| |
| |
| Impact des compilateurs sur les architectures CPU x86/x64 Processeurs Publié le Mardi 28 Février 2012 par Guillaume Louel URL: /articles/847-1/impact-compilateurs-architectures-cpu-x86-x64.html Page 1 - Introduction IntroductionLes compilateurs impliquent-ils un biais dans les mesures de performances des processeurs ? La question est légitime, et parfois posée lorsque nous réalisons des comparatifs de processeurs. Le fait qu'Intel et AMD proposent leurs propres compilateurs est évidemment un indice et certaines pratiques passées ont contribué à semer le doute. Plus récemment, la Federal Trade Commission américaine avait, entre autre, enquêté sur les pratiques des compilateurs d'Intel, mettant en avant le fait que ces derniers offrent des optimisations non pas pour un niveau de support donné (présence du SSE 4 dans la puce par exemple), mais pour des modèles de processeurs précis (Core i7 seconde génération, etc). L'enquête s'est terminé sur un accord qui, au final, ne changeait pas grand-chose à la donne côté compilateurs.  Une des rares conséquences de l'accord Intel/FTC, l'inclusion dans la documentation de cette mention. La question des optimisations reste cependant posée et nous avons voulu nous pencher sur le sujet pour voir si, oui ou non, un impact pouvait se ressentir et dans quelles proportions. Afin d'être complets, nous reviendrons brièvement sur les différents types d'optimisations qui sont proposées dans les compilateurs et leurs impacts. Afin de réaliser ce test nous avons eu l'occasion d'utiliser des applications dont le code source nous était disponible. Il s'agit d'un point important à prendre en compte et qui permet à la fois de relativiser mais aussi de mesurer la complexité du problème : si l'on peut toujours recompiler un logiciel open source, ce n'est pas le cas des applications du commerce. Impossible de recompiler Adobe Photoshop pour son modèle précis de processeur, les choix réalisés par les développeurs en matière de compilateur - et d'options de compilations - ne peuvent être que subis par les utilisateurs finaux. Il s'agit d'un point important qu'il faudra garder en tête ! Page 2 - C, C++, rôle du compilateur C, C++, rôle du compilateurPour cet article, nous nous sommes intéressés plus particulièrement aux compilateurs C/C++. Développés respectivement à la fin des années 60 et 70, C et C++ sont des langages de programmation extrêmement populaires conçus à l'origine pour Unix. Ils sont utilisés majoritairement encore aujourd'hui pour la conception d'applications sous Windows. C est le plus ancien, il s'agit d'un langage dit procédural - à base de fonctions - tandis que C++ aura apporté entre autre la notion d'orientation objet (ou de multi paradigme pour les puristes). Si C continue à être très populaire sous Unix et ses dérivés (Linux ou MacOS via Objective-C), sous Windows c'est généralement C++ qui a la primeur, Microsoft ayant favorisé C++ dans ses API depuis les années 90 (comme par exemple MFC, l'une des bibliothèques qui permet de concevoir les interfaces graphiques des applications Windows). Ces deux langages ayant une parenté commune (C++ ayant été développé comme une extension de C à l'origine, même si au fil des années les langages ont divergés), les compilateurs sont généralement communs entre les deux langages. Interprété, compilé, à la voléeContrairement à des langages simplifiés comme le BASIC ou un interpréteur va lire, ligne à ligne, votre programme pour l'interpréter et le traduire dans un code lisible par le processeur, C et C++ se classent dans la catégorie des langages compilés. Les développeurs écrivent leurs logiciels dans ces langages puis lancent l'opération de compilation. Le but de la compilation étant de traduire le programme C/C++, relativement lisible, en code exécutable directement par le processeur (langage machine). Cette particularité permet à C/C++ d'être des langages (relativement) portables, on peut ainsi compiler un programme pour différents types d'architectures (ARM, PowerPC, ou x86 par exemple). Dans une architecture donnée, on pourra aussi réaliser des compilations optimisées pour certaines variantes, comme par exemple des versions 32 bits et 64 bits de son application, ou bien des versions spécifiques pour une architecture donnée (version d'une application nécessitant SSE2 par exemple). A moins donc d'avoir accès au code source du programme et à un compilateur, on doit donc subir les optimisations et les choix effectués par les développeurs, ce qui est l'une des raisons de ce dossier.  Un extrait de code C. main indique la fonction d'où débute le programme. Car en effet même pour un "standard" donnée comme le x86, toutes les puces ne sont pas égales. Si les processeurs AMD et Intel - à génération équivalente - sont capables de faire tourner les mêmes instructions machines, les ingénieurs d'AMD et d'Intel peuvent avoir privilégié certaines instructions face à d'autres. La division peut par exemple être plus rapide sur un processeur qu'un autre. La compilation, à la manière de la traduction d'une langue à l'autre, n'est en effet pas une science exacte : on peut compiler un même programme de manières différentes. Si les programmes finaux effectueront le même travail (sauf erreur de compilation), leur code en langage machine sera différent. Le fait que x86 soit une architecture processeur qui comporte un très grand nombre d'instructions (une ISA CISC, à contrario des ISA RISC dont le jeu d'instruction est volontairement réduit) donne une marge assez large, x86 comportant de nos jours, avec les diverses extensions (MMX, SSE, etc) plus d'un millier d'instructions . La manière dont un compilateur fonctionne semble donc théoriquement très importante sur les performances finales, et on ne sera pas surpris de voir que et AMD et Intel non seulement participent activement au développement des compilateurs existants (que ce soit celui inclut dans Visual Studio de Microsoft, ou l'open source GCC) mais proposent également leurs propres compilateurs. Il est à noter que depuis quelques années la problématique commence à changer avec des langages comme Java/JVM et C#/.NET. Développés respectivement par Sun et Microsoft, ces langages assez populaires dans les applications d'entreprise (mais ayant une traction plus limitée dans les applications grand public, même si par exemple les panneaux de contrôle graphiques d'AMD et d'Intel sont réalisés en C#/.NET) ont la particularité d'être compilés pour ce que l'on appelle une machine virtuelle. Il s'agit en effet d'un mix entre les concepts de langages interprétés et compilés : avec Java ou C#, le programme est compilé dans un langage intermédiaire, celui de la machine virtuelle (JVM/.NET). Au lancement, la machine virtuelle effectuera une compilation finale du programme, directement adaptée à la machine sur laquelle elle tourne (on parle de compilation JIT, Just In Time, ou à la volée). L'intérêt de la machine virtuelle est assez facile à comprendre, on peut ainsi supporter facilement plusieurs ISA et/ou plusieurs systèmes d'exploitations, c'est l'un des arguments qui a porté Java par exemple. Pour ce qu'il s'agit des optimisations qui pourraient favoriser ou non une marque de processeur, la situation change : c'est celui qui contrôle la VM qui contrôle les optimisations qui seront incluses, ou pas. Notez enfin que si C/C++ sont principalement compilés, il est possible (avec quelques restrictions) d'utiliser C++ avec .NET. A l'inverse, C/C++ peuvent être également compilés à la volée via une plateforme open source comme Clang/LLVM . Seul défaut de la solution, elle est aujourd'hui très mal supportée sous Windows puisqu'elle ne supporte pas certaines extensions "Microsoft" au langage C/C++. En effet, si C et C++ sont des langages standardisés, leur implémentation peut varier d'un compilateur à l'autre. D'une parce qu'il existe plusieurs versions des standards (versions ANSI, ISO, C9, C11 rien que pour le C) mais aussi car ils sont ouverts à de nombreuses extensions. Pire, certains compilateurs n'implémentent que partiellement les normes établies, ce qui est notoirement le cas des outils de Microsoft. Compiler un même programme sous trois environnements différents est un challenge ! Page 3 - Optimisations et performances Optimisations et performancesComme nous l'évoquions précédemment, il n'y a pas qu'une seule manière de traduire un programme C en langage machine exécutable par un processeur. Les compilateurs tentent donc de se démarquer en proposant des options, des optimisations qui ont pour but, en général, d'améliorer les performances. Avant d'aller plus loin et de clarifier ce que nous entendons par optimisation, il est important de relativiser l'impact que le compilateur peut avoir. En effet si les compilateurs sont de plus en plus intelligents, et peuvent parfois proposer des optimisations et des gains de performances redoutables, ils ne sont pas miraculeux et ne peuvent pas automatiquement transformer un algorithme (la logique du programme) lent et mal conçu en quelque chose de très rapide. Qu'il s'agisse de