| |
| |
| 16 curs en action : Asus Z9PE-D8 WS et Intel Xeon E5-2687W Processeurs Publié le Mercredi 9 Mai 2012 par Guillaume Louel URL: /articles/865-1/16-c-urs-action-asus-z9pe-d8-ws-intel-xeon-e5-2687w.html Page 1 - Introduction Lors de notre test de la nouvelle plateforme haut de gamme d'Intel en fin d'année dernière, nous avions regretté le fait que le constructeur n'ai pas proposé de modèle 8 curs sur la plateforme LGA 2011. Car en effet le Core i7 3960X, le processeur "grand public" le plus haut de gamme d'Intel, s'il est basé sur un die 8 curs n'en a en pratique que 6 d'actifs. Raison invoquée pour ce choix par la marque, tenter de contenir la consommation et ainsi maintenir le TDP aux alentours de 130 watts. Un bridage compréhensible, mais qui nous force à nous demander ce qu'aurait donné un tel processeur 8 curs. Si l'on parle pour le lancement futur de la plateforme Ivy Bridge-EP de processeurs grand public équipés de huit curs, il n'est pas nécessaire d'attendre que ceux-ci arrivent pour se faire une idée : les SandyBridge-E existent aujourd'hui en version 8 curs. Sous la dénomination de Xeon E5! La gamme dédiée aux applications serveurs d'Intel a en effet été renouvelée en mars dernier et partage les mêmes dies que notre Core i7 3960X, pleinement débridés. 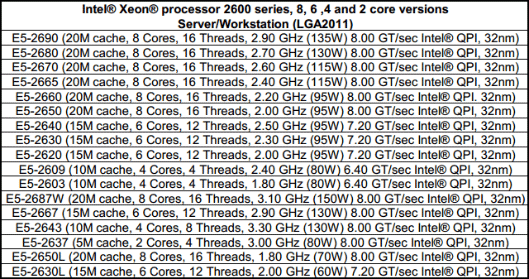 Les processeurs équipés de huit curs ne sont d'ailleurs pas une rareté dans cette gamme qui en compte pas moins de huit ! Outre la segmentation autour de la fréquence, c'est aussi du côté du TDP que la segmentation opère principalement avec des puces qui s'étalent pour couvrir les différents besoins en termes de refroidissement. La question du TDP est d'autant plus importante quand il s'agit de placer ce type de processeurs dans des serveurs rackables. Si l'on y regarde bien cependant, il y a un processeur dans cette liste qui détonne un peu des autres. Il n'est pas tout en haut de la gamme, il n'est même pas le plus cher. Et il dispose d'un TDP, unique, de 150 watts. Baptisé Xeon E5-2687W, il s'agit du processeur octocore le plus rapide d'Intel avec une fréquence de base de 3.1 GHz et un mode Turbo qui peut atteindre les 3.8 GHz. Une puce qui n'aurait d'ailleurs pas du tout fait tâche tout en haut de la hiérarchie des Core i7. Et que nous avons décidé de tester pour vous aujourd'hui.  Parce que deux, c'est mieux Une des particularités de ce Xeon est, à l'image des autres processeurs de la série 2600, sa capacité de fonctionner en couple. Il n'aurait donc pas été très correct de le tester seul ! Mais encore faut il disposer d'une carte mère adaptée. De ce côté nous avons mis la main sur la carte mère Z9PE-D8 WS, une carte "serveur" d'Asus, prévue pour une utilisation "workstation" et qui emprunte quelques codes aux cartes mères grand public !  et que l'ATX, c'est bien trop petit ! L'occasion rêvée pour vous présenter ce type de plateformes, extrêmes dans tous les sens du terme, et leurs particularités. Et pour ceux qui le souhaitent, de rentrer dans les détails du fonctionnement des plateformes équipées de deux sockets (on parlera de 2S par la suite) ou plus ! Page 2 - SMP, Nehalem, QPI, quelques rappels Si pour le grand public, l'introduction des processeurs Core i7 Nehalem a surtout été l'occasion de voir la scission de la gamme d'Intel en deux sockets (le LGA1366 lancé en novembre 2008, puis le LGA1156 en septembre 2009), ce fut du côté de la gamme Xeon l'occasion d'une profonde réorganisation. Pour ceux qui ne le sauraient pas, la gamme Xeon d'Intel regroupe des processeurs destinés plus particulièrement au marché des entreprises et à destination de machines types serveurs ou stations de travail. D'un point de vue fabrication, les processeurs Xeon partagent les mêmes dies que leurs déclinaisons grand public pour un grand nombre de modèles (un ultime die existe, dédié aux configurations au-delà de 4S avec un socket particulier), mais certaines de leurs fonctionnalités peuvent être activées ou désactivées en fonction de la segmentation. L'une des fonctionnalités interdite à la gamme grand public d'Intel ayant été, depuis la nuit des temps, le fonctionnement de deux processeurs en simultanée sur la même machine, ce que l'on appelle souvent SMP pour Symmetric Multi Processing. Avant de parler des performances, revenons sur quelques particularités techniques de ces plateformes qui vont jouer un rôle décisif dans la manière dont elles sont capables d'exploiter les performances de plusieurs processeurs en simultanée. QuickPath Interconnect Une des grandes particularités du lancement de la plateforme 1366 fut l'introduction d'un nouveau bus de communication pour