| |
| |
| Nvidia GeForce GTX 980 et GTX 970 : le GM204 Maxwell et les Gigabyte G1 Gaming en test Cartes Graphiques Publié le Vendredi 30 Janvier 2015 par Damien Triolet URL: /articles/928-1/nvidia-geforce-gtx-980-gtx-970-gm204-maxwell-gigabyte-g1-gaming-test.html Page 1 - Introduction Enfin du mouvement dans le segment haut de gamme des cartes graphiques ! En y introduisant l'architecture Maxwell, Nvidia compte bien pousser les performances d'un cran vers le haut, tout en mettant tout le monde d'accord sur le plan de l'efficacité énergétique. C'est ce que nous allons vérifier à travers un test complet de la GeForce GTX 980 de référence ainsi que des GTX 980 et 970 G1 Gaming de Gigabyte.  Le GM204 pour succéder au GK104 et au GK110Nvidia reprend la même approche que lors du lancement de Kepler et de la GeForce GTX 680. Pour son architecture Maxwell qualifiée de seconde génération, Nvidia n'introduit pas en premier lieu le plus gros GPU de la famille auquel nous pouvons faire référence en tant que GM200. Peu importe son nom, celui-ci débarquera plus tard, probablement l'an prochain avec un process de fabrication plus évolué que l'actuel 28 nanomètres de TSMC. Dans l'immédiat, c'est le second GPU qui est introduit, le GM204. Mais tout comme le GK104 lors de son introduction il ne démérite pas, loin de là. Il est également capable de devancer le gros GPU Kepler, le GK110, comme nous allons le voir. Par la même occasion, Nvidia démontre qu'il reste possible de proposer une évolution intéressante en tout point sans devoir attendre le 20 nanomètres. Le GM204 combine l'architecture Maxwell déjà observée sur le GM107 et les GeForce GTX 750 avec quelques petites fonctionnalités supplémentaires ainsi que le support du HDMI 2.0, de l'encodage HEVC et d'un décodage hybride de celui-ci. Mais surtout, le GM204 en multiplie le nombre d'unités de calcul et apporte quelques légères modifications pour maximiser les performances, malgré les quelques compromis qui ont été fait pour réduire la facture énergétique. A noter que Nvidia a décidé de sauter la nomenclature GeForce GTX 800. Celle-ci est déjà exploitée depuis de nombreux mois pour les traditionnels renommages du monde mobile et le passage aux GeForce GTX 900M est imminent. Nvidia a ainsi jugé peu opportun d'introduire la marque GeForce GTX 800 et préféré de passer aux GTX 900, ce qui n'est pas plus mal. Mais ne vous attendez pas à ce qu'il n'y ait aucun renommage dans cette gamme, ni à ce que les nomenclatures mobile et desktop restent toujours correspondantes à l'avenir. Il n'y a pas de changement majeur de stratégie à ce niveau, juste une modification ponctuelle opportuniste. Mise à jour du 30/01/15 : un peu plus de 4 mois après le lancement de ces cartes, Nvidia a admis avoir commis une erreur dans les spécifications de la GTX 970 communiquées au lancement. Une erreur qui a masqué un comportement plus complexe que prévu dans la gestion de la mémoire de cette carte graphique. Nous avons donc rectifié ce dossier et ajouté une page qui explique les aspects techniques liés. Page 2 - GM204 : 5.2 milliards de transistors GM204 : 5.2 milliards de transistorsAvec Maxwell, nom de code sa nouvelle architecture, Nvidia continue l'effort entrepris lors du passage de Fermi vers Kepler, pour une meilleure efficacité énergétique. C'est d'autant plus nécessaire que le procédé de fabrication n'évolue pas et reste la même variante du 28 nanomètres de TSMC (HP) que pour l'ensemble des GPU précédents, contrairement à ce que nous aurions pu penser. Pour rappel, voici la liste des GPU conçus par Nvidia en 28 nanomètres : GK110 : 7.1 milliards de transistors pour 551 mm² GM204 : 5.2 milliards de transistors pour 398 mm² GK104 : 3.5 milliards de transistors pour 294 mm² GK106 : 2.5 milliards de transistors pour 214 mm² GM107 : 1.9 milliards de transistors pour 148 mm² GK107 : 1.3 milliards de transistors pour 118 mm² GK208 : 1.0 milliards de transistors pour 79 mm²  Le GM204 de Nvidia. Un petit calcul rapide montre que les 4 GPU les plus récents de Nvidia, à savoir les GK110, GK208, GM107 et GM204, affichent une densité de transistors un peu plus élevée que celle de ses premières puces fabriquées en 28 nm. Ceci peut s'expliquer par une petite évolution des règles de design et sur un effort d'optimisation plus poussé mais aussi par la proportion de mémoire SRAM (plus dense que les autres circuits) qui peut être plus élevée. Le GM204 se place à mi-chemin entre les GK110 et GK104 en termes de coûts de production, tout en ayant pour ambition de devancer le premier dans le cadre ludique. Le plein de ROPPour rappel, alors que les GPU Kepler reposaient sur des blocs fondamentaux appelés SMX (Streaming Multiprocessor), qui contiennent unités de calcul et autres unités de texturing, ceux-ci sont appelés SMM dans le cas de la génération Maxwell. Ils ont subi un régime assez drastique afin de les simplifier suffisamment pour pouvoir en augmenter significativement le nombre. Tout comme les SMX, les SMM sont organisés en petits groupes, appelés GPC (Graphics Processing Cluster). Chaque GPC inclus un moteur de rastérisation qui reçoit les triangles traités par les SMX/SMM, les découpes en pixels avec lesquels il forme de petits groupes qui sont renvoyés vers les SMX/SMM en vue de leur calcul. Voici une représentation visuelle du GM204 (notez que la représentation miniature des SMM est basée sur la version officielle qui n'est pas tout à fait correcte) : 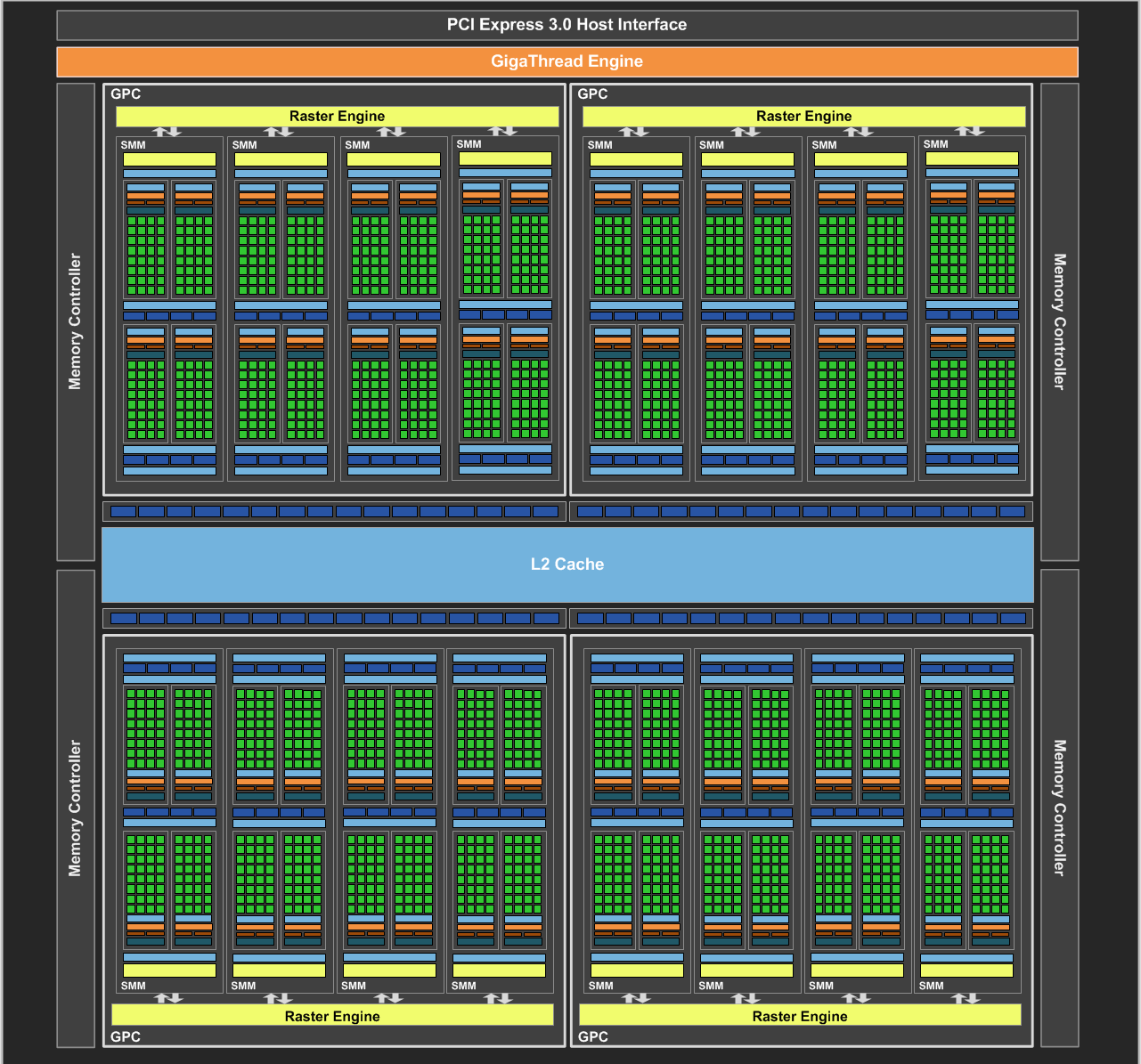 Voici pour comparaisons les spécificités de tous les GPU 28 nm de la marque : GK110 : 5 GPC, 15 SMX, 48 ROP, bus 384-bit, 1536 Ko de L2 GM204 : 4 GPC, 16 SMM, 64 ROP, bus 256-bit, 2048 Ko de L2 GK104 : 4 GPC, 8 SMX, 32 ROP, bus 256-bit, 512 Ko de L2 GK106 : 3 GPC, 5 SMX, 24 ROP, bus 192-bit, 384 Ko de L2 GM107 : 1 GPC, 5 SMM, 16 ROP, bus 128-bit, 2048 Ko de L2 GK107 : 1 GPC, 2 SMX, 16 ROP, bus 128-bit, 256 Ko de L2 GK208 : 1 GPC, 2 SMX, 8 ROP, bus 64-bit, 512 Ko de L2 Alors que le GM107 était passé à 1 Mo de L2 par partition mémoire de 64-bit, le GM204 s'en contente de 512 Ko, soit 2 Mo au total pour les 2 GPU Maxwell. Par contre, Nvidia passe de 8 à 16 ROP par partition mémoire, soit 64 au total. De quoi booster largement le fillrate, ce qui profite notamment aux plus hautes résolutions. Pour éviter d'être trop limité par le bus mémoire 256-bit et la bande passante qui y est liée, Nvidia a amélioré quelque peu ses techniques de compression sans perte du framebuffer. Plus spécifiquement, c'est le codage différentiel pour les couleurs, également appelé compression delta, qui progresse, exactement comme l'a fait AMD avec Tonga. Le principe de base consiste à ne pas enregistrer directement la couleur mais sa différence par rapport à une autre qui fait office de repère. Ce n'est bien entendu utile que quand l'écart entre deux couleurs est suffisamment faible, de manière à ce que cette information représente moins de bits que la couleur en elle-même. Ce type d'approche est exploitée depuis plusieurs générations de GPU mais les nouvelles puces Maxwell exploitent un algoritme plus flexible, capable de profiter de cette compression (2:1) dans plus de cas. 5.33 triangles et 64 pixels par cycleAvec 4 GPC, le GM204 est capable d'afficher jusqu'à 4 triangles par cycle, tout comme le GK104. Si ce débit brut ne progresse pas, en pratique Nvidia a apporté quelques améliorations pour faciliter un rendement plus élevé. Par ailleurs notez que chaque moteur de rastérisation est capable de générer jusqu'à 16 pixels par cycle contre 8 sur Kepler, de quoi pouvoir alimenter les 64 ROP. A noter que tout comme les SMX, les SMM sont capables de débiter 128 bits de couleur par cycle, ce qui équivaut à 4 pixels 32-bit ou à 2 pixels HDR. Avec 16 SMM, le débit de 64 pixels par cycle peut donc être soutenu. Par contre, dans le cas de la GeForce GTX 970 qui se contente d'un GM204 limité à 13 SMM, le débit de pixel maximum est de 52 par cycle. Du côté du traitement de la géométrie, les SMX sont capables de charger un vertex tous les deux cycles, mais ce débit a été réduit à un vertex tous les 3 cycles pour chaque SMM (ce qui correspond au chargement de 1 triangle par cycle quand le maillage des objets est optimisé). Comme nous le disions plus haut, le débit de triangles affichés à l'écran est de 4 par cycle et 12 SMM permettent donc de le maintenir (sauf si plus d'un SMM est désactivé par GPC). Par contre, dans le rendu 3D en temps réel, il n'y a pas que des triangles qui sont réellement rendus et affichés, nombreux sont ceux qui sont masqués parce qu'ils sont en dehors du champ de vision ou parce qu'ils tournent le dos à la caméra (c'est le cas statistiquement de la moitié des triangles qui composent personnages et autres objets). Le débit du culling, qui consiste à éjecter du pipeline de rendu ces triangles masqués, est donc important lui aussi. Cette opération est traitée au niveau des SMX/SMM avec le débit maximal de ceux-ci. Le SMX pouvait donc éjecter du rendu un triangle tous les 2 cycles, contre un tous les 3 cycles pour le SMM. Une GTX 980, avec 16 SMM peut ainsi traiter jusqu'à 5.33 triangles/cycle quand ceux-ci ne poursuivent pas leur chemin jusqu'au rendu final, contre 4.33 triangle/cycle pour la GTX 970. Page 3 - GM204 : le SMM et les nouveautés Le SMM en détailPour rappel, Nvidia a revu l'organisation interne des SMM de manière à augmenter leur rendement aussi bien énergétique que par unité de surface. Pour cela, le ratio d'unités de calcul par unité de texturing augmente, une évolution logique depuis quelques années qui permet de s'adapter aux algorithmes de rendu graphique de plus en plus complexes sur le plan arithmétique. Ensuite, Nvidia se sépare de certains blocs d'unités de calcul qui en pratique étaient peu utilisés, ce qui fait mécaniquement augmenter le rendement des unités restantes. Au final nous passons de 24 flops par unité de texturing sur Kepler (excepté GK208) à 32 flops par unité de texturing sur Maxwell, avec, qui plus est, une meilleure utilisation de cette puissance de calcul. Pour représenter cela plus en détail, nous avons modifié des diagrammes d'architecture de Nvidia de façon à nous rapprocher de la réalité, au mieux de nos connaissances actuelles des différentes architectures : 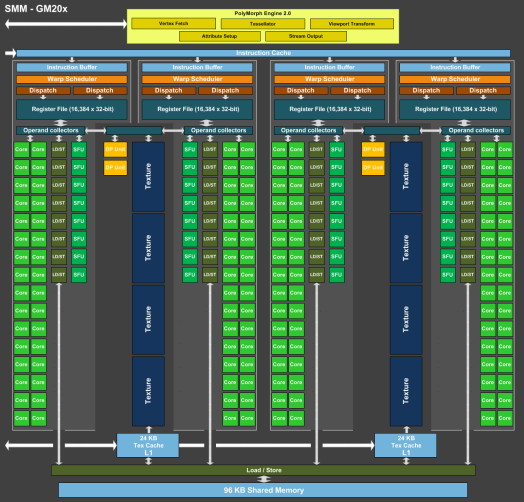
