| |
| |
| Nvidia CUDA : l'heure de la concrétisation ? Cartes Graphiques Publié le Samedi 26 Juillet 2008 par Damien Triolet URL: /articles/728-1/nvidia-cuda-heure-concretisation.html Page 1 - Introduction  Notre dernier article consacré à CUDA a été réalisé il y a plus ou moins 1 an. En 12 mois, CUDA a poursuivi son évolution, la stratégie de Nvidia à son sujet a été légèrement revue et de nouveaux produits dédiés ont été dévoilés. Le mois passé, Nvidia nous a invités pour faire le point sur tout cela dans ses quartiers généraux à Santa Clara, l'occasion également d'y rencontrer quelques développeurs qui ont décidé d'utiliser CUDA et qui nous ont donc pu nous faire part de leur expérience. Notre dernier article consacré à CUDA a été réalisé il y a plus ou moins 1 an. En 12 mois, CUDA a poursuivi son évolution, la stratégie de Nvidia à son sujet a été légèrement revue et de nouveaux produits dédiés ont été dévoilés. Le mois passé, Nvidia nous a invités pour faire le point sur tout cela dans ses quartiers généraux à Santa Clara, l'occasion également d'y rencontrer quelques développeurs qui ont décidé d'utiliser CUDA et qui nous ont donc pu nous faire part de leur expérience.CUDAPour rappel, avec l'arrivée des GeForce 8, Nvidia a entamé le développement de CUDA, une interface et un langage de programmation dérivés du C qui permettent d'exploiter le cur de calcul des GPUs pour le traitement de toute tâche massivement parallèle. Un point qu'il est toujours utile de préciser puisque, contrairement à un CPU, un GPU n'est pas adapté au traitement très rapide des tâches qui s'exécutent en série. Pour exploiter les nombreuses unités de calcul du GPU, il faut donc lui fournir un travail adapté.  Le GPU n'est ainsi pas amené à remplacer le CPU, mais plutôt à prendre le relais pour certaines tâches, autrement dit, à agir comme un coprocesseur, partenaire du CPU. Nvidia insiste d'ailleurs de plus en plus sur ce point pour éviter toute confusion et bien entendu toute comparaison maladroite puisque autant il est possible de mettre fortement en avant le GPU avec une tâche adaptée, autant il est possible de le montrer sous le plus mauvais jour qui soit avec une tâche qui ne se parallélise pas. TeslaL'an passé, Nvidia a fait un pas de plus en dévoilant une gamme de produit spécifique au marché de la puissance de calcul : Tesla. Les produits Tesla, reposent sur l'architecture graphique haut de gamme du moment, mais sont dépourvus de sorties vidéos et étaient équipés de plus de mémoire : 1.5 Go pour chaque GPU Tesla basé sur le G80 (contre 768 Mo pour les GeForce 8800 GTX). Nvidia avait alors dévoilé 3 variantes : simple carte, double carte dans un boîtier externe et quadruple carte dans un rack 1U. Ces produits ne se sont probablement pas très bien vendus à l'exception de quelques pièces. Il s'agissait avant tout de tester le marché et de mettre à disposition des prototypes de développement.  Pour différencier ces cartes Tesla des GeForce et justifier leur prix plus élevé, Nvidia avait alors indiqué réserver certaines fonctionnalités de CUDA à la gamme Tesla. Retournement de situation puisque le mois passé Nvidia nous a avoué avoir changé de stratégie de manière à privilégier une implantation de CUDA la plus large possible quitte à ce que certains optent pour une GeForce "bon marché" plutôt que pour une carte Tesla. Page 2 - GT200 1/2 GT200L'arrivée de son nouveau GPU, le GT200, est importante pour Nvidia pour tout ce qui concerne le GPU Computing, en témoigne le lancement simultané des GeForce GTX 200 et des Tesla 2. Le GT200 présente une évolution de l'architecture des puces G8x et G9x. Evolution dont le rendement est discutable du côté grand public puisque les GeForce GTX 200 se sont fait surprendre par les Radeon HD 4800, plus efficaces. Si la GeForce GTX 280 conserve une courte tête d'avance, cela se fait au prix d'un GPU énorme de pas moins de 1.4 milliards de transistors, soit le double d'une puce telle que le G80 des GeForce 8800 GTX.  