Intel, le QPI. Il s'agit d'un bus d'interconnexion point à point dont le but est de permettre l'interconnexion avec le reste de la machine, généralement le chipset. Jusqu'ici, Intel utilisait en effet un bus propriétaire - nécessitant une licence pour l'exploiter aussi bien côté processeur que chipset - que l'on appelait FSB et dont la fréquence avait évolué avec le temps. Pour chercher l'inspiration du QPI (tant dans l'implémentation technique que sur le concept), il faut regarder côté concurrence. Après s'être émancipé du FSB en 1999, AMD avait lancé en 2001 un nouveau bus point à point, l'HyperTransport qui a servi d'abord pour relier les chipsets northbridges et southbridges, par exemple sur le nForce de Nvidia, puis avec l'Athlon 64 aura servi également d'interconnexion entre processeur et northbridge. Avec le lancement simultané de la plateforme Opteron, AMD s'est servi de ce même bus pour permettre de connecter les processeurs entre eux dans des machines multiprocesseurs. Ainsi de la même manière que les Athlon 64 ne disposaient que d'un seul lien HyperTransport actif (en théorie) contre trois pour les Opteron, Intel a intégré dans ses processeurs sur socket 1366 plusieurs liens QPI (quatre dans le cas de Nehalem), activés en fonction de l'usage. Dans le cas d'un processeur Core i7 desktop, un seul lien QPI est actif, permettant de relier le processeur au southbridge. Avec les quatre liens activés cependant, on peut obtenir des maillages originaux comme par exemple cette plateforme quadri processeur ou chaque puce est reliée aux trois autres, et au chipset : 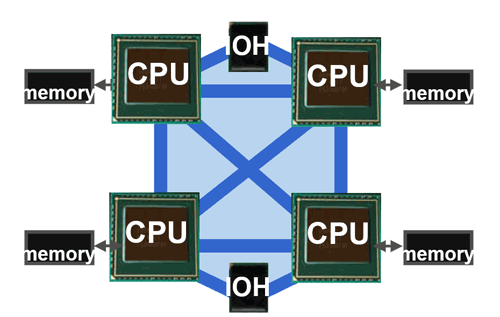 Vous remarquerez sur ce schéma que chaque processeur dispose de sa propre mémoire, Nehalem avait pour rappel été l'occasion de l'introduction d'un contrôleur mémoire, autrefois intégré dans le northbridge, directement dans le processeur. Ce qui peut poser une vraie question, comment les processeurs se répartissent ils les données, et comment tout cela se traduit-il pour le système d'exploitation ? Page 3 - MESI, MOESI, MESIF, NUMA MESI, MOESI, MESIF, NUMA Avec l'arrivée des processeurs multi-curs, le concept des ressources multiples et partagées a été largement intégré, aussi bien côté hardware que dans les systèmes d'exploitations. Dans un processeur moderne, on retrouve un seul contrôleur mémoire qui est utilisé par de multiples curs, avec entre les deux une hiérarchie de caches (pour stocker les données mémoire les plus utilisées), parfois uniques à chaque cur, parfois partagés, afin de créer un système qui permette à la fois de partager efficacement le contrôleur et de maximiser les performances. Et côté systèmes d'exploitation, si l'on dispose de multiples curs, tous partagent la même mémoire. La question de la ressource partagée entraine cependant de nouveaux problèmes : que se passe-t-il si un cur veut accéder à une donnée mémoire utilisée par un autre cur ? Quelle "version" de la donnée est la bonne, celle stockée en RAM ou celle stockée dans le cache ?  Un peu de coordination devient rapidement nécessaire Pour gérer ces conflits, des mécanismes ont été crées, le plus classique étant le protocole MESI qui permet de donner un état (Modified, Exclusive, Shared, Invalid) aux lignes de caches afin de permettre aux curs de se coordonner un minimum. MESI Utilisé jusque Nehalem par Intel, MESI est un protocole qui permet deux choses :
Prenons l'exemple ou un cur A a besoin de lire une donnée en mémoire. Grace à MESI, il va se renseigner d'abord pour savoir si quelqu'un utilise ces données. Une requête est alors envoyée vers tous les autres curs. Si personne ne dispose de la donnée demandée, le contrôleur mémoire va alors aller chercher en mémoire la donnée demandée pour Ainsi, si un cur A à besoin de lire une donnée en mémoire, il va se renseigner pour savoir si quelqu'un utilise ces données en envoyant une requête. Si personne ne dispose de la donnée elle sera récupérée en mémoire par le contrôleur puis renvoyé au cache qui la demandait. Cependant si un autre cur B avait déjà demandé cette donnée auparavant pour la lire, il aura placé lui aussi cette ligne de cache en état Exclusive. C'est là que l'entraide joue, le cur B va alors passer en état Shared pour indiquer qu'il n'est plus le seul à disposer de cette donnée, et il va envoyer la donnée directement au cur A (on parle de forward) qui devient alors lui aussi propriétaire de cette copie (on parle d'instance). Le système fonctionne particulièrement bien lorsque l'on a deux curs au maximum qui peuvent accéder à une même donnée. Si par contre une même donnée est en état Shared sur plusieurs curs, tous ces curs