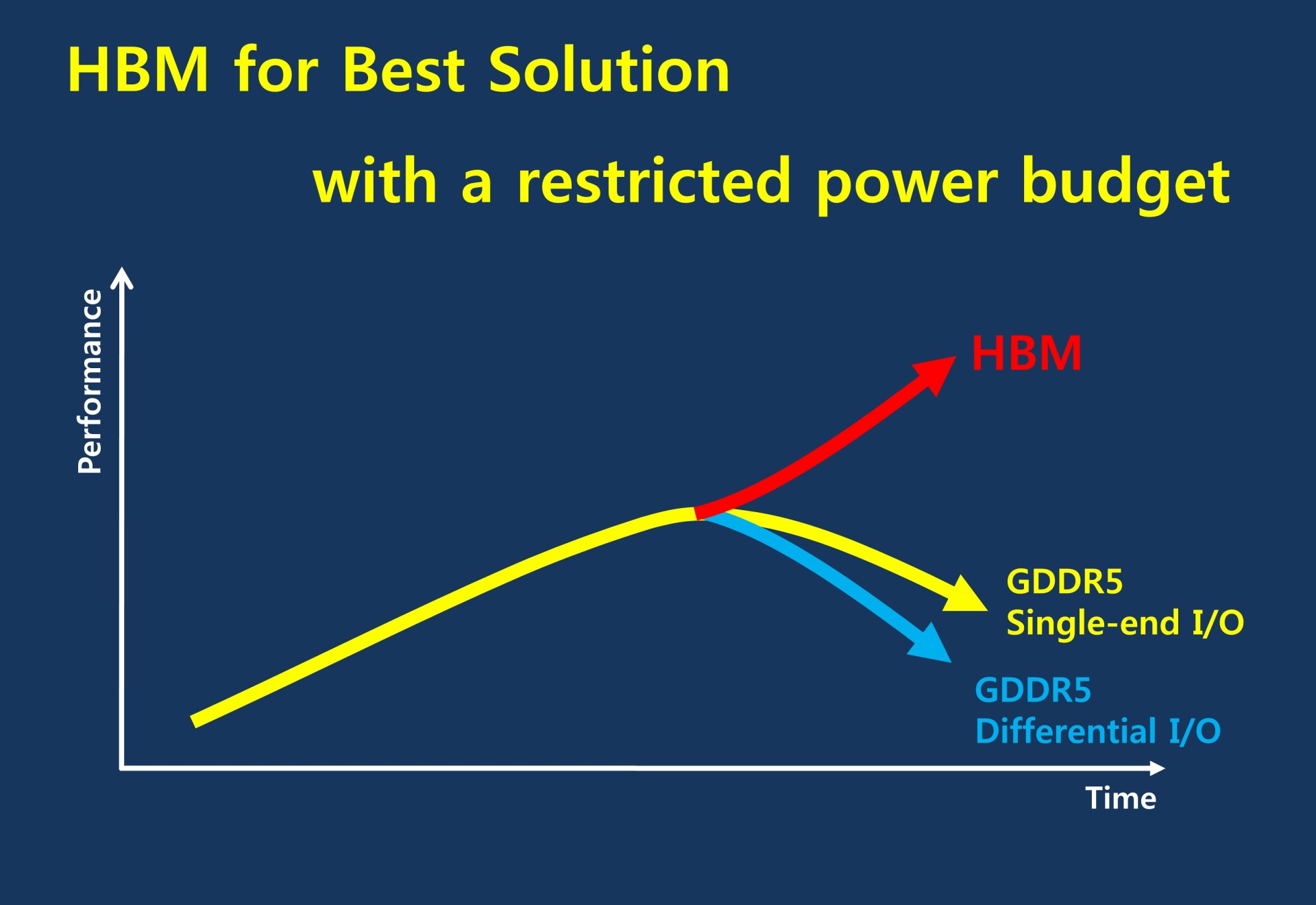 
Grossièrement la HBM est une nouvelle génération de DRAM qui revient sur des bases plus efficaces en réduisant la fréquence mais en élargissant les voies de communication, ce qui est rendu possible par les technologies de fabrication récentes. Alors qu'une puce de GDDR5 est interfacée en 32-bit mais peut tourner à 8 Gbps, une puce HBM va se contenter de 1 Gbps mais en étant interfacée en 1024-bit. De quoi faire progresser la bande passante par puce de 32 à 128 Go/s sans faire exploser la facture énergétique.
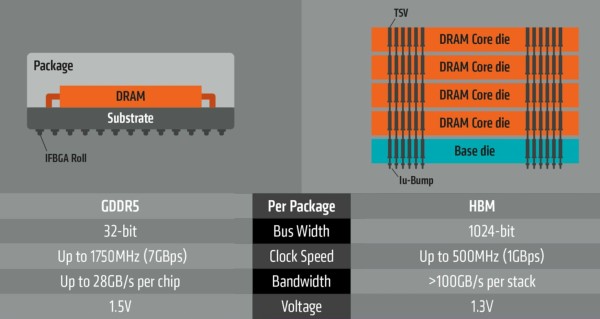
Des puces 1024-bit, comment est-ce possible ? Alors bien entendu, il est logique de se demander comment gérer une telle densité d'entrées/sorties. Si les bus sont restés relativement étroits ce n'est pas pour rien, c'est parce qu'il était physiquement très difficile de les élargir davantage. Passer d'un bus mémoire 512-bit à un autre de 4096-bit est impensable sur base des technologies de fabrication et d'assemblage classiques.
L'interposer Pour rappel, avec le packaging Flip Chip BGA classique utilisé pour les GPU, la puce est retournée de manière à ce que sa matrice de billes (les connexions vers l'extérieur) puisse être soudée sur un substrat qui peut être vu comme un petit PCB intermédiaire.
Vue en coupe d'un packaging fcBGA classique.
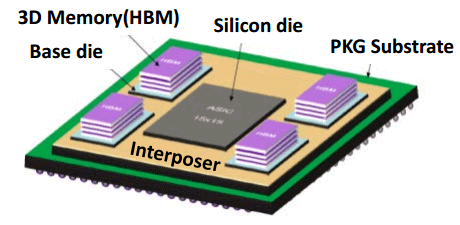 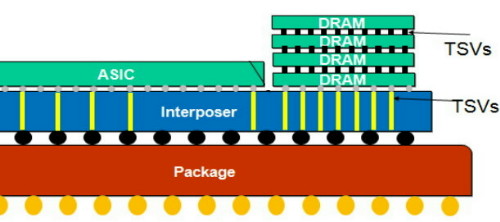 Un interposer est fabriqué par photolithographie, à peu près comme toute autre puce, à la grande différence qu'il est totalement passif et ne contient donc pas de transistors mais uniquement quelques niveaux d'interconnexions. Des interconnexions sur silicium qui peuvent évidemment être bien plus denses et précises que les traces d'un substrat. De quoi cette fois pouvoir exploiter des matrices de micro-billes (µbumps) extrêmement denses qui vont permettre de facilement connecter un GPU et plusieurs modules mémoire HBM interfacés chacun en 1024-bit. De quoi également réduire nettement la longueur de ces connexions, ce qui va permettre d'améliorer la qualité du signal et de réduire la consommation.