Le die énorme du GT200. Dès lors il est légitime de se poser la question de savoir si Nvidia n'aurait pas privilégié le côté GPU Computing plus que le côté rendu 3D. De notre côté nous ne pensons pas que ce soit le cas. Le développement d'un tel GPU se prépare longtemps à l'avance, et à ce moment il aurait été étonnant de voir Nvidia parier sur un marché qui n'existait pas encore au détriment de son business principal. Nous estimons donc que les choix principaux de l'architecture du GT200 ont été faits par rapport à ce que Nvidia pensait être la meilleure solution pour le marché de la carte graphique haut de gamme. Des choix qui ont cependant été faits en sous-estimant, probablement avec un petit peu d'arrogance, la capacité de la concurrence à être compétitifs. Ceci étant dit, Nvidia a bel et bien introduit quelques petites touches spécifiques au GPU Computing dans ce GT200 et bien que les choix principaux aient été opérés en priorité par rapport au rendu 3D, cela ne les rends pas inintéressants pour d'autres domaines, bien au contraire ! Plus d'unités de calculLa principale amélioration provient de l'augmentation des unités de calcul ou processeurs qui travaillent chacun sur des threads différents. Ces processeurs sont organisés par groupes de 8, appelés multiprocesseurs, et exécutent des suites d'instructions (kernels) sur des groupes de 32 threads, appelés warps, en 4 cycles. Alors que le G80 et le G92 reposaient sur 16 multiprocesseurs, le GT200 en embarque pas moins de 30. La puissance de calcul fait donc un gros bond en avant, tout du moins à fréquence égale puisque si le GT200 fonctionne à une fréquence proche de celle du G80 à son introduction, il faut rappeler que le G92 peut, lui, monter beaucoup plus haut, près de 50% plus haut. 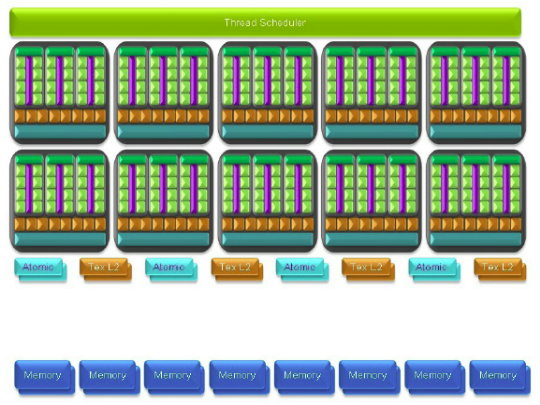 En mode rendu 3D, un détail important concerne l'organisation de ces multiprocesseurs puisqu'ils sont 3 à partager une unité de texturing contre seulement 2 auparavant. Le débit relatif d'accès aux textures est donc revu à la baisse, mais ce n'est pas très important en GPU Computing. Plus de registresUn changement important apporté à l'architecture est le doublement des registres généraux qui n'apporte pas de gros avantages dans les jeux actuels qui ont été optimisés pour tenir dans les limites des GPUs les plus répandus. Par contre cela peut faire une énorme différence en GPU Computing. Chaque multiprocesseur dispose d'un espace de registres qui lui est propre. Ces registres doivent accueillir un certain nombre de threads. Plus le nombre de threads en vol dans chaque multiprocesseur est élevé, mieux le GPU peut masquer les différentes latence et maximiser son débit. Il en faut d'ailleurs au minimum 192 pour masquer complètement la latence des unités de calcul et bien entendu beaucoup plus pour masquer la latence de plus de 400 cycles des accès à la mémoire globale (mémoire vidéo). Cependant, tous ces threads doivent se partager les registres généraux. Dans le cas du GT200 ils sont de 16384 contre 8192 auparavant. Cet espace registre plus grand permet au GT200 d'accueillir plus de threads par multiprocesseur pour mieux masquer les latences ou permet d'utiliser plus de registres pour obtenir un code plus efficace. L'intérêt principal est également ailleurs : avec une pression réduite sur les registres, les développeurs auront moins besoin d'essayer d'optimiser en détail leur code pour obtenir des performances élevées. Page 3 - GT200 2/2 Contrôleur mémoire plus efficaceLes puces de type G8x et G9x accèdent à la mémoire par morceaux de 64 (pour des données de 32 bits) ou 128 octets (pour des données de 64 ou 128 bits) et ce d'une manière très rigide. Il est évident que pour remplir un accès mémoire de 64 ou 128 octets, il faut que plusieurs threads y participent. En mode GPU Computing, les accès à la mémoire globale de 16 threads (soit un demi warps) peuvent ainsi être combinés. Si 16 threads ont besoin d'une donnée de 32 bits, cela remplit un accès mémoire de 64 octets. Cependant pour que cela soit possible il faut obligatoirement que les 16 threads accèdent d'une manière séquentielle, contiguë et alignée à des données contenues dans un bloc mémoire de 64 octets. Si ce n'est pas le cas, un accès mémoire par thread doit être exécuté, ce qui allonge nettement la latence (puisque les threads sont exécutés en même temps il faut attendre que tous les threads aient récupéré leur donnée avant de continuer leur traitement) et gaspille beaucoup de bande passante mémoire (puisqu'un bloc de 64 octets est rapatrié pour n'en utiliser que 32 bits). Le contrôleur mémoire du GT200 a été revu de manière à gagner en efficacité, en plus d'avoir été étendu à 512 bits. Tout d'abord en plus des accès mémoire à des blocs de 64 et 128 octets, il peut se contenter de 32 octets. Il est capable de combiner des accès non-séquentiels effectués à l'intérieur d'un même bloc mémoire, de combiner des accès non alignés ou non contigus dans le bloc mémoire de taille supérieure (par exemple 1 accès de 128 octets pour 64 octets de données au lieu de 16 accès de 64 octets précédemment) et de réduire la taille des accès mémoire autant que possible quand plusieurs sont nécessaires. Les gains d'efficacité seront donc conséquents dans ces situations. 