parallélisme (utiliser tous les curs) ou d'optimiser l'exécution sur les processeurs modernes, les compilateurs tentent de faire de leur mieux à partir du code écrit par les développeurs. Pour compliquer la chose, la barrière qui sépare ce qui est du ressort du développeur et du compilateur est de plus en plus fine. Si la gestion des multiples curs en parallèle est censée être du ressort du développeur, certains compilateurs s'aventurent (souvent mal) sur ce terrain. A l'inverse la prise en compte de l'architecture du processeur, censée être complètement cachée par le C/C++ et purement du ressort du compilateur peut être prise en compte par les développeurs via divers mécanismes censés aider à ce que le compilateur comprenne leurs intentions. Vouloir profiter au maximum des performances des processeurs modernes, à défaut d'être un art, est donc très souvent un difficile numéro d'équilibrisme, aussi bien pour le développeur que pour le compilateur. Ceci étant posé, revenons sur les différentes optimisations que l'on pourra retrouver au sein des compilateurs ! Réduire la tailleDans un temps ancien, la qualité d'un compilateur se jugeait à la taille du fichier exécutable (le code machine compilé) qu'il produisait. A une époque ou le stockage était couteux, l'économie de quelques kilo-octets n'était pas quelque chose de négligeable. Mais au-delà du simple gain de place, réduire la taille était considéré comme une optimisation de performances. Etant donné que nos processeurs se distinguent sur leur capacité à exécuter le maximum d'instructions par seconde, réduire le nombre d'instructions directement dans le programme en réduisant sa taille peut paraitre une piste intéressante !  S'il y a un fond de vérité, de nos jours cependant la question de la taille de l'exécutable est plus complexe. Toutes les instructions n'ont en effet pas le même temps d'exécution. Sur l'architecture Sandy Bridge d'Intel par exemple, là où une addition ( add) aura une latence d'un cycle (un hertz du total de GHz du processeur), une multiplication entière (imul) en prendra trois et la division (div) 26 ! Des chiffres qui, qui plus est, ne sont pas constants d'un processeur à l'autre : sur un Pentium 4 F la multiplication avait une latence de 10 cycles. La chose se complique encore lorsque l'on prend en compte le fait que les curs de processeurs, nous en parlons souvent dans nos articles sur l'architecture des processeurs (Bulldozer, Sandy Bridge), disposent dans chacun de leurs curs de multiples unités (on parle d'architectures super scalaires, la possibilité d'exécuter plusieurs instructions par cycle, une nouveauté introduite par le Pentium). Ainsi, un processeur Sandy Bridge peut réaliser trois additions en simultanées en un seul cycle, ce qui est aussi le cas d'un Phenom II par exemple. Dans le cas de l'architecture Bulldozer, ce nombre tombe à deux par cur (les curieux pourront retrouver une liste complète des latences et débits des instructions sur de multiples architectures x86 dans ce document PDF de Torbjörn Granlund ). Optimiser pour la taille reste malgré tout une option présente dans les compilateurs, nous noterons dans nos tests pratiques un peu plus tard un cas ou cela aura été bénéfique. Dans la majorité des autres cas, cette option ralentissait les performances. Page 4 - Optimiser pour une architecture CPU Générer un code optimisé pour une architecture CPUVous l'aurez deviné, s'il y a des différences fortes dans la manière dont les processeurs traitent les instructions, il est possible pour les développeurs de compilateurs d'optimiser le code qu'ils génèrent afin de prendre en compte les particularités de chacun. Avec l'arrivée du Pentium et des processeurs super-scalaires, l'ordre dans lequel le compilateur aura placé les instructions est devenu excessivement important. Placées correctement, deux additions pouvaient avoir lieu en simultanée sur cette architecture, un doublement de performances gratuit qu'il fallait obtenir à la main : à l'époque les compilateurs n'étaient pas aussi évolués et ne savaient pas prendre en compte cette différence pour générer un code optimisé. Cela a poussé Intel à proposer ensuite avec les Pentium Pro un nouveau type d'architecture, on parle alors de "Out Of Order" ou OOO. Derrière l'acronyme se cache un concept simple, permettre au processeur de changer l'ordre des instructions pour utiliser au mieux les unités super-scalaires. Si à l'époque il s'agissait surtout de maximiser l'utilisation de toutes les unités, aujourd'hui les moteurs d'ordonnancements continuent d'évoluer pour compenser les évolutions des processeurs modernes : aujourd'hui, cacher au maximum la latence des accès mémoires (en traitant le plus tôt possible les opérations de lectures mémoire pour qu'elles soient là lorsque le processeur en aura besoin) est devenu la nouvelle préoccupation, la rapidité des accès mémoire n'évoluant pas aussi rapidement que l'augmentation des performances arithmétiques des processeurs. Depuis l'arrivée du Pentium Pro en 1995 la tendance aura toujours été la même : intégrer au niveau hardware un maximum de nouveautés (super scalaire, OOO, caches, MMU, prefetchers, etc) pour permettre de tirer une efficacité maximale d'architectures qui deviennent de plus en plus complexes. En disant cela, on pourrait penser que le rôle du compilateur diminue tant les processeurs modernes sont capables de gommer par eux même certaines lourdeurs du code que l'on leur demande de traiter. En pratique, il existe toujours cependant des cas ou les choix réalisés par le compilateur sera d'importance. Le choix des instructions par exemple reste crucial. Pour prendre un exemple qui nous ramène au 21eme siècle, les instructions AVX sont disponibles pour la plupart dans deux variantes : 128 bits et 256 bits (le nombre de bits indique la taille des opérandes, les données sur lesquelles les instructions travaillent) et il est généralement possible de remplacer une instruction 256 bits par deux instructions 128 bits. Comme nous l'avions vu à l'époque en évoquant son architecture, un module bulldozer consiste en une fusion de deux curs au sein d'un module ou un certain nombre de ressources sont partagées. Parmi celles-ci, il y a le cas de l'unité virgule flottante, en charge de l'exécution des instructions SSE (128 bits) et AVX (128 ou 256). Elle est particulière car découpée en deux morceaux pouvant travailler indépendamment en mode 128 bits. Cependant s'il faut réaliser une instruction 256 bits, les deux blocs devront se synchroniser et travailler ensemble, ce qui peut avoir un cout. Ainsi mélanger des instructions 128 et 256 bits peut nuire à l'efficacité. Pour prendre en compte cette particularité, le compilateur GCC tentera, si l'on lui demande d'optimiser pour un processeur Bulldozer (architecture bdver1) de favoriser l'utilisation d'instructions AVX128. 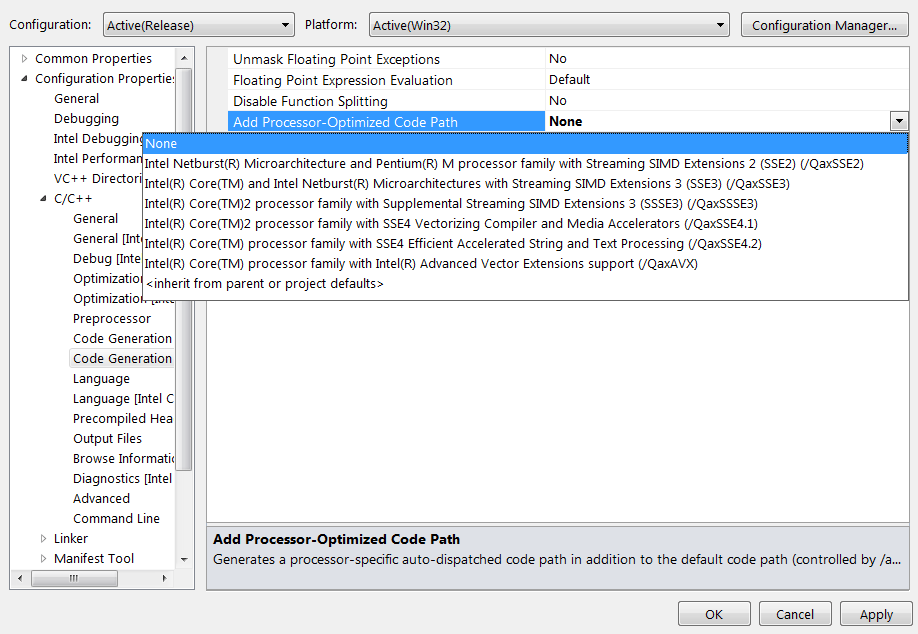 Plutôt que d'optimiser pour une architecture, le compilateur d'Intel permet d'optimiser pour un modèle donné de processeur de marque Intel. Le problème s'épaissit lorsque l'on prend en compte certaines instructions spécifiques du langage C/C++. Si les opérations mathématiques classiques peuvent se traduire simplement en langage machine, pour d'autres tâches, le langage offre des fonctions qui simplifient la tâche des programmeurs. C'est par exemple le cas de la manipulation de chaines de caractères (des suites de lettres ou de chiffres) ou encore la manipulation de blocs mémoire (en pratique, la manipulation de chaines repose sur la manipulation de mémoire). Le langage C/C++ propose des fonctions qui vont être traduites, par le compilateur, par des morceaux de langage machine relativement longs. Et donc optimisables ! La latence dans l'accès aux données, la taille des caches, le fonctionnement interne des prefetchers et de la MMU peuvent être pris en compte par des développeurs zélés au moment de la compilation, tout comme les instructions disponibles sur le processeur. Ainsi, comme nous le verrons plus tard, le compilateur d'Intel dispose d'implémentations spécifiques de ces fonctions pour chacun de ses processeurs. L'optimisation pour une architecture n'est donc définitivement pas enterrée et l'empiètement du hardware sur le terrain du compilateur se compense par une complexification des optimisations. Et puis, il y a la vectorisation Page 5 - SSE, AVX : le problème de la vectorisation SSE, AVX : le problème de la vectorisationPlus tôt, nous évoquions le fait qu'AVX permette de travailler sur des opérandes (des données) d'une taille de 128 ou 256 bits. Il s'agissait d'un raccourci. En effet, la plupart du temps les programmeurs travaillent avec des nombres encodés sur 32 (entre -2,1 milliard et +2,1 milliard environ) ou 64 bits (on parle de double précision+/- 9 trillions). Il s'agit des types de données qui sont proposés par les langages de programmation comme C et C++. Si l'on met de côté quelques cas très rares, stocker et travailler sur des nombres sur 128 ou 256 bits n'a généralement pas beaucoup d'intérêt, et ce n'est d'ailleurs pas vraiment à cela que sert AVX. L'acronyme, qui signifie Advanced Vector eXtension donne la réponse : il s'agit d'instructions vectorielles, c'est-à-dire capables de travailler sur un tableau de données. Une instruction AVX 256 bits peut ainsi travailler sur 8 données de 32 bits en simultanée, ce qui permet d'améliorer significativement la rapidité d'exécution d'un programme, pour peu que l'on ait besoin d'effectuer 8 opérations identiques en parallèle ! 