| |
| |
| OpenCL : le GPU Computing enfin démocratisé ? Cartes Graphiques Publié le Vendredi 12 Décembre 2008 par Damien Triolet URL: /articles/744-1/opencl-gpu-computing-enfin-democratise.html Page 1 - Introduction Près de 6 mois après l'annonce de la création d'un groupe de travail dédié à la mise au point d'OpenCL, celui-ci vient d'être ratifié par le groupe Khronos. Pour rappel, OpenCL (Open Compute Language) est une API dédiée au calcul massivement parallèle dont le développement a été initié par Apple et le groupe Khronos est un consortium d'industriels qui s'occupe du développement d'API ouvertes telles qu'OpenGL.  Comme vous devez maintenant le savoir, les GPUs peuvent être utilisés en tant qu'unités de calcul massivement parallèles, à travers CUDA dans le camp Nvidia et à travers Brook+/CAL dans le camp AMD. Ces APIs propriétaires posent un problème de portabilité puisqu'une application CUDA ne fonctionne pas sur une Radeon et une application Brook+ ne fonctionne pas sur une GeForce. Apple a ainsi proposé OpenCL pour pouvoir exploiter la puissance des GPUs sans être enfermé dans une gamme de produits d'un fabricant particulier (Nvidia). OpenCL peut donc être vu comme une API destinée à standardiser tout cela. La réalité est comme toujours plus complexe, d'où la raison de ce petit article. OpenCL contre CUDA ?C'est la question que beaucoup peuvent se poser puisque CUDA est l'API de type GPU Computing la plus mise en avant à l'heure actuelle, mais OpenCL n'est pas destiné à concurrencer CUDA. Pour comprendre cela il convient de se rappeler de ce qu'est CUDA : une architecture dédiée au calcul massivement parallèle. Nvidia lui a développé une API, « C pour CUDA », une subtilité importante à noter puisque par facilité nous parlons souvent de CUDA autant pour l'architecture que pour son API propriétaire. Les cartes compatibles CUDA (GeForce, Quadro, Tesla) supporteront toutes autant C pour CUDA qu'OpenCL. Il en va de même pour les cartes Stream (Radeon, FireGL, FireStream) qui supporteront autant Brook+ qu'OpenCL. OpenCL se pose donc comme un langage commun à toutes les architectures. Il n'est d'ailleurs pas destiné qu'aux seuls GPUs puisqu'il vise également les CPUs et les accélérateurs tels que le Cell. De quoi permettre de développer un programme compatible avec toutes les architectures ? C'est là que ça se complique. En réalité le groupe de travail en charge d'OpenCL, qui comprend entre autres, Apple, AMD, Intel, Nvidia et Sony, a décidé de favoriser l'utilisation des spécificités de chaque architecture plutôt que la portabilité Page 2 - OpenCUDA OpenCUDAEn parcourant la documentation complète d'OpenCL, il apparaît d'une manière très évidente que la base d'OpenCL est C pour CUDA. Rien ne sert en effet de réinventer une roue qui tourne. D'une manière simplifiée nous pouvons donc dire que le consortium a repris l'API de Nvidia et l'a étendue pour y intégrer tout ce que ses membres désiraient. 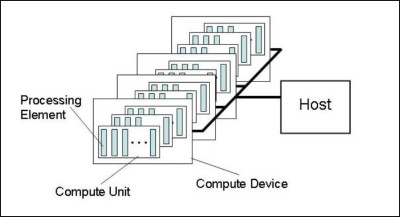 Le fonctionnement de base est exactement le même qu'avec C pour CUDA : un kernel est envoyé à l'accélérateur (Compute device) qui est composé de « compute units » dont les « processing elements » travaillent sur des « work items ». La similitude est complète et il est évident que le groupe Khronos a opté pour des noms différents de ceux de C pour CUDA pour des raisons politiques. Voici ce que donne le traduction si vous êtes familiers avec les termes « CUDA » : Multiprocessor -> Compute unit Processor -> Processing Element Block -> Work-group Thread -> Work-item Texture -> Image object Shared Memory -> Local Memory Si OpenCL reprend le principe de mémoire partagée entre les éléments d'un même groupe de travail il n'en définit cependant pas le comportement. Cette mémoire étant très spécifique, pour l'exploiter d'une manière utile il faudra donc se référer aux documentations des fabricants. Petite différence, alors que C pour CUDA