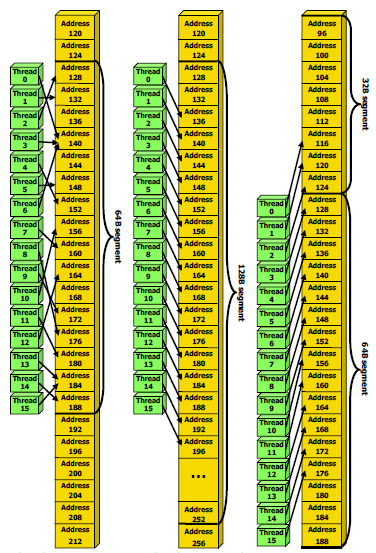 3 exemples d'accès mémoire qui profitent grandement au GT200. Le premier est réalisé avec un seul accès de 64 octets, le second avec un seul de 128 octets et le dernier avec un accès de 64 octets et un de 32 octets. Ces 3 exemples ont besoin de 16 accès de 64 octets sur un GPU antérieur au GT200 ! En détail qui nous était passé inaperçu est que les puces G9x ont introduit une communication plus efficace entre le CPU et le GPU puisqu'il est devenu possible d'envoyer des données au GPU ou à celui-ci d'en envoyer pendant que son cur d'exécution est au travail. Sur une puce G80 ce n'est pas possible et le GPU ne peut pas exécuter de kernel pendant les transferts de données vers ou depuis la mémoire centrale. Le GT200 reprend bien entendu cette capacité. Notez que Nvidia nous a indiqué que la génération suivant qui arrivera l'an prochain, sera capable de recevoir des données et d'en envoyer tout en exécutant un kernel. Support des doublesLa nouveauté qui a été le plus mise en avant avec le GT200 dans le domaine du GPU Computing est sans aucun doute le support des doubles soit du calcul en 64 bits sur les flottants. Ce support a été introduit via l'ajout d'une unité dédiée dans chaque multiprocesseur. 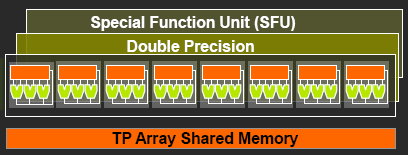 Pour être précis nous devons rappeler que chaque multiprocesseur contient 8 processeurs FMAD principaux + 8 processeurs MUL partagés avec les unités en charge des fonctions spéciales (sin, cos, exp etc.). Un processeur FMAD 64 bits vient s'y ajouter. La puissance de calcul en 64 bits est donc nettement moindre, 8x plus faible dans le cas d'instructions FMAD, 16x plus faible dans le cas d'instructions FMUL. Ce support du 64 bits reste cependant intéressant à plus d'un titre, puisqu'il peut ne concerner qu'un morceau du code ou être utilisé pour développer des applications qui seront utilisées sur les futures générations de GPUs qui recevront plus qu'un processeur 64 bits par multiprocesseur ou mieux, verront tous leurs processeurs évoluer de 32 à 64 bits. Chaque multiprocesseur étant dual issue, il peut traiter 2 instructions non dépendantes en même temps et ainsi débiter par cycle : 8 FMAD 32 bits + 8 FMUL 32 bits 8 FMAD 32 bits + 2 fonctions spéciales 32 bits 8 FMAD 32 bits + 1 FMAD 64 bits 1 FMAD 64 bits + 2 fonctions spéciales 32 bits Ces 2 dernières combinaisons ne sont cependant pas exploitables à l'heure actuelle et Nvidia évalue toujours l'intérêt de leur implémentation dans le compilateur. Concernant les avantages de l'implémentation du FP64 de Nvidia, nous noterons la gestion à pleine vitesse des nombres dénormalisés. Par contres les flags ne sont pas du tout supportés. 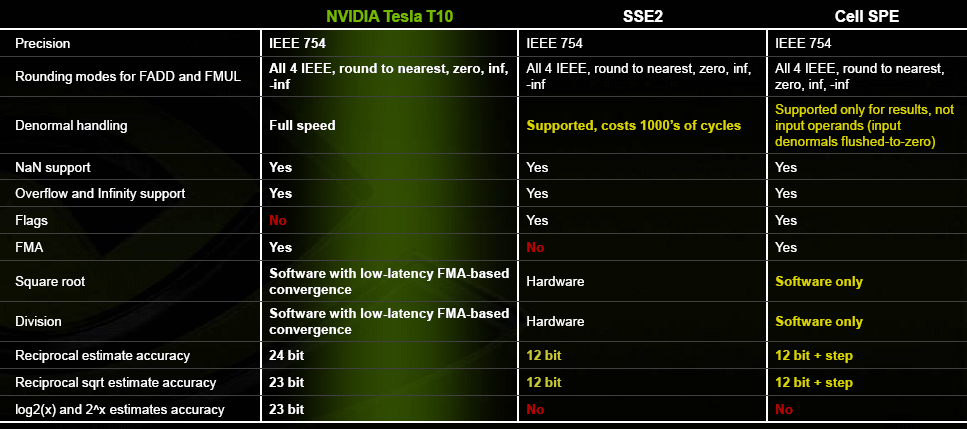 Page 4 - CUDA 2.0 CUDA 2.0CUDA est un environnement de développement mis au point par Nvidia qui consiste en quelques extensions au langage C, des librairies, un compilateur et un pilote. CUDA demande au développeur d'organiser la masse de travail à exécuter par le GPU en un assemblage de blocs de threads. Chaque bloc peut contenir jusqu'à 512 threads. Plusieurs blocs peuvent être actifs en même temps dans un même multiprocesseur. 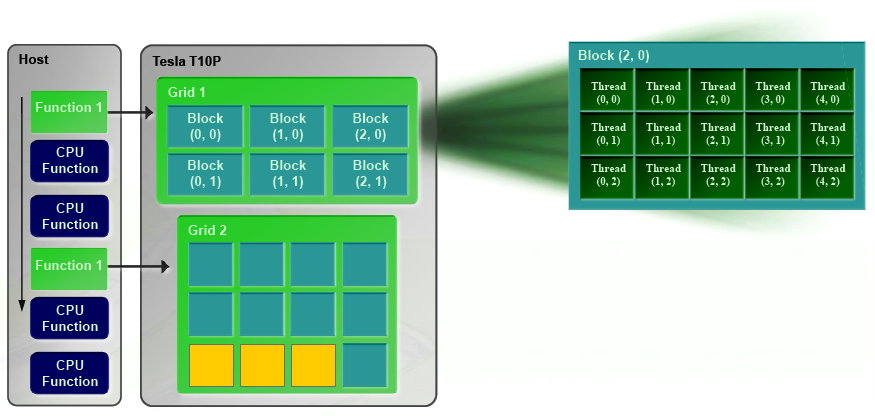 Chaque thread peut communiquer avec les autres threads d'un même bloc à travers une mémoire locale de 16 Ko appelée shared memory. Celle-ci est organisée en 16 banques et les accès qui y sont faits sont soumis à plusieurs contraintes pour être effectués à pleine vitesse. Malgré tout elle permet d'éviter de repasser par la mémoire globale pour passer des données d'un thread à l'autre et est donc un élément important de CUDA. 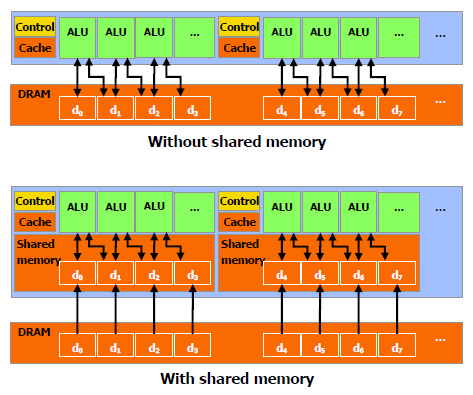 C'est souvent autour de cet élément que les développeurs devront organiser les threads. Plus il y en a en vol, plus ils sont nombreux à pouvoir communiquer entre eux, mais de plus petites données. Si de petits blocs sont utilisés à plusieurs pour remplir un multiprocesseur, la shared memory accessible à chacun est alors réduite. Il faudra donc souvent expérimenter diverses organisations de threads pour savoir laquelle est la plus efficace, d'autant plus quand la shared memory est utilisée. Un point sensible que Nvidia n'a d'ailleurs pas voulu modifier avec de plus récents GPUs puisque tous utilisent une même mémoire de 16 Ko. Parallèlement à l'arrivée du GT200, CUDA 2.0 montre le bout de son nez. Actuellement en version beta, cette nouvelle mouture de l'environnement de développement apporte