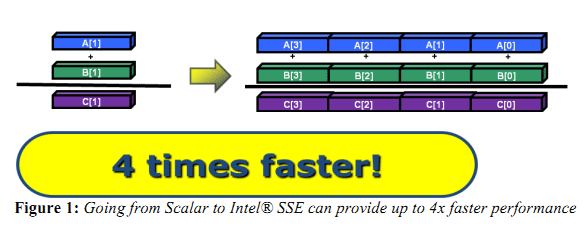 Le cas idéal de la vectorisation, travailler sur quatre données en simultanée permet de quadrupler la rapidité d'execution. Extrait d'un PDF Intel C'est bien sûr ici que les choses deviennent complexes car les langages que sont C et C++ ne sont pas réellement adaptés à cette vision sous forme de tableaux. Les programmes utilisent des variables, qui stockent les informations en fonction de leur type (nombre entier, nombre à virgule, etc) et s'il existe bien une notion de tableaux (plusieurs données du même type), le langage ne fournit pas d'opérations qui s'appliquent directement à ceux-ci (comme ajouter le contenu d'un tableau A à un tableau B). C'est le rôle du développeur de réaliser des algorithmes qui effectueront ces opérations, dont certaines deviennent aujourd'hui accélérées par les processeurs via AVX. En pratique, l'absence de structures (dans C et C++) nativement adaptées à la manière dont fonctionnent désormais en interne les processeurs devient un vrai problème pour lequel plusieurs réponses sont apportées. Remplacer les opérations mathématiquesDans certains cas, utiliser une instruction vectorielle avec une seule donnée peut être plus rapide qu'utiliser son équivalent classique. C'est particulièrement le cas lorsque l'on parle de calculs en virgule flottante pour des raisons historiques. En effet ces opérations que l'on appelle x87 étaient gérées dans les années 80 par des coprocesseurs arithmétiques. Même si ces dernières ont été fusionnées dans les processeurs (via les 486 DX et les Pentium), elles gardent les lourdeurs de fonctionnement de l'époque, à savoir une gestion qui s'effectue sous forme de pile. SSE, SSE2 et AVX proposent aujourd'hui des instructions qui permettent de remplacer x87, laissant tomber le concept de pile et rendant leur exécution beaucoup plus rapide. Utiliser une instruction vectorielle pour une seule donnée peut donc être plus rapide. Notez que si tous les compilateurs proposent ce genre d'optimisations, par défaut, Visual Studio continue de compiler en x87. Vectorisation automatiqueSi l'on veut vraiment profiter de la puissance de calcul en parallèle offerte par les instructions vectorielles, on pourrait penser qu'il serait bon de demander aux compilateurs de détecter les cas où les développeurs travaillent sur des tableaux dans leurs programmes. Le compilateur pourrait alors réaliser une vectorisation automatique. Dans ce cas, le compilateur interprète le code C/C++ (il s'agit généralement de boucles qui répètent une instruction) pour générer automatiquement du code en langage machine utilisant des instructions vectorielles. En théorie, l'idée est excellente. En pratique, le code existant n'est pas forcément écrit pour être vectorisé. En dehors des cas simples, il faudra souvent que le développeur réécrive son code pour retirer des dépendances. En effet si à l'heure du multimédia on peut penser que tous les traitements sont parallèles, le niveau de parallélisme (on parle de granularité) ne s'arrête pas forcément à une instruction dans les cas pratiques. Quand elles s'enchainent, et que les résultats d'un traitement peuvent dépendre d'un résultat précédent (ce que l'on appelle une dépendance), la vectorisation devient rapidement impossible (d'autres problèmes existent comme la gestion des sauts dans le code qui ne convient pas réellement au SIMD). Il est souvent possible de réécrire son code pour qu'il le devienne, mais le compilateur, seul, ne peut pas interpréter "l'idée" derrière un algorithme complexe pour le réécrire à la place du développeur, probablement dans une version moins lisible ou logique pour lui, mais qui le deviendrait pour le compilateur. En pratique, nous le verrons, les résultats de la vectorisation automatique sont loin d'être au niveau des autres techniques. L'assembleurC'est la solution la plus simple techniquement, plutôt que de demander l'impossible au compilateur, le développeur peut décider d'écrire lui-même en assembleur (une version "lisible" du langage machine) certains morceaux de son programme. Si les gains que l'on peut obtenir sont excellents (nous le verrons avec x264), en pratique très peu de développeurs choisissent cette route, car elle est tout simplement très complexe. IntrinsèquesIl s'agit d'une option un peu plus flexible. Plutôt que de devoir écrire des morceaux d'assembleurs, les intrinsèques proposent des raccourcis en langage C vers les instructions AVX. Leur manipulation reste plus ou moins complexe et diffère d'un compilateur à un autre, ce qui peut limiter la portabilité du code. Elle n'est pas réellement employée dans les logiciels que nous avons testés (qui sont open sources et portables). PrimitivesLes développeurs peuvent également se reposer sur des bibliothèques externes qui ont été optimisées pour tirer partie des processeurs modernes. Il s'agit souvent de bibliothèques qui implémentent des algorithmes réutilisables par les développeurs. Intel livre avec son compilateur une telle bibliothèque baptisée Performance Primitives qui propose des implémentations diverses et variées (allant de choses simples comme la manipulation de matrices à des blocs de code complexes comme le décodage et l'encodage d'images JPEG ou de vidéo H.264 !). L'utilisation de ces primitives limite bien entendu à l'utilisation du compilateur d'Intel. Au final, l'utilisation de nouvelles instructions reste souvent un problème pour les développeurs en C/C++. Les langages étant relativement peu adaptés à la manière dont fonctionnent désormais nos processeurs, les solutions pour en tirer partie deviennent soit très complexes (réaliser soit même du code en assembleur), soit forcent à l'utilisation d'extensions propriétaires, ce qui fait perdre le côté standard du langage, et lie le développeur bon gré mal gré au fournisseur de ses outils de développements. Ce qui peut être un problème potentiel quand le fournisseur du compilateur est également un vendeur de processeur. Page 6 - Générique, ciblé, dispatché Générique, ciblé, dispatchéSi nous avons parlé de la manière dont sont prises en compte les différents modèles de processeurs dans les optimisations que proposent les compilateurs, nous avons éludé la question la plus importante : comment arriver à réaliser un programme qui fonctionne de manière optimale sur tous les processeurs existants ? Malheureusement, les compilateurs ne répondent pas réellement à cette question. Les développeurs ont donc plusieurs choix : Privilégier la compatibilitéC'est l'option la plus simple, et souvent celle choisie par les développeurs : réaliser un seul fichier exécutable dont l'intégralité du code fonctionnera sur tous les processeurs x86 modernes (généralement, à partir du Pentium Pro). Le compilateur ne génèrera alors aucun code utilisant les jeux instructions SSE ou AVX. C'est le mode de fonctionnement par défaut des compilateurs. Multiples buildsLes compilateurs étant particulièrement doués pour réaliser des versions spécifiques pour un modèle de processeur donné, les développeurs peuvent simplement réaliser plusieurs versions (on parle de builds) optimisées chacune pour différents types de processeurs. On pourra ainsi trouver pour certains projets (très souvent des projets open source) des versions classiques, ainsi que des versions SSE2 ou autre (ces builds SSE2 utilisant les opérations arithmétiques SSE2 en lieu et place du x87). Dispatcher manuelLes développeurs qui utilisent du code assembleur peuvent choisir de réaliser de multiples builds, mais ils peuvent également choisir la voix du dispatcher. Le concept est relativement simple, ajouter au démarrage du programme une vérification sur les capacités du processeur sur lequel on tourne. Dans ce cas, les développeurs peuvent aller très loin et proposer des sections assembleur pour de nombreux modèles de processeurs (des accélérations SSE, SSE2, AVX, etc...), y compris qui ne soient pas x86 (on peut trouver du code NEON, les instructions SIMD gérées par les processeurs ARM). Cela réclame un travail important de la part des développeurs. x264 propose un tel dispatcher. Dispatcher automatiqueLa dernière option consiste à demander au compilateur de générer une version du programme qui inclut un dispatcher. En plus d'une version basique fonctionnant partout, il peut ainsi être ajouté, par le compilateur, des optimisations ciblant un processeur donné. On peut ainsi profiter d'une large compatibilité, et de performances évoluées sur un modèle de processeur donné. En théorie, cela semble parfait... Page 7 - Les compilateurs : Microsoft, Intel, GCC Les compilateursAfin de réaliser notre dossier nous avons utilisé trois environnements de compilation différents : Visual Studio 2010 SP1, Intel C++ Compiler XE 12.0u5, et TDM-GCC (MinGW/GCC 4.6.1). Visual Studio 2010 SP1L'environnement de développement de Microsoft est sans trop de surprise le plus répandu sous Windows. Côté optimisations, on notera que s'il propose la génération de code SSE, SSE2 et AVX (uniquement par l'ajout d'un switch en ligne de commande pour ce dernier, l'option n'est pas disponible dans l'interface de Visual Studio 2010), il ne propose pas de vectorisation automatique. Il ne propose pas non plus de dispatcher automatique.  