| |
| |
| AMD FX-8150 et FX-6100, Bulldozer débarque sur AM3+ Processeurs Publié le Mercredi 12 Octobre 2011 par Marc Prieur URL: /articles/842-1/amd-fx-8150-fx-6100-bulldozer-debarque-am3.html Page 1 - Une nouvelle architecture  Enfin ! Après avoir été repoussée à plusieurs reprises, l'architecture AMD Bulldozer arrive sur le marché. Sa déclinaison AM3+, nom de code Zambezi, prend comme prévu la dénomination commerciale d'AMD FX, un nom qui n'est pas sans rappeler la glorieuse période du K8 durant laquelle AMD mettait à mal Intel et ses Pentium 4. L'AMD FX sera-t-il à la hauteur de son nom ? Enfin ! Après avoir été repoussée à plusieurs reprises, l'architecture AMD Bulldozer arrive sur le marché. Sa déclinaison AM3+, nom de code Zambezi, prend comme prévu la dénomination commerciale d'AMD FX, un nom qui n'est pas sans rappeler la glorieuse période du K8 durant laquelle AMD mettait à mal Intel et ses Pentium 4. L'AMD FX sera-t-il à la hauteur de son nom ?Une architecture CMT et haute fréquenceNous avions consacré un dossier à l'architecture Bulldozer en mai dernier, toutefois il n'est pas inutile de revenir rapidement sur les principales caractéristiques de celle-ci. La base de l'architecture Bulldozer, c'est l'utilisation de la technologie Cluster Multi-threading (MT). Un processeur 8 curs est en fait composé de 4 modules. Au sein d'un module, les deux curs se partagent un certain nombre de leurs composants : - l'étage « front-end » qui regroupe l'unité de fetch (chargement) et de décodage des instructions, ainsi que le cache L1 d'instructions qui est alimenté par ces unités ; - l'unité de calcul sur les nombres flottants ; - le cache L2. 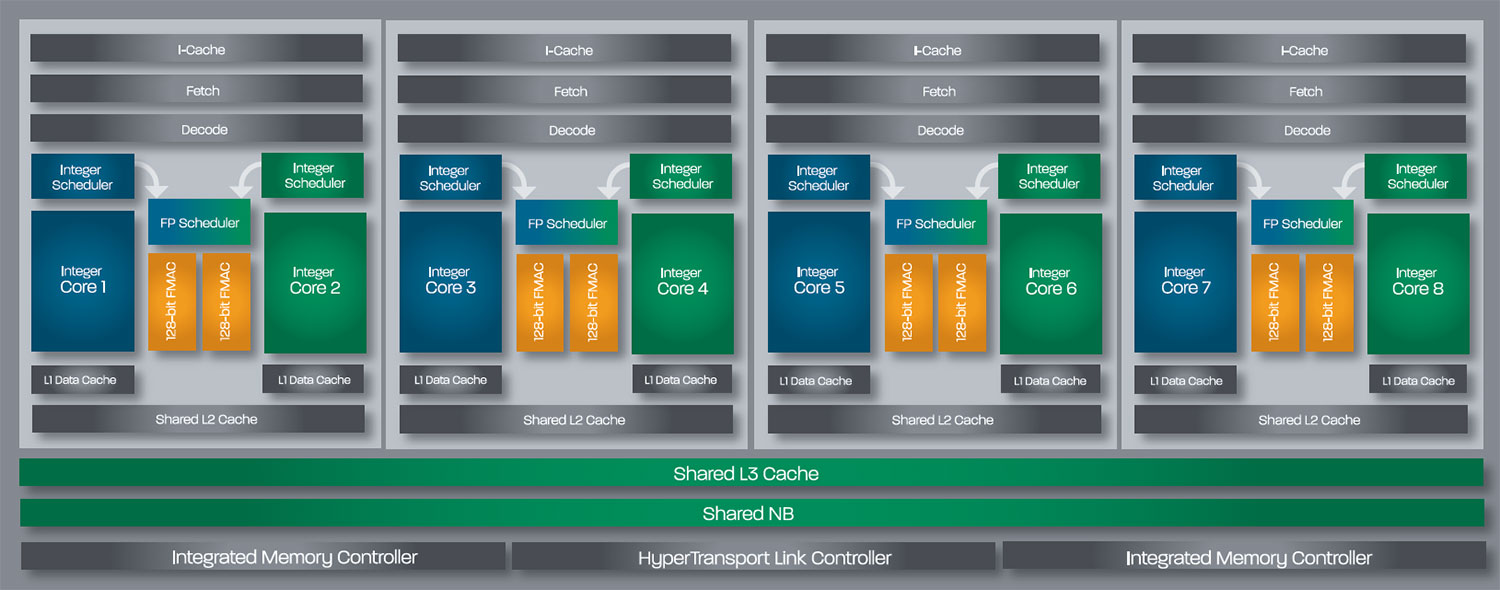 Selon AMD, les deux curs au sein d'un module obtiendraient 80% de performances de deux curs complets, pour d'importantes économies tant en terme de surface sur la puce que de consommation. Beaucoup d'autres modifications ont été apportées, tant au niveau des unités de calculs elles-mêmes que du sous-système de cache, notamment dans l'optique de permettre à l'architecture d'atteindre un haut niveau de fréquence. Bulldozer supporte de plus 100% des jeux d'instructions x86 actuels, et il est donc compatible avec les dernières versions du SSE4 (4.1 et 4.2) et les instructions AES-NI qui permettent d'accélérer l'encryptage. L'AVX, introduit par Intel avec Sandy Bridge, et ses opérantes de 256 bits est de la partie.  On note également l'apparition de quelques instructions propres, regroupées sous le nom de XOP, FMA4 et CVT16. Ces jeux d'instructions correspondent en réalité au SSE5 (annoncé par AMD en 2007 mais jamais implémenté) adapté au format AVX. XOP opère principalement sur des opérandes entières, FMA4 sur les flottants 128-bits, et CVT16 regroupe des instructions de conversion de flottants haute précision en flottants de moyenne et basse précision. Le FMA4, qui permet de faire une multiplication et une addition en un seul cycle, devrait entre autre permettre des gains lorsqu'il sera utilisé par les logiciels, mais c'est une version différente qui sera utilisée par Intel, le FMA3. AMD suivra Intel dans cette voix et l'architecture Piledriver, évolution de Bulldozer, ce qui laisse des doutes quant à la pérennité du FMA4. Page 2 - Zambezi devient AMD FX Zambezi devient AMD FXL'incarnation desktop de l'architecture Bulldozer, c'est Zambezi, qui prend désormais le nom d'AMD FX. Sous ce nom se cache une puce gravée en 32nm chez GlobalFoundries qui intègre environ 2 milliards de transistors sur une surface de 315mm². 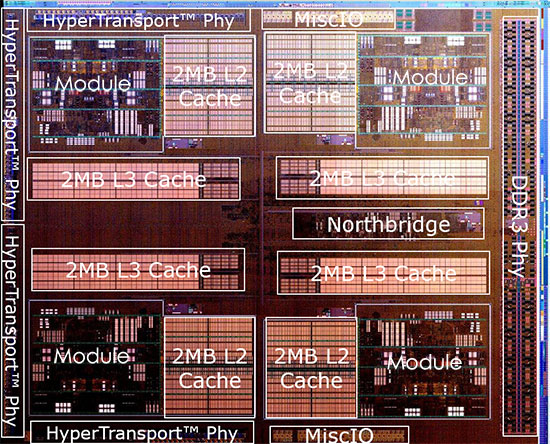 Voici à titre de comparaison quelques données comparatives pour les puces Thuban (Phenom II X6), Deneb (Phenom II X4), Sandy Bridge (Core i7 LGA 1155) et Lynnfield (Core i7 LGA 1156) : 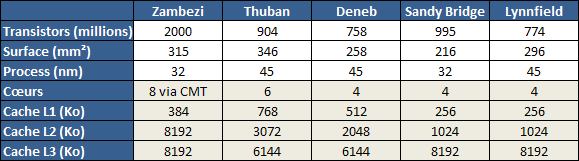 Zambezi est un vrai monstre par rapport à ses prédécesseurs mais aussi ses concurrents. Il intègre ainsi le double de transistors qu'un Sandy Bridge, alors même que ce dernier dispose d'un IGP qui occupe une partie non négligeable de la puce. Cette taille s'explique en grande partie par le cache, puisqu'en combinant les L2 et L3 on arrive à 16 Mo contre 9 Mo au mieux sur la génération précédente et 9 Mo chez Intel. La contrepartie de cette taille importante, c'est bien entendu un coût de production qui risque d'être élevé et une difficulté plus importante pour avoir des puces pleinement fonctionnelles. Pour ce lancement, AMD compte commercialiser 4 AMD FX :  Vous l'aurez remarqué, il existe 2 fréquences Turbo Core. C'est une nouveauté du Turbo Core 2.0 : la fréquence "Max Turbo" peut être atteinte lorsque la moitié des modules sont actifs, la fréquence "Turbo" pouvant fonctionner même avec tous les modules et curs actifs, dans la limite du TDP. Sur Phenom II X6, on avait un seul mode Turbo valable lorsque la 1 à 3 curs étaient actifs. Le positionnement tarifaire d'AMD est plutôt agressif, puisque le FX-8120 est au prix du Phenom II X6 1100T, le FX-6100 au prix du 1055T et le FX-4100 au prix du Phenom II X4 955. Par rapport à l'offre Intel le FX-8150 se positionne entre les 2600K et 2500K, le FX-8120 est un peu en dessous d'un 2500K, le FX-6100 un peu en dessous d'un i5-2300 et le FX-4100 en face d'un Core i3-2100. Page 3 - AM3+, un passage quasi obligatoire ? AM3+, un passage quasi obligatoire ?  Côté plate-forme, les AMD FX utilisent une infrastructure de type AM3+. La compatibilité avec les cartes mères AM3 est assez floue, puisque si ASUS et MSI avaient annoncés il y a des mois des listes de compatibilités, les choses ont un peu changées. AMD avait pour sa part insisté à l'époque sur l'absence de support officiel de la part d'AMD et indiqué que des fonctionnalités qui pourraient être bridées, sans préciser lesquelles. Côté plate-forme, les AMD FX utilisent une infrastructure de type AM3+. La compatibilité avec les cartes mères AM3 est assez floue, puisque si ASUS et MSI avaient annoncés il y a des mois des listes de compatibilités, les choses ont un peu changées. AMD avait pour sa part insisté à l'époque sur l'absence de support officiel de la part d'AMD et indiqué que des fonctionnalités qui pourraient être bridées, sans préciser lesquelles.MSI a finalement fait machine arrière sur une bonne partie des modèles et seules 3 de ses cartes AM3 sont finalement compatibles : - 890FXA-GD70 via le bios A7640AMS.1B0 - 890FXA-GD65 via le bios A7640AMS.I40 - 890GXM-G65 via le bios A7642AMS.1C0 Pour expliquer ce retournement de situation, MSI invoque des modifications nécessaires et non prévues dans les étages d'alimentation. Pourquoi pas, mais gros carton rouge pour le manque de communication sur ce changement qui s'est fait en catimini. Ne disposant pas de ces cartes, nous n'avons pas pu vérifier l'état de la compatibilité annoncée et si le support était complet. ASUS avait également annoncé une compatibilité avec les processeurs AM3+ pour une partie de ses cartes AM3. A priori elle est toujours d'actualité, malheureusement les bios n'ont toujours pas été développés pour les cartes de la série M4/Crosshair IV, AMD priorisant le développement des bios pour la série M5/Crosshair V. Il faut espérer que cette situation s'éclaircira rapidement, sans quoi ce serait également un mauvais coup de publicité pour ASUS. 