    La HBM plus en détail Avec les spécifications du JEDEC, cette présentation de SK Hynix est une des sources d'informations les plus complètes sur la HBM :   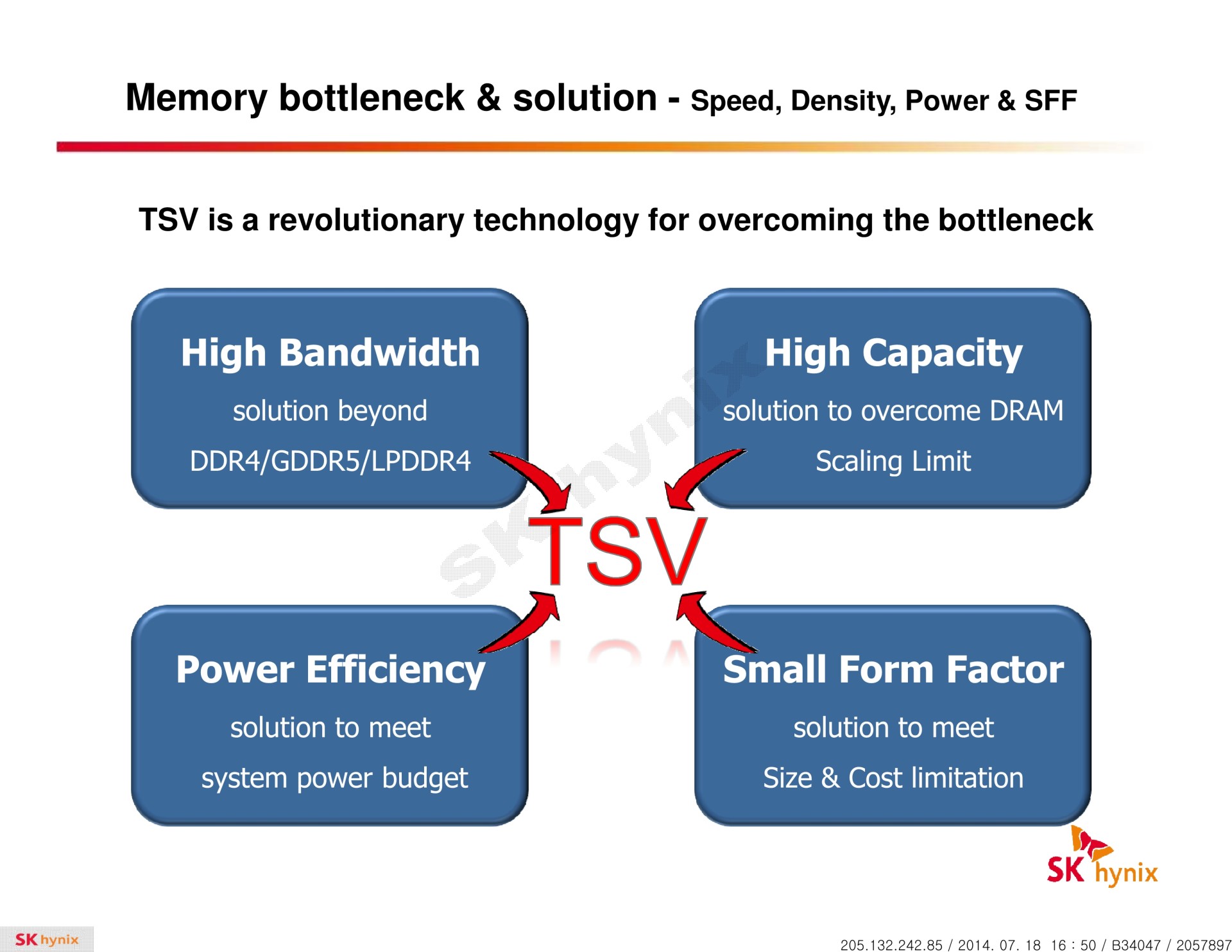 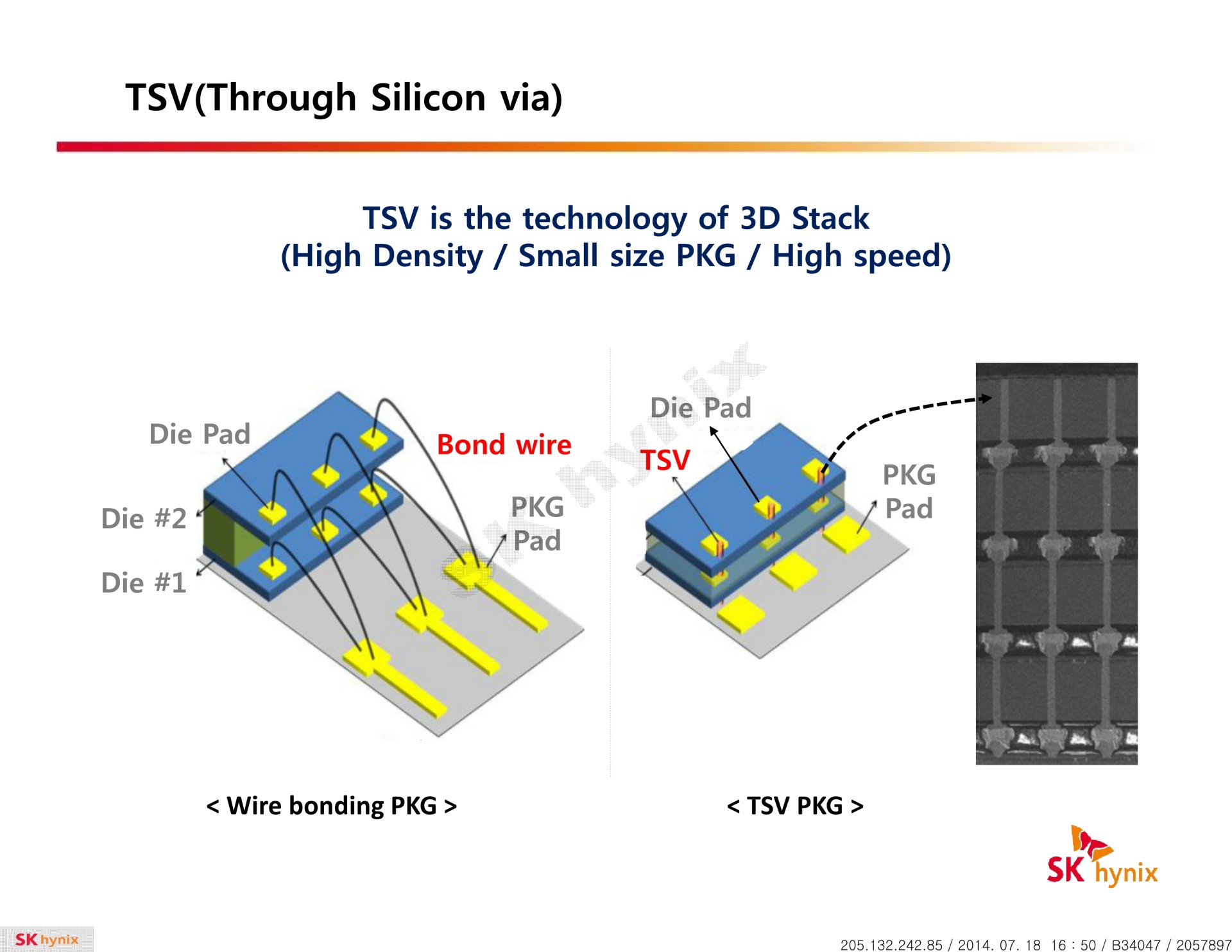 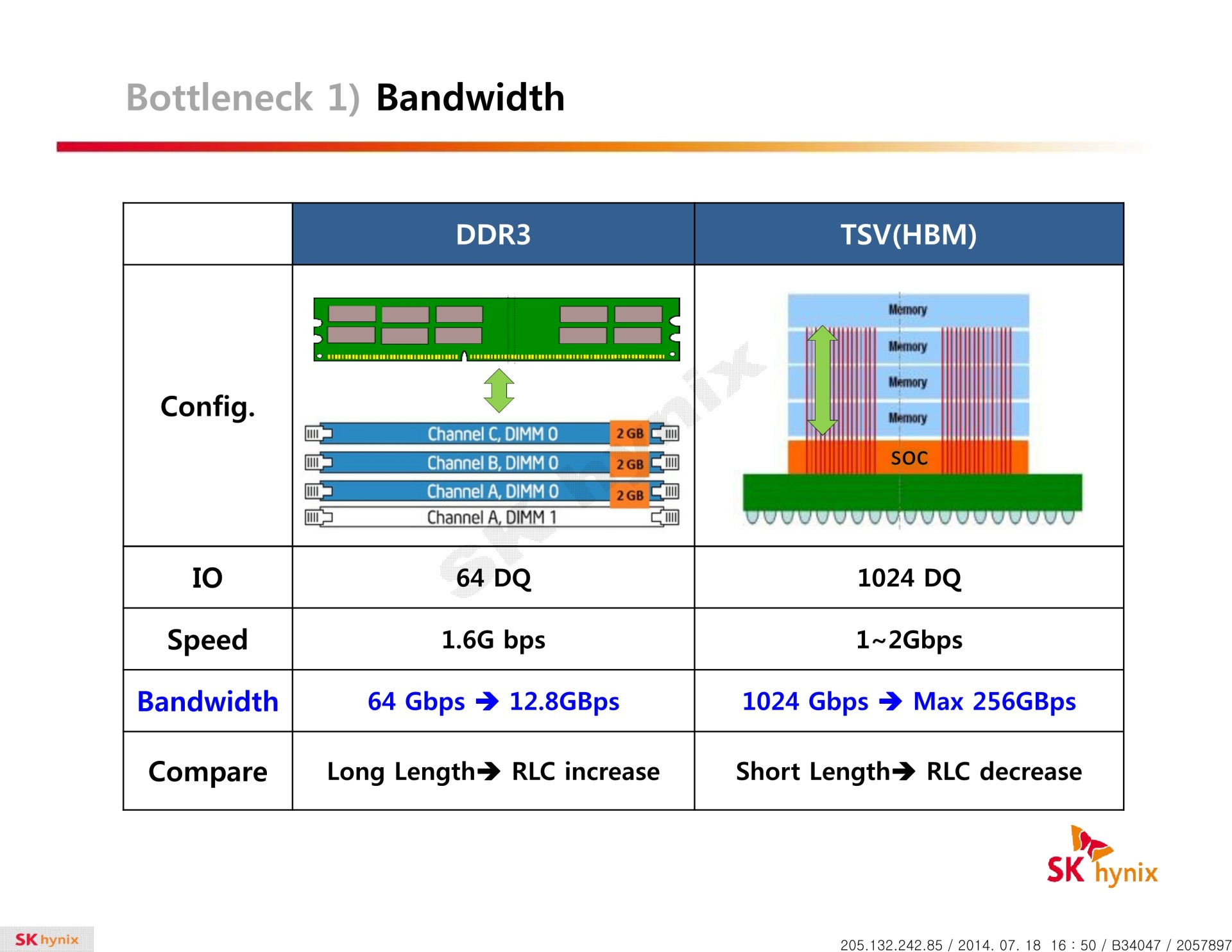   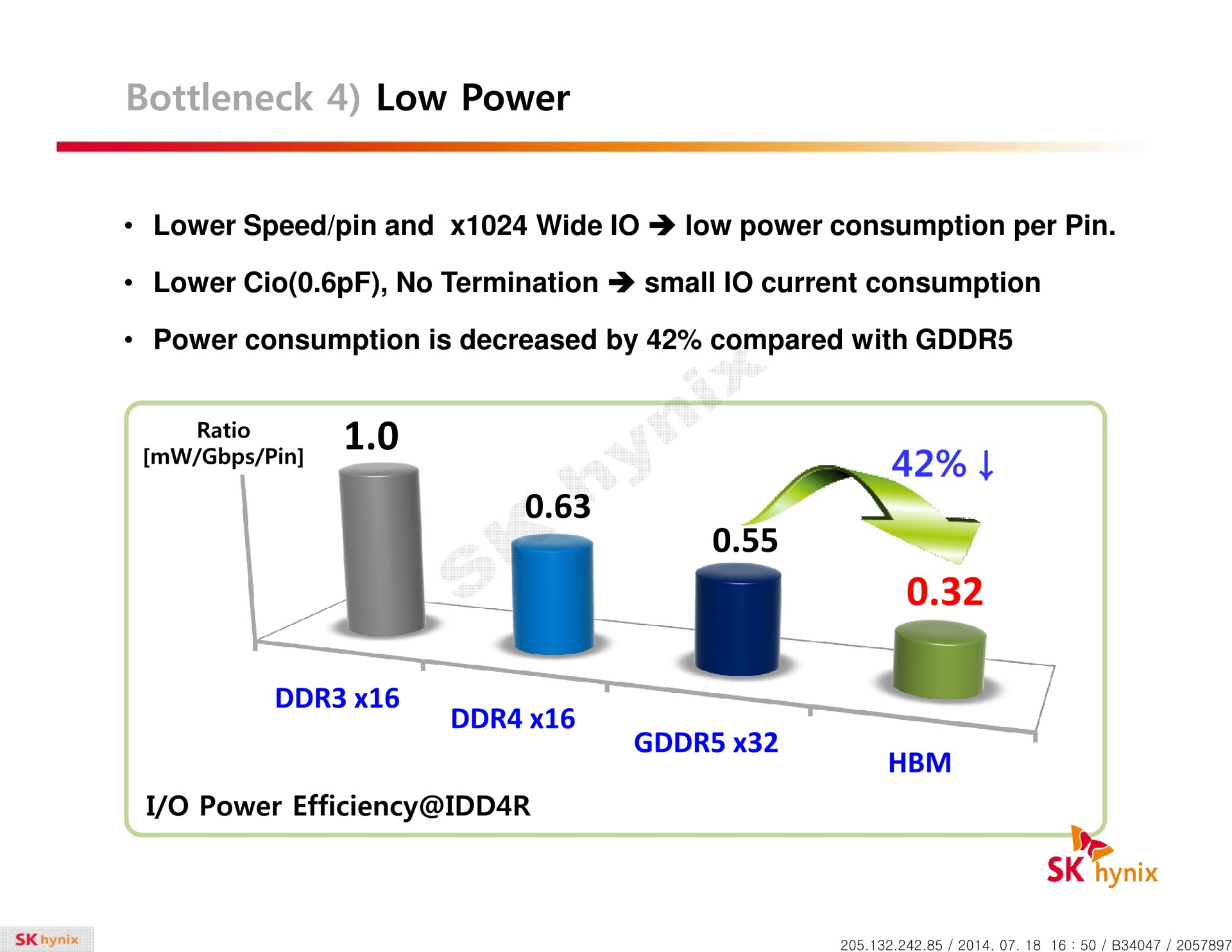 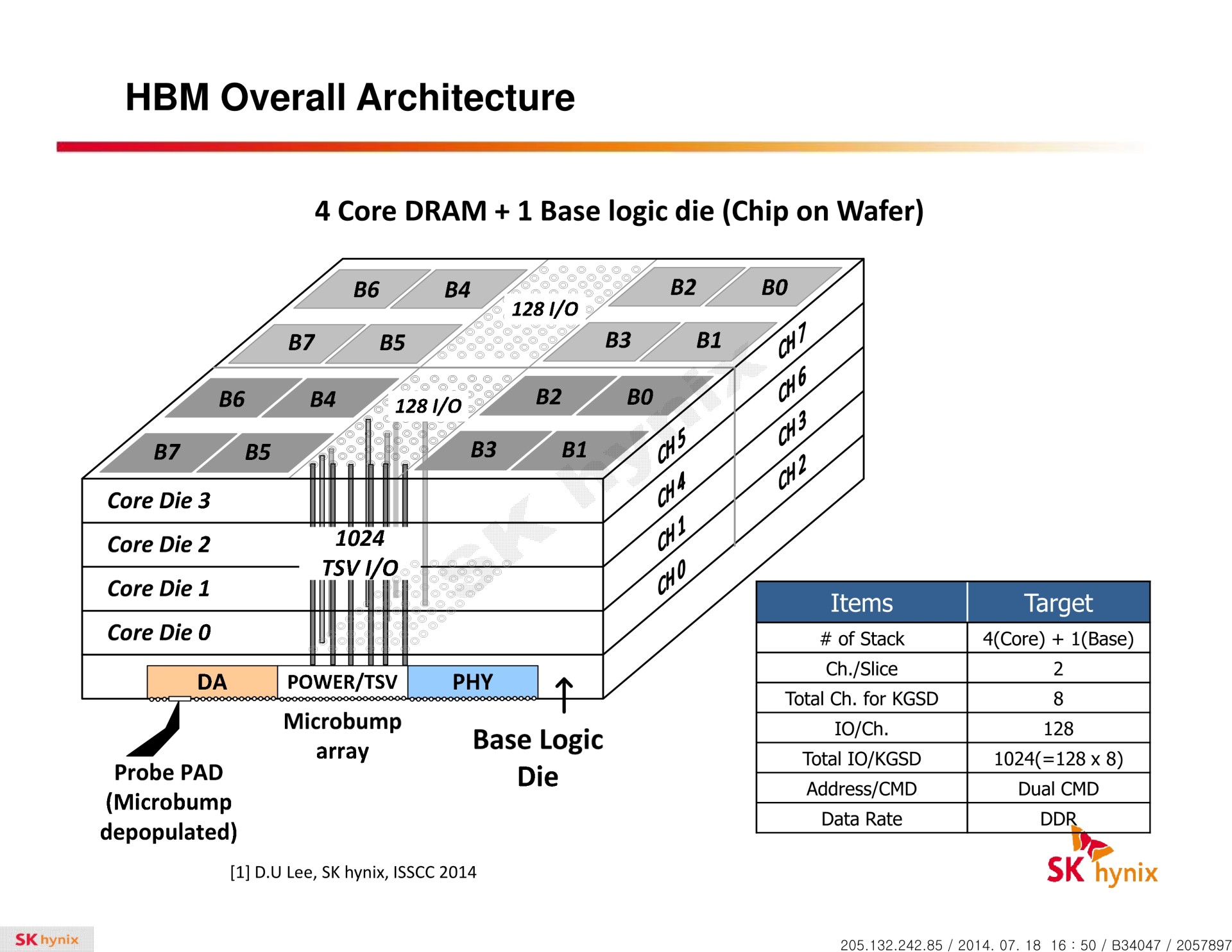 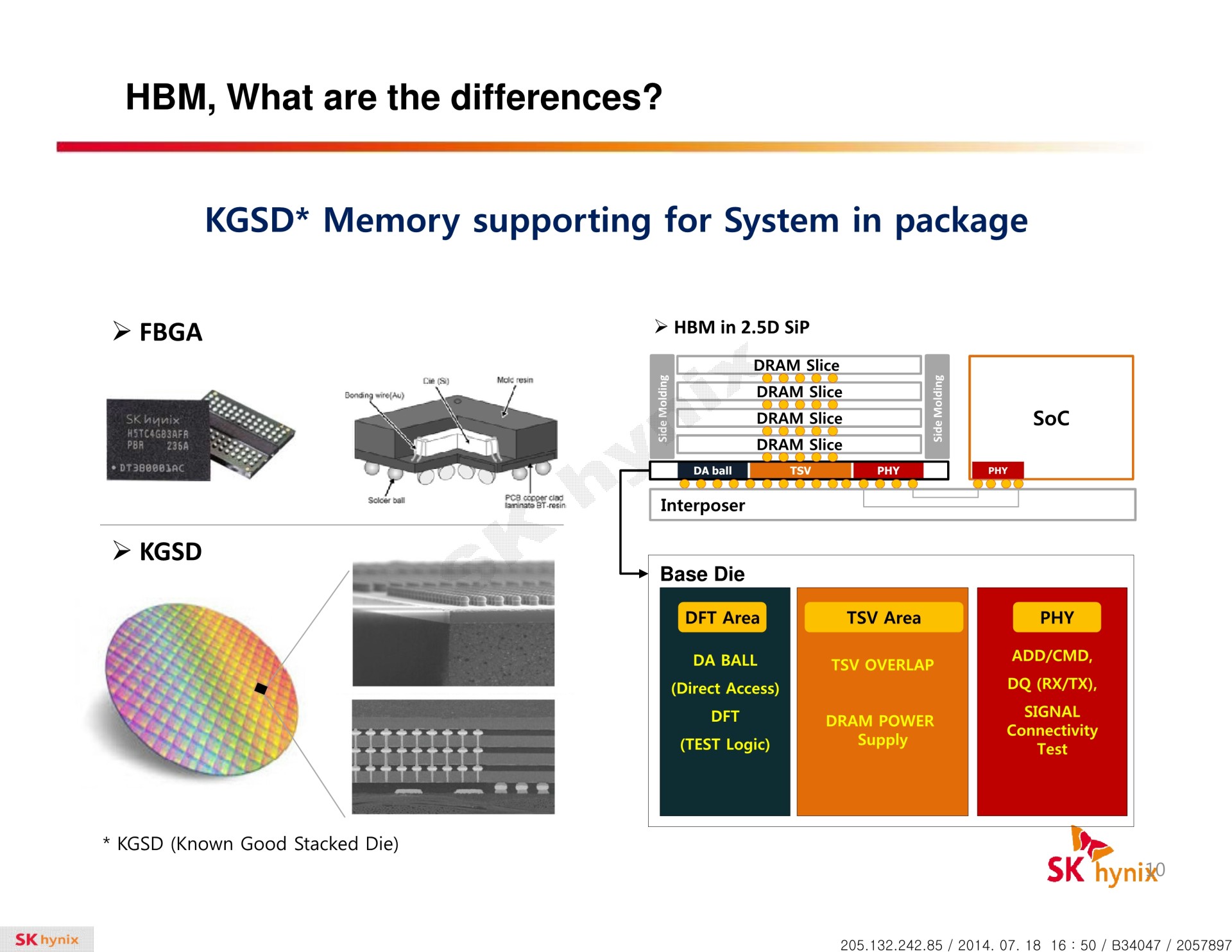  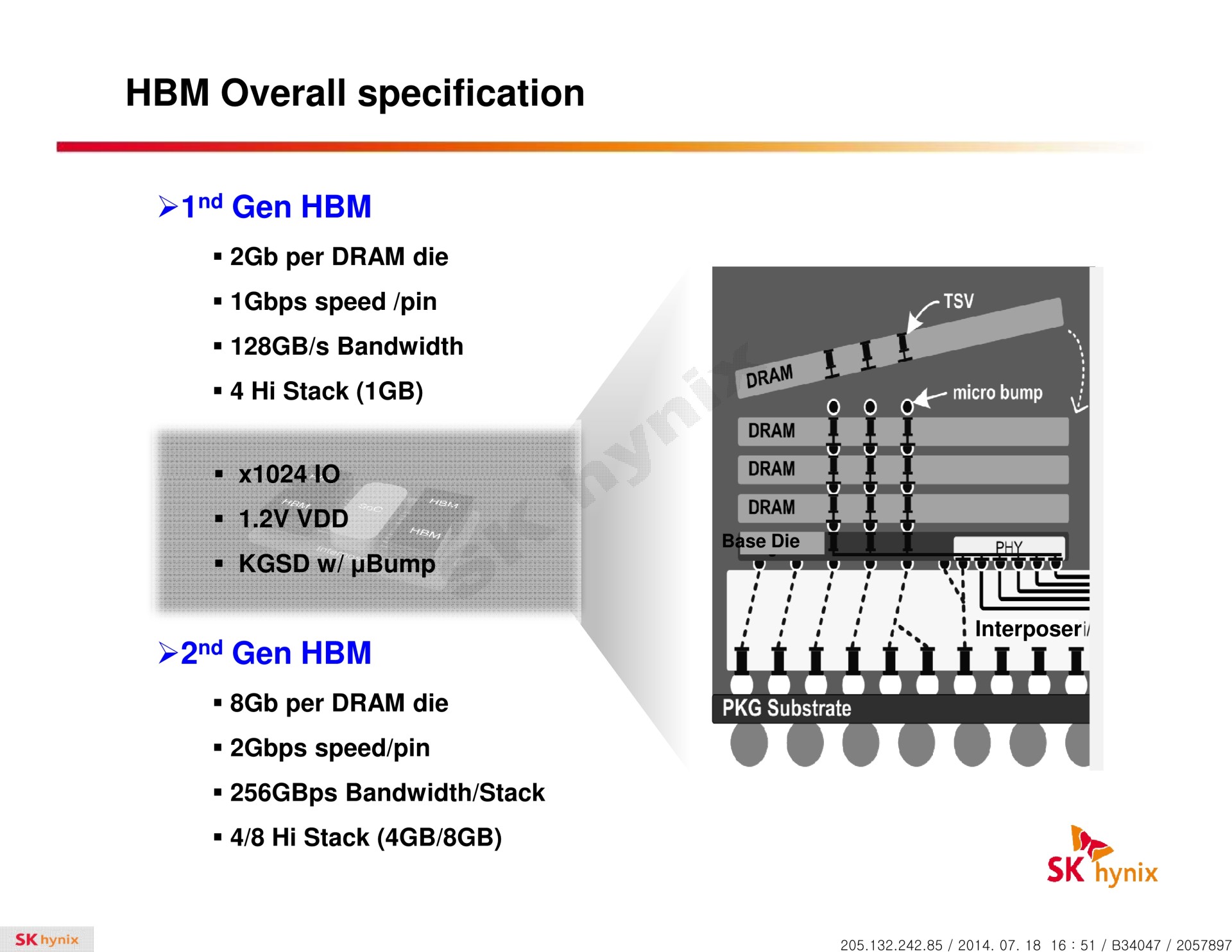  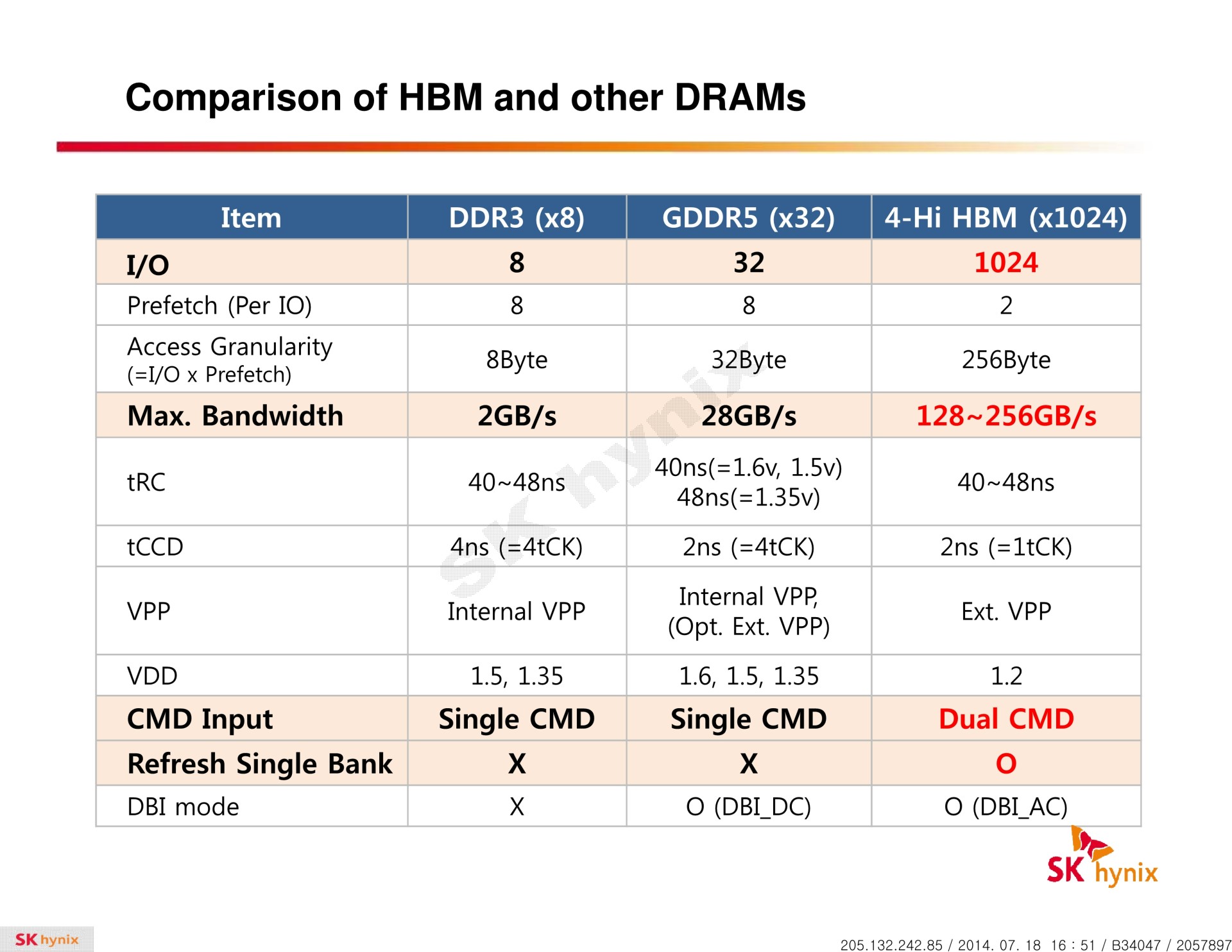 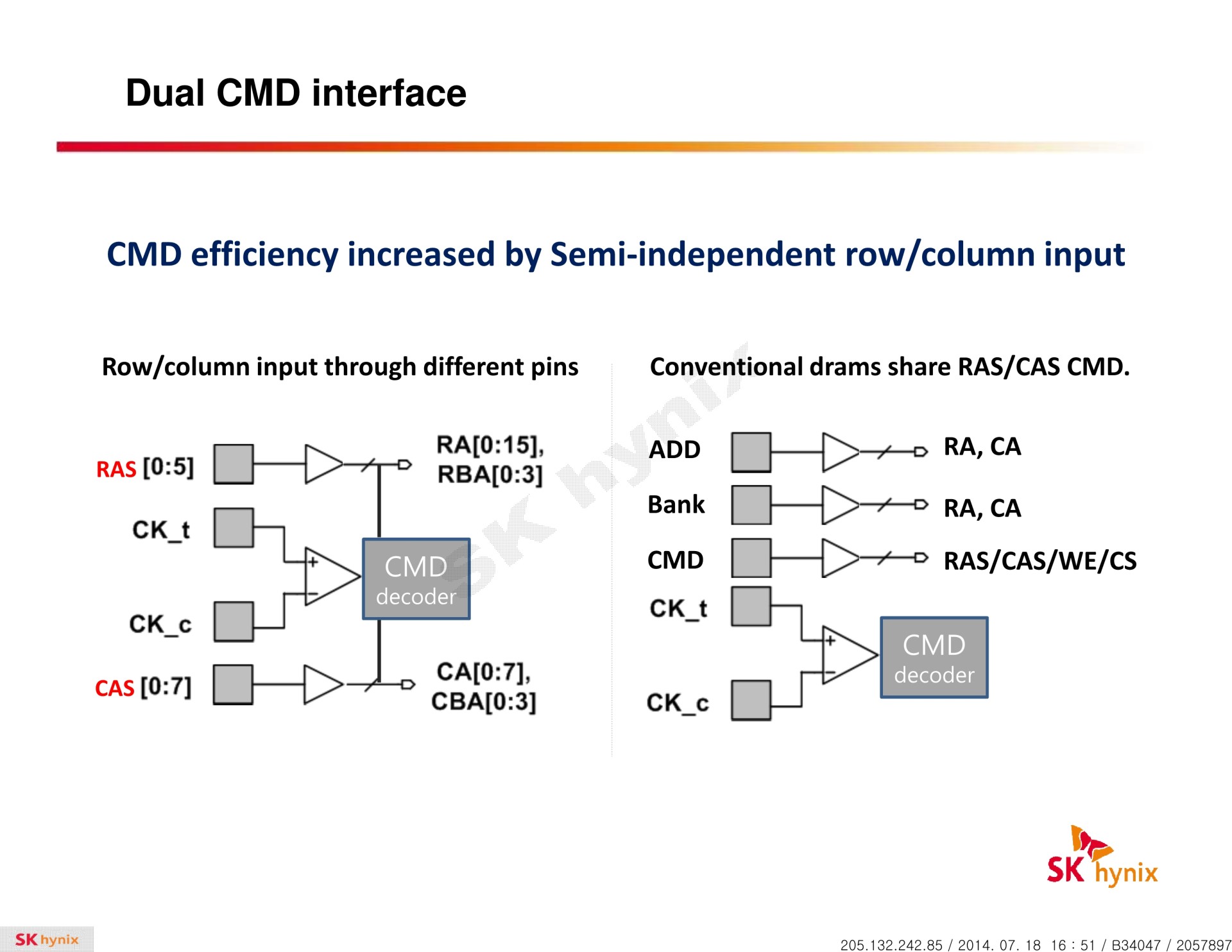 