Le compilateur intégré à Visual Studio (on l'appellera cl par la suite, du nom de son exécutable) est de loin le plus pointilleux au niveau de ce qu'il est capable de compiler. L'implémentation (très) partielle des standards C/C++ pose un certain nombre de problèmes d'interopérabilité avec les autres compilateurs. S'il existe de multiples éditions payantes, Microsoft propose depuis quelques années une version gratuite de Visual C++, baptisée Express. Elle est disponible en téléchargement sur le site de Microsoft. Intel C++ Compiler XE 12.0u5Intel propose lui aussi son propre compilateur sous Windows. Il repose en partie sur des composants réalisés par l'Edison Design Group et très fortement customisés par Intel. D'un point de vue pratique, il a la particularité de s'intégrer facilement avec Visual Studio et de permettre de convertir facilement ses projets. On peut d'ailleurs passer à tout moment d'un compilateur à l'autre si l'on le souhaite ce qui est un très bon argument pour convaincre les développeurs de l'essayer. Côté optimisation, ICC est extrêmement riche, en proposant entre autre la vectorisation automatique. Il est également capable de générer des builds ciblées pour différents niveaux de fonctionnalités de processeurs (les options QxSSE2, 3, 4.1, 4.2, AVX...) ainsi que réaliser une version dispatchée, mais pour un niveau donné uniquement. L'option QaxAVX par exemple fera tourner la version AVX de son code sur les processeurs compatibles AVX, et une version de base (SSE2) sur tous les autres processeurs. En soit on peut comprendre l'intérêt de cette implémentation pour Intel : un programme compilé avec l'option QaxAVX fonctionnerait sur un processeur Sandy Bridge avec un code généré de manière optimale pour un processeur AVX (ce qui inclut le code généré pour la gestion des chaines de caractères et de la mémoire), et en mode SSE2 sur un Core i7 « Nehalem». Si l'on était taquin, nous dirions que cela permet pour certains benchmarks présentés par le constructeur dans certaines de ses présentations de creuser les écarts générationnels. L'utilisation du compilateur d'Intel dans Visual Studio ne demande qu'un clic L'autre problème de ces options est que contrairement à ce que sous entendent le nom des options, le compilateur d'Intel rajoute une vérification de la marque du processeur. C'était d'ailleurs l'un des problèmes évoqués par l'enquête de la FCC contre Intel. Une des conséquences (connues) de l'accord passé entre AMD, Intel et la FCC est que la documentation d'Intel regorge désormais d'avertissements sur le fait que les processeurs «non Intel» peuvent être traités différemment des processeurs Intel, sans plus de précisions. Nous allons tenter de voir en pratique si Intel a changé ses pratiques ou non. ICC a également la réputation d'être le compilateur le plus performant, une réputation que nous allons vérifier ! Notez enfin qu'ICC intègre un troisième mode d'optimisation ( arch:SSE2 par exemple) qui permet de réaliser une build directement pour un niveau de fonctionnalité donné, et non plus pour un processeur Intel donné. La documentation de la version d'ICC que nous utilisions n'indiquait que le support de SSE4.1 au maximum pour cette option, SSE4.2 et AVX étant absent. Cependant, l'utilisation des paramètres arch:SSE4.2 et arch:AVX est bien possible La solution idéale ? En pratique pas forcément, comme nous le verrons rapidement. ICC est un outil payant, proposé par Intel dans de nombreuses éditions , une version d'évaluation est cependant disponible. TDM-GCC (MinGW/GCC 4.6.1)Issu du monde de l'Open Source, GCC est un compilateur dont la vocation historique tendait d'abord à l'universalité. Il existe ainsi pour toutes les architectures (même si cela ne veut pas dire qu'un même code sera compilable partout, des différences subtiles particulièrement autour de la gestion de la mémoire posent souvent problème lorsque l'on tente de réaliser du code "cross-compatible", par exemple qui soit compilable et sous ARM, et sous x86) et est disponible pour quasi tous les systèmes d'exploitations. Pour pouvoir fonctionner sous Windows, GCC requiert un environnement de développement. Deux principaux sont disponibles, d'un côté Cygwin et de l'autre MinGW. Cygwin propose un environnement de développement POSIX complet qui permet de compiler un programme Unix et de le faire fonctionner sous Windows. Une implémentation qui n'est pas sans intérêt, mais qui a un coût pratique certain sur les performances. De nos jours les applications Open Source sous Windows se reposent principalement sur MinGW un environnement minimaliste pour Windows qui sert de pont entre GCC et l'OS, notamment en donnant accès à certaines DLL systèmes essentielles de Microsoft dont la fameuse msvcrt.dll, MS Visual C++ Runtime qui posait tant de problèmes sous Windows 95 et 98.  Cette DLL propose entre autre des implémentations pour les fonctionnalités standard de C/C++ (manipulation de chaines de caractères et d'espace mémoire). Dans le cas de la compilation d'un programme en C pur, ce sont ces routines Microsoft qui seront utilisées par le programme. La DLL étant très ancienne (1998), ses implémentations sont désuètes a l'égard des processeurs modernes ce qui désavantage assez sérieusement les programmes C compilés avec. Le problème ne se pose pas pour C++, GCC disposant dispose d'une bibliothèque standard pour ces fonctions. Il faudra garder en tête ce désavantage lorsque nous évaluerons les performances. Enfin, notez que si la volonté originale de GCC était l'universalité - ce qui lui a longtemps valu une réputation de performances moindres - depuis quelques temps les développeurs misent beaucoup sur les performances. On trouvera donc un grand nombre d'optimisations, de la vectorisation automatique à la génération de mathématiques SSE2 (AVX est partiellement géré) mais également des profils pour un grand nombre d'architectures x86. Nous avons utilisé pour ces tests la distribution TDM-GCC , plus à jour que la distribution originale. Elle inclut GCC en version 4.6.1. Et AMD ?Contrairement à Intel, AMD ne développe pas directement de compilateur. Cela ne veut pas dire que le constructeur ne travaille pas sur le sujet. D'abord, AMD participe (comme Intel) au développement de GCC. Microsoft travaille également activement avec AMD et Intel pour obtenir un support cohérent (et selon eux, non biaisé) dans leurs compilateurs, ainsi que pour les langages managés (.NET) ou des optimisations pour les deux marques existent également. Enfin, AMD sponsorise et distribue un fork d'Open64. Open64 était (en partie) issu d'un projet de recherche sur les compilateurs - financé par Intel - et ciblant son architecture Itanium. L'Itanium a en effet la particularité d'utiliser un jeu d'instruction VLIW. Chaque instruction en contient en réalité trois, qui seront exécutés par un groupe de trois unités scalaires. C'est donc au compilateur, pour Itanium, de choisir quelles instructions mixer pour obtenir le maximum de performances, une tâche particulièrement ardue. Si Intel ne maintient plus ce projet, une version alternative d'Open64 continue d'être proposée par AMD. Elle n'est malheureusement disponible que sous Linux ce qui limite son intérêt pour notre article. Page 8 - Configurations de tests, logiciels, SPEC Configurations de testsAfin d'évaluer l'impact des compilateurs, nous avons d'abord choisi côté matériel trois processeurs issus d'architectures différentes :
SSE 4a était pour rappel une extension d'AMD (quelques détails ici et ici sur un blog d'AMD) qui n'a jamais été reprise par Intel. Elle est en pratique très peu utilisée, sauf dans un cas que nous verrons plus tard ! Attention cependant, le Phenom II ne supporte ni le SSE 4.1, ni le SSE 4.2. S'il y a un très léger overlap entre SSE 4.1 et SSE 4a pour quelques instructions, la grande majorité ne sont pas gérées. Cela pose un certain nombre de problème avec le compilateur Intel comme nous le verrons. Côté plateforme nous avons utilisé :