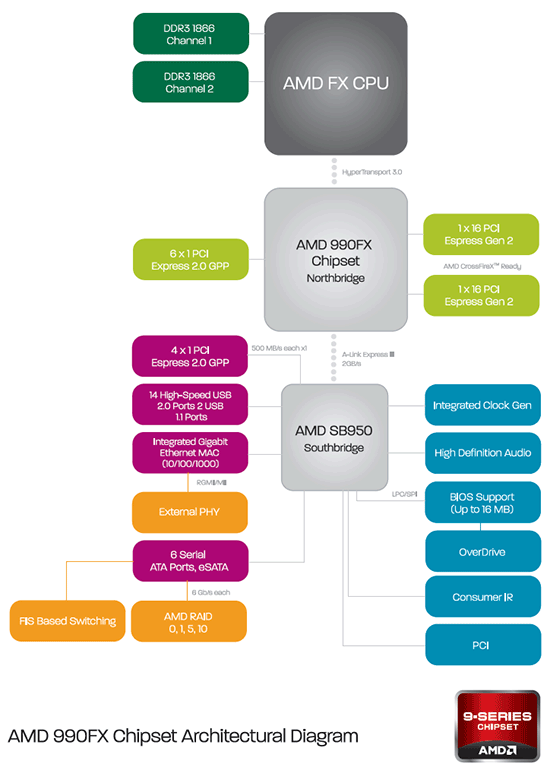 Côté AM3+, AMD propose à l'heure actuelle 3 chipsets qui se distinguent uniquement au niveau de la gestion des cartes graphiques : - 990FX : 2x16 ou 4x8 - 990X : 1x16 ou 2x8 - 970 : 1x16 Il s'agit globalement de chipsets de série 8xx renommés, mais ils ne sont utilisés que sur des cartes mères AM3+ histoire d'essayer de clarifier une situation assez complexe. AMD dispose de ce côté d'un avantage par rapport à l'offre Intel puisque de base le LGA 1155 est équivalent au 990X et qu'il faut passer sur LGA 1366 (et 2011) pour disposer de deux ports x16. L'avantage est certes léger en CrossFire X / SLI, compris entre 2 et 5% lorsqu'on est limité par la puissance graphique, mais présent. Pour le southbridge, on retrouve le SB950 qui intègre notamment 6 ports Serial ATA 6 Gb/s. Page 4 - AMD FX-8150 et FX-6100 en test AMD FX-8150 et FX-6100 en testPour ce test, AMD nous a prêté un processeur AMD FX-8150. Etant donné la présence d'un mode Turbo, il n'est pas possible de simuler de manière fiable les autres processeurs de la gamme. Nous avons pu toutefois nous procurer par une autre source un FX-6100 : 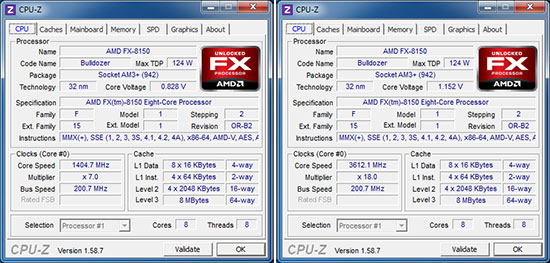 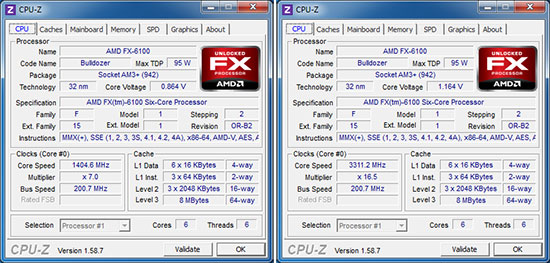 Du point de vue extérieur et en dehors du marquage du processeur, rien ne démarque un AMD FX d'un autre processeur AM3. Nous avons pu remarquer un point de différence sur lequel AMD n'a pas communiqué jusqu'à présent, c'est la vitesse du northbridge intégré au processeur : cadencé à 2.0 GHz sur le FX-6100, comme sur les Phenom II, il est à 2.2 GHz sur le FX-8150.  L'AMD FX-8150 était accompagné d'une carte mère ASUS Crosshair Formula V, une carte très haut de gamme d'ASUS. Ne voyant pas vraiment l'intérêt d'une carte mère quasiment aussi chère que le processeur, et après avoir vérifié que les performances étaient de même niveau, nous avons utilisé une carte mère M5A99X EVO d'ASUS bien plus abordable dotée du bios 810 fournit par ASUS pour les AMD FX. Ceci permettra également d'avoir une meilleure base de comparaison pour la consommation totale du système au repos.  Attention d'ailleurs, avec le bios d'origine le système ne s'initialisait pas avec un AMD FX, il faut donc mettre à jour le bios avec un processeur AM3. Il faut espérer que les cartes vendues dans le commerce disposent déjà d'un bios permettant de démarrer avec un AMD FX ! Page 5 - Nouveau protocole de test Nouveau protocole de testPour ce test, nous avons mis au point un nouveau protocole de test. L'ancien, utilisé pour notre comparatif géant de 185 CPUs, avait en effet 2 ans et il était temps de le dépoussiérer. Afin d'être paré au lancement d'une nouvelle architecture dont le comportement peut fortement varier en fonction des logiciels, nous avons pris pour parti de multiplier les tests afin de nous assurer d'avoir la vision la plus "juste" possible de celle-ci.  Côté 3d, on passe à la version 2011 de 3ds Max, et nous utilisons des scènes proches fournies par Evermotion, l'une préparée pour le moteur de rendu intégré, Mental Ray, l'autre pour un autre moteur de rendu très populaire dans ce domaine, V-Ray 2.0. Pour ce qui est de la compilation nous passons au code source du moteur 3D Ogre qui est compilé à la fois via MinGW / GCC et Visual Studio 2010. 7-Zip, plus efficace tant en terme de compression que d'utilisation du multithread, vient pour sa part rejoindre WinRAR pour la compression de fichiers. Côté encodage vidéo nous conservons x264, dans sa dernière build 2085, que nous utilisons au travers de l'interface StaxRip pour un encodage en 2 passes d'un fichier extrait du film Avatar. Le même encodage est également effectué avec le codec H.264 de MainConcept via leur logiciel Reference. Le traitement des photos en RAW par lot fait également son apparition au sein de notre protocole. Après avoir essayé de multiples logiciels, nous avons arrêté notre choix sur le leader du domaine, Lightroom d'Adobe ainsi que Bibble. Enfin nous terminons ce tour d'horizon applicatif par un type d'application assez particulier, à savoir des algorithmes d'intelligence artificielle destinés aux échecs. Nous utilisons Fritz Chess Benchmarking, de l'éditeur Chess Base, ainsi qu'Houdini Pro 2.0 via l'interface Arena 3. Viennent ensuite les tests destinés à évaluer les performances ludiques des processeurs. Là encore nous avons décidé de multiplier les tests et nous passons à 7 jeux, à savoir : - Crysis 2 - Arma II : Operation Arrowhead - F1 2011 - Rise Of Flight - Total War : Shogun 2 - Starcraft II - Anno 1404  Les tests sont toujours effectués avec un niveau de détail maximal (hors anti aliasing), sauf pour Crysis 2 ou nous préférons le mode Ultra au mode Extreme qui n'offre pas une jouabilité suffisante à moins de disposer de deux cartes graphiques. En effet côté résolution nous abandonnons notre cher 800*600 pour vous fournir des scores en 1920*1080, tout en cherchant malgré tout des scènes assez lourdes qui nous permettent d'être limité en performance par le processeur. Pour Crysis 2, nous utilisons une sauvegarde solo à un endroit chargé et mesurons le framerate pendant une séance continue de tir, alors que sous Arma II : OA avec toutes les options graphiques au maximum la traversée d'un village dans la première mission suffit à mettre à genoux beaucoup de CPU. Pour F1 2011, nous mesurons le framerate durant le départ du GP de Monaco, alors que pour Rise Of Flight on lance une mission personnalisée de 32 contre 32 appareils, le framerate étant mesuré en vue arrière sur nos 31 acolytes. Pour Total War Shogun 2 nous utilisons l'immense bataille du test "DX9 CPU" modifié pour utiliser DX11 et les réglages graphiques adéquats alors que Starcraft II est utilisé via une très importante attaque lors d'un replay, généreusement enregistré par des utilisateurs du forum que nous remercions. Enfin pour Anno 1404 nous chargeons une sauvegarde d'une cité de 46 600 habitants que nous visualisons depuis une vue éloignée. Les concurrentsPour ce test nous avons intégré en face des AMD FX ses prédécesseurs Phenom II X4 et X6, mais aussi les Sandy Bridge Core i7/i5/i3 LGA 1155 ainsi que les Lynnfield Core i7/i5 LGA 1156. A titre de référence nous avons également intégré la plate-forme LGA 775 au travers du Q6600 mais aussi via les Q9650 et QX9770. Par manque de temps nous sommes passés outre les tests sur LGA 1366 pour cette fois, mais il faut bien dire que les AMD FX ont déjà malheureusement fort à faire avec les CPU Intel quatre curs comme vous le verrez par la suite. Sauf mention contraire les tests sont effectués sur les plates-formes suivantes : - ASUSTeK P5QC (LGA775) - Intel DP55KG (LGA1156) - Intel DP67BG (LGA1155) - ASUS M5A99X EVO (AM3+) - 2x4 Go DDR3-1066 7-7-7 (Q6600) - 2x4 Go DDR3-1333 7-7-7 (Q9650) - 2x4 Go DDR3-1600 9-9-9 - GeForce GTX 580 + GeForce 280.26 - SSD Intel X25-M 160 Go + SSD Intel 320 120 Go - Alimentation Corsair AX650 Gold Page 6 - Les unités de calculs Les unités de calculsChacune des deux unités d'exécution x86 du module Bulldozer est composée de deux ALUs (unités arithmétiques et logiques) ainsi que de deux AGUs (unités de génération d'adresse). Plus précisément, AMD parle en fait d'AGLUs plutôt que d'AGUs, ces unités étant capables d'effectuer des opérations simples. 