répondront à la requête ! Plusieurs réponses identiques transitent alors entre les curs, ce qui fait perdre de la bande passante pour rien. L'entraide, mal dirigée, peut avoir ses limites. Pour notre second exemple, admettons la donnée recherchée par notre cur A ait non pas été lue par le cur B, mais qu'il l'ait lu, puis modifiée. En pratique, le cur B aura passé cette ligne de cache de l'état Exclusive à l'état Modified. Cet état est original puisqu'il indique que les données en mémoire principale ne sont plus bonnes (dirty) et que c'est ce cache qui devient le seul et unique détenteur de la vérité concernant ces données. Si notre cur A demande à ce moment cette donnée, le cur B va devoir, pour assurer la cohérence, effectuer un tas d'opérations :
Ces opérations sont bien entendues couteuses, en premier lieu puisque l'on implique le contrôleur mémoire dans l'histoire ! MOESI Pour corriger ces problèmes évoqués précédemment, plusieurs évolutions de MESI ont été crées. AMD de son côté à choisi le MOESI. Ce protocole change la donne sur les deux points évoqués au dessus, en introduisant un état Owned. Si l'on reprend notre premier cas, le cur B pourra passer du mode Exclusive au mode Owned avant d'envoyer la copie. Jusqu'ici, peu de différence, mais si par contre un troisième cur souhaite accéder à cette donnée, en MESI, les curs A et B enverront en simultanée la réponse. MOESI permet de limiter ceci : les curs en état Shared ne répondent pas aux requêtes ! Seul le cur en état Owned répondra, limitant le trafic. Dans le second cas, notre cur B en état Modified, au lieu d'effectuer ses multiples opérations (writeback, changement en mode Shared, forward) passera simplement en mode Owned avant d'envoyer la donnée au cur A. On économise ici de la bande passante mémoire, ce qui est un gros progrès MESIF Depuis Nehalem, Intel a abandonné le MESI pour proposer le MESIF auquel il ajoute un nouvel état, Forwarding. Ainsi dans notre premier exemple, lorsque le coeur A réclame les données, le cur B passera du mode Exclusive au mode Forwarding. Dans ce cas précis, il agira comme le mode Owned de MOESI à savoir qu'il sera le seul à répondre aux requêtes pour limiter le trafic. Dans le second cas cependant, le mode MESIF n'apporte rien. Si sur le papier MESIF est un modèle qui peut paraitre moins intéressant, comme toujours en informatique, tout est question de compromis : une implémentation MOESI peut être plus complexe à mettre au point qu'une implémentation MESIF. Et dans un système multi CPU ? Nous avons décrit ici une situation relativement simple ou l'on ne dispose que d'un seul processeur avec plusieurs curs, disposant d'un système de cache et d'un unique contrôleur mémoire. Mais quid d'un système multi CPU moderne ou chaque processeur dispose de son propre contrôleur, et donc de ses propres barrettes mémoires ? On trouve deux possibilités. La plus simple, et pas forcément la plus intuitive consiste à dupliquer les données. A l'image du RAID pour les disques durs, chaque contrôleur mémoire stockera une copie des données. On divise donc la mémoire disponible par deux sur une plateforme bi socket. En cas de lecture, le cas est simple, les curs de chaque processeurs disposent d'une copie locale de la donnée qui les intéresse. En cas d'écriture, chaque changement doit être reporté simultanément dans tous les espaces mémoires. NUMA Le mode de fonctionnement le plus intéressant resterait la possibilité de pouvoir agréger la mémoire associée à chaque processeur en un grand espace mémoire commun qui pourra être utilisé comme tel par le système d'exploitation. D'un point de vue théorique, il suffit de donner la possibilité au processeur A d'utiliser la mémoire placée dans le processeur B. C'est à cela que servent les deux liens QPI intégrés dans le processeur. Dans le cas des SNB-E, ces liens sont cadencés à 4 GHz, ce qui signifie 32 Go/s de bande passante utile dans chaque sens. Se pose cependant deux problèmes. Le premier est d'ordre pratique : l'espace mémoire vu par le système d'exploitation étant unique, comment doit-on répartir la mémoire entre les deux sockets ? La méthode traditionnelle consiste à enchevêtrer les banks mémoires. Cela veut dire qu'a tout moment, un programme aura la moitié de ses données présentes sur chacun des sockets, indépendamment du processeur ou il s'exécute. L'autre possibilité est d'utiliser un protocole intelligent qui réclame la collaboration du système d'exploitation. C'est ce que l'on appelle NUMA, pour Non Uniform Memory Access. En mode NUMA, le système d'exploitation prend conscience du fait qu'il existe deux espaces mémoires logiques distincts, un