Si les configurations étaient identiques pour les trois plateformes, les tests sur le processeur FX ont été réalisés avec les patchs disponibles sur le site de Microsoft que nous avions évoqués précédemment dans cette article. Nous nous sommes concentrés exclusivement sur les performances des compilateurs disponibles sous Windows puisqu'il s'agit de la plateforme que nous utilisons régulièrement pour nos tests de performances relatifs des processeurs. Linux, BSD et les autres systèmes d'exploitation reposent sur des environnements significativement différents et si certains compilateurs peuvent être communs, les problématiques engendrées peuvent être différentes (Windows ne dispose pas réellement d'un équivalent unifié de la bibliothèque standard). Les résultats que nous vous présentons ne s'appliquent donc que sur ce système d'exploitation. Notez que les performances relatives des trois processeurs ne nous intéressent pas réellement dans cet article (vous pouvez vous reporter au test du FX 8150 pour les voir en détail). Ce qui nous intéressera par la suite est la manière dont les compilateurs traitent ces plateformes, que ce soit les uns par rapport aux autres, ou en fonction des optimisations choisies. Pour mesurer l'impact des compilateurs, nous avons cherché des logiciels C/C++ capables d'être compilés sous Windows à la fois sous GCC, CL et ICC, une tâche relativement ardue. Les logiciels principalement développés pour Windows dépendent très souvent des "extensions" (pour ne pas dire bizarreries) du compilateur de Microsoft. A l'inverse, la compatibilité limitée de ce compilateur avec les standards l'empêche parfois de compiler un grand nombre de programmes censés être universels. SPEC  En plus d'un certain nombre de logiciels open source qui correspondaient à cette description mince, nous nous sommes également tournés vers SPEC. SPEC est un organisme qui tente de réaliser des benchmarks universels qui permettent d'obtenir des mesures de performances standardisées sur de multiples systèmes. Il s'agit cependant d'un peu plus que d'un simple benchmark type 3D Mark puisqu'il propose une gestion de multiples systèmes d'exploitation et de multiples compilateurs. Ainsi, sur chaque plateforme il est possible de compiler et d'exécuter ces tests pour obtenir des scores. En plus d'un certain nombre de logiciels open source qui correspondaient à cette description mince, nous nous sommes également tournés vers SPEC. SPEC est un organisme qui tente de réaliser des benchmarks universels qui permettent d'obtenir des mesures de performances standardisées sur de multiples systèmes. Il s'agit cependant d'un peu plus que d'un simple benchmark type 3D Mark puisqu'il propose une gestion de multiples systèmes d'exploitation et de multiples compilateurs. Ainsi, sur chaque plateforme il est possible de compiler et d'exécuter ces tests pour obtenir des scores. Ces scores baptisés SPECint et SPECfp (nombres entiers et virgule flottantes) reposent sur un indice de performance très précis calculé à partir d'une (longue) série de tests. Pour pouvoir être validé, SPEC impose des règles strictes en matière d'options de compilations et l'on retrouve deux "normes", la norme "base" est la version traditionnelle, elle restreint l'utilisation d'optimisations jugées trop agressives et elle permet une comparaison entre différentes architectures. Un standard "peak" existe également, où tout est autorisé. Les scores SPECint et SPECfp sont très souvent utilisés dans les présentations d'Intel (et parfois d'AMD) pour comparer une architecture à une autre. L'importance de SPEC sur les compilateurs est forte : les développeurs de compilateurs utilisent souvent les benchs inclus dans SPEC pour optimiser leurs compilateurs, mais l'impact joue également sur la manière dont les optimisations sont développées et présentées. La version "base" autorise les optimisations pour un modèle de processeur par exemple. Pour réaliser nos tests, nous avons utilisé un certain nombre de tests individuels de SPEC, les scores que nous indiquons sont les temps d'exécution. Nous ne publions en aucun cas de scores SPECint et SPECfp dans cet article, un point qu'il est important de préciser. Visual Studio n'est pas capable de compiler une grande partie des tests inclus dans SPEC, ce dernier aura donc limité notre choix. Malgré tout, l'abondance de tests inclus dans SPEC nous a laissé une large marge. Passons enfin aux tests ! Page 9 - Performances SPEC : bzip2, mcf Performances sous SPEC, bzip2, mcfLes benchmarks qui suivent sont tous issus de la suite SPEC cpu2006, version 1.2 (septembre 2011), nous utilisons les scripts de compilation inclus dans SPEC pour Visual Studio (cl) et Intel C++ Compiler (icc). Si SPEC supporte officiellement GCC (gcc) sous Linux, ce n'est pas le cas sous Windows. Un port sous Cygwin existait bel et bien mais ce dernier a été retiré. Nous avons donc modifié cpu2006 pour le faire fonctionner sous mingw. Comme nous l'indiquions précédemment, mingw peut être sensiblement handicapé sur les opérations liées aux chaines de caractères et de mémoire, relativement lentes car issues d'une DLL Microsoft ancienne. Nous notons pour chaque benchmark qui suit le langage du bench, ainsi que le type de charge rencontré (entiers ou virgule flottante). Enfin, nous indiquons si le benchmark est multithreadé ou non. Pour chaque test, nous mesurons les performances à partir de builds réalisées avec les options de compilations autorisées par SPEC base. Nous supprimons toutefois (pour Intel) l'option qui crée automatiquement un code optimisé en fonction de la plateforme. Base dans notre graphique correspond donc à la configuration par défaut. Nous forçons ensuite pour Visual Studio la génération de code SSE2 et AVX (les deux seules options offertes) et pour Intel, nous testons les options Qax, recommandée par Intel et qui génère un code optimisé pour un niveau de processeur donné ainsi qu'un code de base qui sera exécuté sur tous les autres processeurs ne correspondant pas à ce niveau (SSE2, 3, 4.1, 4.2 et AVX sont testés). Ces builds sont indiquées par la lettre D (pour dispatcher) dans nos graphiques. Nous ajoutons également les builds avec l'option arch pour les différents modes supportés par Intel. Enfin pour GCC, nous utilisons les profils dédiés aux processeurs à savoir barcelona (architecture Phenom II), bdver1 (Bulldozer v1, architecture du FX), corei7 (architecture Intel précédente) et corei7avx (architecture Sandy Bridge). N'incluant pas de dispatcher, les builds AVX ne sont pas testées sur le Phenom II, elles ne sont tout simplement pas fonctionnelles. Notez enfin que si certains noms de benchmarks font référence à des programmes connus, il s'agit généralement de versions modifiées - par SPEC - de ces programmes, notamment pour améliorer la compatibilité, retirer un éventuel biais pour une architecture ou une autre, ou améliorer la qualité des mesures. 401.bzip2bzip2 est un utilitaire de compression très populaire sous Linux. Le benchmark a été modifié pour effectuer ses tâches de compression et décompression uniquement en mémoire, et ainsi limiter l'influence du disque. Des données de niveaux de compressibilité différentes (fichiers images JPEG, code source, programme binaire) sont compressés et décompressés avec trois tailles de blocks différentes. Le résultat obtenu est un temps en secondes. 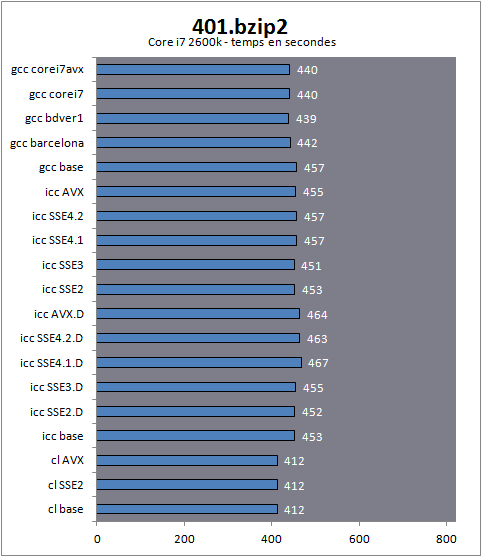 [ Core i7 2600k ] [ FX-8150 ] [ Phenom II X4 975 ] Passez la souris sur un modèle de processeur pour afficher ses résultats Premier benchmark et première surprise : le compilateur Microsoft est ici le plus performant sur Core i7 et sur FX ! Ironiquement, le compilateur d'Intel est celui qui produit le code le plus rapide pour le Phenom II. Les écarts ne sont pas ridicules puisque sur Core i7 le compilateur de Microsoft se place 12% devant une build AVX avec dispatcher, censée être la plus optimisée possible. En matière d'optimisations, comme nous allons le voir, les résultats ne sont pas forcements ceux auxquels on s'attend. De manière intrigante on notera que les versions SSE 4.1/4.2 et AVX sont les plus lentes sur le Core i7 et le FX, ce qui n'est pas le cas pour le Phenom II. Dans tous les cas, le mode SSE3 sans dispatcher est le plus rapide qui soit proposé par ICC. Le comportement des versions dispatcher sur le Phenom II sont particulièrement intrigantes, en effet si l'on admet que le dispatcher traite de la même manière tous les processeurs AMD, le même code devrait tourner à la fois sur le Phenom II, et à la fois sur le FX. Dans la pratique les choses ne sont pas si simples. Notons enfin que GCC est le seul compilateur à proposer un gain de performances via ses profils dédiés aux processeurs, tous les profils obtenant des performances équivalentes sur chaque architecture. On notera pour ce premier test que GCC est en milieu de peloton pour les processeurs Intel et en dernière place sur les machines d'AMD. L'écart de performances CL/GCC reste de 10% sur les deux architectures, ICC est simplement plus efficace sur le Phenom II 429.mcfCe benchmark est tiré de MCF, un programme de génération d'horaires pour transports en communs. Il répond au problème dit de flot minimum en implémentant un algorithme network simplex. Un PDF décrivant le problème et ce type de solution est disponible ici , l'algorithme utilisé dans le benchmark étant un peu plus complexe et optimisé. 