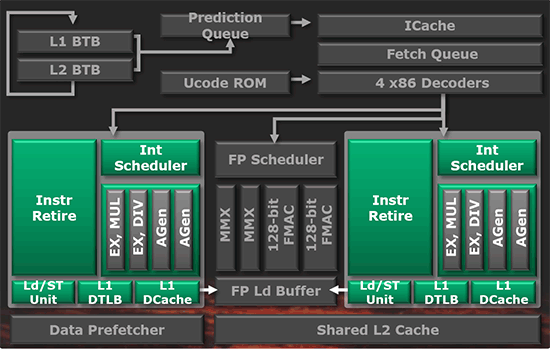 A contrario, l'architecture K10 proposait 3 ALUs et 3 AGUs, ce qui fait qu'avec 3 ALUs contre 2 ALUs Bulldozer peut dans le pire des cas ne pas dépasser 67% d'un K10 sur un seul thread. Côté FPU chaque module est doté d'une seule FPU partagée entre les deux curs. Capable de gérer 2 thread, un pour chacun des curs parents, elle peut également combiner ses deux unités FMAC 128 bits pour traiter les opérations AVX 256 bits. Qu'en est-il en pratique ? Nous avons effectué à l'aide d'AIDA une mesure de la latence et du débit pour les instructions sur K10, Bulldozer et Sandy Bridge dont voici un extrait. La latence représente le délai, exprimé en cycle, pour traiter une seule instruction, alors que le débit mesure la vitesse entre chaque instruction traitée lorsqu'on en traite plusieurs. 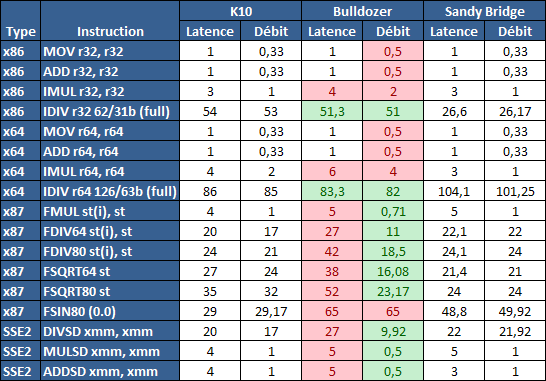 Par rapport à K10, on peut voir que Bulldozer améliore très légèrement la division entière 32 ou 64 bits (IDIV). Cette dernière reste par contre nettement plus rapide en 32 bits sur Sandy Bridge, mais plus lente en 64 bits. La multiplication entière (IMUL) souffre par contre sur Bulldozer tant en terme de latence que de débit, alors que les opérations plus simples telles que la copie (MOV) ou l'addition (ADD) conservent une bonne latence mais voir leur débit baisser, ce qui est lié au passage de 3 à 2 ALUs. Du côté des nombres flottants (x87), et hormis le calcul du sinus qui souffre beaucoup par rapport à K10 qui était nettement plus rapide que SNB, on note une amélioration globale des débits, un bon point si on enchaine le même type d'instruction. Malheureusement c'est loin d'être systématique et la latence souffre beaucoup. Du côté des instructions SSE2, qui sont également exécutées par la FPU, on note le même phénomène. Comme prévu les instructions AES apportent une amélioration des performances importantes, puisque l'on obtient les scores suivants en fonction des architectures (fréquence fixe de 3.2 GHz) sous le test AES de AIDA 64 : - 35 315 pour Yorkfield (Core 2 Quad 65nm) - 433 093 pour Sandy Bridge (Core i7 32nm) - 35 743 pour Deneb (Phenom II X4) - 52 833 pour Thuban (Phenom II X6) - 344 131 pour Zambezi (FX-8) L'apport de l'AVX et du SSE4 est pour sa part plus délicat à démontrer, d'autant plus qu'il est difficile de trouver des versions d'un même programme optimisées correctement pour chaque niveau de jeu d'instruction et pour chaque architecture. Le logiciel y-cruncher par exemple dispose d'une version AVX qui est environ 13% plus rapide que la version SSE3 (les versions SSE4 n'étant pas plus rapide que la version SSE3) sur Sandy Bridge. Ce même code AVX, qui a été optimisé sur la seule architecture AVX disponible (Sandy Bridge) est 10% moins rapide que la branche SSE3 sur Zambezi. En ce qui concerne le FMA4 et le XOP, AMD nous a fournit il y a 48h une version de x264 censée tirer partie de ces instructions. Malheureusement sur nos tests nous n'avons noté aucune amélioration de performances par rapport à la version classique, que ce soit sur la 1ère ou la 2ème passe d'un encodage. Il faut bien dire que les optimisations XOP/FMA4 sont encore au stade de développement pour x264 et n'ont pas intégré la branche de développement principale. Voilà donc une partie qui reste à explorer quant aux performances de l'architecture Bulldozer. Page 7 - Performances des caches Performances cacheAvec Bulldozer, AMD a profondément modifié sa gestion des caches par rapport à K10. D'un cache L1 de 128 Ko par cur, 64 Ko pour les instructions et 64 Ko pour les données, on passe ainsi à un cache de 64 Ko pour les instructions par module, et donc commun à deux curs, chacun d'eux disposant par ailleurs d'un cache de données de 16 Ko. Le cache L2 passe pour sa part à 2 Mo par module, contre 512 Ko à 1 Mo par cur sur les différentes architectures K10. Là où ces derniers se partageaient un cache L3 atteignant au mieux 8 Mo, on va cette fois jusqu'à 6 Mo. La hiérarchie des caches a également été modifiée comme nous l'indiquions dans notre article théorique, avec notamment une relation partiellement inclusive entre le L1D et le L2. Quid des performances en pratique de ces caches ? Nous les avons mesurées à l'aide d'AIDA, à une fréquence de 3.2 GHz pour K10, Bulldozer et Sandy Bridge : 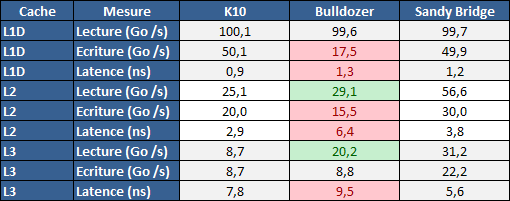 Le cache L1D des trois architectures est équivalent pour ce qui est de la lecture, et on note une hausse de la latence entre K10 et Bulldozer. Le débit en écriture s'effondre par contre complètement puisque du fait de la politique de write-through l'écriture se fait en parallèle dans le cache L1D et dans le L2 plus lent. Le cache L2 est pour sa part plus rapide en lecture sur Bulldozer que sur K10 à fréquence égale, mais moins rapide en écriture et avec une latence bien plus élevée. Côté L3, on note une très forte hausse des performances en lecture, alors que l'écriture est stable et que la latence est en hausse. Il est difficile de juger sur la base de ces chiffres de l'efficacité d'un système de cache mis au point via de nombreuses simulations. Tout est question de compromis et si la hausse des latences et la baisse des débits en écriture ne sont pas des points positifs ils sont compensés par un cache L2 bien plus gros ainsi que des débits en lecture globalement en hausse, une bonne chose étant donné que l'on lit bien plus souvent que l'on écrit dans ces caches. Page 8 - Performances mémoire Performances mémoireNous avions déjà pointé du doigt dans différents articles la relative faiblesse du contrôleur mémoire d'AMD en termes de débits, notamment en écriture. Nous étions donc curieux de voir si ce point avait été amélioré en pratique, et nous avons mesuré la bande passante mémoire via un seul thread sous AIDA64 et via de multiplies thread sous RMMT sur les différentes architectures à 3.2 GHz et accompagnées de DDR3-1600 9-9-9 : 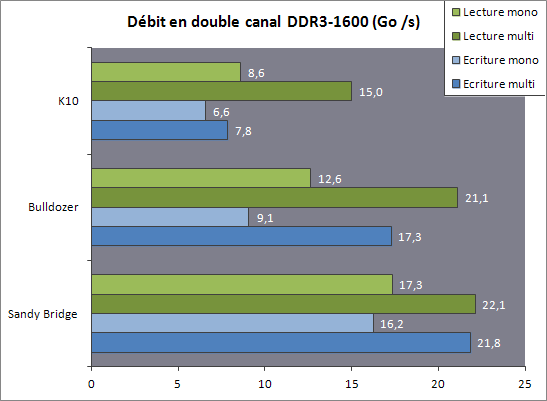 AMD a fait du bon travail sur son nouveau contrôleur mémoire puisque les débits sont en hausse de 47% en monothread et 40% en multithread face au K10. En écriture monothreadées le gain est de 38% alors qu'en multithread les débits sont plus que doublés ! Cette très bonne progression permet à Bulldozer de se rapprocher de Sandy Bridge en multithread, mais ce dernier reste nettement plus rapide avec un seul thread. On notera au passage que la DDR3-1866 est désormais officiellement supportée, en lieu et place de la DDR3-1333 sur la génération précédente. Comme d'habitude il est possible d'aller plus loin puisque si la DDR3-1600 était possible sur K10, sur Bulldozer on dispose désormais des coefficients pour fonctionner en DDR3-2133 et DDR3-2400. Nous n'avons toutefois pas pu faire fonctionner le mode DDR3-2133 à ce jour, et en DDR3-1866 