En plus grand : Comme le montrent ces illustrations, les SMX et les SMM sont subdivisés en 4 partitions. Nvidia a en réalité simplifié le SMM sur 2 points principaux. Premièrement, les blocs de 4 unités de texturing ont été mis en commun par paire de partitions, comme c'était déjà le cas sur le GK208 et le GK20A (Tegra K1) et contrairement aux autres GPU Kepler pour lesquels chaque partition d'un SMX dispose de son propre bloc. C'est ce point qui fait augmenter automatiquement le ratio d'unités de calcul par unité de texturing. Ces dernières sont gourmandes notamment parce qu'elles ont besoin de voies d'accès royales au sous-système mémoire du GPU. Exploiter les 50% d'unités de calcul principales supplémentaires s'est avéré difficile sur Kepler, probablement parce que le fichier registre n'offre pas suffisamment de bande passante et/ou de flexibilité au niveau des accès à ses différentes banques. Il est dès lors difficile de pouvoir obtenir toutes les opérandes nécessaires pour alimenter l'ensemble de ces unités, et en pratique elles le sont rarement. D'après les chiffres communiqués par Nvidia, ces 50% d'unités de calcul supplémentaires, qui permettent d'afficher une puissance de calcul brute en nette hausse, n'apportent qu'un gain pratique d'un peu plus de 10%. C'est donc logiquement que Nvidia a supprimé ces unités supplémentaires des SMM. Le travail de l'ordonnanceur et du compilateur s'en trouve simplifié, ce qui permet des gains énergétiques du côté du premier et la possibilité de pousser plus loin certaines optimisations du côté du second. Au final, en passant du SMX au SMM nettement plus petit, Nvidia a donc supprimé la moitié des unités de texturing, la moitié des unités de calcul 64-bit et un tiers des unités de calcul 32-bit. Malgré cela, en ne conservant que le plus utile aux charges modernes, le SMM conserve des performances proches de celles du SMX, de l'ordre de 90% selon Nvidia. Bien entendu, en jeu et quand le texturing prend beaucoup d'importance, ce nouveau SMM pourra être amené à se contenter de 50% des performances du SMX. Avec la seconde génération Maxwell, Nvidia a apporté de petites modifications pour rapprocher encore plus les performances d'un SMM de celles d'un SMX. Par rapport au GM107, le cache des unités de texturing, qui fait aussi office de cache L1 pour certains accès mémoire (il ne s'agit pas d'un cache en lecture/écriture polyvalent), passe de 12 Ko à 24 Ko par groupe de 4. Par ailleurs, la mémoire partagée progresse de 64 à 96 Ko. En pratique, cela ne veut pas dire que les tâches de type calcul (CUDA ou compute shaders) pourront utiliser plus de mémoire. Celle-ci étant attribuée par groupe de threads, cela signifie que plus de ces groupes pourront résider par SMM, ce qui donne plus de possibilités pour maximiser son rendement. Quelques nouveautésAvec la seconde génération Maxwell, Nvidia a eu un petit peu plus de temps pour implémenter de nouvelles fonctionnalités. Elles s'articulent principalement autour de la mise à jour des moteurs de rastérisation, ces unités chargées de la découpe des triangles en pixels. Une limitation à leur niveau (absence de support de la fonction Target Independant Rasterization) empêchait jusqu'ici Nvidia de supporter le niveau de fonctionnalité matériel 11_1 de Direct3D bien que la plupart de ses autres spécificités soient bien supportées sur les GPU Kepler et Maxwell de première génération. Nvidia n'a pas simplement ajouté ce qui manquait au support du niveau 11_1 mais a fait en sorte de faire le maximum pour s'assurer du support du prochain niveau, dont le numéro n'est pas encore connu. Celui-ci sera supporté par Direct3D 12 ainsi que par Direct3D 11.3 qui apportera l'équivalent sur l'API classique de Microsoft, tous les développeurs n'étant pas prêts à migrer vers la nouvelle API de bas niveau. 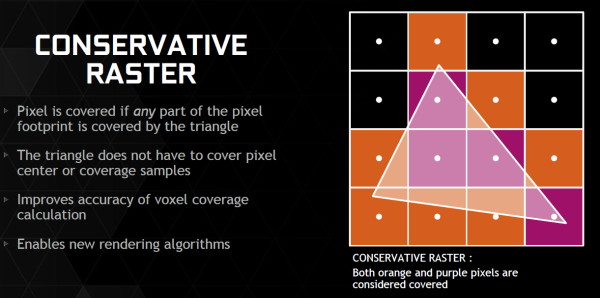 Parmi les nouvelles fonctionnalités de ces futures API, citons la Conservative Rasterization qui permet de vérifier si une primitive est présente dans n'importe quelle petite partie de la zone couverte par un pixel et pas simplement présente en son centre. De quoi pouvoir mieux évaluer sa couverture, ce qui est nécessaire pour certains algorithmes.  Nvidia supporte également les Rasterized Ordered Views et les Volume Tiled Resources. La première fonctionnalité permet de contrôler le respect de l'ordre de rendu des différents éléments de la scène, ce qui est par exemple nécessaire lorsqu'il y a plusieurs niveaux de transparence à respecter (Order Independant Transparency). La seconde transpose dans le monde du voxel le principe des tiled resources ("megatextures"). 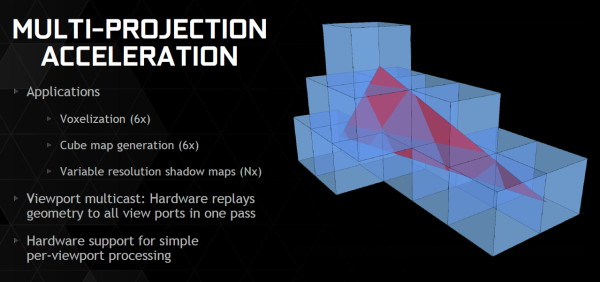 Nvidia combine d'ailleurs le support des Tiled Resources et de la Conservative Rasterization avec quelques petites améliorations matérielles de son cru (notamment l'accélération des projections multiples) pour accélérer efficacement un nouveau type de rendu : le VXGI pour VoXel Global Illumination. Ce nouvel algorithme développé en interne permet d'appliquer un effet de GI en temps réel, sans avoir besoin de le précalculer en amont. Nous tacherons de revenir plus en détails à ce sujet plus tard.  Nvidia s'attend à ce que les petites modifications apportées à son architecture pour l'accélérer se généralisent d'ici quelques temps, autant chez la concurrence qu'au niveau des API graphiques. En attendant, un module VXGI est en développement pour l'Unreal Engine 4 et il sera proposé aux développeurs dès la fin de l'année. Tant qu'à modifier les moteurs de rastérisation sur plusieurs points, Nvidia en a profité pour améliorer leur flexibilité par rapport aux grilles d'échantillonnage utilisées avec l'antialiasing. Ils sont dorénavant capables de faire varier la position des samples d'une image à l'autre et ou d'utiliser une grille multi-pixels. Cette seconde possibilité permet de répartir différent les samples d'un pixel à l'autre pour éviter un schéma uniforme moins efficace. Nvidia n'exploite pas encore cette possibilité.  Faire varier la position des samples, c'est déjà ce que faisais ATI et AMD avec le Temporal AA. Et c'est ce que va faire Nvidia avec le MFAA qui sera disponible d'ici quelques temps via de nouveaux pilotes. Nvidia ne s'est cependant pas contenté de recopier ce principe mais y a ajouté un filtre plus avancé qui combine downsampling et composante temporale basée sur l'image précédente. De quoi se rapprocher de la qualité du MSAA 4x avec seulement du MSAA 2x avec alternance de la position des samples (MFAA 2x), selon Nvidia. Il faudra vérifier en pratique ce qu'il en est, notamment en mouvement. Nouveautés vidéoA noter également le passage au HDMI 2.0, qui apporte une hausse notable de bande passante afin de pouvoir gérer à l'instar du DisplayPort 1.2 les écrans 4K à 60 Hz sans avoir recours à un sous échantillonnage des informations de couleurs comme c'est le cas en HDMI 1.4a. A noter que chacun des 4 contrôleurs d'affichage est désormais capable de gérer plusieurs flux MST de même résolution, ce qui permet par exemple d'utiliser un seul contrôleur pour adresser en DisplayPort un écran 4K "tiled" composé de deux dalles. Cela permet de gérer jusqu'à 4 écrans de ce type, à condition de disposer de 4 sorties DisplayPort (en pratique les fabricants en intègrent jusqu'à 3 à ce jour), contre 2 sur les cartes Nvidia précédentes. 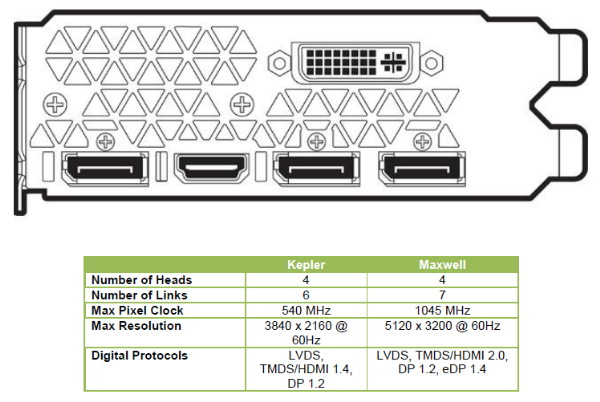 Côté vidéo et H.265, le GM204 profite du décodage hybride introduit avec les GTX 750/750 Ti et depuis étendu aux Kepler par les pilotes. Il s'agit en fait de réutiliser quand c'est possible certaines parties du décodeur matériel H.264 pour le décodage H.265, et quand ça ne l'est pas d'utiliser un décodage logiciel faisant appel aux unités de calcul du GPU. Le GM204 ne dispose donc pas encore d'un décodeur H.265 complet, qui sera plus efficace côté énergétique, mais chose étonnante il intègre par contre un encodeur H.265 ! Celui-ci n'est pas encore utilisable via des pilotes, mais devrait profiter à terme aux applications de Streaming tel que ShadowPlay. Ce dernier profite par contre déjà d'autres nouveautés introduites dans NVENC, tel que l'encodage en 1440p et même en 2160p à 60 fps jusqu'à 130 Mbps alors qu'on était auparavant limité au 1080p à 60 fps et 50 Mbps. Page 4 - GM204 : 3.5 Go + 0.5 Go pour la GTX 970 GM204 : 3.5 Go + 0.5 Go pour la GTX 970Un peu plus de 4 mois après son lancement, les spécifications de la GTX 970 ont été rectifiées et de nouveaux détails ont été dévoilés par Nvidia sur la gestion de sa mémoire. Des détails que nous allons explorer sur cette page. Une partition mémoire plus flexibleLes GPU Kepler et précédents embarquaient un certain nombre de partitions mémoires, souvent résumées à "contrôleurs mémoire de 64-bit". Ces partitions intégraient les interfaces mémoire vers deux puces GDDR5, soit un accès de 64-bit, une certaine quantité de cache L2 et un certain nombre de ROP. Les ROP sont pour rappel ces unités chargées de piloter les écritures de pixels en mémoire, d'effectuer le mélange de couleurs lorsqu'une surface transparente est dessinée par-dessus une autre surface, et de chercher à compresser (sans perte) tout ce qui peut l'être. Avec Maxwell de seconde génération, Nvidia a revu quelque peu l'architecture de ses partitions mémoire, qui ont globalement été subdivisées en deux. Chacune inclus ainsi 2 interfaces GDDR5 32-bit, pilotées chacune par un sous-contrôleur indépendant, deux blocs de 256 Ko de L2 et deux blocs de 8 ROP. Soit 64-bit, 512 Ko et 16 ROP au total. 