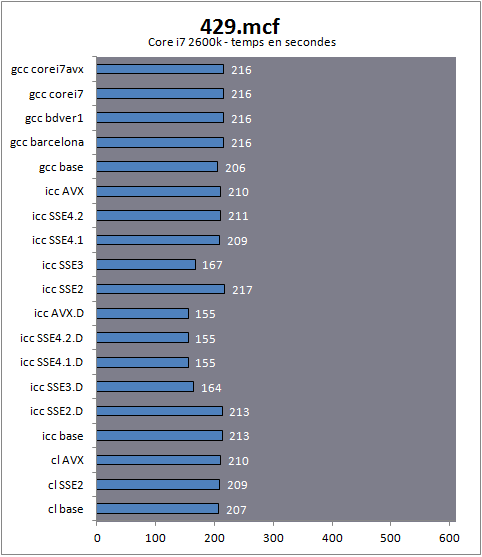 [ Core i7 2600k ] [ FX-8150 ] [ Phenom II X4 975 ] Passez la souris sur un modèle de processeur pour afficher ses résultats Si les modes SSE2 et AVX n'apportent aucun gain sur ce benchmark sur le compilateur Microsoft, on peut noter des premiers gains liés aux optimisations Intel. Si l'on regarde d'abord les builds "dispatcher", on note que la version SSE3 apporte 30% de performances en plus, les trois modes suivants apportant un nouveau léger gain. Problème ? Ces gains ne sont pas reproduits de manière exacte lorsque l'on utilise les builds "arch" censées optimiser de la même manière sur un processeur Intel. Ici, le mode SSE3 est bien plus rapide, mais ce n'est pas le cas des autres modes ! A la décharge d'Intel, on retrouve, pour ces builds sans dispatcher un même comportement sur les processeurs AMD, le Phenom II profitant une fois de plus assez fantastiquement du mode arch:SSE3Les versions dispatcher sur AMD FX et Phenom II ont toutes des performances identiques en tout cas : c'est ce à quoi nous nous attendions. Page 10 - Performances SPEC : gombk, hmmer, sjeng 445.gombkgombk est un algorithme d'intelligence artificielle dédié au jeu de Go. Il s'agit d'une IA extraite du jeu open source GNU Go .  [ Core i7 2600k ] [ FX-8150 ] [ Phenom II X4 975 ] Passez la souris sur un modèle de processeur pour afficher ses résultats Dans ce test, les gains apportés par les diverses optimisations sont relativement mineurs, on notera cependant que les compilateurs MS et GCC sont plus rapides que celui d'Intel sur un Core i7 alors que le compilateur Intel est le plus rapide sur le Phenom II ! Décidément, le compilateur d'Intel aime beaucoup ce processeur ! On notera, pour la version sans dispatcher que les builds SSE 4.1, 4.2 et AVX sont légèrement plus rapides que les autres sur Core i7, l'inverse est vrai sur FX, mais les marges sont extrêmement faibles. Notons une légère autre tendance à vérifier, tant elle est ici minime, les modes SSE2/AVX de Visual Studio semblent légèrement plus lents sur processeurs Intel que la version x87 classique, tandis que l'on note un léger gain sur FX et Phenom II 456.hmmerhmmer est un algorithme qui effectue des recherches dans une base de données de gènes, un algorithme notamment utilisé pour analyser les séquences de protéines. 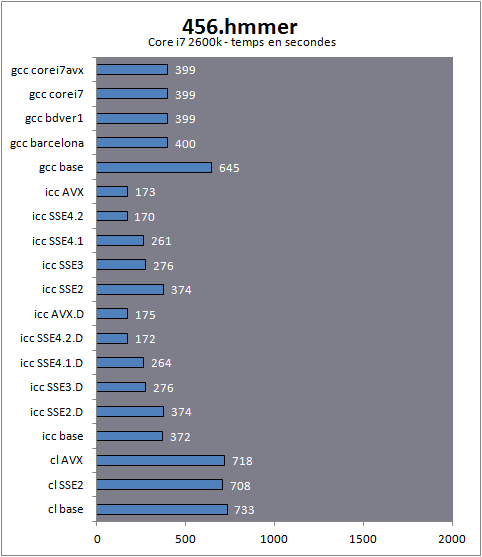 [ Core i7 2600k ] [ FX-8150 ] [ Phenom II X4 975 ] Passez la souris sur un modèle de processeur pour afficher ses résultats Surprise de taille ! Si l'on note bel et bien des gains entre les différentes versions dispatcher du compilateur d'Intel sur le Core i7 on note également des gains significatifs sur les processeurs AMD ! Alors, que se passe-t-il ? Il faut regarder la version dispatcher "AVX" lancée sur le Phenom II, cette dernière est bel et bien trois fois plus rapide que la version de base, et pourtant, le Phenom II n'est non seulement pas capable de faire tourner un éventuel code AVX, mais en prime, la détection des processeurs Intel par le dispatcher l'empêche de faire tourner le code optimisé. Si l'on y regarde de plus près, on notera que les gains ne sont pas en effet exactement identiques. Alors que l'on peut grouper deux à deux les modes sur Core i7 par rapport à leurs performances (AVX et SSE 4.2, SSE 4.1 et SSE3, SSE2 et base), on notera un décalage sur les processeurs d'AMD ou une build SSE3 est aussi lente qu'une version SSE2. Décalage qui disparait lorsque l'on enlève le dispatcher, qui plus est ! Si cela est en soit une bonne nouvelle pour les processeurs AMD, cela souligne aussi l'opacité complète de l'option Qax du compilateur d'Intel. Les optimisations sont multiples et contrairement à ce que laisse sous entendre leur nom, il ne s'agit pas uniquement de la génération de code AVX ou SSE dont il s'agit, mais bel et bien de multiples couches d'optimisations qui peuvent aussi bien toucher les fonctions de chaines de caractères ou les fonctions mémoires. Le compilateur d'Intel semble laisser bénéficier les autres processeurs - certes à un rythme légèrement différent - d'une partie de ses optimisations. On apprécie le geste. Notons enfin que gcc est significativement plus rapide que le compilateur de Microsoft dans ce test. 458.sjengsjeng est une intelligence artificielle pour le jeu d'Echec, extraite de la version 11.2 du logiciel du même nom . 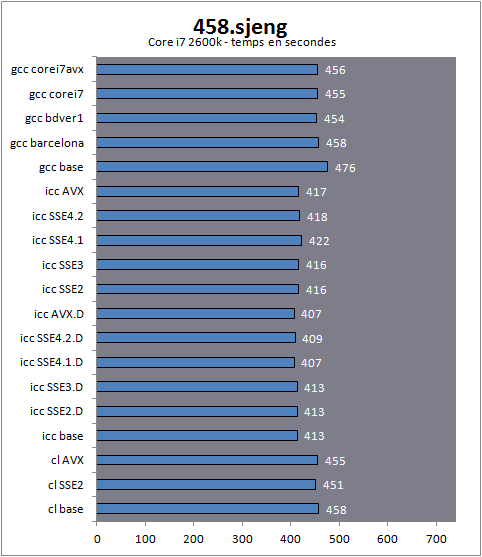 [ Core i7 2600k ] [ FX-8150 ] [ Phenom II X4 975 ] Passez la souris sur un modèle de processeur pour afficher ses résultats Si l'on notera ici un très léger gain obtenu par les versions SSE 4.1, 4.2 et AVX sur Core i7, on notera à l'inverse une légère dégradation dans ces modes sur les processeurs AMD avec le dispatcher. Les algorithmes partagés par la version classique et dispatchée des builds ne profitent pas de la même manière aux architectures. Une fois le dispatcher enlevé, l'AVX apporte bel et bien un petit gain sur le FX. Page 11 - Performances SPEC : h264ref, astar, milc 464.h264refh264ref est une implémentation de référence de la norme de compression vidéo H.264/AVC , le benchmark consiste à l'encodage de deux vidéos via les profils baseline et main (nous vous renvoyons à notre article sur le sujet). 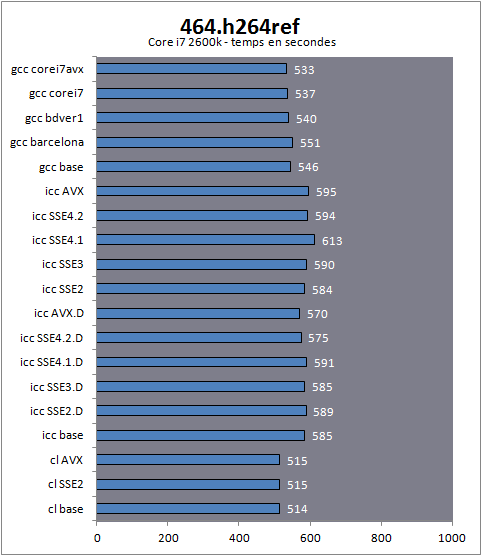 [ Core i7 2600k ] [ FX-8150 ] [ Phenom II X4 975 ] Passez la souris sur un modèle de processeur pour afficher ses résultats Le compilateur de Microsoft est ici un peu plus rapide que celui d'Intel pour le Core i7, tandis qu'une fois de plus le code produit par le compilateur d'Intel est plus rapide sur Phenom II (significativement) mais aussi sur le FX. Les versions avec dispatcher sont les plus efficaces parmis les versions proposées par le compilateur d'Intel. Les optimisations de GCC, utiles sur Phenom II, sont contre productives sur FX. Le tuning corei7avx apporte un petit gain de performances sur le Core i7. 473.astarastar est une implémentation de l'algorithme de pathfinding A*, très utilisé dans les jeux de stratégie temps réel. 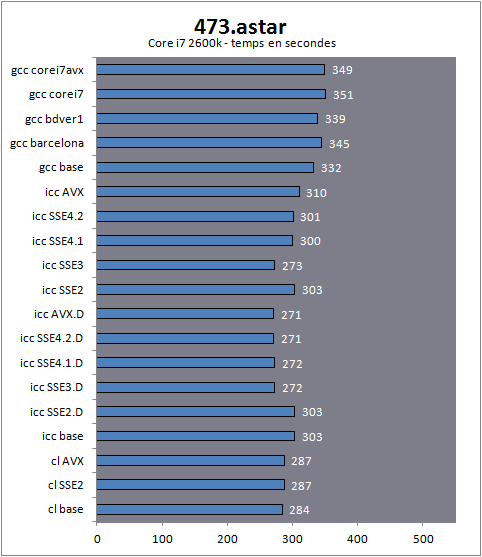 [ Core i7 2600k ] [ FX-8150 ] [ Phenom II X4 975 ] Passez la souris sur un modèle de processeur pour afficher ses résultats Bien qu'il s'agisse de notre premier benchmark C++ (censé lui être plus favorable), GCC marque le pas. Ses optimisations sont plutôt contreproductives. Le compilateur de Microsoft est plus efficace, sauf sur Core i7 où des optimisations non partagées entrent en jeu dès la version SSE3. On notera le cas, une fois de plus, du mode sans dispatcher du compilateur d'Intel où seule la version SSE3 profite d'optimisations, là où les autres versions n'en profitent pas. Bien entendu il n'y a aucun lien entre le jeu d'instruction supporté ici et ces optimisations. 433.milcMilc est un benchmark de simulation physique de chromodynamique quantique (QCD). 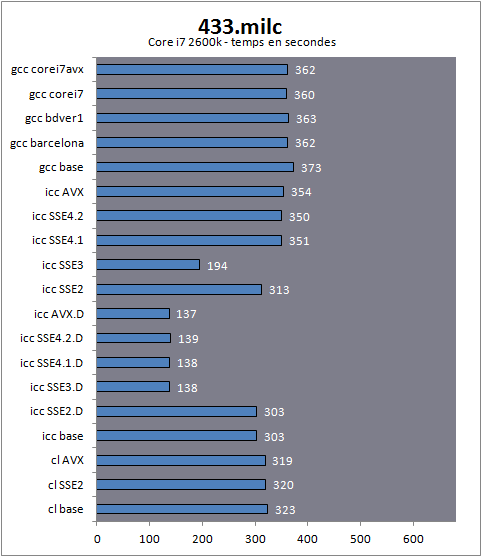 [ Core i7 2600k ] [ FX-8150 ] [ Phenom II X4 975 ] Passez la souris sur un modèle de processeur pour afficher ses résultats A l'image du benchmark précédent, sur Core i7 on note un avantage certain dès l'arrivée du mode SSE3 avec le compilateur Intel avec le dispatcher. Les performances sont ici plus que doublées. On notera que si les performances ne bougent pas sur FX, on observera un gain de 9% sur Phenom II. Lorsque l'on regarde les builds sans le dispatcher, on notera une fois de plus que seule la version SSE3 profite des optimisations mais pas de toutes ! Ainsi même sur Core i7 cette dernière est significativement plus lente. Les processeurs AMD profitent de ces petits gains tout de même, mais l'opacité du fonctionnement de ces options continue de frapper Page 12 - Performances SPEC : namd, lbm, sphinx3 444.namdnamd est un benchmark scientifique de simulation dynamique de molécules. Un benchmark portable à été extrait du logiciel original, disponible ici . 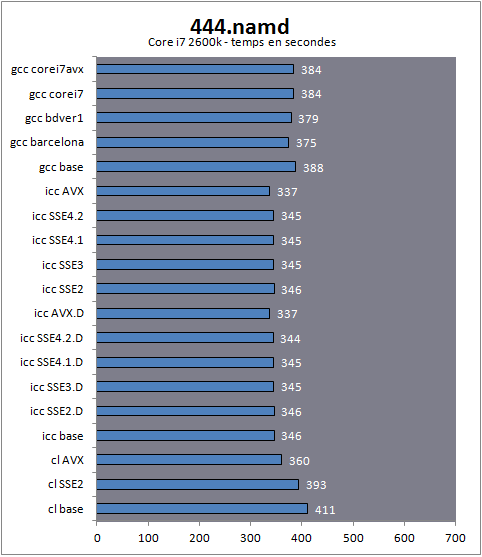 [ Core i7 2600k ] [ FX-8150 ] [ Phenom II X4 975 ] Passez la souris sur un modèle de processeur pour afficher ses résultats Le mode dispatcher AVX du compilateur Intel apporte un très léger gain que l'on retrouve également sur le FX. De manière assez intéressante, on notera que le mode AVX du compilateur Microsoft propose de gros gains de performances, particulièrement sur les plateformes AMD. Les optimisations AMD de GCC sont ici plus efficaces que les optimisations Core i7 sur Core i7 ! 470.lbmLbm est un programme scientifique permettant la simulation du comportement de de fluides. Des images et vidéo sont disponibles sur ce site en allemand . 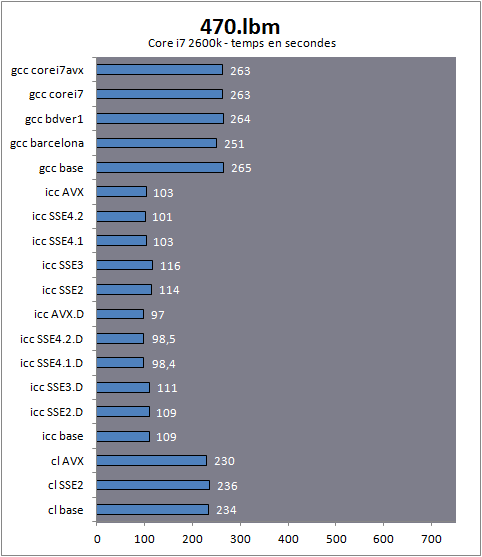 [ Core i7 2600k ] [ FX-8150 ] [ Phenom II X4 975 ] Passez la souris sur un modèle de processeur pour afficher ses résultats Le compilateur d'Intel est ici significativement plus efficace que les autres, avec des gains pouvant être faramineux sur le FX. Cependant, on notera un petit bémol pour les modes AVX et SSE 4.1 avec dispatcher qui sont significativement plus lents sur les processeurs d'AMD. Si ce n'est pas la première fois que l'on voit ces modes se différencier, particulièrement sur le FX, cela n'a jamais été aussi net qu'ici. 482.sphinx3Terminons enfin notre tour de SPEC par sphinx3, un algorithme de reconnaissance vocale disponible sur ce site. 