9-10-9-28 les performances ne sont pas vraiment meilleures qu'en DDR3-1600 9-9-9 :  On perd ainsi 1% sous V-Ray, on gagne 1% sous Visual Studio 2010 alors que les performances sous MainConcept H.264, Bibble et Fritz sont stables. On gagne par contre 1.5% sous Arma II : OA, 2% sous Anno 1404 et 2% sous 7-zip. Des écarts qui restent donc marginaux. Page 9 - Efficacité du CMT Efficacité du CMTBulldozer chamboule quelque peu la définition de cur, telle qu'elle est implémentée sur les architectures x86 actuelles puisque ce qu'AMD appelle 2 curs partagent au sein d'un module des ressources qui étaient précédemment dédiées. Il faut savoir que lorsqu'AMD avait déposé ses brevets lié à Bulldozer, les ingénieurs avaient fait le choix d'appeler ce qui est aujourd'hui un module un cur, et ce qui est un cur un cluster. La dénomination finale choisie par AMD est-elle pour autant complètement abusive ? Afin d'y voir plus clair nous avons effectués sur un processeur d'architecture Bulldozer cadencé à 3.2 les tests suivants : - Test en mode 4 modules et 8 curs - Test en mode 2 modules et 4 curs - Test en mode 4 modules et 4 curs Pour le premier cas, c'est relativement simple puisqu'il s'agit de la configuration de base. Pour le second, notre carte mère permet de désactiver certains modules. Pour le troisième c'est plus compliqué puisqu'il nous faut définir l'affinité sur les bons curs (les CPU 0, 2, 4 et 6 dans Windows), en limitant si possible le nombre de threads exécutés par l'application à 4. Ce dernier test est impossible avec les tests sous MinGW ou Visual Studio, de nombreux processus étant utilisés au fil de la compilation. Pourquoi faire ce test ? Cela permet de voir si l'affirmation d'AMD indiquant que 2 curs CMT valent 80% de deux curs standards d'une même architecture est valide, et de manière liée si l'augmentation des performances entre 4 et 8 curs justifie l'appellation de processeurs "8 curs" donnée par AMD. Dans ce premier tableau, la version 4 modules 4 curs obtient l'indice 100. 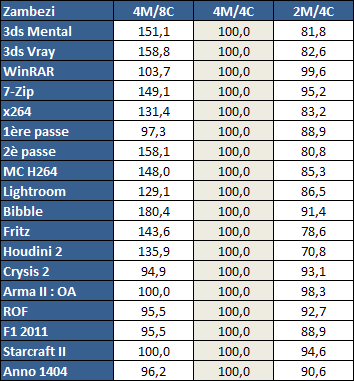 Selon les tests et si on exclue les tests qui ne chargent pas complètement 4 curs (WinRAR, la 1ère passe x264 et les jeux), on obtient 71 à 95% des performances de la configuration 4 modules / 4 curs avec 2 modules / 4 curs. L'affirmation d'AMD concernant l'efficacité du CMT semble donc exacte. Par contre si un logiciel ne charge pas complètement les 4 curs, c'est le mode 4 modules / curs qui est le plus rapide, même si l'écart est souvent réduit. Mais le Bulldozer peut-il pour autant être considéré comme un 8 cur ? Ou dois-t-on plutôt parler d'un processeur 4 curs 8 thread comme c'est le cas d'Intel pour ses processeurs avec Hyperthreading. Voici les gains occasionnés par l'Hyperthreading sur Sandy Bridge, le passage de 4 à 6 curs sur K10 et le CMT sur Bulldozer dans les applications les plus multi-threadées : 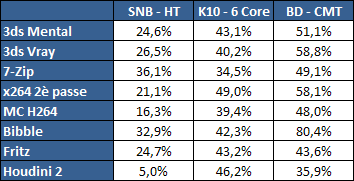 En moyenne, l'Hyperthreading offre un gain de 23,4%, contre 42,2% pour le passage de 4 à 6 curs sur K10 et 53,1% pour le CMT intégré dans le Bulldozer. On est donc bien au-delà de ce qu'apporte l'Hyperthreading et parler d'un processeur 8 curs nous semble le plus proche de la réalité pratique. Bien entendu, les esprits chagrins diront qu'en utilisant cette dénomination, AMD dispose d'un avantage assez limite en terme de marketing par rapport à Intel : 8 curs, c'est forcément mieux que 4 pour beaucoup. Mais on peut également voir le verre à moitié plein : cela permet aussi d'indiquer qu'il faut 8 threads lourds afin d'exploiter le plein potentiel de la puissance de calcul qui nous est offerte, ce qui n'est pas le cas avec 4 threads. Certes, ce n'est certainement pas le message initial que voulait faire passer l'équipe marketing, ni celui que relaiera le vendeur du rayon information de votre grande surface... Page 10 - CMT, Turbo Core 2.0 et Windows 8 CMT, Turbo Core 2.0 et Windows 8L'AMD FX intègre une évolution du Turbo Core d'AMD. Sur Phenom II X6, Turbo Core n'agissait que si au maximum la moitié des curs étaient actifs et on avait donc par exemple sur le 1100T : 1) 3.3 GHz comme fréquence de base 2) Jusqu'à 3.7 GHz avec jusqu'à 3 curs en charge Sur un AMD FX-8150 la nouvelle version du Turbo Core permet de définir plusieurs versions : 1) 3.6 GHz comme fréquence de base 2) Jusqu'à 3.9 GHz avec tous les modules en charge 3) Jusqu'à 4.2 GHz avec 2 modules en charge 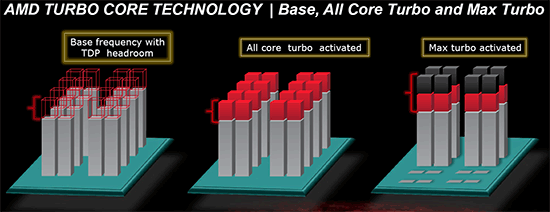 Cette hausse de fréquence se fait comme c'est le cas chez Intel dans la limite du TDP, et l'on obtient généralement pas la fréquence maximale en continue sur tous les modules. 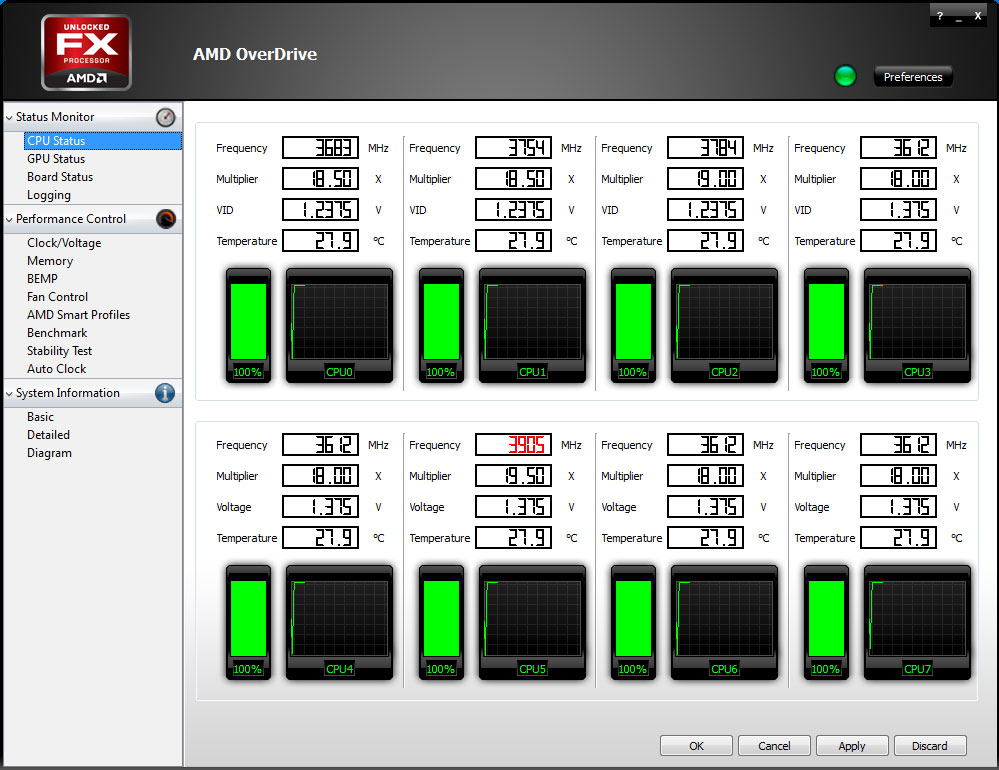 Sur cet exemple la fréquence des différents module varie entre 3612 et 3905 MHz, tout comme la tension varie entre 1.2375V et 1.375V. Il faut noter que la mise à jour des fréquences sous AMD OverDrive ne semble pas se faire exactement en même temps ce qui explique les incohérences tel que des fréquences distinctes pour deux CPU d'un même module ou un VID élevé malgré une fréquence de base. Vous aurez remarqué que nous parlons en termes de module et non plus de curs pour le fonctionnement du Turbo. Ainsi, si vous avez 4 thread répartis sur 4 modules, vous vous retrouverez dans le cas n°2, soit 3.9 GHz au mieux, alors que vous auriez pu atteindre les 4.2 GHz avec 4 thread répartis sur 2 modules. Pourtant cette dernière option n'est pas forcément la plus efficace puisque le CMT n'offre que 80% des performances des curs complets. Si on regarde ce qui se passe sur Fritz Chess Benchmark, on obtient les performances suivantes : 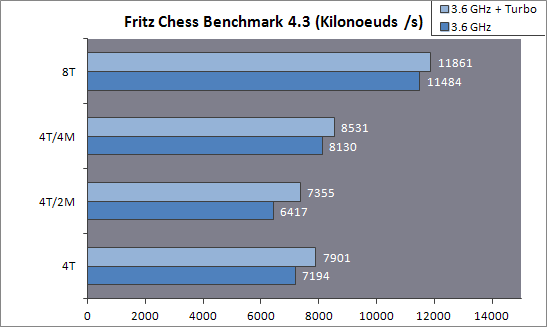 Pour Windows 7 SP1, tous les curs d'un AMD FX se valent et ce dernier ne favorise donc pas un plus que l'autre. Les performances obtenues de base avec 4 threads (4T) sont donc comprises entre celles obtenues lorsqu'on les force sur 4 curs de 2 modules (4T/2M) et 4 curs de 4 modules (4T/4M). L'activation du Turbo apporte un gain variable en fonction de l'occupation des modules, ce qui est normal. En mode 4T on gagne 9,8%, contre 14,6% si on se limite à 2 modules et seulement 4,9% sur 4 modules. Le Turbo ne parvient toutefois pas à compenser l'efficacité réduite du CMT par rapport à des curs non partagés et c'est tout de même le réglage 4T/4M qui est ici le plus performant avec 4 thread. Avec 8 threads, le gain offert par le Turbo est de 3,3%. Ce positionnement des threads a bien entendu une influence sur la consommation puisque cette dernière varie fortement en fonction de la configuration comme vous pouvez le voir ici : 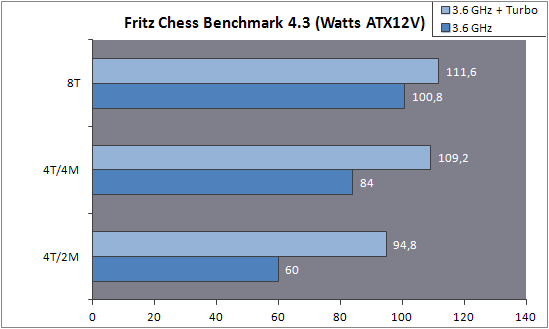 C'est logiquement lorsque les 4 threads sont positionnés sur deux modules que la consommation est moindre. On peut évaluer le coût du CMT en termes de consommation à 20% si l'on compare les performances entre 4 threads sur 4 modules et 8 threads. Quid de l'efficacité des performances par watts ? Les voici récapitulées : 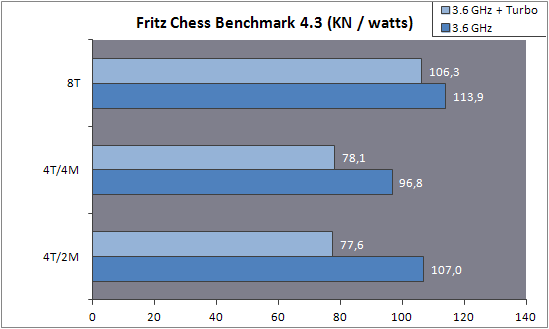 Sans le mode Turbo, on obtient les meilleures performances par watts pour 4 threads lorsqu'ils sont groupés sur 2 modules : la baisse de performance est plus que compensée par la baisse de consommation. Comme vous pouvez le voir, l'augmentation de performance liée au Turbo se fait pour sa part au détriment de l'efficacité énergétique du processeur.  