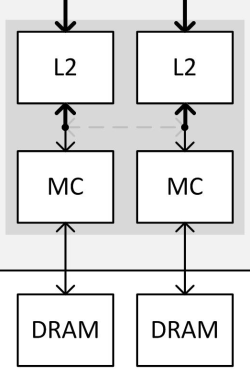 Sur ce schéma, le bloc L2 représente 256 Ko de cache L2 et 8 ROP. Le bloc MC représente un sous-contrôleur 32-bit et l'interface GDDR5. Si Nvidia a subdivisé en deux les partitions mémoire, c'est pour avoir plus de flexibilité lors de la configuration des puces. Des blocs entiers de celles-ci peuvent être désactivés, soit pour en réutiliser lorsqu'elles souffrent de petits défauts de fabrication, soit pour des raisons de segmentations. Avec le GM204, au lieu de devoir désactiver un contrôleur mémoire de 64-bit avec 512 Ko de L2 et 16 ROP, Nvidia est dorénavant capable de ne désactiver qu'un contrôleur de 32-bit avec 256 Ko et 8 ROP. Une configuration qui gagne ainsi en finesse. Mais ce n'est pas tout. 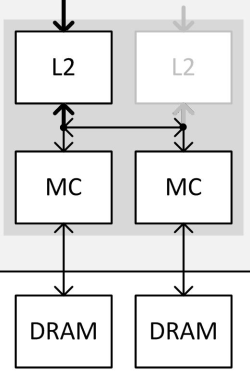 Un petit bus a été implémenté pour rediriger le trafic d'un sous-contrôleur de 32-bit vers le bloc cache L2 de son voisin. Quand il est activé, un unique bloc L2 est ainsi capable de piloter les deux sous-contrôleurs mémoire 32-bit de la partition. L'intérêt de l'opération est évident pour Nvidia : ne pas avoir à réduire la largeur de l'interface mémoire, soit sa bande passante théorique maximale et la quantité de mémoire à laquelle elle peut être associée. Nvidia nous a précisé que ce bus croisé entre les L2 et les MC n'a été implémenté qu'à cet effet, ce qui démontre à quel point proposer une carte graphique 256-bit / 4 Go a de la valeur sur le plan commercial par rapport à une solution de type 224-bit / 3.5 Go. La GeForce GTX 970 est la première carte graphique équipée d'un GPU qui exploite cette nouvelle flexibilité. Malheureusement, le doublement de la charge sur un seul ensemble L2 + ROP n'est pas sans conséquences sur le plan des performances comme vous pouvez vous en douter. Nvidia a bien prévu un accès plus large au L2 qui lui permet d'encaisser le trafic de 2 sous-contrôleurs de 32-bit mais ce n'est vrai que dans certains cas. Pour ce cas de figure, Nvidia a ainsi implémenté dans ses pilotes un mode spécial de gestion de la mémoire. Les accès mémoire plus en détailPour bien comprendre ce qu'il se passe, quelques détails de plus sont nécessaires. Les interfaces mémoire et leurs contrôleurs sont très complexes, et ce qui suit reste évidemment une simplification. A chaque cycle, chaque bloc L2 est capable de soumettre à son contrôleur mémoire jusqu'à 2 requêtes de lectures de 32 octets ainsi que 2 autres requêtes d'écriture de 32 octets, soit 4 requêtes au total. Parmi ces requêtes (et probablement d'autres qui n'ont pas encore été exécutées), le contrôleur en choisit une, celle qui permet une utilisation optimale des accès mémoire, et l'exécute. Une seule requête de 32 octets par cycle peut être exécutée par chaque contrôleur mémoire. Précisons que le bloc L2 fonctionne suivant un domaine de fréquence propre, différent de la fréquence GPU classique et de la fréquence de l'interface mémoire. Nvidia ne nous a pas communiqué sa fréquence mais nous a indiqué qu'elle était bien supérieure à 875 MHz, soit à la moitié de celle de l'interface mémoire qui est de 1750 MHz sur les GeForce GTX 980 et 970. Une puce GDDR5 32-bit débite des morceaux de 32 octets tous les deux cycles (à 1750 MHz), la fréquence du bloc L2 est donc au moins suffisante pour encaisser le flux de données. Le nombre de requêtes soumises par cycle par un bloc L2 étant bien plus important que le nombre de requêtes exécutables par un contrôleur mémoire, chaque L2 est en théorie capable de piloter simultanément deux contrôleurs mémoires. Par contre, d'après les explications de Nvidia, qui manquent de détails sur ce point, des requêtes d'un même type ne pourraient pas être envoyées vers deux contrôleurs différents. Par exemple il ne serait pas possible de demander une requête en lecture à chacun. Le seul moyen d'exploiter ces deux contrôleurs en parallèle serait donc d'envoyer des demandes de lectures à l'un et d'écritures à l'autre. L'organisation de la mémoireLes données sont en règle générale placées en mémoire de manière à profiter de toute l'étendue de l'interface et donc d'une bande passante maximale. L'espace mémoire est réparti équitablement à travers tous les contrôleurs mémoire. Par exemple, chaque contrôleur mémoire ne s'occupe pas de textures particulières, mais chaque texture est répartie sur l'ensemble des contrôleurs mémoire. Si vous combinez ceci avec la limitation décrite dans le paragraphe précédent, vous comprendrez qu'un problème va se poser. Si une donnée est répartie sur l'ensemble de la mémoire alors qu'une partie de celle-ci ne peut être lue en même temps qu'une autre, cela implique qu'un large accès devra se faire en deux temps. De quoi diviser la bande passante par deux dans le pire des cas. Un pire des cas qui aurait probablement été courant et aurait fortement impacté les performances de la GeForce GTX 970. Pour éviter ce problème, Nvidia divise l'espace mémoire en deux. Le principal est interfacé à 224-bit et comprend 3.5 Go de mémoire. Les données sont principalement réparties à travers cet espace mémoire. Un second espace mémoire interfacé en 32-bit et doté de 0.5 Go de mémoire, prend place à côté et n'est exploité que quand l'espace principal est rempli. Si l'occupation mémoire est inférieure à 3.5 Go, seul l'espace principal est utilisé par le GPU, ce qui évite de rencontrer un conflit dans les accès qui pourrait pénaliser lourdement la bande passante pratique. Par contre cela revient à limiter l'interface mémoire de manière ferme à 224-bit et à réduire ainsi de 12.5% la bande passante disponible. Lorsque l'occupation mémoire dépasse 3.5 Go, les 512 Mo supplémentaires font en quelque sorte office de réserve de mémoire de secours, avant de devoir passer par le bus PCI Express pour aller puiser dans la mémoire centrale. Ces accès mémoire sont beaucoup plus lents vu que l'interface chute de 224-bit à 32-bit. Dans certains cas des accès peuvent se faire en parallèle entre les deux espaces mémoires (lecture dans l'un, écriture dans l'autre), mais de toute évidence c'est suffisamment rare pour que ce second espace mémoire ne soit exploité qu'en dernier recours par Nvidia soit quand ses faibles performances restent préférables à celles de la mémoire centrale. En d'autres termes, Nvidia n'estime pas qu'utiliser ce second espace mémoire permet d'obtenir en pratique une bande passante supérieure à celle d'un bus 224-bit. Nous devons donc considérer la GeForce GTX 970 comme une carte graphique équipée d'un bus 224-bit avec 3.5 Go de mémoire rapide et 0.5 Go de mémoire lente. C'est similaire à ce qui se passait avec les GPU Fermi et Kepler associés à une mémoire asymétrique (puces de mémoire de plus grosse capacité sur certains contrôleurs), si ce n'est que l'asymétrie n'est pas présente physiquement sur le PCB de la carte graphique. L'avantage principal est de permettre à Nvidia de pouvoir mettre en avant un bus de 256-bit. Le comportement de la GTX 970 aurait probablement été similaire, voire identique, si son interface mémoire était physiquement de 224-bit mais avec un module mémoire de 1 Go contre 512 Mo pour les 6 autres (au lieu de 8 modules de 512 Mo interfacés en 256-bit). Un exercice d'équilibristes pour les pilotes et l'OSIl revient aux pilotes à l'OS de gérer tout cela au mieux, encore une fois, à peu près de la même manière que pour les cartes précédentes équipées d'une mémoire asymétrique (GTX 660 par exemple). Cela n'a pas été un gros problème pour ces cartes et il n'y a pas de raison que la GTX 970 en souffre plus. Mais il est évident que l'efficacité et les performances pourront être moindres quand la quantité de mémoire allouée et réellement utilisée s'approche de la limite. Il est important de rappeler une fois de plus qu'il faut faire la distinction entre mémoire allouée et mémoire réellement utile. Tant qu'il reste de la place en mémoire, certaines données qui ne sont plus utilisées mais l'ont été auparavant, vont rester en mémoire. Un principe qui permet de disposer de celles-ci directement par la suite au cas où cela serait nécessaire. Mais effacer des textures non-utilisées et les retransférer par la suite n'est pas un gros problème, à moins bien entendu que cela ne se fasse de façon incessante. Avant d'utiliser le second espace mémoire de 0.5 Go, les pilotes et l'OS font d'abord en sorte d'essayer, plus ou moins agressivement, de faire de la place dans l'espace principal de 3.5 Go. C'est pour cette raison que dans certains cas il est possible d'avoir l'impression que la quantité de mémoire plafonne à 3.5 Go. C'est tout simplement parce que Nvidia fait en sorte, si possible, de