plusieurs avancées. Premièrement, elle supporte bien entendu les fonctionnalités nouvelles apportées par le GT200, à savoir plus de registres, les doubles etc. Voici un résumé des différentes révisions hardware spécifiques à CUDA affichées par les GPU compatibles : 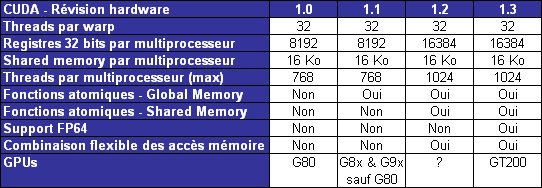 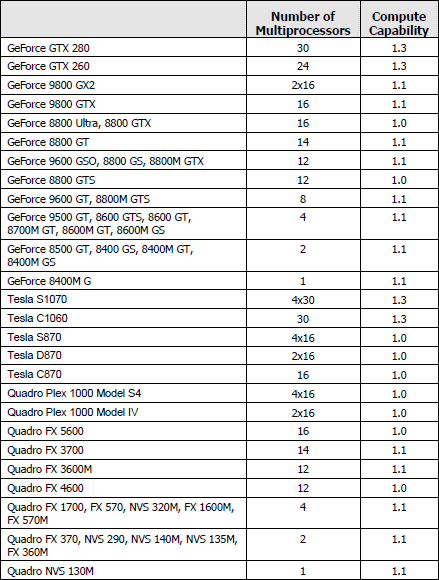 Comme vous pouvez le constater, il n'existe à ce jour aucun GPU et aucune carte graphique de révision 1.2. Cela peut s'expliquer par 2 raisons : premièrement, au départ, Nvidia avait envisagé de limiter le support du FP64 aux produits Tesla et Quadro haut de gamme, du coup une GeForce GTX 200 serait retombée dans la révision 1.2 au lieu de la 1.3. Ce revirement de situation est dû au changement de stratégie qui a été opéré et qui consiste à privilégier l'utilisation de CUDA plutôt que la vente des produits Tesla. Une stratégie qui pourrait se révéler plus intéressante à long terme pour Nvidia. CUDA et le x86 multicoreC'est selon nous l'information la plus intéressante dévoilée par Nvidia : l'ajout dans le compilateur CUDA d'un profil optimisé pour les CPUs x86 multicores ! Actuellement, le code CUDA est séparé en 2 parties : une partie traitée par le CPU et redirigée vers un compilateur classique (du choix du développeur) et une autre partie spécifique au GPU, dont s'occupe le compilateur CUDA. La nouveauté est qu'il sera dorénavant possible de compiler cette partie spécifique au GPU pour le CPU, de manière à ce que la totalité du code CUDA tourne sur ce dernier. L'exploitation automatique du multicore sera réalisée via, grossièrement, la transformation d'un bloc de threads GPU en un thread CPU. 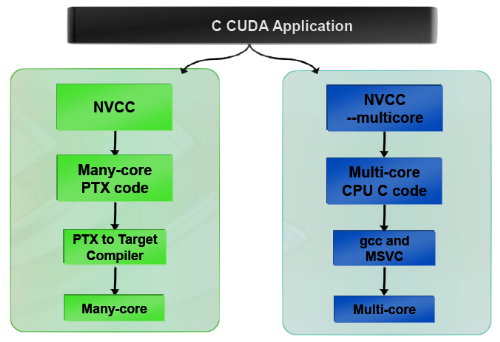 Une nouvelle version beta de CUDA 2.0 qui supporte cette possibilité sera rendue publique sous peu. Actuellement, nous ne savons pas quel sera le niveau d'efficacité réel de la compilation pour le CPU. Il sera intéressant de vérifier ce point quand le tout sera mûr. Ce nouveau positionnement est dû à plusieurs raisons. La volonté de Nvidia, encore une fois, d'essayer de rendre l'utilisation de CUDA aussi répandue que possible, quitte à ce qu'il soit utilisé en partie sur un CPU plutôt que sur un GPU. Ensuite Nvidia répond à une demande des utilisateurs actuels ou potentiels de CUDA qui désirent des garanties avant de se lancer dans l'aventure. Développer un code spécifique à un GPU est plus risqué qu'un développer un compatible avec le GPU et avec le CPU. S'il arrivait un problème aux GPUs dans le futur il serait ainsi possible de passer facilement sur un CPU, quitte à ce que ce soit plus lent. Bien entendu la question qui vient immédiatement à l'esprit est CUDA sur Larrabee ? Pour rappel, Larrabee sera un processeur Intel équipé de 32 cores et dédié à l'accélération des problèmes massivement parallèles. Bref un concurrent direct du GPU mais qui sera x86. CUDA sur Larrabee sera donc sauf surprise possible. Il sera là aussi intéressant d'observer les performances ! Page 5 - Tesla Série 10 Tesla Série 10Nvidia a dévoilé le mois passé 2 nouveaux produits Tesla qui reposent sur le GT200. Comme nous vous l'avons indiqué, Nvidia a changé d'avis et décidé d'activer toutes les fonctionnalités liées à CUDA sur tous ses GPUs qui les supportent, qu'ils soient Tesla, Quadro ou GeForce. Du coup, les cartes Tesla n'ont pas de fonctionnalités hardware spécifiques, ni de logiciel spécifique puisque les pilotes sont similaires à ceux des GeForce, contrairement aux Quadro. Du coup quel intérêt peuvent bien avoir des produits Tesla par rapport aux GeForce ? D'autant plus qu'ils sont dépourvus de sorties vidéos et ont donc besoin qu'une carte graphique soit dans le PC. Il y en a 2. Le premier, des normes de validations plus poussées. Il ne justifie cependant pas réellement une gamme différente. Nvidia en introduit un second avec cette seconde génération Tesla. La première disposait déjà de 1.5 Go de mémoire par GPU, contre 768 Mo pour une GeForce 8800 GTX. Un avantage certes mais peut-être pas assez significatif. Du coup, cette fois, Nvidia place pas moins de 4 Go de mémoire sur tous les produits Tesla Série 10 ! Une différence significative par rapport aux produits grand public, tels que les GeForce GTX 280 équipées de 1 Go, et qui n'est pas sans intérêt dans ce domaine où les datasets à traiter peuvent être énormes. Nvidia communique ainsi cet exemple, pour lequel ils ont limité la mémoire adressable d'une carte Tesla Série 10 à 1.5 Go au lieu de 4 Go. Le gain en efficacité pour certaines tâches est ainsi plus que conséquent : 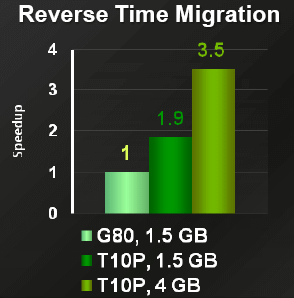 Dans un premier temps, Nvidia lance 2 produits Tesla Série 10 : une carte simple et un rack 1U équipé de 4 de ces cartes. La version "Quadro Plex" équipée de 2 cartes n'est pas renouvelée. Contrairement aux Tesla Série 8, la Série 10 reçoit un PCB spécifique, ce qui était rendu obligatoire pour le support de 4 Go de mémoire puisqu'il faut utiliser 32 puces alors que le PCB de la version grand public du GT200 ne peut en accueillir que 16. Nvidia utilise par ailleurs des puces d'une densité double. Du coup, la fréquence de la mémoire est revue un petit peu à la baisse puisqu'il s'agit de DDR3 à 800 MHz qui offre donc une bande passante de 95.4 Go/s au GPU.  