Il faut noter que Windows 8 devrait changer la donne en ce qui concerne la répartition des threads sur les processeurs AMD FX. Au lieu d'une répartition sans distinction entre les curs, Windows favorisera ceux au sein d'un même module afin d'utiliser le moins de module possible. Un choix qui peut sembler au premier abord incohérent étant donné que les résultats obtenus sous Fritz Chess Benchmark sont bien meilleurs lorsqu'on ne favorise pas les modules. Ce serait oublier qu'une grosse partie des applications lourdes n'utilisant pas pleinement un processeur 8 curs sont des jeux et qu'ils peinent même aujourd'hui à occuper pleinement 4 curs. En page précédente, nous avons ainsi vu qu'avec seulement un demi Zambezi, soit 2 modules et 4 curs, on obtenait 89 à 98% des performances sur 4 modules et 4 curs. Dès lors il peut devenir intéressant de favoriser le Turbo et donc de grouper les threads sur un minimum de module, c'est le choix qui a été fait par AMD via Windows 8. Néanmoins le gain de performance devrait être au final, sauf cas particulier, marginal. De notre côté nous avons observé que les performances variaient de -3% et +3% en forçant l'affinité des jeux sur 2 modules sur un AMD FX-8150 avec Turbo par rapport à la configuration de base de Windows 7 SP1. Page 11 - Tests à 3.2 GHz Tests à 3.2 GHzComme à chaque lancement d'architecture, nous avons effectué des tests à une fréquence égale de 3.2 GHz. Bien entendu, un tel test n'offre qu'une vision partielle des performances d'un processeur et même d'une architecture puisqu'il ne prends pas en compte les fréquences plus importantes qui peuvent être permises par des concessions sur les performance à fréquence égale. Les performances sont reportées avec une base 100 équivalente au Deneb à 3.2 GHz (Phenom II X4 955) : 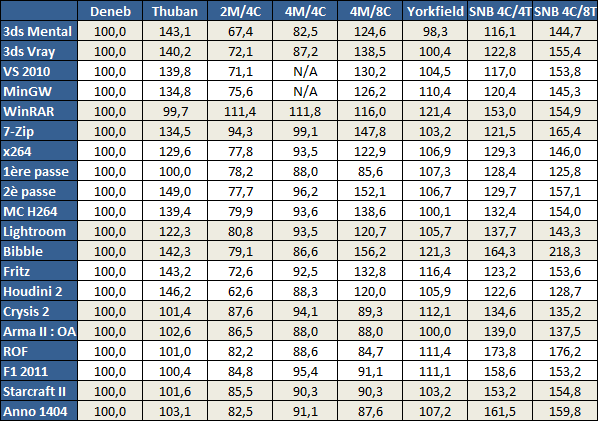 Comme vous pouvez le voir, Zambezi souffre d'un déficit de performances lorsque les architectures sont comparées à fréquence égale. En version 4 curs (2 modules), il offre en effet 62,6 à 111,4% des performances de Deneb (Phenom II X4). Ce dernier score fait figure d'exception et la moyenne ressort à 80,8%. Les choses s'arrangent quand on part sur la version 8 curs (4 modules) dès lors que les applications en tirent parti, mais ce n'est pas le cas des jeux qui restent à la traine. Et dans les applications exploitant 8 curs, Zambezi ne fait mieux que Thuban que sous 7-zip, la seconde passe de x264 et Bibble. La comparaison avec l'offre Intel est encore plus désavantageuse pour Zambezi puisque le Yorkfield à 3.2 GHz (Intel Core 2 QX9770) fait nettement mieux dans les jeux, un avantage encore accentué avec Sandy Bridge. Dans les applications multithreadées Zambezi parvient régulièrement à s'intercaler entre SNB avec et sans HT, mais reste parfois derrière. Page 12 - Consommation et efficacité énergétique Consommation et efficacité énergétiqueDans nos précédents articles dédiés aux processeurs, nous mesurions la consommation en charge sous Prime95. Ce stress test a le mérite de pousser de manière assez équitable les différentes architectures dans leurs derniers retranchements, mais il nous était impossible de mettre en parallèle consommation et performance, le benchmark intégré à Prime95 consommant moins et n'étant pas aussi équilibré entre les processeurs. Nous avons donc décidé de chercher un autre logiciel offrant sur toutes les architectures un niveau de performance et de consommation représentatif de ce que nous obtenions sur les autre applications de notre protocole de test. Au final notre choix s'est porté une nouvelle fois sur sous Fritz Chess Benchmark, qui a de plus l'avantage de pouvoir facilement fixer le nombre de thread à utiliser. Les mesures de consommation ne sont donc pas à prendre comme des valeurs maximales absolues mais plutôt typique d'une charge lourde, puisque des logiciels spécialisés dans le stress processeur tels que Prime95 peuvent consommer environ 20% de plus. Toutes les fonctionnalités d'économie d'énergie, y compris celles des cartes mères comme l'EPU d'ASUS, sont activées pour ce test du moment qu'elles n'impactent pas négativement les performances : 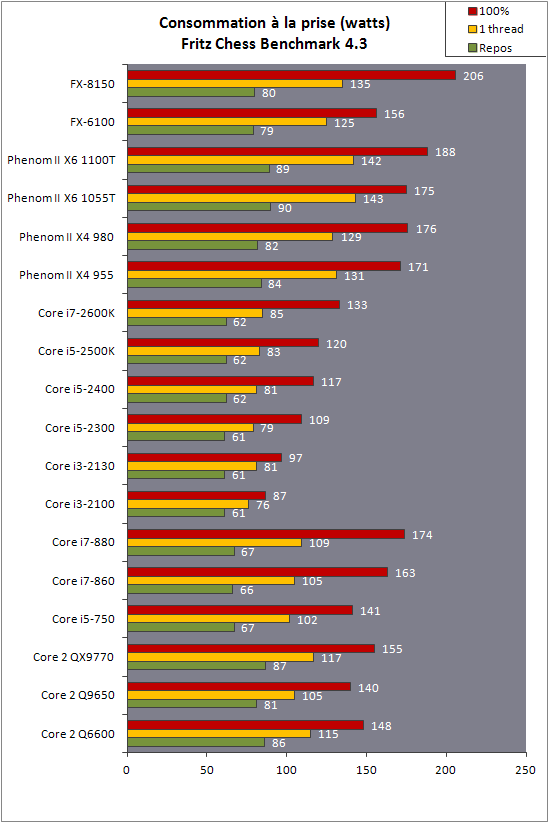 [ Prise 220V ] [ ATX12V ] Les AMD FX sont plus économes que les Phenom II X6 et même X4 au repos, ce qui est une avancée très intéressante. On est malheureusement encore nettement au dessus de la consommation des plates-formes Intel 1155 et 1156. En charge légère (1 thread), la consommation se situe à peu près au même niveau que celle des Phenom II X4 alors qu'en charge lourde (100%) on va au-delà pour le FX-8150. La mesure sur l'ATX12V permet d'isoler la consommation du processeur. Les chiffres ne sont malheureusement pas exactement comparables puisque dans certains cas une petite partie de la consommation du CPU est issue de la prise ATX 24 pins standard. A défaut, on peut toutefois comparer les processeurs qui utilisent une même carte mère. Les tendances observées sur la mesure à la prise sont bien confirmées. Reste maintenant à représenter l'efficacité énergétique d'un processeur. Pour se faire il s'agit de diviser la performance obtenue sous Fritz Chess Benchmark par la consommation du CPU. Seul problème, il n'est pas possible de connaitre exactement celle-ci : la mesure sur l'ATX12V n'est pas 100% comparable d'une plate-forme à une autre, et la mesure à la prise ne permet pas complètement d'isoler tout ceci. Nous avons donc fait le choix d'utiliser deux méthodes de calcul pour isoler la consommation de processeur : - Consommation sur l'ATX12V - 90% du delta de consommation à la prise entre charge et repos Nous utilisons les 90% afin d'exclure le rendement de l'alimentation à proprement parler. Il faut noter que si la première mesure favorise les processeurs tirant une petite partie de leur énergie via la prise ATX classique, la seconde favorise ceux qui ont une consommation élevée au repos. Malheureusement aucune méthode n'est parfaite. 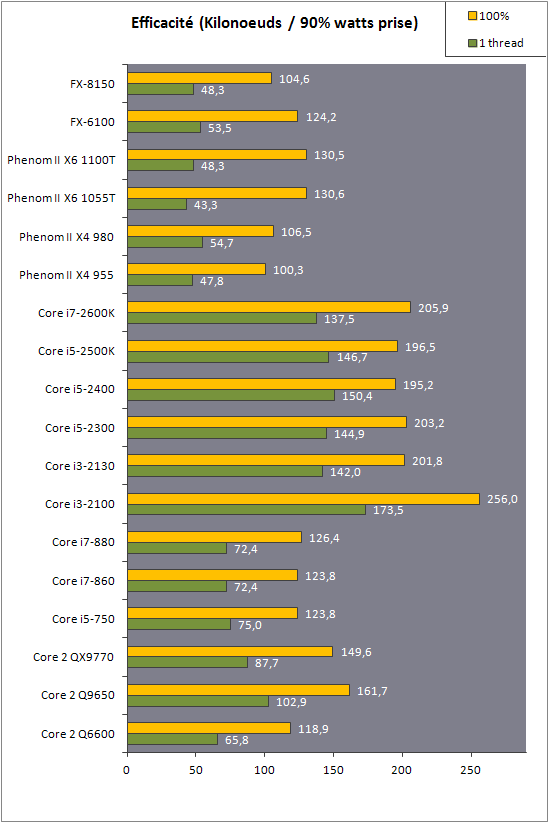 [ Prise 220V ] [ ATX12V ] Si on se contente de comparer les processeurs AM3/AM3+ entre-eux le graphique sur l'ATX12V nous permet de dire que l'efficacité énergétique n'as pas vraiment évoluée depuis les Phenom II. Avec un thread, on reste à des niveaux comparables, et avec une utilisation maximale du processeur on est en dessous des Phenom II X6. Pour le moment, l'architecture Bulldozer et son CMT ne sont pas convaincants dans ce domaine. La comparaison avec l'offre Intel fait mal quelque soit la mesure utilisée. Même en multithread, AMD atteint en effet le niveau de la génération précédente 45nm LGA 1156, et les Sandy Bridge 32nm LGA 1155 sont clairement dans un autre monde. Page 13 - Overclocking OverclockingDestinée à pouvoir soutenir de hautes fréquences, les AMD FX ont fait parler d'eux dans le domaine de l'overclocking puisque AMD a annoncé en fanfare il y a peu avoir battu le record de fréquence pour un processeur x86 avec pas moins de 8429 MHz sous hélium liquide. Il ne s'agit pas d'une fréquence stable, mais maximale, obtenue avec un refroidissement extrême et sur seulement un module. Quid d'un overclocking plus classique ? Nous avons essayé d'overclocker notre FX-8150 à l'aide d'un Noctua NH-U12P SE2, toujours sur la M5A99X EVO.  