n'utiliser que la mémoire la plus performante. Si une quantité supérieure à 3.5 Go est estimée utile, alors les 512 Mo supplémentaires sont exploités puisqu'ils restent plus rapides que la mémoire centrale, tant en termes de bande passante que de latence. Il revient dans ces cas-là aux pilotes à essayer de faire en sorte que les données les plus importantes sur le plan des performances ne se retrouvent pas dans la partie lente de la mémoire. Un système d'heuristiques générales est utilisé pour aider le pilote à opter pour une bonne stratégie et des optimisations spécifiques peuvent être implémentées pour certains jeux et certaines conditions. Nvidia n'a pas communiqué de détails sur la façon dont le pilote gère tout cela en pratique. Nous avons par contre pu observer qu'en SLI, le pilote essaye plus agressivement de ne pas dépasser 3.5 Go. Globalement, il nous a été difficile de prendre en défaut la GTX 970 et nous ne prenons pas trop de risques en concluant que les pilotes s'en sortent très bien dans les situations classiques, voire difficiles. Il est par contre impossible de garantir que ce sera toujours le cas et il est certain qu'une GTX 970 ne peut être aussi efficace qu'une GTX 980 lorsque 4 Go de mémoire sont utiles. Page 5 - Performances théoriques : pixels Performances texturingNous avons mesuré les performances lors de l'accès aux textures avec filtrage bilinéaire activé et ce, pour différents formats : en 32 bits classique (8x INT8), en 64 bits "HDR" (4x FP16), en 128 bits (4x FP32), en profondeur de 32 bits (D32F) et en FP10, un format HDR introduit par DirectX 10 qui permet de stocker des textures HDR en 32 bits avec quelques compromis. Les GeForce GTX sont capables de filtrer les textures FP16 à pleine vitesse contrairement aux Radeon, ce qui leur donne un avantage considérable sur ce point. Notez que dans ce test, les GeForce à base de GK104/106/107 ont du mal à atteindre leur débit maximal alors que le GM107 et le GM204 en sont plus proches, une efficacité en hausse des unités de texturing qui est probablement liée au fait que leur proportion réduite permet de plus facilement les saturer. Le GM204 est capable d'accéder aux surfaces de type D32F aussi efficacement que les autres formats, comme les GPU Radeon, mais contrairement aux GPU GeForce précédents. FillrateNous avons mesuré le fillrate sans et puis avec blending, et ce avec différents formats de données : [ Standard ] [ Avec Blending ] Le fillrate est l'un des points forts des GPU Hawaii qui intègre pas moins de 64 ROP chargés d'écrire les pixels en mémoire. Tout comme pour Bonaire et Tonga, ces ROP profitent qui plus est d'une efficacité supérieure avec blending. De quoi permettre un gain massif dans un exemple aussi simple que notre test qui tombe pour ces GPU dans le cas idéal. À l'inverse, le fillrate peut être vu comme le point faible du GK110. Ainsi, il n'augmente que très peu par rapport au GK104. La limitation se situe en fait au niveau des rasterizers : le GK110 en dispose de 5 contre 4 pour le GK104. Chacun de ceux-ci étant capable de générer 8 pixels, le GK110 est en réalité limité à 40 pixels par cycle contre 32 pour le GK104. La différence de fréquence réduit encore cet écart. Les GeForce depuis Kepler sont enfin capables de transférer les formats FP10/11 et RGB9E5 à pleine vitesse vers les ROP, mais le blending de ces formats se fait toujours à demi vitesse. Si les GeForce et les Radeon sont capables de traiter le FP32 simple canal à pleine vitesse sans blending, seules ces dernières conservent ce débit avec blending. Bien que les Radeon 7800 disposent du même nombre de ROP que les Radeon HD 7900, leur bande passante mémoire inférieure ne leur permet pas de maximiser leur utilisation avec blending ainsi qu'en FP16 et FP32 sans blending. En doublant le nombre de ROP en passant du GK107 au GM107, et avec une architecture qui permet de les alimenter à pleine vitesse tant au niveau du rasterizers que des SMM, ce premier GPU Maxwell voit son débit de pixels progresser nettement, excepté en FP32 avec blending, mode dans lequel la bande passante semble être le facteur limitant pour tous les GPU Nvidia. Avec 64 ROP, le GM204 est ici le GPU Nvidia le plus performant. Par contre dans sa version GTX 970, en principe limitée à 52 pixels par cycle au lieu de 64, l'impact est plus important que prévu. Nous ne savons pas pourquoi et pouvons juste supposer qu'il est plus difficile de s'approcher des maximums théoriques que la configuration du GPU est déséquilibrée. Page 6 - Performances théoriques : géométrie Débit de trianglesÉtant donné les différences architecturales des GPU récents au niveau du traitement de la géométrie, nous nous sommes évidemment penchés de plus près sur le sujet. Tout d'abord nous avons observé les débits de triangles dans deux cas de figure : quand tous les triangles sont affichés et quand ils sont tous rejetés (parce qu'ils tournent le dos à la caméra) : Quand les triangles peuvent être éjectés du rendu, les GeForce GTX 780 Ti, GTX 980, GTX 770 et GTX 660 profitent pleinement de leur capacité de prise en charge de 7.5, 5.33, 4 ou 2.5 triangles par cycle pour se démarquer des Radeon. Une fois que les triangles doivent être rendus, le débit maximal théorique des GeForce chute sur certains modèles alors que leur efficacité est plus généralement en baisse, peut-être parce que ces GPU sont engorgés à un endroit ou à un autre, ou encore parce que leurs performances ont été réduites artificiellement pour différencier les Quadro des GeForce. Quoi qu'il en soit, cela ne semble plus être un problème sur le GM204 qui repasse devant Hawaii sur ce point. Ensuite nous avons effectué un test similaire mais en utilisant la tessellation : Avec les GeForce GTX Kepler, Nvidia réaffirmait sa supériorité lorsqu'il s'agit de traiter un nombre important de petits triangles générés par un niveau de tessellation élevé. Cet avantage ne concerne par contre que le haut de gamme. Le premier GPU Maxwell de première génération n'en profite pas, ses performances se situant quelque peu derrière celles de Bonaire, tout en représentant malgré tout un net gain par rapport au GK107. Le GM204 Maxwell de seconde génération renforce l'avantage de Nvidia lorsque les triangles ne sont pas affichés mais peine à se démarquer du GK110 quand ils doivent être affichés. Les Radeon HD 7900/ R9 280X ne se démarquent pas des Radeon HD 7800 et de la Radeon HD 7790 qui disposent du même nombre d'unités fixes dédiées à cette tâche. L'architecture des Radeon fait qu'elles peuvent être engorgées plus facilement par la quantité de données générées, ce qui réduit drastiquement leur débit dans ce cas. AMD fait évoluer progressivement les différents buffers liés à la tessellation, et la manière de les utiliser, pour éviter autant que possible de se trouver dans ce cas. Les derniers pilotes apportent d'ailleurs des gains significatifs à ce niveau pour l'ensemble des GPU GCN. Hawaii et Tonga affichent un gain important au niveau du débit brut, soit lorsque les triangles générés ne doivent pas être rendus. Lorsque c'est le cas, ils se contentent par contre dans notre test d'une progression très légère. Notre test étant relativement lourd en termes de données générées par triangles, nous supposons que ces GPU souffrent d'un embouteillage à un endroit ou à un autre, peut-être au niveau du canal de transfert de ces données vers les contrôleurs mémoire (mais pas directement au niveau de la bande passante globale qui est loin d'être saturée). Page 7 - Spécifications, la GeForce GTX 980 de référence Spécifications 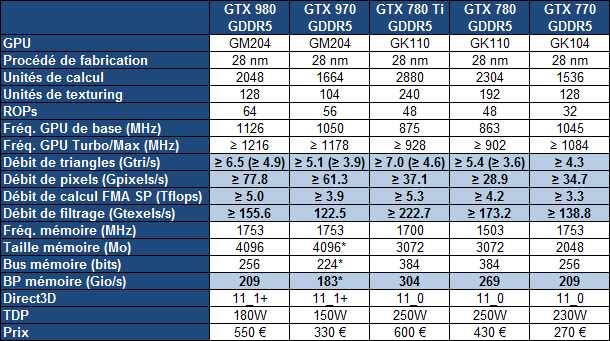 *la GTX 970 est équipée d'une configuration mémoire particulière de type 3.5 Go + 0.5 Go Rappelons tout d'abord que sur la majorité des cartes graphiques Nvidia depuis la génération Kepler, la fréquence turbo maximale varie d'un échantillon à l'autre. Grossièrement, Nvidia applique un overclocking automatique sur les GPU qui sont capables de tenir la fréquence officielle à une tension plus faible que le maximum spécifié. La GeForce GTX 980 embarque un GPU GM204 en configuration complète, cadencé à une fréquence relativement haute, de quoi lui permettre d'afficher une puissance de calcul presque identique à celle de la GTX 780 Ti. Il faut par ailleurs garder en tête que cette puissance de calcul est plus facilement pleinement exploitable sur Maxwell que sur Kepler. La puissance géométrique est similaire mais la GTX 980 a un net avantage au niveau du fillrate alors que la GTX 780 Ti domine sur le plan du texturing et de la bande passante mémoire. La GeForce GTX 970 se contente d'un GPU GM204 amputé de quelques unités : 3 SMM (384 unités de calcul) et 8 ROP ont été désactivés, un dernier détail que Nvidia avait au départ oublié de communiquer. Il n'est pas sans conséquences puisqu'il impacte directement le fonctionnement de la mémoire comme expliqué dans la page dédiée à cette caractéristique. La GTX 970 4 Go se comporte ainsi comme une carte graphique équipée d'une mémoire rapide de 3.5 Go, interfacée en 224-bit, complété par 512 Mo de mémoire lente, interfacée en 32-bit. C'est similaire à ce qui se passe par exemple pour une GTX 660 2 Go, équipée de 1.5 de mémoire rapide, 192-bit, et de 512 Mo de plus de mémoire lente, 64-bit. Au final, les spécifications de référence correspondent à 4 Go de mémoire GDDR5 autant pour la GTX 970 que pour la GTX 980, une quantité de mémoire en hausse pour coller à l'air du temps. Dans sa documentation à destination de la presse, Nvidia communique pour la GTX 980 un TDP (thermal design power) de 165W et pour la GTX 970 un TDP de 145W. Malheureusement il s'agit de la même astuce que celle utilisée par AMD avec le TBP (typical board power) de la Radeon R9 285 pour présenter un chiffre raboté artificiellement, si ce n'est que Nvidia ne s'embarrasse pas de cette subtilité alphabétique. Les vrais TDP sont de 180W et 150W (plus consommation en 3.3V) pour les GTX 980 et GTX 970. La GTX 980 de référencePour ce test, Nvidia nous a fait parvenir une GeForce GTX 980 de référence et nous a indiqué qu'il n'y aurait pas de GTX 970 de référence mais uniquement des cartes personnalisées.       