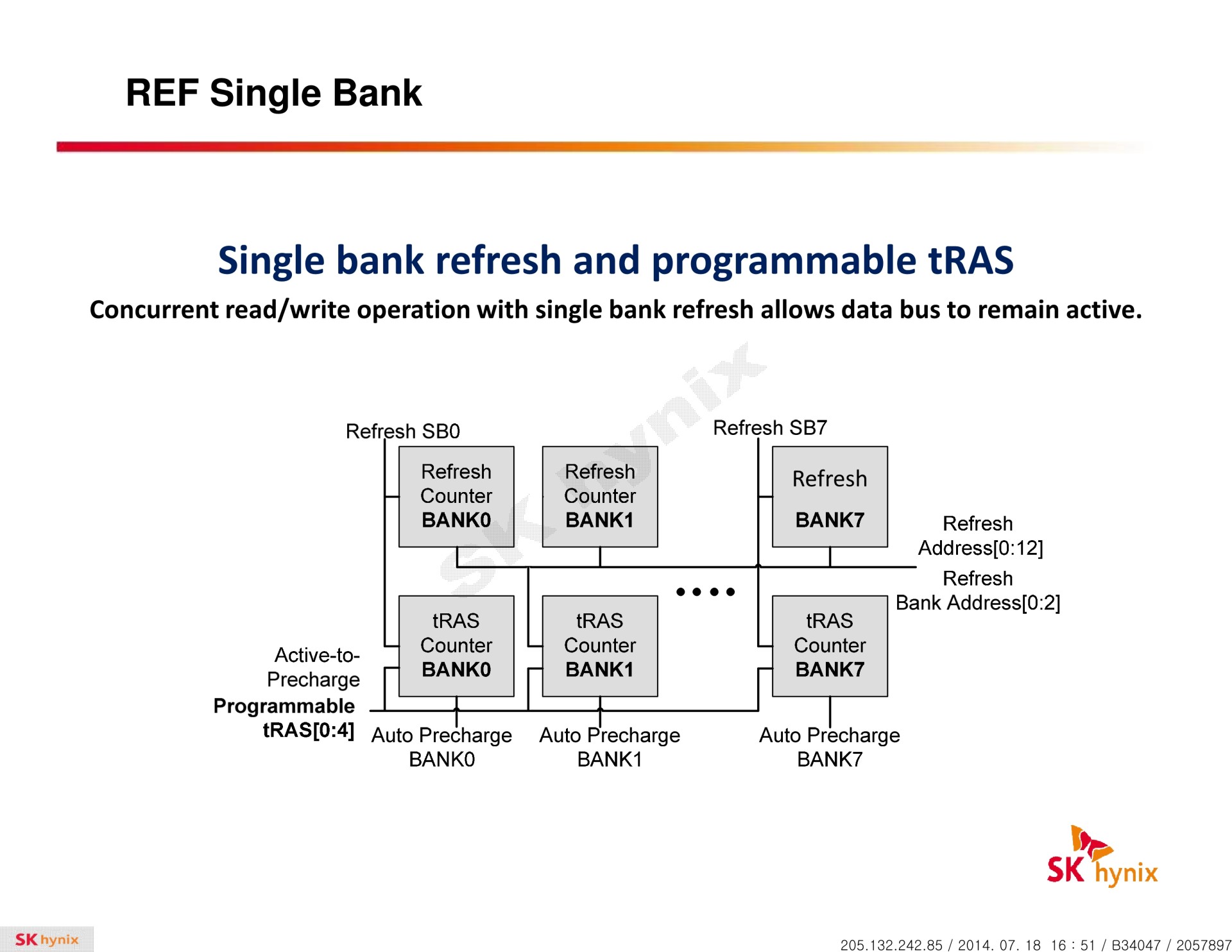  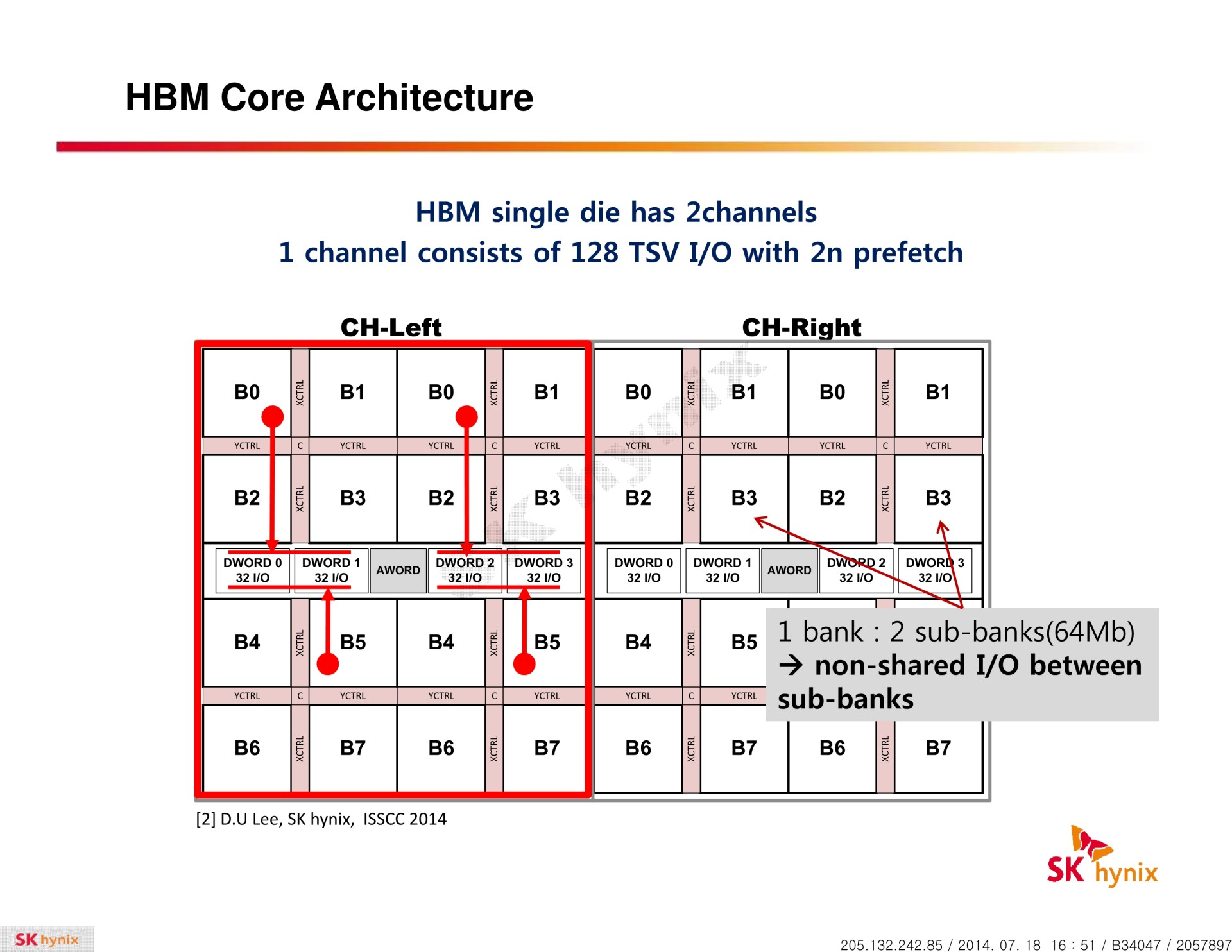 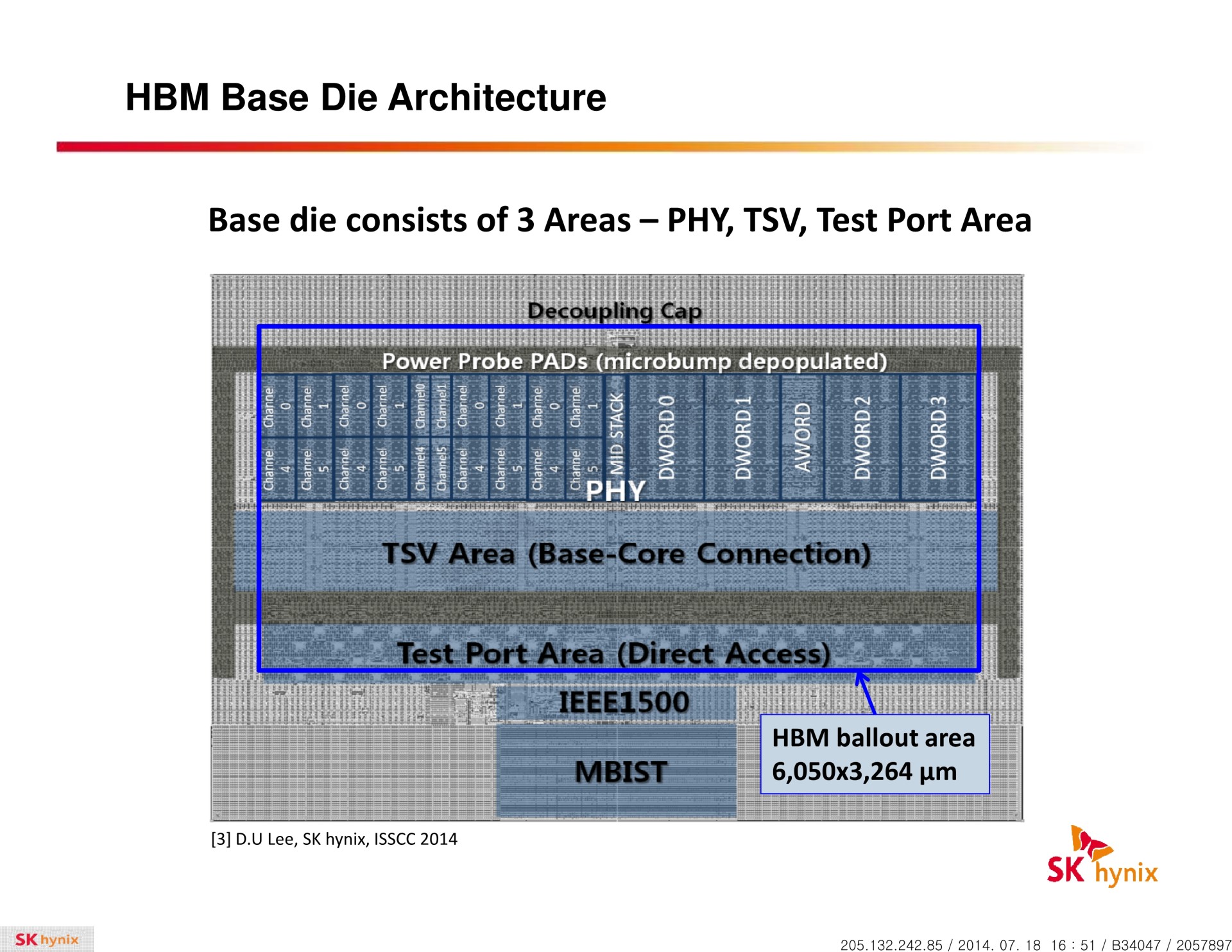  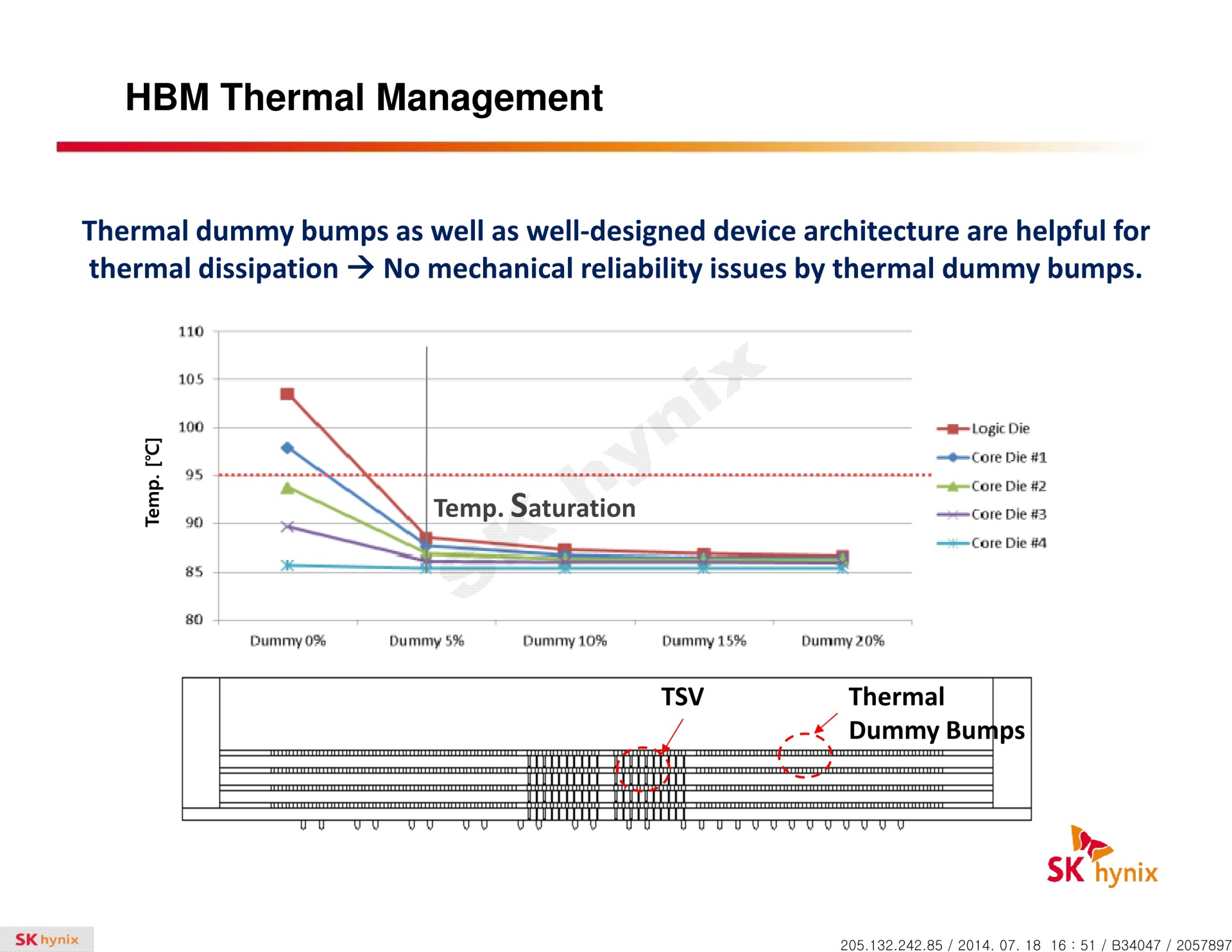 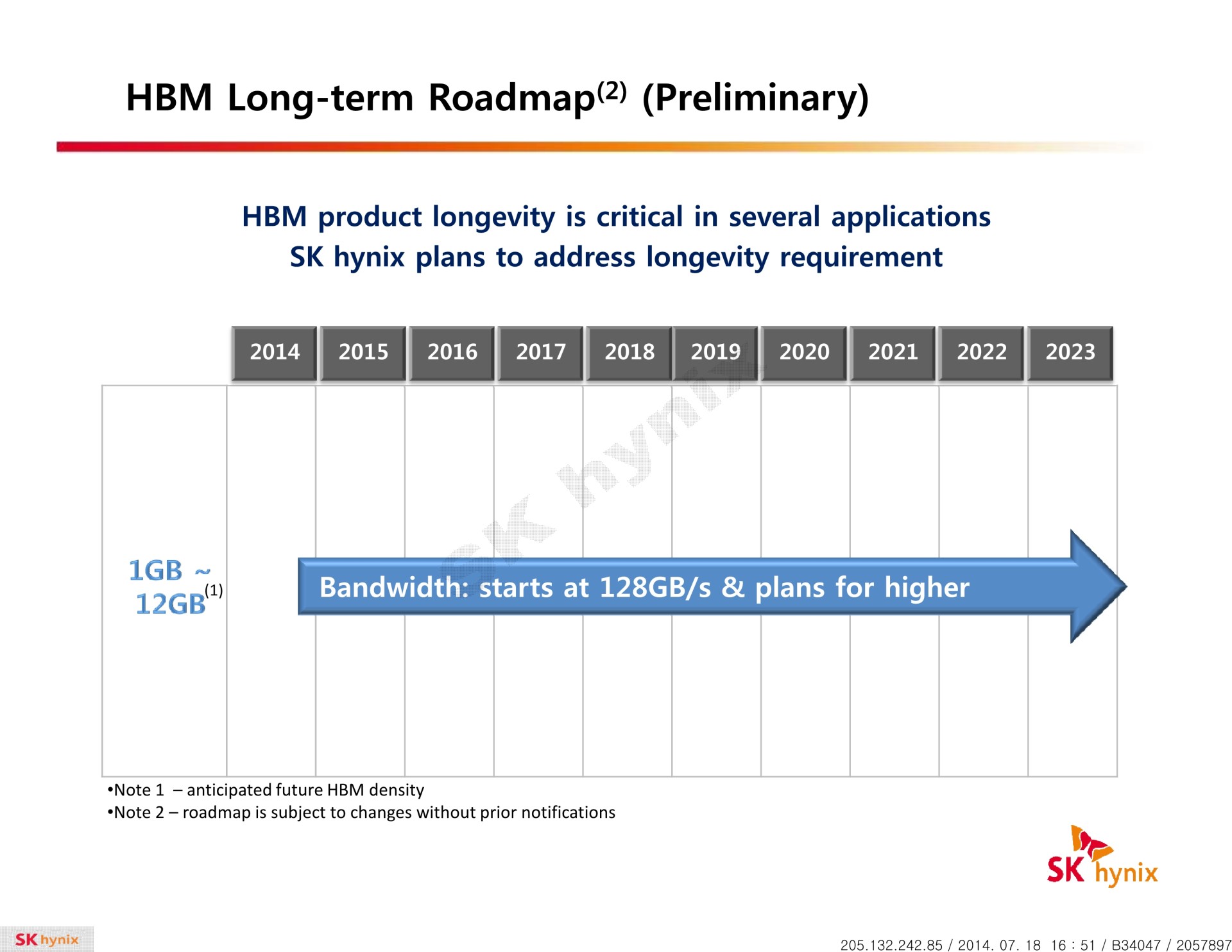   Un des challenges pour les modules HBM était de proposer une quantité suffisante de mémoire (densité) sur une très petite surface. Difficile d'imaginer associer 12 ou 16 modules lorsque chacun représente un bus de 1024-bit et rappelons que l'espace est cher sur un interposer. Les modules de Hynix, les premiers