Nvidia en a profité pour apporter quelques petites modifications, notamment au niveau du système d'alimentation. Ainsi les cartes Tesla Série 10 se contentent de 2 connecteurs d'alimentation PCI Express 6 broches, l'utilisation du 8 broches étant optionnelle, contrairement à la GeForce GTX 280. Cela est dû au fait que la TDP est revue un petit à la baisse en mode GPU Computing puisque certaines unités liées au rendu 3D n'ont pas à être utilisées.  Le système de refroidissement de la carte Tesla C1060 est similaire à celui des GeForce GTX 200, mais d'une fabrication plus robuste, tout du moins c'est l'impression que donne l'aspect mat de la carte. Les 240 unités de calcul de son GT200 sont cadencées à 1.33 GHz, soit légèrement plus que la GeForce GTX 280 pour laquelle il s'agit de 1296 MHz. Sa puissance de calcul atteint donc 960 Gflops si l'on compte l'exploitation des processeurs MUL en dual issue avec les processeurs MAD. La consommation type annoncée est de 160W. Attention, un des 2 connecteurs est situé à l'arrière de la carte et non sur le dessus, la carte rentrera donc plus difficilement dans certains boîtiers qu'une GeForce GTX 200.  Le rack 1U Tesla S1070 est de conception similaire à la version précédente. Il embarque 4 PCB de Tesla Série 10 surmonté par un gros radiateur, une lignée de ventilateurs étant chargés de créer un flux d'air à travers le rack suffisant pour refroidir le tout. D'une manière visiblement efficace puisque sur ce produit Nvidia pousse la fréquence des 960 unités de calcul combinées des 4 GT200 à 1.5 GHz, de manière à atteindre 1.08 Tflops par GPU au 4.32 Tflops pour le rack ! Chaque GPU est bien entendu accompagné de 4 Go de mémoire, soit 16 Go au total. La consommation typique annoncée est de 700W. Ce rack doit être piloté par un serveur CPU via 2 connexions PCI Express 2.0 externes.  Page 6 - Exemples variés Exemples variésL'utilisation des GPUs comme processeur de calcul, à travers CUDA, concerne de nombreux domaines qui vont de la simulation de la cuisson des pizzas au four à micro-onde (pour arriver à obtenir le même résultat qu'au four traditionnel), à la recherche de remèdes face à certains virus ou cancers, en passant par l'analyse financière et la recherche du pétrole. L'utilité et l'efficacité des GPUs pour ces tâches n'est plus à démontrer, cela a déjà été fait. Nous somme plutôt dans une phase de validation dans laquelle les solutions développées sont testées sur de petites parts de l'analyse ou de la simulation, de manière à limiter les risques. Comme vous pouvez vous en douter, l'industrie est en général frileuse à l'idée de passer d'une technologie à l'autre. C'est donc pas à pas qu'elle se tourne vers une solution telle que CUDA, une fois que son utilité à été démontrée. Parfois cette évolution pas à pas se fait également parce qu'il n'est pas facile de convertir d'un coup tout le code lié à une activité. Soit à cause du temps que cela prend de le porter, de l'optimiser et de la valider, soit parce que tout le code n'est pas naturellement parallélisable. Par exemple, le National Center for Atmospheric Research aux Etats-Unis a porté 1% de son code de recherche et prévision météorologique sous CUDA et obtenu un gain de 20% sur la totalité de l'application, ce qui est déjà très significatif.  Correction optiqueUn autre exemple qui revêt un intérêt particulier est la simulation optique qui est particulièrement intéressant pour Nvidia. Elle est utilisée pour appliquer une correction optique sur les masques de fabrications des puces. Avec les technologies actuelles il n'est plus possible de "simplement" dessiner sur le masque les structures désirées et de les obtenir en sortie. Les déformations sont devenues trop importantes à cause de différents phénomènes optiques. Du coup la technique consiste à produire un masque déformé en prenant en compte tout cela de manière à ce que l'image finale corresponde aux structures voulues pour les transistors. Calculer la déformation, ou correction, du masque et ensuite vérifier qu'elle corresponde bien à la structure voulue, représente une masse de calculs énorme. Il faut en général d'énormes clusters de milliers de CPUs pour le calculer dans un délai acceptable de plusieurs jours. Avec une dizaine de GPUs assistant quelques CPUs, il ne faut plus que quelques heures. GAUDA a développé une telle solution, compatible autant avec les GPUs Nvidia qu'AMD. 