peu à l'image de la manière dont le noyau prend en compte l'HyperThreading ou les architectures sous formes de module des AMD FX. Le système d'exploitation tentera alors d'allouer la mémoire dans le socket qui correspond au cur processeur qui exécute le thread censé utiliser la mémoire. Grace au protocole MESIF vu précédemment (ou MOESI chez AMD), dans le cas ou une application partage des données entre plusieurs threads, les transferts mémoires s'opèreront lorsque cela est nécessaire. Sur le papier, le mode NUMA semble logiquement être le meilleur mais comme souvent les choses ne sont pas forcément si simple. Nous avons d'abord comparé la latence et la bande passante mémoire multithreadée via les logiciels RMMT et Aida64. Notez que pour ces tests théoriques, nous avons désactivé l'HyperThreading ainsi que quatre curs sur chaque processeur. La raison derrière cette limitation vient du fait que RMMT ne permet pas de gérer plus de huit threads en simultanée, un problème sur lequel nous reviendrons ultérieurement. Huit barrettes de 4 Go de mémoire DDR3 registered cadencée à 1066 (CAS7) sont installées pour ces tests : 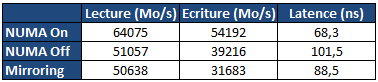 Pour rappel, en mode mirroring seuls 16 Go sont disponibles. En mode NUMA Off et NUMA On, les 32 Go sont disponibles, mais si NUMA est désactivé, l'espace mémoire est enchevêtré entre les deux sockets. On notera de manière assez logique que le mode Mirroring est le moins efficace en matière d'écritures mémoires. Chaque écriture réalisée est envoyée vers les deux contrôleurs mémoire en simultanée, saturant les 32 Go/s offerts par le bus QPI. Si l'on désactive le mirroring, la bande passante en écriture remonte, on est toujours partiellement limité par le bus QPI, mais le fait que le contrôleur local ainsi que le contrôleur distant soient utilisés alternativement mitige les problèmes. Activer NUMA permet de maximiser les performances avec un gros gain aussi bien sur la lecture, l'écriture que la latence, chaque thread utilisant la mémoire locale du socket sur lequel il s'exécute. Bien entendu les performances théoriques sont l'occasion de contres exemples pratiques ! Nous avons mesuré les performances sous 7-Zip, la valeur indiquée est un temps de compression en secondes : 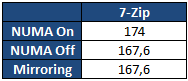 7-Zip est plus lent en mode NUMA. Il s'agit bien entendu d'un cas particulier. Ici, le logiciel utilise un dictionnaire de données commun entre tous ses threads et dont l'accès est partagé. NUMA dans ce cas peut engendrer une légère perte de performances, qui semble plus particulièrement liée au choix de l'utilisation du protocole de cohérence MESIF. Comme toujours en informatique tout est une question de compromis et si, pour une utilisation générale l'activation de NUMA est toujours conseillée, à l'image de l'HyperThreading dans certains cas, elle peut également être légèrement contreproductive. Selon le type d'applications utilisées, chacun pourra configurer les contrôleurs mémoire en fonction de ses besoins. Pour les tests qui suivent nous avons opté pour la configuration par défaut, et celle qui hors 7-Zip est systématiquement la plus efficace. Page 4 - Xeon E5-2687W Xeon E5-2687W Comme nous l'avions indiqué dans notre test du Core i7 3960X, le die développé par Intel pour la plateforme LGA 2011 (SandyBridge-E) est composé de 2.27 milliards de transistors et est composé nativement de huit curs. Par rapport aux processeurs Sandy Bridge classique, la taille des caches de niveau 1 et deux a été doublée tandis que le L3 atteint 20 Mo. 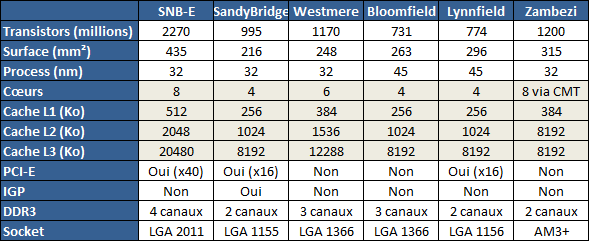 Dans le cas de la gamme grand public LGA 2011 cependant, l'offre proposée par le constructeur se contente de quatre à six curs activés. Ce n'est bien entendu pas le cas de la gamme Xeon ou des processeurs huit curs sont proposés, souvent à des fréquences de fonctionnement plus faibles afin de rester dans un TDP de 130W (parfois 135W) équivalent à celui du Core i7 3960X.  Comme nous l'indiquions en introduction, nous nous intéressons aujourd'hui au modèle le plus extrême de la gamme E5-2600, le Xeon E5-2687W dont le TDP atteint les 150 watts ! Les huit curs du die sont actifs et si la fréquence de base de la puce est un peu plus faible (seulement 3.1 GHz contre 3.3 pour le Core i7 3960X), sa fréquence Turbo maximale (un ou deux curs actifs) atteint les 3.8 GHz. 