disponibles, mesurent 5.5mm x 7.3mm, c'est 4x plus petit qu'un module GDDR5 dont le packaging mesure 12mm x 14mm. Des modules GDDR5 représentent chacun jusqu'à 512 Mo dans leur version la plus dense (4 Gb). C'est très bien quand ils sont présents en nombre, mais trop peu dans le cas de quelques modules HBM dont l'exemple présenté par AMD en mentionne 4. Pour augmenter la densité, la HBM a ainsi recourt au die stacking, soit à l'empilement de dies mémoire. Pour cette première génération, Hynix a opté pour 4 dies mémoires superposés, dont la surface est intégralement (ou presque) dédiée aux cellules mémoire. Toute la partie logique est déportée sur un 5ème die qui fait office de base au module. Une particularité optionnelle au standard JEDEC probablement nécessaire pour les structures 2.5D ou pour gagner de la place sur les dies de cellules DRAM. 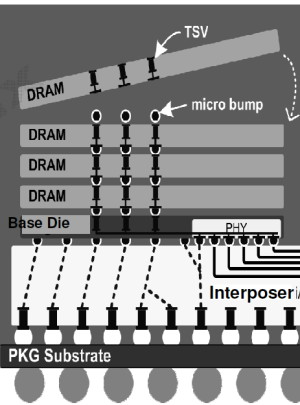 Ici aussi ce sont les TSV qui permettent de construire cet empilement, chaque die mémoire étant perforé pour que les interconnexions puissent le