La GeForce GTX 980 de référence reprend le même design que les autres GeForce haut de gamme précédente. Nvidia exploite des matériaux de qualité et a optimisé autant que possible les divers éléments du ventirad. Le PCB, prévu pour monter jusqu'à 6 phases, s'en contente de 4 pour alimenter le GM204 dont la TDP est limité à 180W. Tout comme sur la GTX Titan Z, Nvidia explique avoir prévu ses étages d'alimentations pour être capables de faire du load balancing entre les différentes sources de 12V. Par exemple, si le canal 12V du bus PCI Express est saturé alors que la limite globale ne l'est pas, la carte fera en sorte de tirer une proportion plus importante du courant via l'un des 2 connecteurs PCI Express 6 broches. Au niveau des sorties, Nvidia propose 3 DP, 1 HDMI et 1 DVI, avec une grille revue pour profiter au maximum de l'espace restant.  Une backplate est fixée à l'arrière de la carte mais Nvidia a prévu la possibilité d'un détacher une petite partie. De quoi permettre de laisser passer le flux d'air nécessaire au niveau du ventilateur lorsque deux cartes sont collées l'une à l'autre en SLI.  A noter que Nvidia a simplifié quelque peu le radiateur de son système de refroidissement. Alors qu'il était équipé d'une chambre à vapeur, par exemple sur les GTX 780 Ti, celle-ci passe à la trappe. Dans la base en aluminium, 3 petits caloducs plats font en sorte d'optimiser quelque peu la dispersion de la chaleur. Quand bien même le GPU GM204 est très efficace sur le plan énergétique, était-ce bien nécessaire de chercher à économiser 2$ sur sur le ventirad d'une carte proposée à 550 ? Page 8 - Gigabyte GTX 980 & 970 G1 Gaming Gigabyte a pu nous faire parvenir des échantillons de ses GeForce GTX 980 et GTX 970 G1 Gaming. Les deux cartes sont similaires mais pourtant bel et bien différentes tant au niveau du ventirad que du PCB. Elles mesurent 30cm de long, le radiateur et la coque dépassant de 3cm à l'arrière du PCB.    Le GTX 970 G1 Gaming se contente d'un ventirad WindForce 3 classique, ni en version "450W", ni "600W". Il est équipé de 4 caloducs de 6mm de diamètre. Le PCB exploite une alimentation GPU à 6 phases et l'ensemble est suffisamment costaud pour passer la limite de consommation de 150 à 250W. L'overclocking d'usine pousse les fréquences de 1050/1178 à 1178/1329 (base/turbo officiel) avec un turbo maximal réel de 1354 sur notre exemplaire.    La GTX 980 G1 Gaming reprend le WindForce 3 "600W", plus musclé avec 5 caloducs de 8mm et un de 6mm. Pour être certain que le GPU ne soit jamais limité, Gigabyte a poussé la limite de consommation de 180 à 300W et le nombre de phases qui alimentent le GPU à 8. Même sous Furmark la fréquence maximale est préservée ! Celle-ci profite d'un overclocking pour passer de 1126/1216 (base/turbo officiel) à 1228/1329 avec une fréquence maximale réelle de 1380 MHz sur notre échantillon. Ces deux cartes permettent au GPU de maintenir une fréquence maximale dans toutes les situations ou presque. Par contre la consommation peut augmenter fortement ainsi que les nuisances sonores, malgré l'utilisation de ventirads performants. Il aurait été intéressant que Gigabyte propose un mode silence, qui limite un petit peu la gourmandise du GM204, d'autant plus que les gains deviennent minimes au-delà de 1300 MHz, la bande passante mémoire ayant tendance à devenir le facteur limitant. Or la mémoire n'est pas overclockée et, à 1750 MHz, ne dispose pas de beaucoup de marge.  Sur ses deux cartes, Gigabyte a revu la connectique en y ajoutant une sortie DVI de plus, profitant du fait que son ventirad n'a que faire d'une grille d'extraction. Page 9 - Consommation, efficacité énergétique ConsommationNous avons utilisé le protocole de test qui nous permet de mesurer la consommation de la carte graphique seule. Nous avons effectué ces mesures au repos sur le bureau Windows 7 et en veille écran.. Pour la charge, nous testons d'une part Anno 2070 en mode de qualité maximale qui représente un jeu très lourd et d'autre part Battlefield 4 en mode Ultra qui représente un jeu moins lourd. Ces mesures affichent directement la couleur : le GM204 est relativement peu gourmand. Dans nos conditions de test, avec température ambiante à 26 °C, le ventirad de référence de la GTX 980 est capable d'encaisser une charge qui correspond à une consommation totale de la carte de +/- 150W. Elle augmente légèrement dans Anno, la fréquence de base étant atteinte, ce qui fait que GPU Boost laisse la température s'apprécier légèrement au-delà de la limite de 79 °C. Sans aucune limite de consommation, les cartes de Gigabyte tournent à pleine vitesse et leur consommation grimpe dans Anno. Bien que ces données soient approximatives, compte tenu de la variation entre échantillons d'un même modèle, nous avons mis en relation ces mesures de consommation avec les performances, en retenant des fps par 100W pour que les données soient plus lisibles, de quoi donner une idée globale sur le rendement énergétique de toutes ces cartes : [ Battlefield 4 ] [ Anno 2070 ] L'efficacité énergétique des GeForce GTX 900 fait un bond en avant, dépassant même la GTX 750 Ti dans le cas de la GTX 980. Celle-ci est 2x plus efficace que la Radeon R9 290X sous BF4, et 1.8x sous Anno ! Page 10 - Bruit et températures Nuisances sonoresNous plaçons les cartes dans un boîtier Cooler Master RC-690 II Advanced et mesurons le bruit d'une part au repos et d'autre part en charge sous le test1 de 3DMark11. Un SSD est utilisé et tous les ventilateurs du boîtier ainsi que celui du CPU sont coupés pour la mesure. Le sonomètre est placé à 60cm du boîtier fermé et le niveau de bruit ambiant se situe à moins de 20 dBA, ce qui est la limite de sensibilité pour laquelle il est certifié et calibré. Nous en avons profité pour tester la GTX 980 de référence en mode "Uber", c'est-à-dire en poussant ses limites de consommation et de température à leur maximum de manière à ce qu'elle maintienne la fréquence turbo maximale et d'observer comment se comporte le ventirad dans ces conditions. Avec une consommation réduite, la GTX 980 de référence aurait pu être plus discrète que les GTX 780 et 770, mais ce n'est pas le cas, Nvidia ayant décidé de passer à un radiateur moins efficace pour son refroidissement. Les nuisances sonores restent cependant tout à fait raisonnables. En mode "Uber" par contre elles explosent. La priorité pour Gigabyte n'a visiblement pas été le silence, mais de maintenir des performances maximales. TempératuresToujours placées dans le même boîtier, nous avons relevé la température du GPU rapportée par la sonde interne : La GTX 980 de référence atteint ici 81 °C, alors que sa limite est de 79 °C. Cela indique qu'elle a atteint sa fréquence de base et que GPU Boost ne s'efforce plus de respecter cette dernière limite. Gigabyte semble avoir calibré ses ventilateurs de manière à ce que le GPU n'atteigne pas 79 °C même en charge extrême de type Furmark. Avec une charge lourde mais moins extrême, le GPU reste à 73 °C sur la GTX 980 G1 Gaming et à 75 °C sur la version GTX 970. Page 11 - Protocole de test Protocole de testPour ce test, nous avons repris les 10 jeux utilisés précédemment, avec leur dernier patch au 29/08/2014, la plupart étant maintenus à jour via Steam/Origin/Uplay. Nous avons envisagé l'intégration de Watch Dogs à notre protocole mais avons fini par abandonner cette idée. Le jeu est fortement limité par le CPU dans les scènes extérieures, à tel point qu'il n'aurait pas été très intéressant de départager les cartes entre 60 et 70 fps en scènes intérieurs alors qu'elles se retrouvent toutes à 40 fps à l'extérieur. Nous nous sommes focalisés dans un premier temps sur une résolution de 2560x1440 mais envisageons de mettre à jour ce dossier avec des résultats en 1080p et ou en 4K. Pour rappel, nous n'affichons plus les décimales dans les résultats de performances dans les jeux pour rendre les graphiques plus lisibles. Ces décimales sont néanmoins bien notées et prises en compte pour le calcul de l'indice. Toutes les cartes ont été testées avec les pilotes Catalyst 14.7beta (14.30.1005Beta2) et GeForce 344.07 beta. Nous avons forcé l'activation du PCI Express 3.0 sur la plateforme X79 pour les GeForce. Nous avons simulé une GeForce GTX 970 aux spécifications de référence à travers la GTX 970 G1 Gaming de Gigabyte. Pour cela nous avons ramené sa limite de consommation à 150W, modifié la courbe de ventilation pour monter au-delà de 70 °C (la température GPU influence sa consommation et donc sa fréquence turbo) et ramené la fréquence de base aux 1050 MHz de référence. Nous avons opté pour tester la Radeon R9 290X de référence en mode Quiet, d'une part parce que la Radeon R9 290X Sapphire est présente et d'autre part parce que le mode Quiet est le seul supportable et limite le GPU de la même