définit une mémoire locale (sur la carte graphique) et globale (dans le système), OpenCL regroupe ces 2 mémoires sous le terme Global memory. OpenCL ne fixe pas réellement de spécifications. Il permet par contre d'obtenir toutes les spécifications de l'accélérateur qui va être utilisé Le développeur devra se baser sur celles-ci et s'assurer de la compatibilité entre son code et l'accélérateur car dans certains cas le code sera purement incompatible avec certains accélérateurs puisque, par exemple, l'endianness est libre. Nous pouvons également imaginer un code auto-adaptatif suivant les spécifications de l'accélérateur, mais en dehors de quelques cas simples cela devrait à priori rester un exercice de style. Les différences principalesOpenCL est une API légèrement de plus bas niveau que C pour CUDA. Pour être précis, il est utile de rappeler que C pour CUDA peut être exploité en mode runtime, classique, ou driver, un peu plus complexe. C'est grossièrement à cette dernière version que correspond OpenCL qui impose donc au développeur de gérer manuellement la mémoire alors qu'en version runtime de C pour CUDA tout cela est transparent. Ensuite OpenCL, tout comme le langage Ct d'Intel, supporte 2 modèles de parallélisme : au niveau des données et au niveau des tâches. Le parallélisme au niveau des données est celui utilisé par les GPUs (même si Nvidia parle de threads il s'agit en fait d'un programme identique exécuté sur différentes données) alors que le parallélisme des tâches correspond à ce qui se passe dans une unité SSE par exemple. Ce second modèle est moins efficace sur un GPU. OpenCL supporte des extensions, comme OpenGL, qui peuvent être propriétaires et permet même d'inclure dans un programme des kernels natifs qui sont des bouts de code destinés à tourner sur l'accélérateur sans être écrits et compilés via OpenCL. Chaque fabriquant peut donc faire ce qu'il veut à ce niveau. L'utilisation d'une API propriétaire ou d'un kernel natif empêchera directement le code de tourner sur un matériel différent. Enfin, OpenCL supporte un mode « ES » avec un minimum requis revu à la baisse, notamment sur le respect des standards en terme de précision de calcul, destiné aux périphériques mobiles. Page 3 - Nvidia et OpenCL Nvidia et OpenCLLa semaine passée, nous nous sommes entretenus avec le responsable de CUDA de manière à faire le point sur OpenCL que la compagnie supporte fermement. Certains pourraient être tentés de penser qu'OpenCL est un concurrent de C pour CUDA et que dans ce contexte Nvidia n'est pas très emballé par l'arrivée du premier. Bien entendu pour Nvidia l'utilisation de C pour CUDA est idéale puisque cela impose l'achat de ses produits alors qu'avec OpenCL d'autres produits peuvent être utilisés. C'est cependant une vision des choses beaucoup trop simpliste. Le marché concerné en est encore à ses débuts et plutôt que se battre pour protéger quelques miettes il est bien plus utile de préparer un gros gâteau. Dans ce contexte, toute initiative destinée à développer l'utilisation de la puissance de calcul des puces massivement parallèles telles que les GPUs est bonne à prendre. C'est d'ailleurs Neil Trevett, un ancien de 3D Labs et l'actuel Vice President of Embedded Content de Nvidia qui préside le groupe de travail OpenCL. Etant donné les similitudes entre C pour CUDA et OpenCL et le fait que, officiellement, ce soit Apple qui en ait eu l'idée et l'ait proposé (après avoir décidé d'équiper ses nouveaux Mac en produits Nvidia ) il est probable que Nvidia en soit en réalité au moins le co-instigateur. 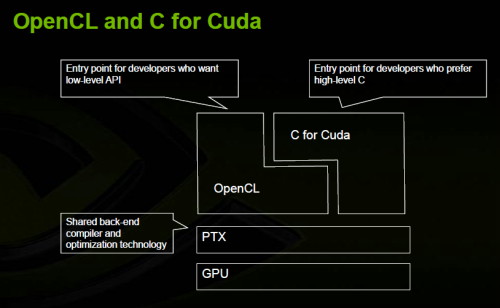 Nvidia enfonce le clou en précisant qu'OpenCL a été développé sur ses GPUs et que la compagnie a été la première à en faire la démonstration. La similitude entre CUDA et OpenCL facilite ici la tâche à Nvidia puisqu'il lui suffit de mettre en place un pilote qui supporte l'API et de modifier légèrement son compilateur C pour CUDA de manière à en créer une version OpenCL. Ces 2 compilateurs utiliseront le même langage intermédiaire, le PTX de CUDA, qui est utilisé pour optimiser et créer le code machine exécuté par le GPU. De son coté AMD devra vraisemblablement mettre en place un compilateur OpenCL vers CAL, ce qui demandera un peu plus de travail. 