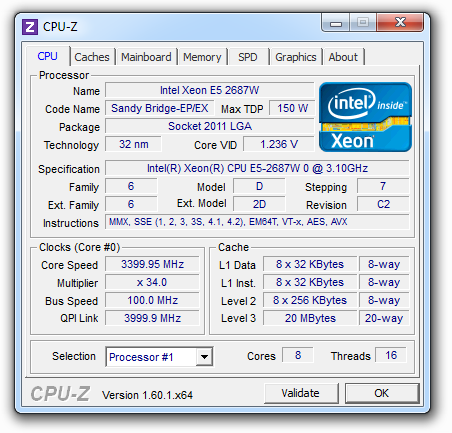 Nous avons récapitulé dans ce tableau côte à côte la fréquence Turbo maximale en fonction du nombre de curs actifs pour le Xeon E5 2687W et le Core i7 3960X : 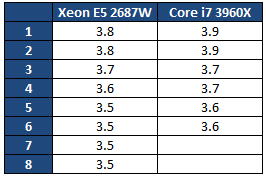 L'écart de fréquence est donc en général de 100 MHz entre ces deux puces, même si l'on notera que la répartition des fréquences n'est pas uniforme, à trois curs actifs, les deux processeurs fonctionnent à 3.7 GHz. Autre point à noter au sujet du Turbo et des multiplicateurs, contrairement au Core i7, ces Xeon ne permettent pas que l'on change les ratio Turbo. Le coefficient multiplicateur de ces puces est également bloqué. La dernière particularité de ces Xeon, et non des moindres est bien entendu le fait que deux de ses brins QPI soient actifs, ce qui autorise, couplé à une carte mère adéquate, le fonctionnement en mode bi socket. Page 5 - Asus Z9PE-D8 WS Asus Z9PE-D8 WS Afin de réaliser notre test, Asus nous a fourni la Z9PE-D8 WS, carte mère de la gamme "serveur" du constructeur même si l'on parlera de carte type "workstation". Elle est équipée côté chipset de l'Intel C602, connu précédemment sous le nom de Patsburg-A. La première chose qui frappe est bien entendu sa taille. La carte est en effet au format E-ATX. Par rapport à une carte mère ATX traditionnelle, la hauteur reste la même, à 30.5 centimètres. C'est la largeur qui augmente puisque l'on passe de 24.5 à 33 centimètres. Cette augmentation de taille est bien entendu obligatoire afin de pouvoir placer les deux sockets ainsi que la mémoire associée. Il va sans dire qu'une telle carte nécessite un boitier spécifiquement compatible avec la norme EEB. Un simple grand boitier grande tour, aussi large soit il, ne sera pas suffisant s'il n'est pas explicitement compatible EEB. On retrouve sur la carte mère deux sockets LGA 2011 avec sur la droite le socket principal. Pour rappel si Intel utilisait un lien QPI pour relier les processeurs au chipset avec Nehalem, ce n'est plus le cas pour la plateforme SNB-E, ici le socket principal est relié au chipset par un bus DMI (un bus PCI Express 2.0 x4), à l'image de ce que l'on trouve sur les plateformes socket 1155.  Côté mémoire chaque socket est entouré par quatre slots, Asus se limite sur ce modèle à un DIMM par canal pour contenir la taille de la carte. Sachez qu'il existe également des modèles avec deux DIMM par canal (soit huit slots mémoire par socket, 16 en tout sur une carte mère bi socket). Notez côté alimentation que chaque socket réclame son propre connecteur d'alimentation de type P8. Si les blocs de large capacité proposent généralement deux connecteurs de ce type, ce n'est pas forcément le cas de tous les modèles. On trouve cependant dans le commerce des adaptateurs 6 broches PCI Express vers connecteur d'alimentation P8.  Côté stockage, le chipset C602 offre à l'image du X79 six connecteurs Serial ATA, deux de type 6 Gb/s et quatre de type 3 Gb/s. Quatre ports additionnels sont ajoutés par la SCU (Storage Controller Unit) qui est un bloc additionnel ajouté au chipset. En pratique ces ports sont donc particulièrement limités. Pour compenser cela Asus ajoute un contrôleur Marvell 9230 qui expose quatre ports 6 Gb/s. Particularité, le contrôleur est connecté au chipset en PCI Express sur deux lignes, et non une.  Du côté du PCI Express, la carte inclut sept ports ! Leur configuration est particulière, pour rappel les processeurs SNB-E disposent chacun de 40 lignes PCI Express de type 3.0. Ici les quatre premiers slots sont reliés au socket principal, et les trois suivants au second socket. Avec deux processeurs, on peut donc disposer en utilisant les quatre slots bleus de quatre fois 16 lignes PCIe 3.0. Si l'on peuple tous les slots, leur fonctionnement est limité au mode x8. Panneau arrière Le panneau arrière semblera déjà plus classique puisque l'on retrouvera un connecteur PS/2 ainsi que six ports USB 2.0. Deux ports réseau Gigabit Ethernet sont également présents, pilotés chacun par un contrôleur gigabit Intel 82574L.  Une des particularités de ce contrôleur est sa gestion, avec les pilotes adéquats, du VT-d. Ces contrôleurs peuvent être asservis directement à une machine virtuelle. Pour le reste on retrouvera des choses plus classiques à savoir deux ports USB 3.0 gérés par un contrôleur ASMedia 1042 ainsi que six jacks assignables et un connecteur S/PDIF pilotés par un Realtek ALC 898 (avec option encoage DTS). Ces fonctionnalités, si elles peuvent sembler classiques pour une carte mère desktop ne le sont cependant pas forcément pour des cartes workstation ou serveur. Connectique interne Côté connectique interne on retrouvera de quoi connecter deux ports USB 3.0 supplémentaires (ASMedia 1042), six ports USB 2.0, deux headers Firewire et deux connecteurs pour ports séries. De manière plus originale, on retrouvera également un header VGA sur la carte mère, animé par un SOC ARM Aspeed AST2300 qui sert de contrôleur 2D basique pour avoir un retour écran en salle serveur, mais aussi de permettre la prise de contrôle à distance sans pour autant devoir ajouter de carte graphique additionnelle.  