manière que Nvidia s'impose de limiter la consommation à 180W et surtout la température à 79 °C. La comparaison de ce mode de la R9 290X avec la GTX 980 nous paraît donc pertinente. Pour ce test, nous avons fait en sorte d'intégrer à chaque fois une carte personnalisée en plus de la carte de référence, pour les R9 290 et GTX 780. De quoi vous proposer des résultats plus représentatifs de ce qui se trouve sur le marché. Comment se comportaient toutes ces cartes vis-à-vis de leurs limites thermiques ? Voici les fréquences que nous avons relevées lors des tests : 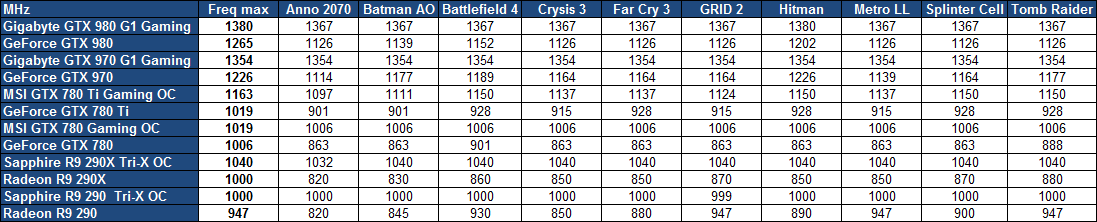 Les GTX 900 de Gigabyte maintiennent leurs fréquences maximales, ou presque, dans tous les jeux. La GTX 980 de référence, par contre, reste dans la majorité des cas à sa fréquence de base, notre échantillon n'étant probablement pas le meilleur, ce qui nous indique au passage que Nvidia n'a pas opéré un tri trop sélectif sur les échantillons presse. Pour ce test, et pour les résolutions de 1080p et 1440p, nous avons utilisé l'écran Asus Swift PG278Q compatible G-Sync. Ce mode était cependant désactivé et, bien que cela n'ait pas d'incidence sur les performances puisque nous testons en v-sync off, nous nous sommes contentés du 120 Hz, le 144 Hz posant problème sur les Radeon pour une raison inconnue (câble pas assez blindé ?). G-Sync n'était pas actif pour les mesures de performances. A noter que pour les quelques mesures effectuées avec les GeForce GTX 480 et 580, nous avons dû passer sur un autre écran en 60 Hz, ces dernières ne proposant pas de DisplayPort, seule connectique supportée par l'écran Asus.  Configuration de testIntel Core i7 3960X (HT off, Turbo 1/2/3/4/6 cores: 4 GHz) Asus P9X79 WS 8 Go DDR3 2133 Corsair Windows 7 64 bits Pilotes GeForce 340.52 WHQL Catalyst 14.7beta (14.30.1005Beta2) Page 12 - Benchmark : 3DMark et Unigine Pour ce test, nous avons lancé différents benchmarks populaires : 3DMark Fire StrikeNous lançons le test Fire Strike avec les 2 presets proposés par Futuremark : [ Fire Strike ] [ Fire Strike Extreme ] Unigine Valley 1.0 & Heaven 4.0Les tests sont effectués avec tous les paramètres au maximum en 1920*1080 et MSAA 8x. [ Valley ] [ Heaven ] Page 13 - Benchmark : Anno 2070 Anno 2070  Anno 2070 reprend une évolution du moteur d'Anno 1404 qui intègre un support de DirectX 11. Nous utilisons le mode de qualité maximale du jeu et effectuons un déplacement sur une carte en mesurant les performances avec Fraps. Dans Anno 2070, c'est avant tout la puissance de calcul qui compte et les GPU sont mis à rude épreuve par rapport à leurs limites de consommation ou de température. De quoi permettre aux GTX 900 de se démarquer. Page 14 - Benchmark : Batman Arkham Origins Batman Arkham Origins  Dernier opus de la série, Batman Arkham Origins est toujours basé sur l'Unreal Engine 3 mais pousse un petit peu plus loin les effets graphiques dont certains ont été implémentés sur PC en collaboration avec Nvidia. C'est le cas du TXAA et d'effets GPU PhysX réservés aux GeForce (il n'est plus possible d'activer une version CPU de tous ces effets), mais également de l'occlusion ambiante de type HBAO+, d'un effet de Depth of Field plus évolué (NVDOF), d'ombres adoucies (PCSS) et de la tessellation (pour la cape et la neige) qui sont utilisables sur tous les GPU DirectX 11. Nous utilisons le mode de qualité maximale du jeu, avec du MSAA 4x. Nous relevons les performances avec Fraps, sur un parcours bien défini. Le jeu est maintenu à jour via Steam. Batman Arkham Origins est bien plus dépendant de la bande passante mémoire ce qui en fait un des jeux les plus difficiles pour les GTX 900. La GTX 780 Ti passe tout juste devant la GTX 980 et il en va de même pour la GTX 780 qui passe devant la GTX 970. Page 15 - Benchmark : Battlefield 4 Battlefield 4  Battlefield 4 repose sur le moteur Frostbite 3, une évolution de la version 2 présente dans Battlefield 3. La base du rendu reste très proche (rendu différé, calcul de l'éclairage via compute shaders) et les évolutions visibles sont mineures, DICE ayant principalement optimisé son moteur pour les consoles de nouvelle génération. Parmi les petites nouveautés, citons un support plus avancé de la tessellation et une amélioration du module "destruction" du moteur. Sur PC, un mode Mantle spécifique aux Radeon et qui permet de réduire le coût CPU du rendu est proposé mais nous ne l'avons pas utilisé pour ce test. Pour rappel, il s'agit d'une API propriétaire de plus bas niveau dédiée aux Radeon HD 7000 et supérieures, qui a été développée par AMD et DICE. Nous testons le mode Ultra par défaut soit avec MSAA 4x. Nous relevons les performances avec Fraps, sur un parcours bien défini. Le jeu est maintenu à jour via Origin. Le GM204 semble apprécier particulièrement Battlefield 4. Page 16 - Benchmark : Crysis 3 Crysis 3  Crysis 3 reprend le même moteur que Crysis 2 : le CryEngine 3. Ce dernier profite cependant de quelques petites évolutions telles qu'un support plus avancé de l'antialiasing : FXAA, MSAA et TXAA sont au programme, tout comme un nouveau mode appelé SMAA. Ce dernier est une évolution du MLAA qui permet, optionnellement, de prendre en compte des données de type sous-pixels soit à travers la combinaison avec du MSAA 2x, soit avec une composante temporelle calculée à partir de l'image précédente. Le SMAA 1x est la simple évolution du MLAA, le SMAA 2tx utilise une composante temporelle et le SMAA 4x y ajoute le MSAA 2x. Notez qu'il ne faut pas confondre le SMAA 2tx proposé en mono-GPU avec le SMAA 2x proposé en multi-GPU, ce dernier utilisant du MSAA 2x sans composante temporelle. Nous mesurons les performances avec Fraps et le jeu est maintenu à jour via Origin. Les GTX 780 et 780 Ti customs offrent un large bond en avant dans ce jeu lourd qui limite fortement leurs versions de référence. Les GTX 900 conservent cependant l'avantage. Page 17 - Benchmark : Far Cry 3 Far Cry 3  Far Cry 3 est relativement lourd, notamment à travers les effets d'occultation ambiante, de filtrage des surfaces alpha et bien entendu à travers la MSAA 4x ou 2x.Pour mesurer les performances, nous activons le HDAO et poussons le niveau graphique en mode élevé. Notez que le SSAO, moins gourmand, propose un rendu immonde, alors que le HBAO produisait des artefacts par endroit avant le patch 1.5 et, même une fois corrigé, affiche un résultat qui se rapproche du SSAO, inférieur au HDAO. Le HBAO ayant été développé à l'origine par Nvidia alors que le HDAO l'a été par AMD, certains testeurs, incités dans ce sens par Nvidia, préfèrent comparer les GeForce avec HBAO aux Radeon avec HDAO. Nous estimons cependant que cette approche n'est pas correcte, le HBAO étant moins gourmand et offrant un résultat inférieur, tout du moins dans ce jeu. Nous utilisons Fraps sur un parcours bien défini. Far Cry 3 fait partie des jeux très appréciés des GTX 900. Page 18 - Benchmark : GRID 2 GRID 2  Dernier né chez Codemaster, GRID 2 reprend une évolution légère du moteur DirectX 11 maison exploité par DiRT Showdown. Pour rappel, en partenariat avec AMD, les développeurs avaient mis en place un éclairage avancé qui prend en compte de nombreuses sources de lumière directes et indirectes ainsi qu'une approximation du rendu de type illumination globale. Ces techniques sont toujours exploitées, même si le partenaire principal de Codemaster est cette fois Intel qui a aidé à la mise en place d'optimisations spécifiques aux GPU intégrés à Haswell. Pour mesurer les performances, nous poussons toutes les options graphiques à leur maximum, y compris l'adoucissement de l'effet d'occlusion ambiante, et activons le MSAA 8x. Nous utilisons Fraps sur l'environnement de Barcelone, le plus lourd dans le jeu. Les Radeon sont ici légèrement en retrait. Page 19 - Benchmark : Hitman Absolution Hitman Absolution  Hitman Absolution utilise un moteur plutôt lourd et qui manque probablement d'optimisations. La charge CPU est par ailleurs relativement élevée dans certaines scènes dans lesquelles une foule importante peut être animée. Différents effets DirectX 11 ont été intégrés avec la coopération d'AMD. Pour mesurer les performances, nous poussons les options graphiques au niveau ultra et utilisons fraps dans le jeu. Hitman Absolution est le second jeu testé dans lequel les GTX 900 souffrent. Elles se font cette fois devancer autant par les GTX 700 que par les Radeon R9 290. Page 20 - Benchmark : Metro Last Light Metro Last Light  Tout comme Metro 2033, sa suite Last Light développée par 4A Games est très gourmande. Elle repose sur une petite évolution du moteur DirectX 11 maison, le 4A Engine, ainsi que sur des environnements et éclairages plus riches. Le jeu pousse par ailleurs plus loin l'utilisation de la tessellation, mise en place en collaboration avec Nvidia, autant sur les personnages que sur les objets ou les sols, même si dans bien des cas la différence n'est cependant pas transcendante. Au niveau de l'antialiasing, le 4A Engine support l'AAA, un algorithme maison similaire au FXAA/MLAA/SMAA, ainsi que le SSAA extrêmement gourmand en mode 2x, 3x et 4x. Un mode 0.5x est également proposé et consiste alors à rendre le jeu dans une résolution inférieur qui est par la suite étendue. Le support de GPU PhysX est toujours de la partie. A ne pas confondre avec PhysX, qui gère globalement la physique au niveau du CPU, il s'agit d'effets accélérés par le GPU à travers une librairie propriétaire de Nvidia, ce qui implique qu'ils ne peuvent pas être