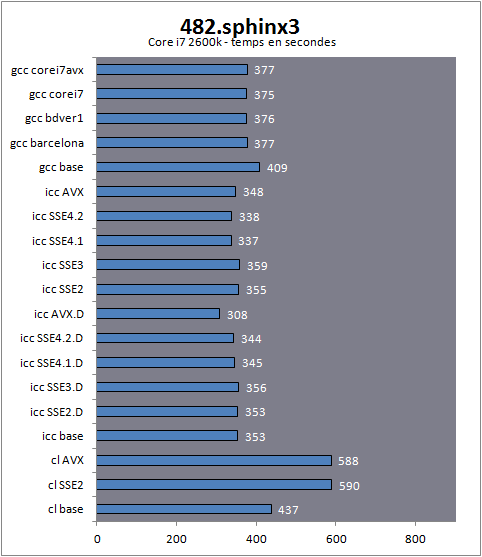 [ Core i7 2600k ] [ FX-8150 ] [ Phenom II X4 975 ] Passez la souris sur un modèle de processeur pour afficher ses résultats Intéressons-nous d'abord plus particulièrement au comportement du compilateur de Microsoft. Si le mode SSE2 ralentit significativement les performances sur les trois plateformes, on notera que le comportement du mode AVX est assez différent sur le Core i7 où il reste quasi aussi lent que le mode SSE2, et sur FX où il devient d'un coup plus rapide. Une rareté En ce qui concerne le compilateur d'Intel, si le mode AVX dispatché apporte un gain de performances sur Core i7, le mode non dispatché apporte un recul, et ce sur toutes les plateformes. Page 13 - Performances : C-Ray, TSCP, 7-Zip Nous avons également utilisé plusieurs logiciels open source pour tenter de mesurer les performances relatives des compilateurs. C-RayC-Ray est une implémentation d'un raytracer en C. Particulièrement concise, cette implémentation stresse très fortement les capacités flottantes des processeurs modernes et à été transformée en benchmark pour ce but (vous pouvez retrouver le code source ici). 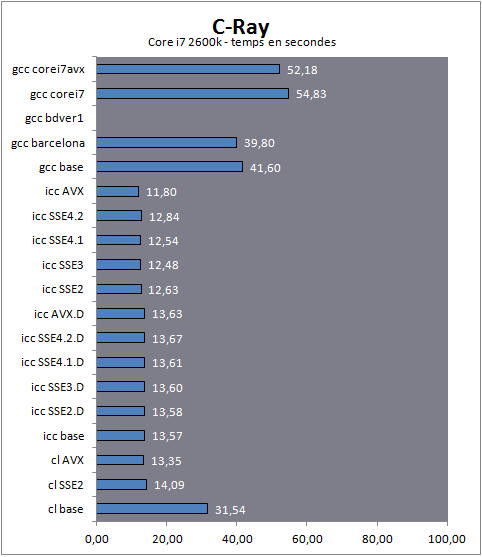 [ Core i7 2600k ] [ FX-8150 ] [ Phenom II X4 975 ] Passez la souris sur un modèle de processeur pour afficher ses résultats Les résultats obtenus montrent tout d'abord la différence que peut faire l'utilisation d'opérations mathématiques SSE2 ou AVX. Sur les trois plateformes, passer du x87 au SSE2 avec le compilateur de Microsoft fait plus que doubler les performances (le Phenom II étant celui qui, de loin, en profite le plus !). Le mode AVX du compilateur de Microsoft se paye même le luxe d'être plus plus rapide que le compilateur d'Intel sur un Core i7. Ironiquement une fois de plus, c'est le compilateur d'Intel qui est le plus efficace sur les plateformes AMD. Les différentes optimisations du compilateur d'Intel ne changent pas grand-chose avec le dispatcher, même si une fois celui-ci désactivé, on est obligé de noter un petit décrochement sur le FX des modes SSE 4.2 et AVX. On notera enfin que les optimisations Core i7 sont très contreproductives sous GCC, ce qui n'est pas le cas des optimisations AMD. TSCPTSCP est une implémentation d'une intelligence artificielle d'échecs par Tom Kerrigan (que nous remercions pour nous avoir laissé utiliser son bench). 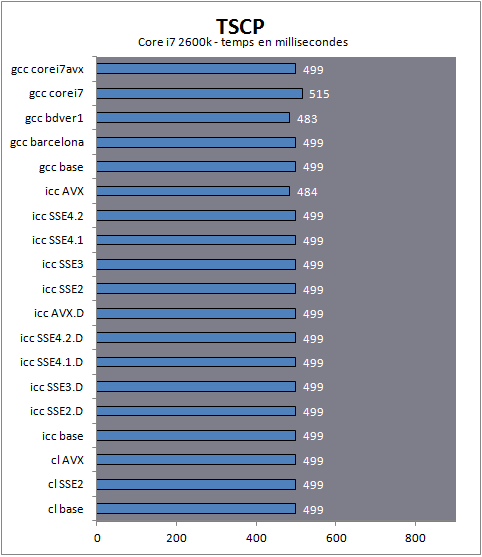 [ Core i7 2600k ] [ FX-8150 ] [ Phenom II X4 975 ] Passez la souris sur un modèle de processeur pour afficher ses résultats Une fois n'est pas coutume, les différentes optimisations du compilateur Intel ne servent ici à rien sans dispatcher. Avec, on note un petit avantage du mode AVX. C'est surtout GCC qui tire son épingle du jeu avec les meilleurs résultats sur les trois plateformes, parfois ex-equo avec le compilateur d'AMD qui s'en sort aussi très bien. 7-ZipNous utilisons ici le bench intégré à 7-Zip 9.20 , ce dernier mesure les performances de la compression LZMA2, cette dernière s'effectue exclusivement en mémoire à l'image de ce que nous avions vu pour SPEC et bzip2. 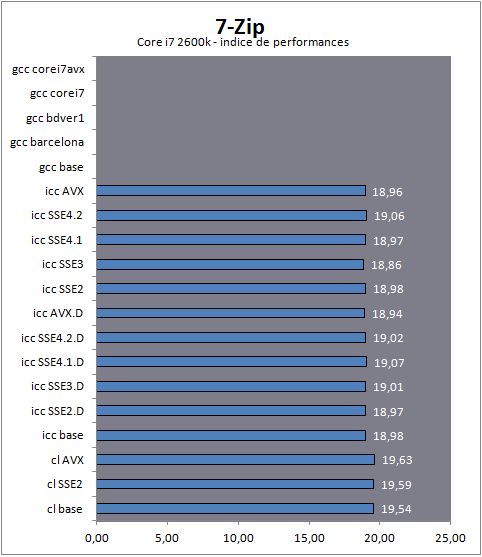 [ Core i7 2600k ] [ FX-8150 ] [ Phenom II X4 975 ] Passez la souris sur un modèle de processeur pour afficher ses résultats Attention, contrairement à tous nos autres graphiques, 7-Zip rapporte un indice de performance et non un temps. Une barre plus longue indique donc de meilleures performances. Le code de 7-Zip n'est pas compilable directement avec GCC. Un portage unix/posix existe bel et bien (p7zip ) mais comparer le temps d'exécutions de code sources différents ne ferait ici pas sens. On notera surtout ici le fait que le compilateur de Microsoft se distingue en étant plus rapide sur Core i7 et FX. L'Intel n'est devant que sur Phenom II, décidément le constructeur aime beaucoup ce processeur ! Notons enfin pour l'anecdote que la version optimisée pour la taille du code était très légèrement plus rapide dans ce test, sous Visual Studio ( -O1). Un choix d'ailleurs effectué par le développeur pour les versions qu'il distribue. Page 14 - Impact de l'assembleur : x264 x264Le logiciel de compression vidéo x264 que nous utilisons régulièrement dans nos articles est assez particulier. Il intègre en effet un assez grand nombre d'optimisations assembleurs. Les auteurs ne se contentent pas du x86 d'ailleurs puisque l'on retrouvera par exemple des optimisations utilisant le jeu d'instruction SIMD NEON d'ARM. Il est également possible de compiler le logiciel en désactivant toutes les optimisations assembleurs. L'occasion de vérifier l'impact de ce dernier et voir si les optimisations des compilateurs peuvent faire quoique ce soit pour compenser cette perte. Nous utilisons mingw/gcc uniquement pour ce test (les autres compilateurs ne sont pas directement supportés, des patchs et forks existent cependant), dans une version légèrement différente de celle utilisée jusqu'ici. Gcc est ici en version 4.6.2. i686 représente ici le profil de base, noasm indique que nous avons désactivé les optimisations assembleurs lors de la compilation. 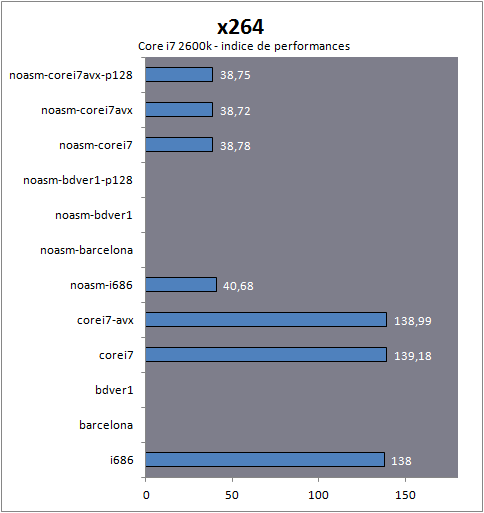 [ Core i7 2600k ] [ FX-8150 ] [ Phenom II X4 975 ] Passez la souris sur un modèle de processeur pour afficher ses résultats Premier point à noter, une build compilée via gcc avec les optimisations SSE4a (ce qui est le cas des profils AMD) sera détectée comme telle au lancement par x264 qui stoppera son exécution. Seul le FX, disposant à la fois d'AVX et de SSE4a peut lancer toutes les versions compilées. Ensuite, si l'on en doutait encore, un code rédigé en assembleur reste la voix royale pour obtenir un maximum de performances. Les versions avec assembleurs arrivent cependant à profiter très légèrement des profils corei7/corei7-avx pour le Core i7-2600k, et bdver1 (et surtout) barcelona pour les processeurs AMD. De manière plus surprenante ces optimisations sont généralement défavorables sur le code dépourvu d'assembleur. Notez enfin que forcer l'utilisation d'instructions AVX 128 bits (ce qui est indiqué par le p128) apporte un impact, ici très léger cependant. Bien entendu ces résultats ne sont pas directement comparables aux autres que nous avons pu vous présenter, mais ils permettent d'illustrer que si le compilateur reste important, un développeur pourra toujours optimiser de façon forte un code en C/C++. Page 15 - Moyennes MoyennesPour illustrer les performances relatives des compilateurs, nous avons calculé des moyennes en ramenant à un indice 100 la performance du compilateur de Microsoft sur chacune des plateformes. 7-Zip et x264 sont bien entendu exclus de ces moyennes. Pour être très précis, nous avons également effectué deux autres moyennes en ramenant à 100 les scores du compilateur Microsoft en version SSE2, et Intel en version de base. 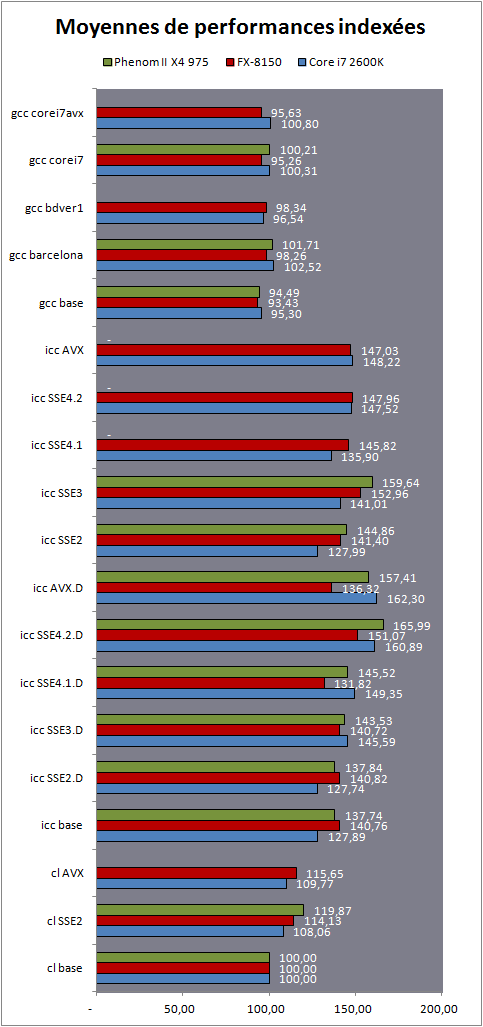 [ cl base ] [ cl SSE2 ] [ icc base ] Passez la souris sur un compilateur pour centrer les moyennes Bien entendu, les performances des ces trois processeurs ne sont pas identiques mais en ramenant chacun à un indice équivalent, nous pouvons voir plus précisément de quelle manière les performances évoluent en fonction du compilateur ou des options utilisées. Si vous avez suivi notre article depuis le début, les résultats présentés ici ne vous surprendront pas. Le compilateur d'Intel arrive, sans surprise, à se placer devant. Si gcc ne démérite pas, en pratique les options de tuning ont souvent été contreproductives, mitigeant les gains qu'elles apportent. Visual Studio de son côté est significativement plus lent dans sa version classique, et pour cause, il génère encore du code x87 par défaut pour les opérations en virgule flottante. Passer au SSE2 pour les opérations mathématiques augmente les performances, particulièrement sur les processeurs AMD dont le mode x87 a été quelque peu délaissé au profit des nouveaux jeux d'instructions comme SSE2 qui sont censés les remplacer. Si l'on compare ce mode à celui par défaut d'Intel (qui compile également pour SSE2), on notera que ce dernier se détache, et c'est même le FX-8150 qui en profite le plus avec 24% de performances en plus obtenues contre 20% seulement pour le Core i7. En centrant les performances sur ce mode, on peut voir plusieurs points intéressants. D'abord, la manière très progressive dont chaque mode Qax profite aux processeurs d'Intel. Des gains graduels, un peu trop parfaits pour être liés simplement à l'utilisation d'un jeu d'instruction. Pour se convaincre de ce fait, il suffit de regarder l'écart que l'on retrouve entre la version AVX avec et sans dispatcher sur un Core i7 2600k. Les modes "équitables" ne sont pas optimisés avec la même vigueur par Intel que les autres modes d'optimisations. Intel ne s'en cache d'ailleurs pas. Les modes Qax sont des modes d'optimisations fourre tout ou nombre des optimisations ne sont pas du tout liées au niveau de support du processeur. Le fait que ces autres optimisations, dont l'on a vu parfois en pratique les effets bénéfiques sur les processeurs AMD, ne soient pas rendues disponibles dans les modes censés être