On notera enfin côté ventilation la présence de deux connecteurs processeurs et six connecteurs châssis, tous au format 4 broches, ainsi que la présence très utile de leds de débogguage et d'interrupteurs power/reset. Bundle Pour terminer on notera que côté bundle, Asus livre pas moins de quatorze (!) câbles Serial ATA, des ponts SLI, Tri SLI et Quad SLI, deux équerres pour port COM, une équerre exposant deux ports USB 2.0 et un port Firewire ainsi qu'un manuel épais qui s'attarde assez longuement sur le fonctionnement du LSI MegaRaid qui n'est pourtant pas intégré, et des autres particularités de la carte. Pour le reste le manuel est d'une conception similaire à celle des manuels grand public d'Asus. Notez au rang des absents dans ce bundle la non-présence d'une équerre USB 3.0. Un adaptateur pour le header VGA aurait également pu être intégré. Page 6 - BIOS/UEFI, logiciels BIOS/UEFI Les origines serveur de la carte mère se retrouvent dans l'interface du BIOS qui, s'il est de type UEFI garde une interface textuelle. Les réglages sont particulièrement nombreux et si globalement l'interface est cohérente, nous avons tout de même noté certains détails qui montrent l'approche à mi chemin entre un produit serveur et celle d'un produit grand public. Notez à titre indicatif que le temps de boot de la plateforme est relativement long puisque nous avons mesuré 28 secondes entre l'allumage et le lancement du système d'exploitation sur un démarrage à froid (en limitant le POST report à 1 seconde). La majorité de ce temps est passé à la détection des processeurs et de la configuration mémoire, on sera pour plus d'une vingtaine de secondes dans le cas d'une configuration complète sans image à l'écran. Si cela peut sembler long au regard des plateformes grand public, c'est un temps court pour une carte mère de ce type.    A l'image des cartes grand public, on retrouve une interprétation du menu AI Tweaker qui permet l'overclocking. Elle est cependant relativement minimaliste, en pratique, passer en mode manuel permet de changer la fréquence d'horloge ainsi que le ratio processeur. Notez cependant que si l'overclocking BCLK est actif, on ne peut pas choisir dans le BIOS le coefficient multiplicateur qui était présent sur les plateformes X79 (voir notre test ici). Si l'on pourra changer le ratio processeur sur un processeur Core i7 débloqué, cela ne sera pas le cas sur un Xeon. Ce type de plateforme n'est pas pensé par Intel pour l'overclocking et si l'effort d'Asus est toujours bon à prendre, en pratique on s'abstiendra. Cela ne veut cependant pas dire que le menu AI Tweaker n'a aucun intérêt. Outre les tensions processeur (Vcore et Vuncore), on retrouve quatre tensions mémoires distinctes. Les canaux ABCD représentent les quatres canaux du premier processeur, et les EFGH ceux du second. Cette flexibilité est particulièrement bienvenue et nous a permis de booter des configurations mémoires pour le moins ésotériques. Ainsi nous avons pu mixer en simultanée sur chaque socket ces barrettes de 4 Go :
Sans réglage particulier, cet ensemble démarre à 1333 MHz 9-9-9, mais nous avons pu forcer 1600 MHz 9-9-9 sans problème. Les contrôleurs mémoires Intel sont relativement flexibles et les réglages de tensions individuels aident dans ce cas, même si cela ne garantit pas que toutes les configurations soient possibles ! Vous noterez au passage que si les réglages de timings sont présents, on ne trouvera pas le réglage de la fréquence mémoire dans cet onglet             Il faudra aller dans le menu avancé pour trouver la longue (!) liste des menus. La vitesse mémoire est cachée dans les réglages chipsets, c'est également ici que l'on choisira les modes de fonctionnement des contrôleurs mémoires (mirroring ou indépendant, et si l'on active ou non NUMA). Du côté des choses plus originales, on notera une option SCU SAS, elle permet de piloter un contrôleur LSI Megaraid, disponible en option et qui transforme les quatre ports SCU en des ports SAS. Au rang des choses originales on notera également la gestion de WHEA , protocole de rapport d'erreur de Microsoft ainsi que la possibilité de faire démarrer une ROM sur n'importe quel slot PCI Express (pour rendre bootable un SSD PCI Express ou une carte RAID additionnelle). Autre particularité, la page de logs qui indiquera les dysfonctionnements matériels, ils servent surtout dans les situations de management à distance pour voir d'éventuels problèmes.       