En réglant le CPU Load Line Calibration à High, et en rajoutant via Offset 0.16v à la tension processeur nous avons pu stabiliser sous Prime95 une fréquence de 4.6 GHz en utilisant un coefficient multiplicateur de x23, ce dernier étant débloqué sur toute la gamme FX, une très bonne chose là où il faut payer un modèle K chez Intel. 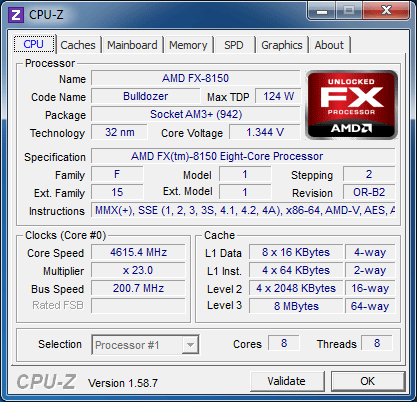 4.6 GHz, c'est bien, mais pourquoi nous être arrêtés en si bon chemin ? Tout simplement parce que la consommation explose déjà avec ce réglage. Par rapport à la configuration de base, en charge CPU sous Fritz Chess Benchmark on passe ainsi de 206 à 313 watts de consommation à la prise et de 109 à 206 watts via l'ATX12V seul. Le résultat passe lui à 14602 Kilonoeuds par seconde, soit 23% de mieux que le réglage par défaut, ce qui fait tout de même assez peu pour une consommation qui est quasiment doublée pour le processeur. Sous Prime95 la consommation sur l'ATX12V montait même à 255 watts, et lors d'essais d'overclocking plus poussés nous avons pu voir des consommations démentielles pouvant atteindre les 300 watts sur l'ATX12V. Si l'AMD FX affole les compteurs pour les overclockings extrême, l'exercice semble donc plus délicat pour ceux utilisables au quotidien... reste à voir si les versions du commerce offriront de meilleures prestations. Pour ce qui est de l'undervolting nous n'avons pas pu faire mieux que 0.05v de moins, ce qui fait économiser une dizaine de watts de consommation. Page 14 - Rendu 3D : Mental Ray et V-Ray 3d Studio Max 2011 - Mental Ray  Nous passons aux tests pratiques avec pour commencer un rendu 3d sous 3d Studio Max 2011 en utilisant le moteur de rendu Mental Ray sur une scène d'Evermotion . Le rendu est effectué en 600*375 afin de garder un temps de test raisonnable. 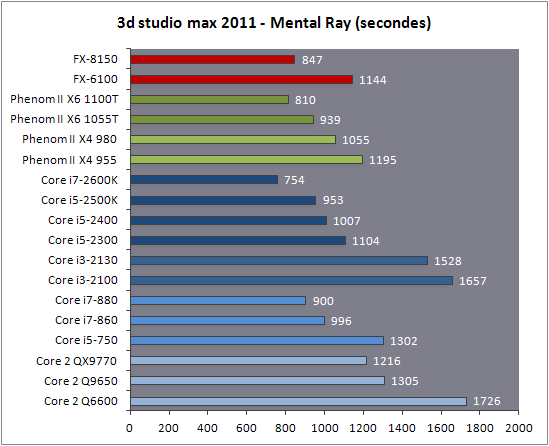 Grosse déception ici puisque le FX-8150 ne parvient pas à faire mieux que le Phenom II X6 1100T. Le FX-6100 est pour sa part nettement distancé par le 1055T pourtant au même tarif. AMD conserve toutefois un bon positionnement par rapport à l'offre Intel à tarif équivalent puisque l'on reste intercalé avec le FX-8150 entre le 2500K et le 2600K, ce qui n'est certes pas un exploit transcendant au vue de la débauche de transistors. 3d Studio Max 2011 - V-Ray 2.0  Toujours sous 3d Studio Max 2011, on change de moteur pour le moteur tiers le plus populaire, V-Ray 2. On utilise une autre version de la même scène préparée par Evermotion pour ce moteur, le rendu étant toujours effectué en 600*375. Les temps de rendu sont nettement plus rapides, toutefois il ne s'agit pas de comparer les moteurs entre eux puisqu'il faudrait également observer de manière très attentive la qualité des fichiers finaux. 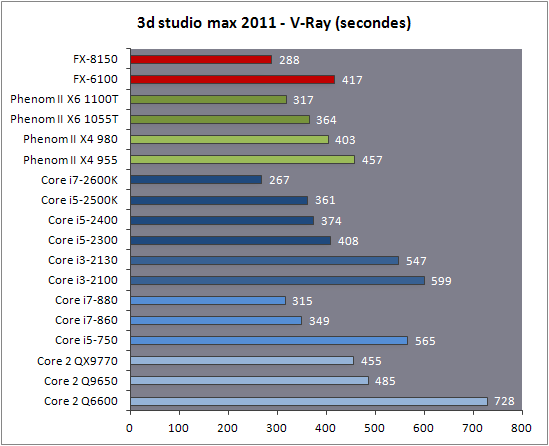 Cette fois le FX-8150 apporte un gain significatif par rapport au 1100T, mais le FX-6100 reste en retrait par rapport au 1055T qui est pourtant au même tarif. Ceci permet au FX-8150 de se rapprocher d'un 2600K qui conserve malgré tout une marge encore confortable. Page 15 - Compilation : Visual Studio et MinGW/GCC Visual Studio 2010 SP1  Nous compilons sous Visual Studio 2010 SP1 le code source du moteur 3D Ogre. 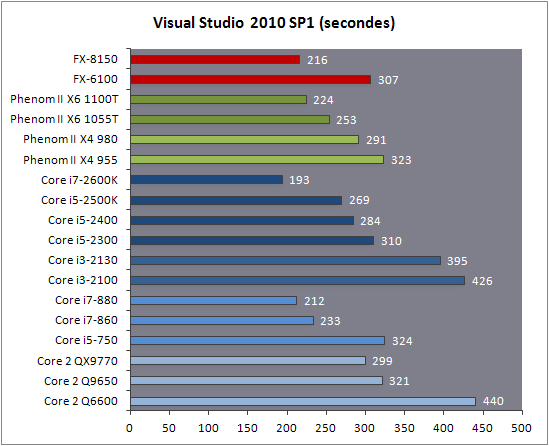 Le FX-8150 est légèrement plus rapide que le 1100T, mais le FX-6100 n'arrive pas au niveau du 1055T. Là encore le FX-8150 se rapproche du 2600K mais il conserve une avance confortable de près de 12%. MinGW / GCC 4.5.2  Le même code source est cette fois compilé sous MinGW / GCC 4.5.2. 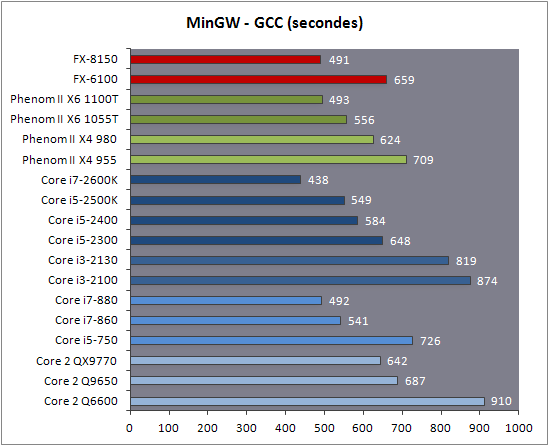 Malheureusement cette fois le FX-8150 obtient des performances proches de celles du X6 1100T. Il vient en fait s'intercaler parfaitement entre le 2600K et le 2500K. Le FX-6100 confirme son mauvais positionnement face au 1055T. Page 16 - Compression : 7-zip et WinRAR 7-zip 9.2  7-zip rejoint notre protocole de test. Contrairement à WinRAR ce logiciel est fortement multithreadé si on utilise son algorithme le plus performant, LZMA2. Nous mesurons le temps nécessaire pour compresser un volume important de fichiers. 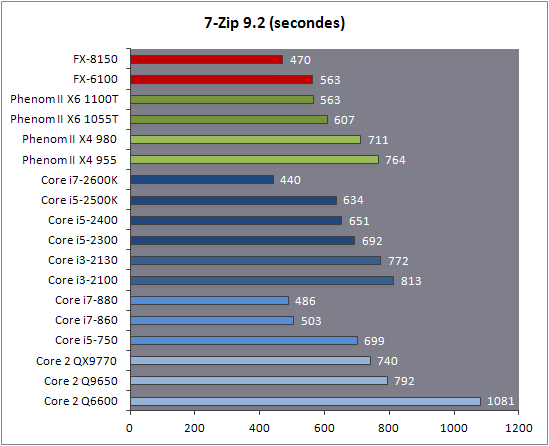 Cette fois le gain de performance est substantiel puisque le FX-6100 parvient à se positionner au même niveau que le 1100T. Le FX-8150 se rapproche pour sa part d'un i7-2600K, mais ce dernier conserve encore près de 7% d'avance. La taille des caches ainsi que les améliorations du contrôleur mémoire ne sont pas étrangères à ces gains, les logiciels de compressions étant généralement gourmands de ce côté. WinRAR 4.01  Les mêmes fichiers sont compressés sous WinRAR en utilisant l'algorithme RAR le plus poussé ("Best"). 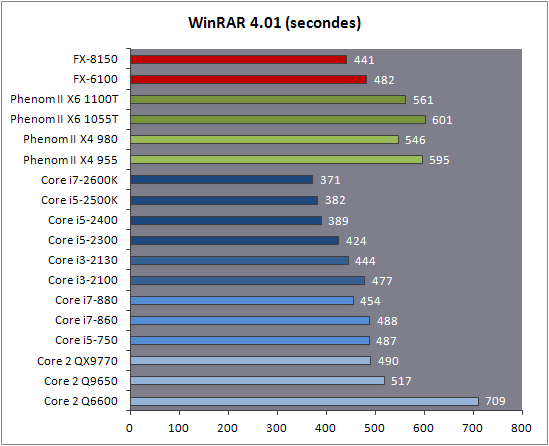 WinRAR ne tire malheureusement pas vraiment parti de plus de 2 curs, mais là encore il semble apprécier les caches et le contrôleur mémoire des AMD FX. Le gain est important par rapport à la génération précédente, mais malheureusement pour AMD WinRAR est encore plus à l'aise sur les processeurs Intel, la faible dose de multithreading n'aidant pas. Page 17 - Encodage : x264 et MainConcept H.264 StaxRip - x264 build 2085  Pour l'encodage vidéo nous avons conservé le célèbre x264, ici dans sa build 2085. Nous utilisons l'interface StaxRip pour transcoder un extrait 1080p tiré du Blu-ray du film Avatar en utilisant 2 passes en mode fast avec un bitrate de 10 Mbits /s. Les temps des deux passes sont reportés, la 1ère étant moins multithreadée que la seconde et ne profitant pas de vraiment de plus de 3 à 4 curs. 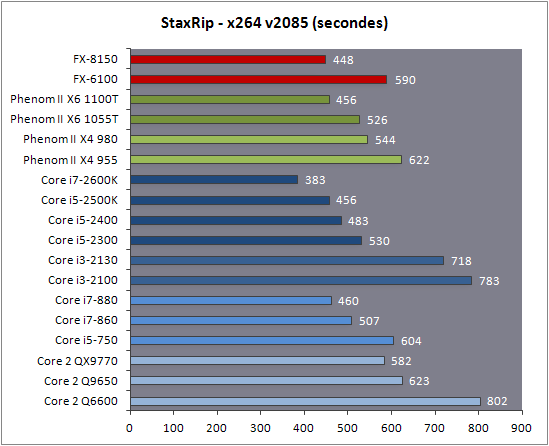 [ Total ] [ 1ère passe ] [ 2nde passe ] Pour cette utilisation très populaire, le FX-8150 n'apporte qu'un gain mineur comparé au 1100T, et on est donc juste devant un 2500K (seulement). Si on regarde dans le détail, on peut voir que les FX souffrent beaucoup sur la 1ère passe mais se comportent mieux sur la seconde, durant laquelle le FX-8150 fait jeu égal avec le 2600K ! Notez qu'AMD nous a fournit il y a 48h une version de x264 censée tirer partie de ces instructions FMA4 et XOP. Malheureusement sur nos tests nous n'avons noté aucune amélioration de performances par rapport à la version classique, que ce soit sur la 1ère ou la 2ème passe d'un encodage. Il faut bien dire que les optimisations XOP/FMA4 sont encore au stade de développement pour x264 et n'ont pas intégré la branche de développement principale. Voilà donc une partie qui reste à explorer quant aux performances de l'architecture Bulldozer. MainConcept Reference 2.2 H264 Pro  On passe maintenant à un autre codec H.264, celui de MainConcept. Nous utilisons l'interface MainConcept Reference H.264 pour effectuer le même type de transcodage que sous x264. Il faut noter que la 1ère passe est mieux multithreadée et nous ne reportons cette fois que le score global. 