accélérés sur une Radeon. Ils sont alors traités par le CPU, d'une manière non-optimisée, ce qui rend leur utilisation difficile en pratique. Nous avons testé le jeu via Fraps sur un parcours bien défini. Nous avons dû faire l'impasse sur le SSAA, bien trop gourmand et nous contenter du mode de qualité élevée mais en poussant le niveau de tessellation sur très élevé. Un jeu sans MSAA que les GTX 900 apprécient particulièrement. Page 21 - Benchmark : Splinter Cell Blacklist Splinter Cell Blacklist  Basé sur le LEAD engine, une version retravaillée en interne de l'Unreal Engine 2.5, Splinter Cell Blacklist profite pour la version PC d'effets graphiques supplémentaires mis en place en collaboration avec Nvidia tels que le HBAO+, la tessellation ou encore le TXAA. Notez au niveau de l'occlusion ambiante que le jeu propose de nombreuses options dont les plus avancées représentent l'effet le plus lourd du jeu. Nous mesurons les performances avec Fraps sur un parcours bien défini et le jeu est maintenu à jour via Uplay. Dans Splinter Cell, les GTX 900 gardent la tête. Page 22 - Benchmark : Tomb Raider Tomb Raider  Tomb Raider a été l'une des meilleures surprises de 2013. Le rendu graphique est plutôt réussi, AMD ayant collaboré avec les développeurs pour s'assurer d'une version PC de bon niveau. C'est particulièrement le cas pour TressFX, l'option de rendu avancé des cheveux de Lara qui apporte une bonne dose de réalisme. Nous avons testé Tomb Raider en mode de qualité Ultime qui inclut l'effet TressFX. Nous avons mesuré les performances avec Fraps, sans utiliser le bench intégré qui correspond plus aux cinématiques qu'aux scènes de jeu classiques. La GTX 780 Ti OC de MSI parvient ici à revenir à hauteur de la GTX 980 OC de Gigabyte. Page 23 - Récapitulatif des performances RécapitulatifBien que les résultats de chaque jeu aient tous un intérêt, nous avons calculé un indice de performances en nous basant sur l'ensemble de résultats et en attachant une importance particulière à donner le même poids à chacun des jeux. Nous avons attribué un indice de 100 à la GeForce GTX 780 Ti de référence : Au final, la GeForce GTX 980 de référence termine 9% devant la GTX 780 Ti mais avec des résultats variables d'un jeu à l'autre en 1440p. En 1080p par exemple, chiffres que nous n'avons pas publiés, toutes les cartes n'ayant pas été testées dans cette résolution, cette avance monte à 13%. C'est près de 20% de mieux qu'une Radeon R9 290X de référence limitée en mode Quiet et légèrement plus qu'une R9 290X de Sapphire qui conserve sa fréquence maximale. Mais une fois débridée également, avec la version G1 Gaming de Gigabyte, la GTX 980 progresse de 12% et domine facilement les Radeon. Seule une GeForce GTX 780 Ti personnalisée et fortement overclockée peut alors prétendre essayer de lutter. Du côté de la GTX 970 basique, elle égale notre GTX 780 Gaming OC de MSI et devance de 12% la version de référence. Une fois overclockée c'est à la GTX 780 Ti qu'elle s'attaque ainsi qu'à la Radeon R9 290X de Sapphire. Par rapport aux anciennes générations, passer d'une GTX 580 ou d'une GTX 680 à une GTX 980 de référence permet un bond en avant appréciable de plus de 100% ou de 60%. Page 24 - Overclocking : 1.5 GHz à portée de clic Overclocking et GM204Avant d'observer les capacités d'overclocking directes des 3 GTX 900 que nous avons testées, nous avons voulu nous pencher de plus près sur l'influence de l'overclocking du GPU et de la mémoire sur les performances du GPU GM204. Est-il plutôt limité par sa puissance de calcul ou par sa bande passante mémoire ? Pour cela nous sommes partis de fréquences de 1250 MHz pour le GPU et de 1750 MHz pour la mémoire, ce quoi correspond à peu près aux fréquences turbo d'un modèle cadencé aux fréquences de référence. Nous avons ensuite poussé ces valeurs dans chaque cas de 14% (le maximum stable pour la mémoire) : [ Pourcents ] [ FPS ] Dans le cas d'Anno 2070 par exemple, seule la fréquence GPU compte, les gains liés à l'overclocking de la mémoire étant minimes. Par contre Batman Arkham Origins et Battlefield 4 affichent tous les deux des gains similaires avec l'overclocking du GPU ou de la mémoire et un gain combiné qui profite clairement des deux. Pour ces jeux, il faut en conclure que, sur GM204, à peu près la moitié du temps de calcul d'une image est limité par la puissance de calcul alors que l'autre moitié est plutôt limitée par la bande passante mémoire. Il est donc important d'overclocker ces deux éléments. Overclocking des GTX 980 et GTX 970Comme toutes les cartes graphiques, les GeForce GTX 900 peuvent être overclockées. Elles reprennent pour cela les mêmes interfaces que pour les GeForce GTX 700. Il est donc possible de modifier manuellement : - la fréquence GPU - la fréquence mémoire - la tension GPU maximale - la limite de température - la limite de consommation Les partenaires de Nvidia sont libres de proposer eux aussi des modèles overclockés d'usine, il n'y a que la limite de température par défaut de 79 °C à laquelle ils ne peuvent pas toucher. Ils peuvent par ailleurs décider d'étendre les plages de modifications pour l'overclocking et pour la limite de consommation. La plage de température n'est par contre pas modifiable et le maximum a été fixé par Nvidia à 91 °C. Nvidia nous a par ailleurs indiqué qu'ils devaient conserver un même ratio entre les fréquences de base et GPU Boost sur lesquelles ils communiquent. Ainsi, un fabricant ne peut pas se contenter de sélectionner les exemplaires qui montent le plus haut en fréquence, ne rien changer et annoncer une fréquence GPU Boost énorme sans toucher à la fréquence de base. Par contre, rien ne les empêche de faire l'inverse, c'est-à-dire sélectionner les échantillons dont la fréquence turbo réelle est la plus faible pour proposer un très gros overclocking d'usine officiel, sans atteindre la limite d'instabilité au niveau de la fréquence maximale réelle. La limite de température fixée à un niveau relativement bas par défaut, 79 °C, est un élément qui peut être relevé pour gagner quelques points de performances, principalement sur les cartes de référence mais également sur certains modèles dont le ventirad serait peu efficace. En contrepartie cela augmente la vitesse de ventilation et donc les nuisances sonores. A noter que si la limite est poussée à 91 °C, une fois celle-ci atteinte, le ou les ventilateurs montent instantanément à 100% et reviennent à un niveau normal dès que la température GPU a chuté de quelques degrés. Mieux vaut donc en pratique éviter d'atteindre cette limite et se contenter de 85 °C voire 90 °C au maximum. Augmenter la limite de consommation est également utile dans le cas où la limite de température n'est pas atteinte (sinon cela ne fait aucune différence). L'intérêt dépend également du niveau de base spécifié par le fabricant. Par exemple sur une GTX 980 de référence dont le TDP est fixé à 180W, le pousser à son maximum, 225W (125%), a plus de sens que sur une GTX 980 de Gigabyte dont le TDP par défaut est déjà fixé à 300W, valeur supérieure à la consommation observée dans les jeux les plus gourmands. Le pousser manuellement à 336W (112%) n'apportera pas d'avantage, ni de désavantage d'ailleurs, excepté peut-être un stress supplémentaire dans certaines applications telles que Furmark. La fonction d'overvoltage (OV) ou d'augmentation de la tension GPU reste similaire à ce que nous avons pu observer sur les GTX 700 si ce n'est que la plage semble être un peu plus élevée. Il ne s'agit pas d'une augmentation directe de la tension ni d'un offset comme sur les Radeon mais bien d'un allongement de la courbe des tensions/fréquences. Un ou deux points en plus sur cette courbe qui permettra de gagner 13 ou 26 MHz quand les limites de consommation et de température ne sont pas atteintes. Lorsqu'elles le sont l'OV n'a aucun impact. Voici l'impact de l'OV sur nos 3 cartes : GTX 980 de référence : max 1265 MHz @ 1.225V -> max 1278 MHz @ 1.243V GTX 980 Gigabyte : max 1380 MHz @ 1.225V -> max 1393 MHz @ 1.250V GTX 970 Gigabyte : max 1354 MHz @ 1.206V -> max 1380 MHz @ 1.250V A noter que l'algorithme GPU Boost bloque l'accès au dernier ou aux deux derniers points de la courbe de tensions/fréquences lorsque certaines conditions sont rencontrées. Nous n'avons pas encore pu les déterminer précisément mais elles semblent liées à la charge et à la température GPU, même quand les limites à ce niveau ne sont pas atteintes. Un mécanisme probablement mis en place par Nvidia pour contenir l'augmentation des nuisances avec un impact négligeable sur les performances. Augmenter la fréquence GPU sur GTX 900, tout comme sur les GTX 600 et 700, revient à appliquer un offset. C'est-à-dire que la fréquence est relevée sur tous les points de la courbe utilisée par GPU Boost. Vu sous un autre angle, cet offset revient à réduire la tension GPU appliquée à chaque niveau de fréquence. Ainsi, même si votre carte se retrouve limitée par sa température ou sa consommation et n'atteint pas sa fréquence maximale, l'overclocking GPU reste utile ! A noter que nous testons la stabilité d'un overclocking à différents niveaux de charge de manière à vérifier cette stabilité à différents points de la courbe des fréquences/tensions. En plus du petit gain lié à l'OV, voici les overclockings GPU que nous avons pu obtenir, en évoluant par pas de 26 MHz pour nous adapter aux étapes de 13 MHz de la courbe de fréquences mise en place par Nvidia : GTX 980 de référence : +208 MHz -> max 