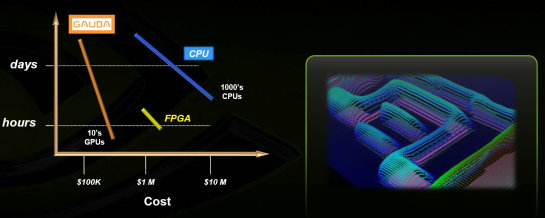 Utiliser le GPU a également l'avantage de réduire fortement le coût comme vous vous en doutez. C'est d'autant plus vrai par rapport à un module FPGA dont le développement représente un investissement énorme. Simulation des marchésLe monde de la finance s'est lui aussi rapidement intéressé au potentiel du GPU. Des simulations financières complexes sont maintenant utilisées pour limiter les risques et pouvoir les traiter rapidement est bien entendu un must dans un monde qui bouge vite. Toute perte de temps peut faire rater un deal intéressant. Modéliser les variations des marchés etc. est très complexe et fait appel à des quants, des mathématiciens de haut niveau. Ceux-ci ne courent pas les rues et sont payés très chers, du coup leur temps de travail doit être rentabilisé au maximum. S'ils passent la majeure partie de leur temps à coder le modèle qu'ils ont définis, ce n'est pas très intéressant. 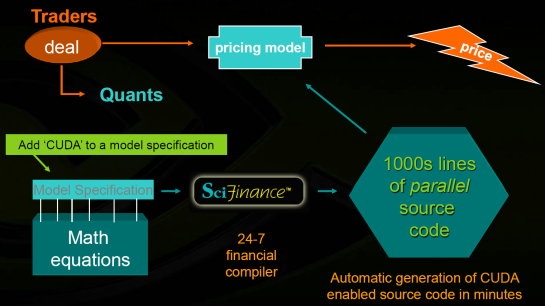 SciFiance, par exemple, propose un logiciel qui sur base d'équations écrites dans un langage de haut niveau va fournir automatiquement un code C ou C++ prêt à être exploité. Ce logiciel supporte maintenant CUDA de la même manière et permet donc de sortir un code destiné à réaliser les simulations beaucoup plus rapidement, de manière à pouvoir tester plus de modèles et à en rapporter les résultats aux quants qui vont pouvoir rapidement adapter ces modèles pour les perfectionner. 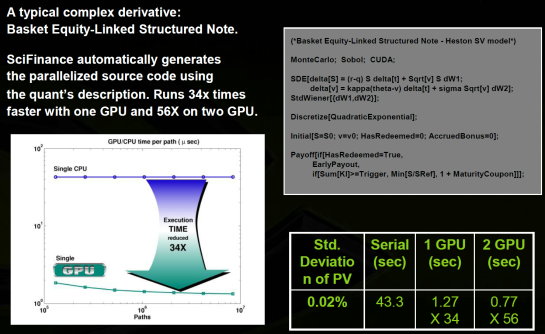 Utiliser les GPUs permet donc une analyse plus rapide et indirectement de meilleure qualité des marchés financiers, de quoi devancer ceux qui n'y font pas appel et qui auront donc dorénavant un train de retard. Page 7 - Exemple détaillé : TechniScan Exemple détaillé : TechniScanNous avons décidé de détailler plus en profondeur l'un des exemples d'utilisations des GPUs à travers CUDA qui est particulièrement intéressant puisqu'à lui seul il résume parfaitement les raisons d'utiliser cette solutions et le chemin qui mène à ce choix.  Cet exemple concerne la mise au point par TechniScan d'un appareillage destiné à la détection du cancer du sein qui va fournir de nombreuses images très précises sur la base des données ultrason. Des images qui pourront par ailleurs être utilisées pour créer une reconstruction en 3D. Le médecin spécialisé peut alors analyser complètement la structure scannée pour y détecter toute anomalie, contrairement aux solutions plus classiques avec lesquelles il est possible de passer à côté d'un problème. Le problème de ces solutions est que le traitement des images peut être très long, d'autant plus qu'il faut qu'elles soient nombreuses pour ne pas passer à côté d'un problème. TechniScan s'est fixé comme objectif de mettre au point un appareillage capable de fournir les résultats suffisamment vite pour qu'en un seul rendez-vous chez le médecin il soit possible de donner les résultats à la patiente. Cela impliquait un temps de traitement des images proche de 15 minutes. TechniScan s'est rapidement heurté aux limites de la technique, tout d'abord avec le premier projet à base de Pentium 2 auquel il fallait une semaine d'analyse. Plus tard un cluster de Pentium M est devenu en charge de générer ces images. Il fallait près de 4h30 et augmenter encore le nombre de processeurs n'apportait plus de gain, au contraire puisque le coût dû à la gestion de nombreux processeurs faisait chuter les performances au-delà d'une certaine limite. TechniScan a alors envisagé d'utiliser le Cell, mais il représentait un investissement trop important avec un résultat incertain. Cette idée a donc été oubliée. La compagnie s'est alors engagée dans le développement d'un nouveau cluster, cette fois à base de Core 2, les résultats progressaient bien par rapport au Pentium M. Même si l'objectif des 15 minutes semblait difficile à atteindre, la solution devenait réaliste.  