Pour le reste les options sont classiques, on notera tout de même une petite originalité avec l'outil de mise à jour de BIOS, EZ Update dont l'interface reprend le "skin" des BIOS grand public Asus. Logiciels Outre les pilotes, l'offre logicielle d'Asus se résume à deux utilitaires pensés pour la gestion de serveur. Outre un outil de monitoring réseau on retrouve ASWM Entreprise, une suite d'outils dédiée à la gestion à distance de la plateforme et qui requiert de nombreux prérequis, même pour fonctionner localement (le serveur web IIS et SQL Server pour ne citer que ces deux là). Malgré l'installation des prérequis, le fichier d'installation d'ASWM aura refusé de s'installer sur notre plateforme Windows 7. En soit cela n'est pas forcément dramatique pour une utilisation grand public/workstation, et des logiciels comme hwinfo64 nous auront permis d'accéder au monitoring. La fourniture par Asus d'un utilitaire un peu moins contraignant ne serait pas dans l'absolu une mauvaise chose. Page 7 - Configuration, consommation, performances mémoire Configuration Nous avons mesuré les performances de cette plateforme avec trois configurations processeurs différentes :
Pour le reste notre configuration était équipée comme suit :
Dans le cas d'un test mono socket, la quantité de RAM est divisée par deux bien entendu, ce qui n'aura aucun impact en pratique pour nos benchs. En ce qui concerne le système d'exploitation il est important de noter que Windows 7 supporte les plateformes jusqu'à deux sockets. Au-delà, l'utilisation de la déclinaison serveur (Windows 2008 R2) est indispensable. En pratique le noyau de Windows 7 supporte nativement la gestion de NUMA, 2008 R2 n'apportera rien du côté des performances processeurs à ce type de plateforme. Consommation Nous avons mesuré la consommation à la prise dans trois scénarios : au repos, en charge sous Cinebench, en charge sous Prime95. 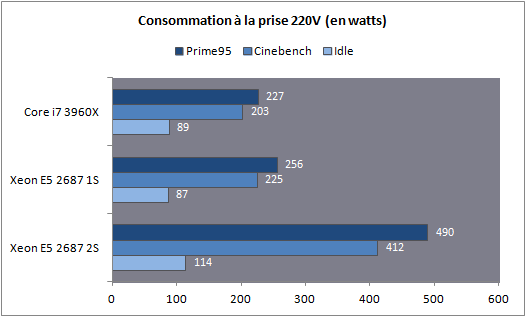 La consommation au repos de notre Xeon E5 seul est équivalente à celle du Core i7 3960X. En charge, on notera que les deux curs supplémentaires engendrent une consommation à la prise d'un peu plus de 29 watts supplémentaires sous Prime95. En ce qui concerne la plateforme 2S, si la consommation au repos est contenue, en charge on va jusque frôler les 500 watts pour la plateforme complète ! Avec de la mémoire registered/ECC, significativement plus gourmande, nous avons atteint les 541 watts à la prise, à titre indicatif, sous Prime95 ! Latence mémoire Nous nous sommes attardés sur les performances théoriques des contrôleurs mémoires, ce qui a été l'occasion de voir les limites de certains benchmarks. Nous avons tout d'abord mesuré la latence mémoire via AIDA64 : 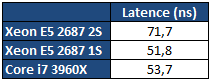 On notera ici un tout petit avantage pour le Xeon E5 par rapport au Core i7, la mesure la plus intéressante étant bien entendue la latence mesurée en mode 2S (2 sockets) : utiliser deux processeurs en simultanée rajoute, malgré NUMA, une vingtaine de millisecondes de latence moyenne. Si vous avez lu le debut de notre article, ce gain de latence ne vous surprendra pas ! Cela pourra être un facteur mitigeant légèrement la scalabilité des performances pratiques. Bande passante multithreadée Terminons enfin les mesures mémoires par RMMT, le bechmark multithreadé intégré à Rightmark. Afin de bypasser le copieux cache L3, les opérations mémoires sont effectuées sur des blocs de 32 Mo pour chaque cur. Comme nous l'indiquions précédemment, ce benchmark est limité à 8 threads en forçant l'affinité sur les curs de manière non optimale, nous limitons donc chaque die à quatre curs pour pouvoir utiliser les deux contrôleurs.  Grâce à NUMA, les performances explosent comme on l'attendait et l'on rate d'un cheveu le seuil des 90 Go/s de bande passante cumulée en lecture ! Si la bande passante mémoire n'est pas toujours un facteur limitant dans les performances pour les applications grand public, il ne faut pas oublier qu'ici, il y a 32 threads à alimenter en mémoire. Cette bande passant ne sera donc probablement pas inutile Mais assez de mesures théoriques, passons (enfin !) à la pratique. Page 8 - Performances Cinebench, Visual Studio, 7-Zip Etant donné que nous souhaitons avant tout voir le comportement multithreadé de ces Xeon, nous avons exclu de nos tests des applications peu threadés (telles les jeux) qui ne profiteraient pas réellement d'une telle augmentation du nombre de curs. Afin de rester dans l'esprit de cet article nous n'utilisons pas non plus de benchmarks spécifiques aux serveurs, il s'agit avant tout d'avoir un aperçu du potentiel d'une telle plateforme dans les benchmarks ou les Core i7 hexacores brillaient déjà. Cinebench R11.5  Afin de mesurer les performances en rendu 3D, nous avons utilisé Cinebench en version R11.5. Le logiciel utilise pour rappel le moteur de rendu du logiciel professionnel Cinema 4D. 