traverser. Contrairement à ce que laissent penser les illustrations de la mémoire HBM, cela n'en fait pas pour autant un module qui ressemble à une tour. Tous ces dies sont produits sur des wafers ultra fins et au final un module HBM n'est pas plus épais qu'une puce classique telle qu'un GPU. Hynix parle de +/- 0.5mm pour la hauteur totale. Pour cette première génération, Hynix empile 4 dies d'une densité de 2 Gb, ce qui représente une densité totale de 8 Gb, soit 1 Go de mémoire. A noter qu'il y a eu pas mal de confusion au départ sur la densité de ce module. Les spécifications initiales de Hynix (densité de 1 Gb) pouvaient laisser penser que seulement 128 Mo de mémoire était embarqués. C'était autant une erreur de communication qu'une mauvaise lecture de ses spécifications puisque pour la HBM, le standard JEDEC ne définit pas la densité de mémoire par module mais par canal... dont le nombre pouvait être déduit des 1024-bit pour obtenir la densité totale.
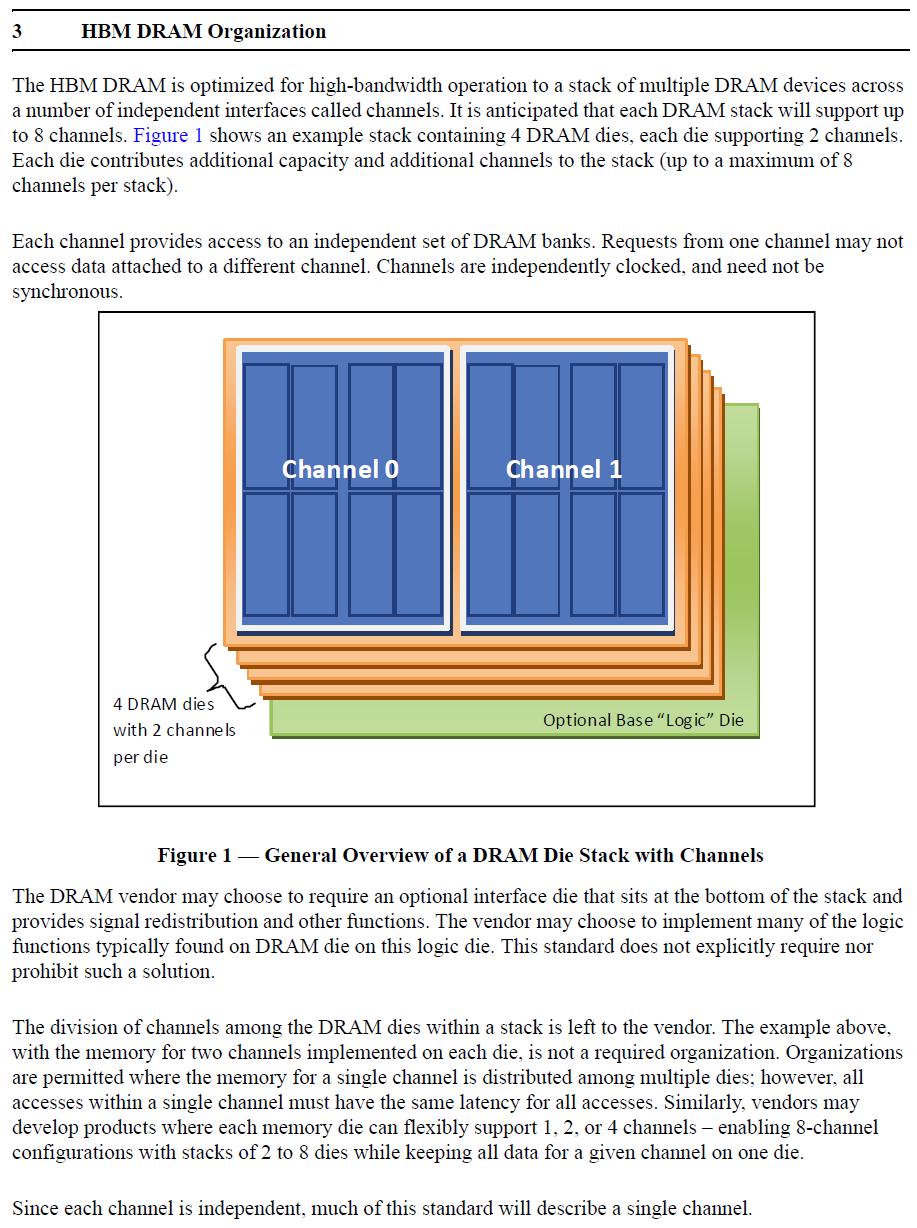 Extrait de la spécification JEDEC pour la HBM.