Reste que d'autres acteurs du marché étaient probablement sur le coup aussi. TechniScan a alors continué d'envisager d'autres solutions. Un des développeurs principaux a eu l'idée de jouer un petit peu avec CUDA, en dehors de son temps de travail. Il a obtenu rapidement des résultats très intéressants sur certains algorithmes, résultats qu'il a présentés au management qui a oublié son scepticisme et a été séduit. Promesse de gains énorme pour coût de développement très faible ! TechiScan a alors implémenté la totalité de son traitement des données ultrason à travers CUDA et a obtenu quelque chose de fonctionnel et de rapide. Du coup, avec 4 cartes Tesla, le temps de traitement des données est réduit à 16 minutes, l'objectif est ainsi atteint. La solution a donc été retenue pour le produit final qui est en cours de validation par les organismes médicaux aux Etats-Unis pour une commercialisation prévue à la fin de l'année. 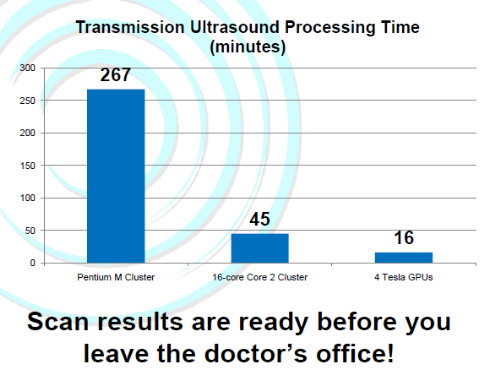 Le coût de la partie informatique de l'équipement revient à 10.000$ en version Tesla alors que le cluster de Core 2, 3x plus lent, serait revenu à 20.000$. Au final TechniScan promet l'arrivée sur le marché d'un appareillage plus rapide et moins cher que ce que ne propose la concurrence. CUDA aide ici à la conception d'un meilleur produit, plus pratique pour les médecins et les patients, et permet également à TechniScan d'être plus compétitif que ses concurrents. Page 8 - Exemple testé : Elcomsoft Exemple testé : ElcomsoftDe nombreux chiffres sont souvent avancés pour mettre en avant le GPU par rapport au CPU. x20, x100, x200 Il est souvent difficile de se faire une idée de la différence de performances entre les 2 types de puces sur les calculs massivement parallèle. D'une part parce que les performances varient très fort d'une utilisation à l'autre et d'autre part parce qu'il faut souvent se contenter des chiffres affichés par le fabricant. Des chiffres souvent donnés sans précision. Quel CPU est comparé au GPU ? Combien de cores CPUs sont utilisés ? Ce sont la plupart du temps des informations absentes et très souvent Nvidia compare les performances obtenues sur ses GPUs en version CUDA à une version CPU du code qui n'exploite qu'un seul core. Nous aimons donc bien pour illustrer les articles consacrés à ces technologies, réaliser nos propres tests. Il ne s'agit bien entendu que d'un exemple, mais que nous avons pu vérifier, pour rassurer les plus sceptiques. Pour cet article, nous avons utilisé un logiciel d'Elcomsoft, Elcomsoft Distributed Password Recovery, dont le but est de retrouver un mot de passe perdu. La méthode employé est la "brute force", autrement dit, le logiciel teste toutes les combinaisons possibles jusqu'à trouver la bonne. Elcomsoft a ajouté à son logiciel le support des GPUs à travers CUDA. Il s'agit donc d'une solution commerciale disponible, pas d'un bout de code expérimental. Nous avons testé ce logiciel pour essayer de retrouver des mots de passe sur base de hash md5. Il exploite automatiquement le GPU si une puce compatible CUDA est détectée. Voici les résultats que nous avons obtenus : 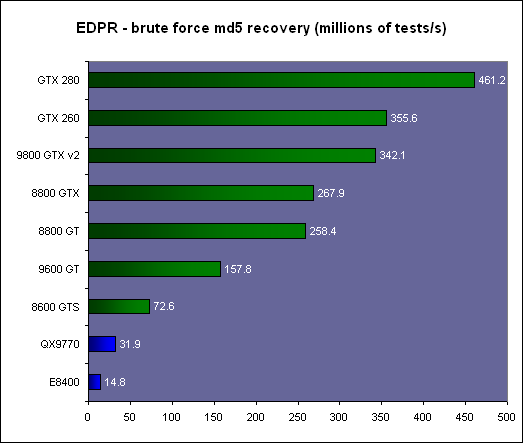 La GeForce GTX 280 est ici 14x plus rapide que le plus performant des CPUs Intel, le Core 2 Extreme QX9770. Comparé à un CPU plus courant tel que le Core 2 Duo E8400, la GeForce GTX 280 est 31x plus rapide. Vous remarquerez que les performances sur les GPUs varient presque entièrement d'après leur puissance de calcul. Page 9 - Et AMD ? Et AMD ?AMD, au départ précurseur dans le domaine de l'exploitation des puces graphiques comme unité de calcul, a pris du retard, beaucoup de retard, trop de retard selon nous. Nous évoquions déjà cet état de fait lors de notre dernier article consacré à CUDA et nous réitérons donc nos critiques. AMD a été le premier à montrer de l'intérêt pour le GPU Computing, AMD a été le premier à présenter des fonctions dédiées dans ses GPUs, AMD a été le premier à supporter le FP64, mais AMD a été incapable de produire rapidement un kit de développement. Aujourd'hui, la situation s'est améliorée, mais nous sommes encore loin du but. Au départ, AMD, ou plutôt ATI à l'époque, s'est focalisé sur un accès bas niveau à ses GPUs avec la CTM, Close To Metal. Cet accès avait l'avantage d'avoir un accès complet au GPU, mais le désavantage d'être très difficilement utilisable. Plus tard, AMD a proposé CAL, par-dessus la CTM. CAL, Compute Abstraction Layer, est un langage pseudo assembleur indépendant de l'architecture particulière du GPU. Il correspond a peu près au PTX, langage pseudo assembleur intermédiaire de CUDA. 