largement compatibles (sans dispatcher) est particulièrement gênant. Si ces modes sont effectivement plus "justes", ils sont en pratique moins rapides pour tout le monde, y compris les processeurs Intel. Alors, quelles sont ces autres optimisations ? En analysant le code assembleur généré par le compilateur d'Intel nous avons pu remarquer un certain nombre de choses. D'abord, il y a des optimisations qui ne concernent pas le code des développeurs. Que ce soit l'utilisation d'une version ou d'une autre des fonctions d'allocations et de copie mémoire, les résultats peuvent être très changeants. Tout ce code annexe généré par le compilateur pour les fonctionnalités standard de C/C++ est important, et si le dispatcher en affecte certaines, d'autres ne sont pas affectées. C'est d'ailleurs à cela que l'on doit cette si grande variété dans les résultats que l'on retrouve. Pour le test lbm, le code assembleur généré dans la section critique du programme est identique dans les versions SSE 4.1 et 4.2. Pire, le code généré n'est pas dispatché (il l'est en mode AVX, avec un gain très modeste), mais l'on note une différence de traitement significative entre un Core i7 et un FX en SSE 4.1. Parce que certains blocs de code annexes, sont, eux, dispatchés. Ensuite, il ne faut surtout pas surestimer la quantité de code SSE/AVX généré. Si le compilateur est souvent capable d'en utiliser, nous avons remarqués dans nombre de tests que le code produit dans les sections critiques (les parties de code les plus gourmandes) n'utilise pas toujours de code AVX. Les instructions SSE2 sont souvent préférées, et ce à juste escient. Enfin, il y a les optimisations opaques. Nous avons pu remarquer par exemple que les modes Qax influent sur le dépliement de boucle. Cette optimisation consiste à remplacer des boucles (des morceaux de codes que l'on demande de répéter de multiples fois) par ce code répété plusieurs fois. Cela rallonge la taille du code généré, mais en pratique le fait d'éviter des sauts conditionnels (très couteux sur l'architecture x86) peut apporter de bons gains de performances. Nous avons pu remarquer, dans le cas du test lbm, que le compilateur d'Intel ne déplie pas le code en mode QaxSSE2, et qu'il le déplie avec plus ou moins de vigueur dans les autres modes, alors même que l'option de dépliement est activée par défaut dans le compilateur. Page 16 - Conclusion ConclusionA l'heure de refermer ce dossier, nous espérons tout d'abord avoir pu démystifier quelque peu la problématique des compilateurs, et le rôle qu'ils jouent dans les performances de nos processeurs. Nous avions posé au cours de notre article un certain nombre de questions, il convient désormais d'y répondre. D'abord, oui, le choix du compilateur aura un impact sur les performances. La réputation du compilateur d'Intel - toutes optimisations mises de côté - n'est pas volée. Si nous avons pu voir des contre exemples, il reste en moyenne plus rapide que celui de Microsoft avec ses options par défaut. Et même si l'on force l'utilisation des opérations mathématiques SSE2, le compilateur de Microsoft pourra accuser un déficit de 15 à 20% de performances par rapport à son rival. Si Intel investit dans le développement d'un compilateur, c'est bien entendu pour s'en servir comme une arme de plus dans la guerre des performances. En choisissant de permettre l'optimisation automatique pour chacune de ses familles de processeurs - tout en nommant ces options par les jeux d'instructions supportées, comme QaxAVX pour l'AVX - Intel tend à ne faire profiter des dernières optimisations qu'à ses derniers modèles de processeurs, ce qui peut enfler quelque peu la perception que l'on peut se faire des gains apportés par le jeu d'instruction. Il suffit de regarder les performances du Phenom II exécutant ces versions "AVX" dispatchées pour s'en convaincre. 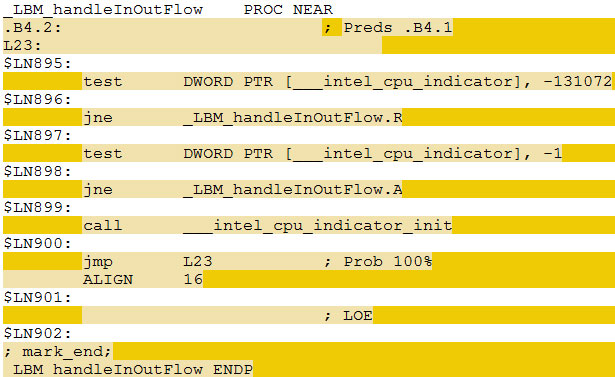 Exemple de fonction dispatchée, extraite du code assembleur de la build AVX dispatchée produite avec le compilateur Intel du test 470.lbm. En fonction de la valeur de la variable __intel_cpu_indicator, un chemin rapide (.R) ou lent (.A) sera exécuté. Lorsque l'on supprime le dispatcher, le problème s'épaissit puisque certaines de ces couches d'optimisations - pas réellement liées aux instructions supportées par le processeur - disparaissent. Pire, certains modes sont bizarrement plus efficaces que d'autres, c'est le cas du mode SSE3 qui en moyenne est le plus rapide ! Le compilateur d'Intel laisse donc un choix complexe aux développeurs qui sont prêts à se plonger dans le manuel pour essayer de comprendre le fonctionnement des options d'optimisations. On retrouve d'un côté un mode universel, équitable dans ses optimisations, mais qui ne propose pas les meilleures performances, et ce pour des raisons qui n'ont pas grand-chose à voir avec la génération de code SSE ou AVX. De l'autre on retrouve des modes dispatchés, fourre tout, qui permettent de gagner jusque 15% de performances en plus sur un processeur Intel par rapport aux modes "équitables". Et qui ont une tendance, plus ou moins forte selon le modèle, à ne pas augmenter, ou diminuer les performances des processeurs AMD. La question de l'implémentation exacte du dispatcher d'Intel dans son compilateur est donc ouverte. En choisissant d'executer une version différente de certaines parties des programmes en fonction de la marque du processeur, et non en fonction de ses capacités techniques, Intel n'est pas particulièrement fair play. La réponse traditionnelle du constructeur sur ce point est claire : ils proposent un logiciel qui tend - certes - à favoriser leurs propres produits, libre à son concurrent de faire de même. Le passage de la Federal Trade Commission n'a pas changé la problématique, si ce n'est par le fait qu'Intel indique désormais clairement que son compilateur optimise différemment selon la marque des processeurs (sans réellement préciser comment). Le fait cependant que nombre de ces optimisations ne soient pas vraiment liées au modèle de processeur, mais à d'autres couches d'optimisations qui se rajoutent, comme le dépliement de boucles par exemple, rendent la situation encore moins claire pour les développeurs. Notons en plus que cette détection de la marque du processeur est utilisée au cas par cas, non seulement par ICC, mais aussi par d'autres produits secondaires vendus par Intel comme par exemple la bibliothèque mathématique MKL ou celle de gestion de threads, TBB, toutes deux dispatchés, certes, mais sans que la marque du processeur n'intervienne. 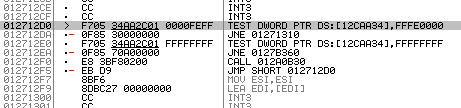 Le même code dispatché, vu à l'execution du programme via OllyDbg Le problème s'épaissit lorsqu'Intel va ensuite démarcher les développeurs de logiciels pour leur proposer d'utiliser leur compilateur, tout en suggérant d'utiliser ces modes Qax qui, outre le fait d'être conseillés par Intel, seront détectés comme plus performants par les développeurs qui prendront le temps de vérifier les performances respectives. Sur le plan de l'équité que nous souhaitons, on peut y voir un problème. Particulièrement quand sont visés les développeurs de jeux ou de benchmarks en vogue - car utilisés dans la presse spécialisé pour mesurer les performances des processeurs. Peut-on cependant blâmer les développeurs qui y passent ? C'est bien là le cur du problème. Si l'on propose à un développeur le choix d'utiliser un compilateur "équitable" contre un autre qui apportera 35% de performances en plus aux utilisateurs de processeurs AMD, et 54% de performances en plus aux utilisateurs de processeurs Intel, doit on le blâmer de choisir un compilateur qui accélèrera dans les deux cas ses utilisateurs, certes de façon partisane ? Et quid de l'utilisateur de processeur AMD dans ce cas ? Préfère-t-il une version équitable et lente, ou un peu plus performante tout en sachant qu'elle avantagera plus les utilisateurs de processeurs concurrents ? En pratique, hors du monde de l'open source, il n'aura de toute façon pas à donner son avis. Les utilisateurs d'applications commerciales doivent subir les choix, bons ou mauvais, réalisés par les développeurs. De la même manière, les mesures de performances que nous réalisons lors de nos comparatifs de processeurs restent impactées par les choix réalisés. Si nous écartons dans l'élaboration de nos protocoles les benchmarks trop partisans - ou ceux conseillés par les constructeurs - lorsqu'une application très populaire avantage un modèle de processeur plutôt qu'un autre, mesurer ces écarts n'est que refléter, au final, la réalité vécue par les utilisateurs de ces logiciels. Le problème de l'équité est épais et les solutions maigres. L'évolution de compilateurs qui produisent du code managé, à l'image de LLVM peut être une solution, tout comme une généralisation de .NET. En gardant à l'esprit que celui qui contrôle la machine virtuelle, au final, contrôle la clef des performances sur chacune des architectures. Déplacer un problème, cela ne veut pas forcément dire le résoudre Copyright © 1997-2025 HardWare.fr. Tous droits réservés. |