1486 MHz @ 1.243V GTX 980 Gigabyte : +130 MHz -> max 1522 MHz @ 1.250V GTX 970 Gigabyte : +104 MHz -> max 1484 MHz @ 1.250V Atteindre 1.5 GHz est donc relativement aisé pour le GPU GM204, même si toutes les cartes n'y arriveront pas de manière totalement stable. Au niveau de la mémoire, nous avons également cherché l'overclocking maximum en évoluant par pas de 25 MHz en fréquence réelle soit par pas de 50 MHz au niveau de la fréquence affichée par Afterburner : GTX 980 de référence : +"300" MHz -> 1900 MHz GTX 980 Gigabyte : +"500" MHz -> 2000 MHz GTX 970 Gigabyte : +"500" MHz -> 2000 MHz A noter que sur la carte de référence, la mémoire est stable à 2000 MHz mais uniquement pendant quelques minutes, probablement le temps que sa température ou celle de son étage d'alimentation monte. Nous avons dû redescendre à 1900 MHz pour stabiliser la carte dans la durée. Voici les gains de performances que nous avons pu observer tout d'abord en poussant les limites de consommation et de températures à leur maximum, ensuite en appliquant l'overclocking. Au niveau des températures, bien que la limite soit poussée à 91 °C pour donner un maximum de marge, en pratique la carte de référence se contente de 82 °C dans Anno sans overclocking et de 83 °C avec. Les cartes de Gigabyte restent à 70 °C et 72 °C, soit très loin de la limite. [ FPS ] [ Pourcents ] Fort logiquement, seule la carte de référence profite d'une simple revue à la hausse de ses limites, celles-ci n'étant pas atteintes sur les cartes de Gigabyte. C'est également en partie ce qui lui permet d'afficher un plus gros global. Ce gain plus faible sur les cartes Gigabyte s'explique également en partie par le fait que l'overclocking d'usine puise dans les capacités d'overclocking manuel. Il reste donc moins de marge supplémentaire pour l'utilisateur. Au final, suivant les jeux, nous obtenons après overclocking un gain de 19 à 23% sur la GTX 980 de référence, de 11 à 15% sur la GTX 980 G1 Gaming de Gigabyte et de 7 à 13% sur la GTX 970 G1 Gaming de Gigabyte. Quel impact sur la consommation ?Nous avons mesuré la consommation sous Anno 2070 et Battlefield 4 avant et après overclocking : [ Watts ] [ Pourcents ] Fort logiquement, c'est sur la GTX 980 de référence que la consommation progresse le plus avec +43% dans Anno 2070, ce qui est logique puisque par défaut sa température maximale est atteinte ce qui limite sa consommation dans les jeux les plus gourmands. A noter que même relevée de 25%, sa limite de consommation (225W) est atteinte et sa fréquence GPU est réduite de 1473 à 1424 MHz. Toujours dans Anno, les GTX 980 et 970 G1 Gaming sont 20% plus gourmandes après overclocking, pour une consommation qui dépasse les 250W pour la première. Dans un jeu moins lourd tel que Battlefield 4, toutes les cartes restent sous les 200W une fois overclockées, ce qui permet à la carte de référence de rester à sa fréquence maximale. Page 25 - Conclusion ConclusionLors du lancement de la GeForce GTX 750 Ti, nous nous demandions si Nvidia pourrait conserver l'excellente efficacité énergétique obtenue par le premier GPU Maxwell sur de plus grosses puces à la structure plus complexe. Nvidia nous assurait alors qu'il n'y avait pas de raison que ce soit un problème, mais nous sommes de nature prudente et attendions d'en avoir la démonstration. C'est chose faite.  Le GPU GM204, qui représente la seconde génération Maxwell, parvient même à pousser cette efficacité énergétique un cran plus haut dans sa version GeForce GTX 980. Une prouesse technique des ingénieurs de Nvidia qui témoigne du travail acharné effectué dans ce sens depuis 2010 et la génération Fermi qui les menait droit dans le mur. Un virage radical a été pris dès que les équipes chargées du développement des GPU ont pris conscience de la problématique d'une consommation excessive qui induit surchauffe des GPU et nuisances sonores désagréables. Kepler en a marqué la première étape et Maxwell en représente l'aboutissement, ce qui permet à Nvidia de relancer la course à la performance malgré une finesse de gravure qui reste bloquée en 28nm depuis bientôt 3 ans. Cela ne veut pas dire qu'il n'y a pas moyen de faire encore mieux, c'est toujours possible, mais que Nvidia est parvenu à placer la donnée énergétique au centre de ses développements. N'ayant pas rencontré cette problématique aussi tôt que Nvidia, AMD a pris du retard dans son intégration au centre de ses décisions. Il lui faudra probablement du temps pour revenir sur ce point. Il y a cependant un autre élément qui facilite la tâche de Nvidia : l'architecture est également très efficace côté performances. Cela permet d'obtenir une avance sur la concurrence, même légère, sur le plan des performances sans pour autant pousser le GM204 dans ses limites en termes de fréquence ou de tension grâce à un contrôle très strict de la consommation et des températures. Il ne fait aucun doute que si la Radeon R9 290X avait été 10% plus performante, la GeForce GTX 980 aurait été autorisée à monter plus haut en fréquence, tension, consommation et température, ce qui aurait tempéré quelque peu son rendement. Il serait malgré tout resté largement supérieur comme en témoigne les résultats des cartes débridées de Gigabyte. Après avoir finalisé ou presque ses optimisations énergétiques dans les premiers GPU Maxwell, la seconde génération profite de quelques fonctionnalités de plus. Rien de fracassant, mais de quoi pouvoir s'assurer d'un support matériel des petites nouveautés de Direct3D 12, ce qui est toujours utile, ainsi que d'un traitement efficace d'un nouveau mode de rendu qui semble prometteur : le Voxel Global Illumination. La connectique HDMI 2.0 et l'encodage HVEC sont également de la partie. Si vous recherchez aujourd'hui une carte graphique haut de gamme mono-GPU pour le jeu, la GeForce GTX 980 est à l'heure actuelle ce qui se fait de mieux. Pour un peu plus cher, une GTX 780 Ti efficace s'en rapproche, mais avec une consommation plus élevée, et la Radeon R9 290X est battue et consomme encore plus.  Bien conscient de son avantage, Nvidia n'est par conséquent pas très agressif côté prix sur ce modèle qui est proposé à 550 . De quoi permettre au passage de laisser de la place à l'écoulement des stocks de GeForce GTX 780 Ti qui en auront bien besoin. Ces dernières sont d'ailleurs désormais en fin de vie, tout comme les GTX 780 et GTX 770, et il y aura peut-être de bonnes affaires d'ici peu pour celui qui est équipé d'un de ces modèles et envisage de passer au SLI. Avec un ticket d'entrée à 330, la GeForce GTX 970 est la déclinaison la plus intéressante pour de nombreux joueurs. Elle se situe entre les GTX 780 et GTX 780 Ti sur le plan des performances et est très proches d'une Radeon R9 290X de référence ou basique. S'il s'agit d'un modèle boosté par l'un des partenaires de Nvidia, elle monte d'un cran et se comporte en moyenne comme une Radeon R9 290X efficace, telle que la Tri-X de Sapphire, les watts en moins ! C'est le cas de la version G1 Gaming de Gigabyte que nous avons testée, même si nous aurions préféré que le fabricant propose d'origine un mode plus discret en ne laissant pas la consommation maximale monter trop haut. Cela se configure par contre très facilement en limitant la consommation maximale autorisée, avec un impact très limité dans les quelques jeux les plus gourmands et nul dans tous les autres. Il en va de même pour la GTX 980 G1 Gaming qui autorise par défaut une consommation de 300W, là où 100W de moins auraient fait amplement l'affaire. Pour répondre au GM204 et surtout à la GTX 970, AMD n'a pas d'autre choix que de repositionner du point de vue tarifaire ses 290X/290 afin d'offrir un meilleur rapport performance/prix compensant un minimum son retard en terme d'efficacité énergétique, bien que la sensibilité sur ce point soit à géométrie variable en fonction des joueurs. Il ne sera toutefois pas sans conséquences pour AMD et ses partenaires puisqu'une carte à base d'Hawaii coûte nettement plus cher à produire qu'une autre à base de GM204, que ce soit au niveau du GPU plus gros mais aussi du PCB plus complexe pour le bus mémoire 512 bits et l'étage d'alimentation plus musclé. A plus long terme, AMD a donc clairement besoin d'une architecture plus efficace, un point sur lequel son récent GPU Tonga n'a pas convaincu. En attendant, Nvidia dispose donc d'un atout majeur et devrait continuer de décliner son architecture Maxwell dans les mois à venir, que ce soit en utilisant un GM204 bridé sur une probable GTX 960 mais aussi en l'utilisant sur d'autres puces, certaines rumeurs indiquant qu'un GM200 plus imposant serait en préparation. Mise à jour du 30/01/15 : Après avoir pris en compte ses spécifications rectifiées et passé de nombreuses heures à essayer, sans grand succès (cf. focus), de la mettre en défaut sur son utilisation de la mémoire, il est évident que la GTX 970 reste selon nous une excellente carte graphique, que nous vous recommandons toujours. Nul doute que cette erreur risque par contre de coûter cher en termes de réputation à cette GeForce et que Nvidia doit aujourd'hui s'en mordre les doigts. AMD profite bien entendu de l'aubaine pour mettre en avant ses solutions, avec des Radeon R9 290 qui sont très bien placées du fait d'une hausse de leur prix bien moins rapide que celles des GTX 970 suite à l'évolution du taux de change /$, les revendeurs bénéficiant actuellement d'une promotion temporaire d'AMD. Copyright © 1997-2026 HardWare.fr. Tous droits réservés. |