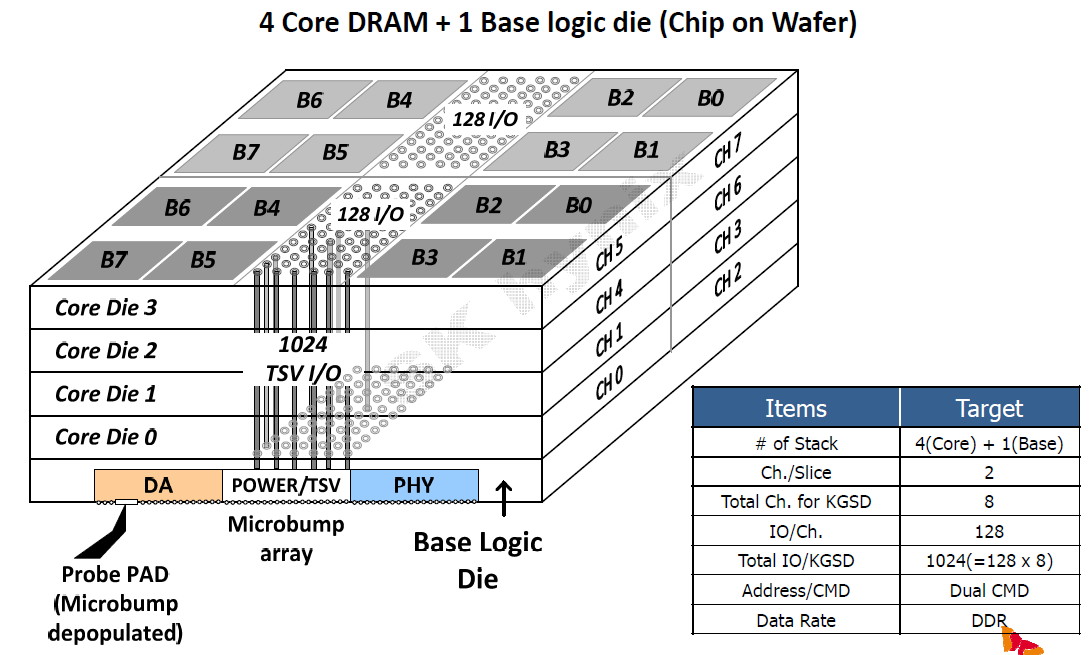 Pour rester à un niveau similaire à celui de la GDDR5, les 1024-bit de la HBM ont été répartis en 8 canaux indépendants de 128-bit. A noter que si la spécification HBM définit précisément ce que doit être un canal, elle est par contre très flexible au niveau de l'aspect global : 1024-bit et 8 canaux est un maximum mais il est possible de faire moins, par exemple des modules 512-bit et 4 canaux. Tant que la latence est identique pour tout l'espace mémoire couvert par un canal, les fabricants sont libres de les placer physiquement comme ils l'entendent. En pratique l'approche la plus logique et retenue par Hynix est de placer 2 canaux sur chacun des 4 dies de cellules mémoire. Il nous paraît plausible d'imaginer qu'un module HBM 1024-bit puisse également être configuré en mode 512-bit 4 canaux, avec une densité doublée par canal. D'autant plus quand un 5ème die logique est utilisé, comme chez Hynix, et pourrait intégrer la gestion de cette flexibilité. Une approche qui permettrait, à l'instar du mode clamshell de la GDDR5, de doubler la quantité de mémoire rattachée à un bus donné. Rien ne semble l'empêcher dans les spécifications JEDEC, mais rien n'indique que les modules Hynix supportent cette possibilité. Par ailleurs les différents canaux fonctionnent de manière asynchrone, ce qui offre probablement des opportunités d'économies d'énergie et pourrait peut-être réduire le nombre de contrôleurs mémoire nécessaires dans un GPU. Un bus total de 4096-bit représente par exemple 32 contrôleurs 128-bit ou 16 contrôleurs 256-bit. C'est beaucoup. Mais si nous mettons en parallèle la fréquence plus élevée du GPU et l'asynchronisme entre canaux, nous pouvons imaginer qu'il soit possible de retrouver à l'intérieur d'un gros bloc "256-bit" un petit contrôleur de 128-bit qui gérerait en alternance deux canaux de 128-bit. De quoi faciliter l'implémentation d'un bus mémoire aussi large au niveau du GPU. A ce point, ce n'est bien entendu que de la spéculation de notre part.
 Extrait de la spécification JEDEC pour la HBM.
Le GPU Fiji et la HBM Nous en savons encore très peu sur les détails qui concernent l'implémentation de la HBM pour le GPU Fiji d'AMD. Les rumeurs parlent d'un bus de 4096-bit, ce qui nous semble réaliste. De son côté, AMD parle d'une fréquence mémoire de 500 MHz (DDR), ce qui impliquerait avec un tel bus une bande passante de 512 Go/s (476.8 Gio/s). Un bond conséquent de 50% par rapport au GM200 de Nvidia (GTX Titan X) et de 60% par rapport au GPU Hawaii (R9 290X).  Tout ceci se ferait avec un gain au niveau de la consommation liée à l'interface mémoire. AMD parle d'une bande passante par watt plus que triplée par rapport à la GDDR5 pour atteindre plus de 35 Go/s par watt avec la HBM. AMD annonce également que la solution HBM permet un gain important de bande passante pour une consommation réduite de plus de 50%. AMD n'en dit cependant pas plus sur ce à quoi correspondent ces chiffres : uniquement la consommation externe au GPU ou également ses interfaces mémoire ? La réponse se trouve probablement dans la documentation d'Hynix qui parle de son côté de 3.3W par puce HBM 128 Go/s. Associées par 4, cela donne 13.2W, ce qui correspond à peu près aux chiffres d'AMD qui du coup ne représenteraient que la partie externe. Une quinzaine de watts y seraient ainsi gagnés par rapport à la mémoire de Hawaii et bien plus par rapport à un GPU qui utiliserait de la GDDR5 pour atteindre 512 Go/s de bande passante. Cela ne veut cependant pas dire que la consommation de la carte graphique va baisser, par exemple de 285 à 270W. Ces watts gagnés seront vraisemblablement réinvestis dans le GPU dont le turbo ne crache pas sur un peu de marge supplémentaire. Par ailleurs, il faut encore voir quel sera l'impact sur la consommation de l'interface mémoire du GPU. Certes la fréquence du bus baisse, mais il passe tout de même à 4096-bit. Une des grosses interrogations concerne la quantité de mémoire qui pourra être attachée au GPU Fiji. Les déclarations d'AMD, qui a organisé la semaine passée une conférence téléphonique commune pour l'ensemble de la presse technique, sont d'ailleurs interprétées différemment suivant les médias. Notre propre interprétation est que le porte-parole d'AMD, Joe Macri (CTO AMD et Président du sous-comité DRAM du JEDEC), a fait en sorte d'essayer de parler de généralités en s'efforçant de ne rien dévoiler de définitif concernant Fiji. Ainsi si la plupart des éléments pointent vers une limitation à 4 modules HBM, soit à 4 Go, nous n'excluons pas à ce point qu'AMD garde sous le coude la surprise d'une variante 8 Go. Dans tous les cas, de manière générale, l'utilisation d'une mémoire plus chère et plus complexe à intégrer en masse va demander aux ingénieurs qui développent les pilotes graphiques de prendre soin de mieux utiliser la mémoire disponible. Et sur ce point, Joe Macri explique que nous serions choqués en apprenant les nombreuses possibilités d'optimisation qui ont été inexplorées jusqu'ici parce qu'augmenter la quantité de mémoire était plus simple. (Une déclaration que les joueurs qui ont dû mettre à jour leur carte graphique suite à une mémoire insuffisante apprécieront à des degrés divers !) Autre question qui revient régulièrement : quid du refroidissement ? Devra-t-il être adapté ? Le recours au watercooling est-il obligatoire ? De nombreux éléments laissent penser qu'il existera au moins une variante Fiji de référence qui fera appel à un système de watercooling. Mais le recours à la HBM ne l'impose pas. Si AMD y a recours ce sera pour accompagner un GPU gourmand. La base du système de refroidissement devra certes s'occuper de la mémoire HBM en plus du GPU, mais sa consommation n'est pas bien importante par rapport à ce dernier. Par ailleurs, Joe Macri a indiqué que les modules HBM permettent en fait en quelque sorte d'augmenter la surface de dissipation du GPU, une partie de la chaleur qu'il dégage leur étant transmise.  Enfin, la mémoire HBM permet de simplifier nettement le PCB puisqu'il ne doit plus intégrer la mémoire et son bus. De quoi potentiellement réduire significativement sa taille, même si ce ne sera probablement pas toujours utile vu que certains systèmes de refroidissement à air resteront, eux, volumineux. Nous avons posé plusieurs questions plus spécifiques à AMD. Sera-t-il possible de configurer les modules HBM en 512-bit pour augmenter la quantité de mémoire ? Sera-t-il possible à un GPU de profiter du fonctionnement asynchrones des différents canaux ? Est-il important pour la HBM d'éviter qu'elle ne dépasse une certaine température pour éviter une baisse de performances ? Est-ce que la fréquence de 500 MHz est utilisée pour éviter le bank grouping ? ... Malheureusement pour nous (et pour vous), après quelques jours de réflexion, AMD nous a invité à reposer ces questions lors d'un prochain lancement.
A quoi ressemblera physiquement le packaging du GPU Fiji ? Une image discrètement intégrée au design d'une page AMD pourrait bien être un extrait d'une représentation réaliste de la chose :

Une mémoire vouée à se généraliser ? L'association de la HBM avec le GPU Fiji n'est qu'un début. Fiji peut d'ailleurs être vu comme une plateforme de développement pour la HBM tant de nombreux éléments ont dû être progressivement mis en place au niveau des chaînes de fabrication pour que cette mémoire devienne réalité.   CPU et autres SoC seront également intéressés par cette mémoire. AMD a d'ailleurs laissé entendre que certains de ses futurs Opteron en embarqueraient pour faire exploser leur bande passante mémoire. Dès 2016, Hynix proposera la HBM 2 qui doublera les débits ainsi que la densité pour atteindre 256 Go/s et 2 Go par module. AMD a d'ores et déjà annoncé que cette mémoire serait utilisée dès qu'elle serait disponible. C'est également ce type de mémoire que Nvidia envisage pour sa prochaine architecture GPU : Pascal. Restera alors à voir si l'expérience acquise par AMD avec cette technologie se transformera en avantage une fois que son utilisation explosera. Copyright © 1997-2026 HardWare.fr. Tous droits réservés. |