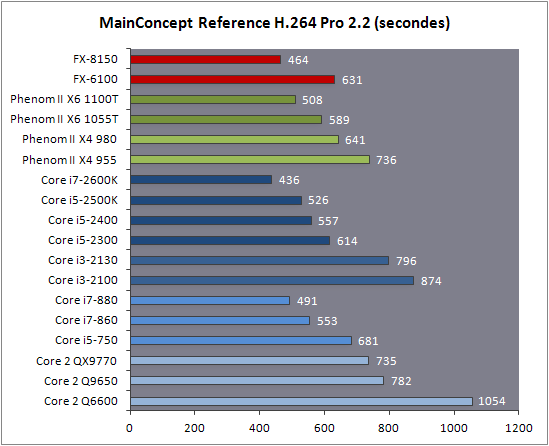 Le FX-8150 est cette fois 9,4% plus rapide que le 1100T, mais le FX-6100 n'arrive pas à passer devant le X6 1055T. Par rapport à l'offre Intel le FX-8150 vient s'intercaler entre le 2600K et le 2500K. Page 18 - Traitement photo : Lightroom et Bibble Adobe Lightroom 3.4  Le traitement des photos par lot fait son apparition au sein de notre protocole. On commence par Lightroom au sein duquel nous exportons en JPEG un lot de 96 photos RAW issues d'un 5D Mark II tout en leur appliquant divers effets, tels que des corrections colorimétriques, d'objectif ou encore le traitement du bruit. 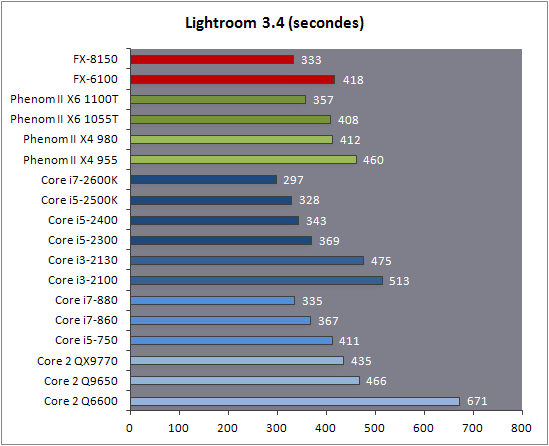 Les puces AMD avaient dans ce domaine un retard assez important, quelque soit le logiciel (nous avons eu l'occasion d'en tester plusieurs lors de la mise au point du protocole). Sous Lightroom l'AMD FX permet de le combler en partie puisque le FX-8150 arrive quasiment au niveau du 2500K, mais le 2600K reste inaccessible. Bibble 5.2.2  Sous Bibble nous traitons un lot de 48 photos RAW. Vous noterez que Bibble est plus lent que Lightroom, mais comme pour les moteurs de rendu ce test n'est pas là pour comparer les logiciels entre eux d'autant qu'il faudrait alors comparer minutieusement la qualité des sorties : un export plus lent peut aussi être plus qualitatif. 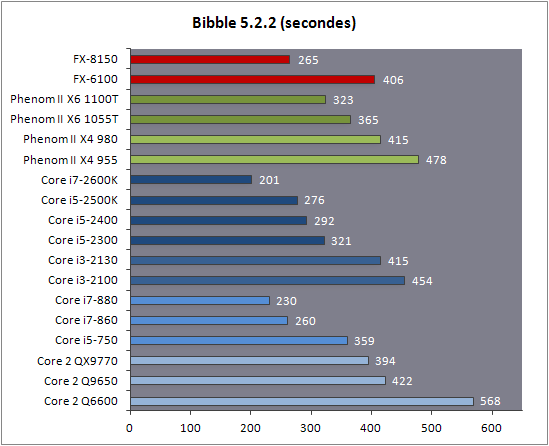 Le retard d'AMD était encore plus marqué sous Bibble. Le gain apporté par les AMD FX est très important puisque le FX-8150 est près de 22% plus rapide que le 1100T. Cela lui permet de dépasser le 2500K, ce qui en soit n'a rien d'exceptionnel mais l'est plus quand on voit le 1100T au niveau d'un i5-2300. Page 19 - IA d'échecs : Houdini et Fritz Houdini 2.0 Pro  Enfin nous terminons ce tour d'horizon applicatif par un type d'application assez particulier, à savoir des algorithmes d'intelligence artificielle destinée aux échecs. On commence par Houdini Pro 2, utilisé via l'interface Arena 3. La version 1.5 trustait les 1ères places des classements des moteurs d'échecs et la version 2 semble promise au même avenir. Nous laissons tourner le moteur jusqu'au 24è tour en début de partie et notons la vitesse exprimée en Kilonoeuds par secondes. 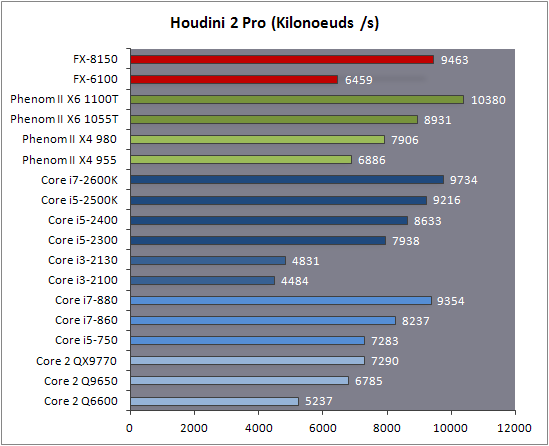 Houdini est friand de l'architecture K10, et c'est le 1100T qui domine ici les débats. Le FX-8150 est en retrait mais s'intercale tout de même entre les 2500K et 2600K. Le FX-6100 est par contre en net retrait. Fritz Chess Benchmark 4.3  Nous passons maintenant à Fritz Chess Benchmarking, de l'éditeur Chess Base. Là encore les chiffres sont exprimés en Kilonoeuds par secondes. 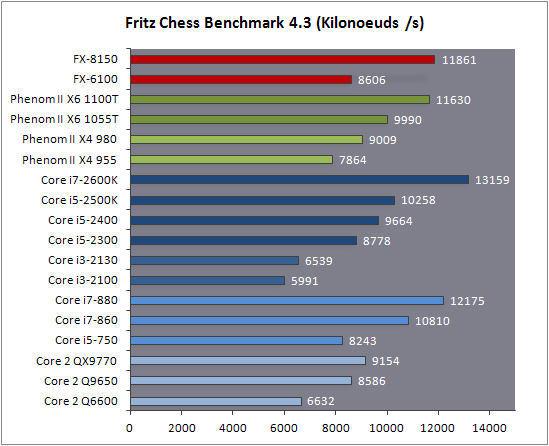 Cette fois le FX-8150 est légèrement devant le 1100T. Une nouvelle fois il s'intercale entre les 2500K et 2600K. Page 20 - Jeux 3D : Crysis 2 et Arma II : OA Crysis 2 v1.9  Crysis 2 inaugure la partie jeux 3D de ce comparatif. Nous utilisions la dernière version 1.9 en DirectX 11 et mesurons le framerate obtenu en 1920*1080 Ultra à un emplacement précis au cours d'une fusillade.  Crysis 2 ne tire pas vraiment profit de plus de 4 curs, ce qui ne permet pas aux AMD FX de s'exprimer pleinement. Dès lors étant donné leurs faibles performances lorsque seulement 4 curs sont pleinement exploités on se retrouve malgré sa fréquence avec un FX-8150 qui ne parvient pas à se hisser au niveau des X6 1100T et X4 980. La comparaison avec l'offre Intel est catastrophique puisqu'un simple i3-2100 suffit pour atteindre les mêmes performances. Arma II : Operation Arrowhead v1.59  Sous Arma II : Operation Arrowhead nous mesurons le framerate lors de la traversée d'un village lors de la première mission solo, toujours en 1920*1080 et toutes options poussées au maximum, y compris la distance de visibilité.  Les mêmes causes ont les mêmes effets : comme sous Crysis 2 le FX-8150 est dépassé par ses prédécesseurs et le Core i3-2100 est également plus véloce. Page 21 - Jeux 3D : Rise of Flight et F1 2011 Rise Of Flight v1.021b  Rise Of Flight, simulateur d'avions de chasses de la 1ère guerre mondiale, est utilisé en 1920*1080 avec un niveau de détail élevé. Pour ce test nous lançons une mission personnalisée avec un combat de 32 contre 32 appareils, le framerate étant mesuré en vue arrière sur nos 31 acolytes. 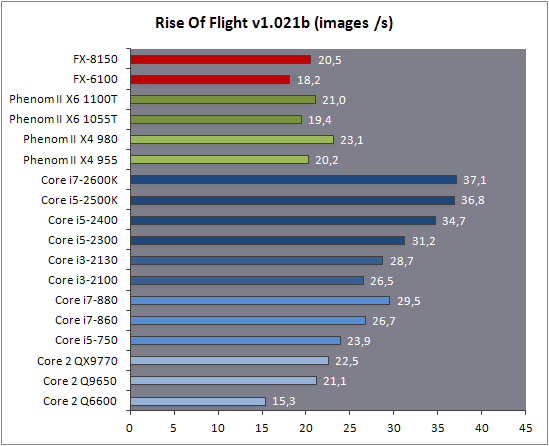 Les FX n'offrent de nouveau pas de gain de performances par rapport à la génération précédente, au contraire. Le Core i3-2100 est cette fois nettement plus rapide alors que les i5 et i7 prennent le large. F1 2011  Le tout nouveau F1 2011 est utilisé en 1920*1080 avec les détails poussés au maximum. Nous mesurons le framerate durant le départ du GP de Monaco. 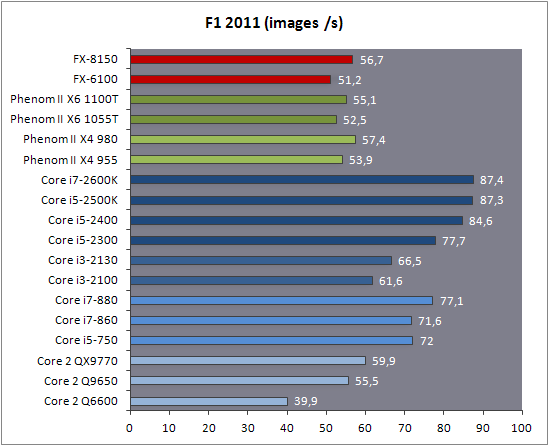 Sans gain significatif par rapport aux Phenom II, les AMD FX ne parviennent pas à accrocher ne serait-ce qu'un Core i3-2100. Page 22 - Jeux 3D : Total War Shogun 2, Starcraft II et Anno 1404 Total War : Shogun 2  Pour Total War : Shogun 2 nous utilisons l'immense bataille du test "DX9 CPU" modifiée pour utiliser DX11 en 1920*1080 avec un niveau de détail élevé. 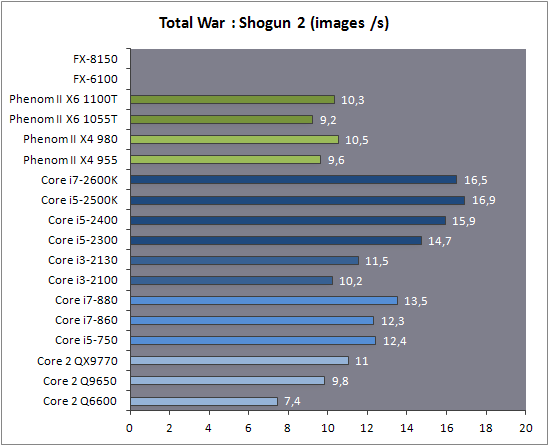 Nous n'avons malheureusement pas de score à vous fournir pour les AMD FX pour ce jeu. En effet, sur ce processeur le jeu plante au démarrage, bug que nous avons remonté à AMD. AMD a pu le reproduire et travaille à un correctif. Il s'agit du seul logiciel nous ayant posé un problème durant ce test, et si nous l'intégrons à titre informatif il ne sera bien entendu pas pris en compte pour la moyenne. Les autres processeurs tirent fortement la langue sous ce test extrême, avec toujours une avance très nette pour les CPUs Intel. Starcraft II v1.3.6  Sous Starcraft II, nous utilisons un replay spécialement enregistré par des utilisateurs du forum que nous remercions. Ce replay contient une attaque très (très) importante et nous mesurons le framerate durant cette dernière en 1920*1080 avec les détails poussés au maximum. 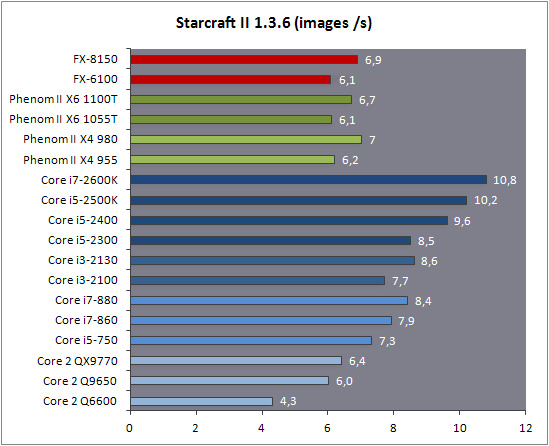 Les machines sont mises à genoux par ce test qui est en pratique encore plus extrême que celui effectué sous Shogun 2. Starcraft II ne tire pas vraiment partie de plus de 2 curs, ce qui explique le faible écart entre i3 et i5. De leur côté les AMD FX sont au niveau des Phenom II et sont dépassés, pour changer, par l'i3-2100. Anno 1404 v1.3  Enfin pour Anno 1404 nous chargeons une sauvegarde d'une cité de 46 600 habitants que nous visualisons depuis une vue éloignée, le tout en 1920*1080 détails poussés au maximum. 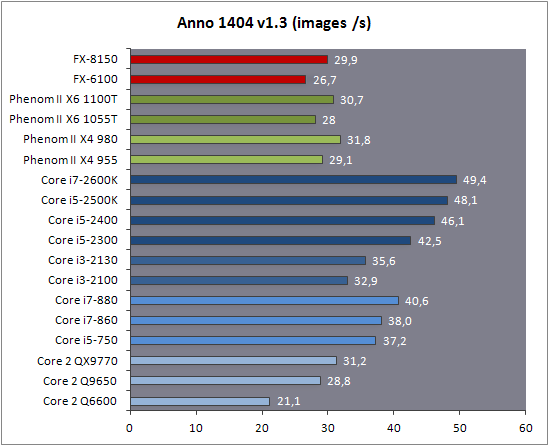 Sans grande surprise, les AMD FX n'apportent pas de gain et sont même en léger retrait par rapport aux Phenom II. L'i3-2100 est devant, les i5/i7 sont d'un niveau tout autre. Page 23 - Moyennes MoyennesBien que les résultats de chaque application aient tous un intérêt, nous avons calculé des indices de performances en se basant sur l'ensemble de résultats et en donnant le même poids à chacun des tests. Pour la première fois, nous intégrons en fait deux moyennes, l'une applicative intègre tous les tests en dehors des jeux 3D et l'autre est spécifique aux jeux 3D. 