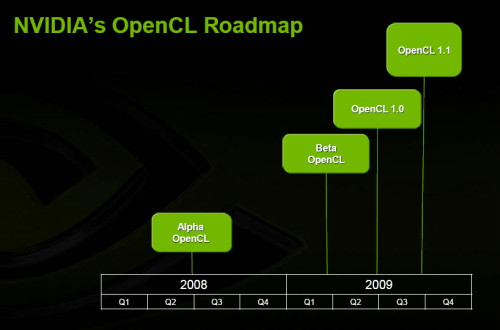 Nvidia prévoit de rendre disponible un pilote OpenCL beta au printemps et un pilote final pendant l'été 2009 avec une version 1.1 qui devrait suivre rapidement. Celle-ci devrait à priori être utilisée pour corriger les lacunes d'OpenCL mise en avant par les premiers utilisateurs de l'API. AMD a de son côté annoncé un pilote OpenCL pour le premier semestre 2009. 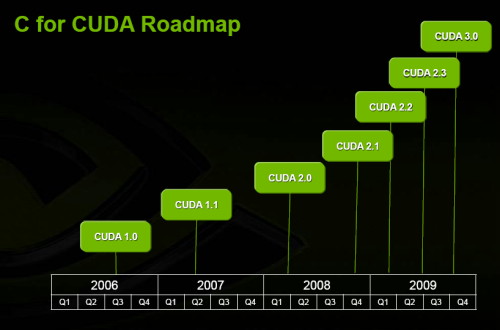 Bien entendu, l'arrivée d'OpenCL ne signe pas l'arrêt du développement de C pour CUDA qui reste très important pour Nvidia. Etant une API propriétaire elle permet au fabricant de bouger plus vite par rapport à ses propres GPUs et de développer de nouvelles fonctions sans dévoiler à la concurrence des détails architecturaux sur ses prochaines puces. 2 révisions « mineures » sont prévues pour la première moitié de 2009 avec le passage à la version 3.0 dans 1 an. Page 4 - Portabilité : oui mais Portabilité : oui maisUne API qui supporte une large gamme de périphériques simplifie de par sa nature la portabilité entre ceux-ci. Néanmoins, développer un code OpenCL compatible avec plusieurs accélérateurs sera complexe. Il faudra écrire un code différent pour chaque matériel supporté, puisque l'implémentation efficace d'un algorithme peut être très différente d'une architecture à l'autre, bien plus qu'en 3D. Ou alors il faudra se contenter d'un code moins optimisé mais basé sur les points communs des différentes architectures, ce qui peut être envisagé dans le cas de GPUs différents mais pas dans le cas d'un GPU et du Cell par exemple.  Dans le domaine professionnel, nous pouvons estimer que c'est la première solution qui primera et qu'en fin de compte un code OpenCL pour cartes Tesla ne sera pas vraiment plus compatible avec les cartes FireStream qu'un code C pour CUDA même si le développeur se sentira moins tributaire d'un fabricant donné. Plus le code sera optimisé moins il sera portable et dans le secteur HPC les algorithmes sont bien entendu optimisés autant que possible. Dans le domaine grand public il est difficile de savoir ce qui va se passer. A ce niveau il est très décevant qu'OpenCL n'encadre pas les spécifications et ne standardise rien du tout. S'il est bien entendu plus simple d'utiliser OpenCL pour les GeForce et les Radeon que C pour CUDA d'un côté et Brook+ de l'autre, le travail reste fastidieux. OpenCL souffre d'ailleurs ici du même problème qu'OpenGL, mais nettement amplifié, et il faudra probablement attendre DirectX 11 pour que l'utilisation des GPUs en tant que coprocesseurs massivement parallèles puisse être simplifiée du côté grande public. A moins que les développeurs ne décident d'exploiter OpenCL en ayant en tête la base commune définie par DirectX 11, de manière à fixer de « bonnes pratiques » pour la portabilité entre GeForce et Radeon. Nvidia et AMD pourraient alors avoir en tête ces « bonnes pratiques » lors du développement de leurs futurs GPUs. Mais tout cela n'est que suppositions. Avec OpenCL, le groupe Khronos a une nouvelle fois mis au point une API qui ouvre de nombreuses portes, mais sans rien imposer, ce qui a autant d'avantages que d'inconvénients. S'il est indéniable que l'univers grandissant du calcul massivement parallèle se voit ainsi doté d'un nouvel outil aux usages multiples, ce n'est malheureusement pas le messie tant attendu qui du jour au lendemain va permettre aux développeurs d'utiliser facilement et d'une manière standardisée, tout le potentiel de puissance de calcul des machines modernes. Copyright © 1997-2026 HardWare.fr. Tous droits réservés. |