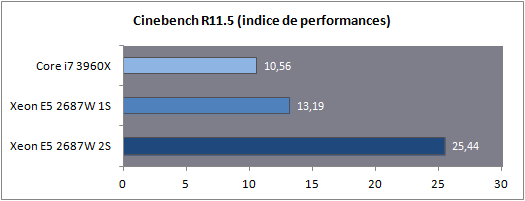 Les choses commencent ici fortement pour le Xeon E5 2687W qui, avec deux curs de plus, propose 25% de performances en plus que son comparse le Core i7 3960X. En mode 2S, la scalabilité est excellente puisque l'on gagne 92.9% de performances en ajoutant un processeur supplémentaire. Voir les 32 threads faire une bouchée du rendu sous Cinebench ne laisse pas indifférent. Visual Studio 2011 beta  Nous avons opté pour la version 2011 en beta de Visual Studio. Nous compilons pour l'occasion la dernière version (1.7.4) du code source du moteur 3D Ogre (exemples inclus). La compilation parallèle est activée pour chaque projet sous VS. 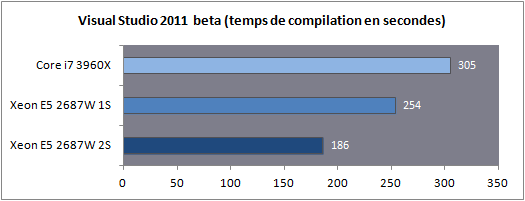 De manière similaire, on notera que le Xeon du haut de ses huit curs permet d'augmenter les performances de 20% par rapport au Core i7. L'ajout d'un second processeur apporte encore un gain de 36.6%, beaucoup plus mesuré, toutes les opérations réalisées par VS n'étant pas suffisament multithreadées. 7-Zip 9.20  Nous utilisons la version 9.20 de 7-Zip pour compresser un volume important de fichiers en utilisant l'algorithme LZMA2. 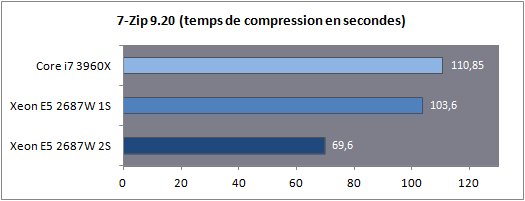 Ajouter deux curs supplémentaires provoque un gain assez mesuré de seulement 6%. L'ajout d'un second socket est beaucoup plus rentable avec 48.9% de gain, malgré le fait que le mode mémoire NUMA ne réussisse pas beaucoup à ce benchmark comme nous l'avions vus un peu plus tôt. Page 9 - Performances Staxrip - x264, Bibble Staxrip - x264 b2197  Passons au frontend Staxrip que nous utilisons pour transcoder une scène du film Avatar via x264 en build 2197. Nous réalisons un encodage en 2 passes type medium sur une source 720p, réencodée à un bitrate de 6 Mbits/s. Pour rappel la seconde passe est celle qui profite le plus du multithreading. 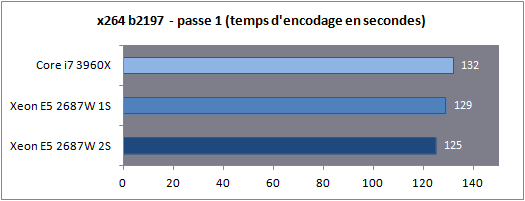 [ Passe 1 ] [ Passe 2 ] Si les gains sur la première passe sont négligables, ils sont beaucoup plus nets sur la seconde. Le passage du Core i7 au Xeon entraine 25% de gain tandis que l'ajout du second socket permet de rajouter 64% de performances. Bibble 5.2.3  Nous traitons un lot de 48 photos RAW, exportées en JPEG. 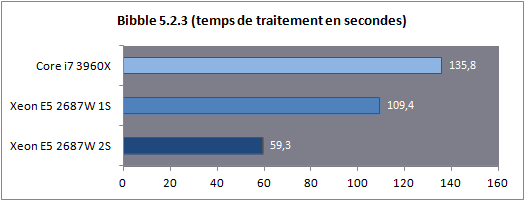 Si le Xeon apporte uen fois de plus un gain aux alentours de 24%, Bibble tire pleinement profit du second socket avec 84.5% de performances en plus obtenues ! Page 10 - Conclusion C'est un peu sans surprise que l'on note les performances, énormes, du Xeon E5-2687W dans les applications multithreadées. Avec deux curs en plus, il corrige assez souvent le plus extrême des Core i7, le 3960X qui n'est pourtant pas exactement lent dans ce type d'applications. Ce Xeon nous donne donc d'un côté quelques regrets sur ce qu'aurait pu être la gamme Core i7 LGA 2011, et de l'autre un espoir que le constructeur se décide à nous offrir une telle puce "grand public" rapidement dans sa gamme.  Evidemment, lorsque l'on en cumule deux, les performances explosent dans les applications qui gèrent correctement le multithreading et si les mécanismes de partage de mémoire ont un coût, des gains de 80% ou plus ne sont pas rares pour peu que les applications soient correctement écrites. Du côté de la carte mère on doit adresser une mention spéciale à Asus qui a essayé de proposer une interprétation moderne d'une carte mère "workstation", genre généralement très convenu où des choses banales comme la possibilité de régler des tensions, la présence d'un codec audio ou même d'un port S/PDIF sont souvent aux abonnées absents. Le BIOS au boot rapide est appréciable et si l'on retrouve les origines serveurs dans certains coins de la carte (le contrôleur VGA intégrée par exemple, ou l'offre logicielle), le compromis trouvé est pour le moins intéressant pour ceux qui souhaiteraient se monter une telle configuration.  A défaut de souhait, on ferait d'ailleurs peut être mieux de parler de rêve. Parce qu'au-delà de la curiosité qui nous animait à voir ce qu'avait dans le ventre le plus rapide des Xeon E5, la question du tarif nous fait rapidement redescendre sur terre. Les Xeon E5-2687W sont en effet vendus, par 1000 unités à un prix de 1885 dollars. Pièce. A côté, le prix de la carte mère d'Asus est raisonnable à "seulement" 495 euros. Heureusement, le droit de rêver reste, lui, gratuit Copyright © 1997-2026 HardWare.fr. Tous droits réservés. |