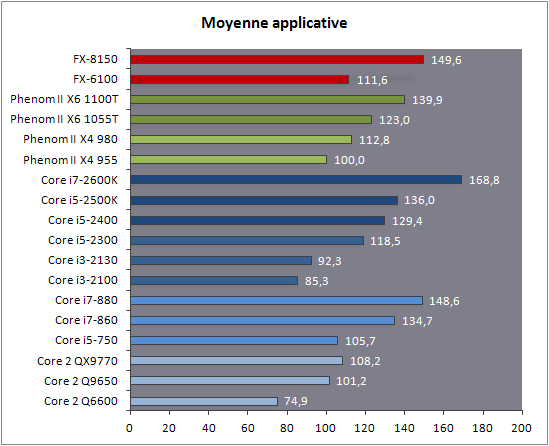 [ Standard ] [ Par performance ] Le FX-8150 est le processeur AMD le plus rapide en moyenne applicative. Le gain de 6.9% est toutefois mesuré par rapport à la débauche de moyens mis en uvre et le FX-8120 qui est au même tarif que le 1100T devrait logiquement être derrière. C'est d'ailleurs le cas du 6100T qui se positionne en retrait par rapport au 1055T malgré des tarifs égaux. Le positionnement par rapport à l'offre Intel est pour sa part correct puisque le FX-8150 est entre les 2500K et 2600K tant en termes de performance que de tarif. 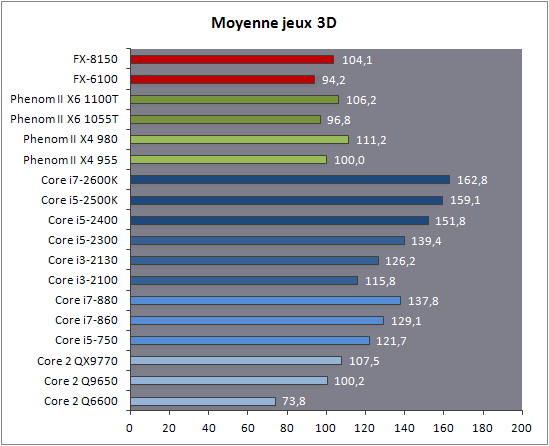 [ Standard ] [ Par performance ] Malheureusement dans les jeux 3D les résultats sont mauvais. Rarement capable d'exploiter de manière intensive plus de 4 curs, les jeux ne sont pas à l'aise sur les AMD FX, le Turbo ne compensant pas la baisse d'IPC. Les performances sont mêmes en léger retrait par rapport aux Phenom II, et un simple Core i3-2100 parvient à faire mieux. AMD reste dans ce domaine au niveau d'un Q9650, soit un niveau proposé par Intel dès la sortie du QX9650 il y a près de 4 ans. Bien entendu nous avons cherché au travers de nos tests des cas où les performances ludiques sont limitées par le CPU et non pas le GPU, ceci malgré l'utilisation du 1920*1080 et de détails élevés. Forcément, si on utilise des scènes moins lourdes côté CPU et/ou on augmente encore les réglages graphiques impactant uniquement le GPU de manière à ne plus permettre d'atteindre les framerates rendus possibles sur les CPU les plus performants (via l'AA ou la résolution) il est possible de resserrer les rangs. Dans le cas ou on serait limité par les performances du GPU, il est même possible que la plate-forme AMD FX repasse légèrement en tête, notamment en SLI / CrossFire X du fait de la gestion en 2x16 contre 2x8 sur LGA 1155. Ce léger avantage ne saurait toutefois pas combler le trou énorme qui sépare ces solutions quand les performances sont limitées par le CPU. Page 24 - Conclusion ConclusionLes nouvelles architectures processeurs sont rares et l'arrivée de Bulldozer était très attendue par tous. Rompant avec la vision traditionnelle des curs, son architecture CMT était en effet prometteuse sur le papier, mais son intégration au sein des AMD FX n'est malheureusement pas au niveau. Certes, nous avons noté que les performances étaient globalement bonnes lorsque les 8 curs étaient pleinement exploités, et AMD a apporté des améliorations importantes à son contrôleur mémoire tout en gonflant le cache, trois points qui laissent penser qu'en version Opteron l'architecture Bulldozer est intéressante.  Mais les AMD FX sont des processeurs desktop et si les performances applicatives sont bonnes, en moyenne le gain est très réduit par rapport aux Phenom II X6. Pire, à tarification égale, ces derniers conservent l'avantage, et le 32nm n'apporte aucun gain en termes d'efficacité énergétique du fait de la débauche de transistors utilisée au sein des AMD FX. Par rapport à l'offre Intel, les AMD FX sont compétitifs en terme de rapport performance / prix en dehors des jeux 3D, d'autant que les cartes mères sont légèrement moins chères, mais les Core i5 et i7 sont très loin devant pour ce qui est de l'efficacité énergétique. On attendait également les AMD FX côté overclocking, surtout avec le buzz fait par AMD pour le record de 8.4 GHz. Malheureusement sur notre processeur de test nous n'avons pu atteindre que les 4.6 GHz stables en doublant une consommation déjà élevée, ce qui n'a rien d'exceptionnel. En fait c'est même décevant au regard de l'orientation "haute fréquence" de l'architecture, cette orientation n'étant pas sans concessions en termes d'IPC : si la fréquence ne suit pas, alors les résultats ne peuvent pas être au niveau. La performance dans les jeux 3D est l'autre gros point noir puisqu'on ne note pas de gain par rapport aux Phenom II X4 et X6 alors que c'était leur principal défaut, si bien qu'un simple Core i3 avec 2 curs et Hyperthreading est légèrement plus rapide ! Bien entendu dans beaucoup de cas, elle sera suffisante pour obtenir une bonne jouabilité, mais qui peut le plus peut le moins et Intel dispose d'une avance plus que confortable dans ce domaine. On tombe ici sur le défaut de l'architecture CMT implémentée dans Bulldozer, puisque si on ne charge que 4 curs on est loin d'utiliser toutes les ressources présentes au sein du processeur : à ce niveau il peut donc être considéré comme un processeur 8 curs, même si ces curs sont individuellement assez faibles et ne permettent pas lorsqu'ils sont combinés de positionner systématiquement le CPU devant d'autres processeurs 4 ou 6 curs. Il n'y a pas 36 solutions pour résoudre ce problème des performances lorsque tous les curs ne sont pas pleinement chargés. Soit il faut attendre que les moteurs de jeux exploitent correctement 8 curs, soit il faut arriver à augmenter la fréquence, soit il faut augmenter les capacités de traitement d'un cur au sein d'un module. Dans le premier cas, AMD n'a pas grand-chose à faire si ce n'est motiver les troupes, mais la route semble encore longue et difficile pour les développeurs. Pour la fréquence le prochain stepping devrait permettre d'aller légèrement plus haut, quant à la capacité de traitement par thread il faudra attendre de voir si c'est une option choisie pour les futures architectures déclinées de Bulldozer qui s'enchaineront assez rapidement, une très bonne chose si AMD tiens sa roadmap : Piledriver en 2012, Steamroller en 2013 et Excavator en 2014. 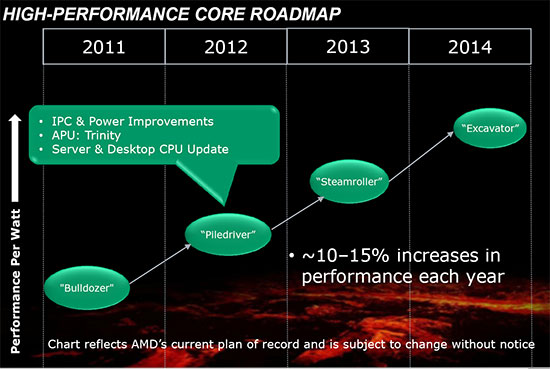 Une autre option plus technique pouvant augmenter les performances sur un thread serait d'avoir une architecture CMT capable de répartir les instructions d'un thread entre les deux curs d'un même module, une sorte d'anti-hyperthreading donc. Intel comme AMD travaillent sur ce genre de projet depuis des années mais à ce jour il s'agit encore de science fiction, l'exercice étant des plus délicats. A moyen terme au moins, il faudra donc compter sur un mix des trois premières pistes, combinées avec des optimisations éventuelles des logiciels de manière à utiliser les instructions supplémentaires supportées par les AMD FX et à coller au mieux à l'architecture. Toutefois après plusieurs retards on attendait clairement plus que des promesses de performances futures, et seuls les aficionados d'AMD y trouveront leur compte. Voilà donc une situation au final dommageable pour tout le monde, la concurrence d'AMD étant essentielle au marché du processeur x86. Pour finir, si malgré tout vous comptez opter pour un AMD FX, notez que pour le moment nous n'avons aucune information concernant la date de disponibilité exacte des CPUs malgré nos demandes répétées à AMD, certaines rumeurs parlant de livraisons début novembre seulement. Vous l'aurez compris, de notre côté nous vous conseillons de passer votre tour mais de garder comme nous un il très intéressé sur eux afin de voir comment ils mûriront. Copyright © 1997-2026 HardWare.fr. Tous droits réservés. |