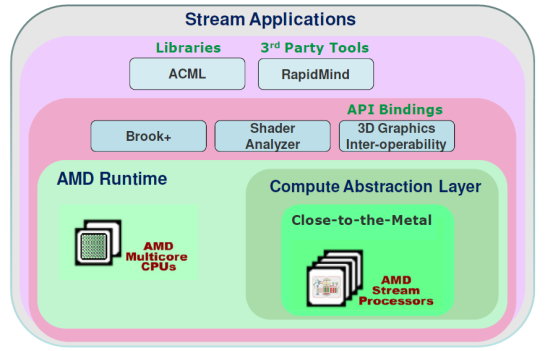 Enfin, AMD propose maintenant un langage de haut niveau, mais ne l'a pas développé comme Nvidia avec CUDA. AMD a choisi de reprendre Brook GPU déjà disponible. Brook GPU est le premier langage qui a été développé pour exploiter les GPUs. Son compilateur se charge de transposer le code proche du C/C++ en code OpenGL, ce qui n'est pas très efficace. AMD a amélioré cela et parle non pas de Brook mais de Brook+, la différence se situant justement à ce niveau puisque avec Brook+ le compilateur produit un code pour CAL et non pour OpenGL. Brook+ est donc très proche de CUDA, mais n'a pas été développé spécifiquement pour l'architecture des GPUs modernes. Il est donc, selon nos premières impressions, moins efficace. Notre plus gros reproche à AMD est de n'être toujours pas parvenu à rendre transparente l'utilisation des GPUs comme unité de calcul. L'aspect processeur graphique est très souvent rappelé au développeur. Par exemple, même avec CAL, il faut commencer le kernel en indiquant une version des Pixel Shader ! Il est aberrant que tout ceci n'ait pas été masqué. Et nous passerons certaines instructions qui existent en version _DX9 et en version _DX10 AMD pourrait compenser ce manque flagrant de finition par des documentations de qualité. Mais il faut être réaliste, si AMD n'a pas pu fignoler son interface d'accès, il ne faut pas s'attendre à des miracles au niveau des documentations qui ont un côté très brouillon. Elles sont dans l'état dans lequel nous nous attendions à les trouver il y a plus de 2 ans ! Ca part dans tous les sens. Il y a des documents de tout type, certains se recoupent etc. Certains documents font référence aux GPUs par leur nom commercial (Radeon HD 2900), d'autres par leur nom de code public (R600) et enfin d'autres par leur nom de code interne (Pele). Certains mélangent même plusieurs d'entre eux sans jamais dire à quoi ils correspondent. AMD indique ainsi que les architectures Pele et Boom ont un comportement différent sur certaines instructions, mais ne dit à aucun moment à quoi ils correspondent. Nous savons que Pele est le R600, mais quid de Boom ? RV670 ? Pour les GPUs plus récents, il n'y a rien de disponible alors que Nvidia a rapidement intégré le support des cartes à base de GT200. Bref, ce n'est pas très sérieux du côté d'AMD et cela témoigne selon nous d'un manque flagrant de ressources. Du coup on se demande si AMD y croit réellement ou continue simplement à faire des annonces dans le GPU Computing histoire de pouvoir dire "moi aussi" A l'exception de quelques développeurs téméraires et du personnel d'AMD, le kit de développement proposé devrait malheureusement rebuter beaucoup de monde. Page 10 - Conclusion ConclusionDès notre premier article consacré à CUDA, peu après la sortie publique de sa première version beta, nous avions été emballés par le côté concret qui semblait se dessiner autour de l'utilisation des GPUs en tant qu'unité de calcul dédiée au traitement des tâches massivement parallèles. Un côté concret qui a rapidement effacé le statut de précurseur accordé à ATI et AMD qui près de 3 ans après le début des annonces, n'ont toujours pas été capables de proposer un kit de développement digne de ce nom. Cette vision concrète provient de l'exécution rapide et efficace de Nvidia en ce qui concerne CUDA. Peu après l'annonce des premiers GPUs compatibles, le fabricant a très rapidement rendu publique son premier kit de développement beta, qui s'est bonifié au fil du temps pour rapidement atteindre un niveau de qualité suffisant pour que son utilisation soit sérieusement envisagée par l'industrie. Le tout accompagné d'une documentation très claire, de quoi pouvoir facilement faire ses premiers pas avec CUDA.  Nvidia s'est cependant rendu compte que la connaissance de la programmation massivement parallèle était trop peu enseignée dans les universités et a donc décidé d'organiser un premier cours dans une université américaine, cours qui s'est répandu dans de nombreux établissements aujourd'hui. CUDA est un formidable outil pour l'enseignement puisqu'il permet à faible coût d'avoir accès à un système massivement parallèle, contrairement à la difficulté de mettre à disposition des étudiants d'énormes supercalculateurs pour tester leurs algorithmes. Nvidia a donc bien compris qu'il y avait là une opportunité à ne pas manquer puisqu'en aidant à l'apprentissage de la programmation parallèle, ce qui était une demande importante, le fabricant habitue au passage les étudiants à exploiter ses GPUs, ce qui semblait encore farfelu il y a peu. Cette stratégie commence à payer, nombreux sont ceux qui s'intéressent maintenant aux GPUs à travers CUDA, que ce soient des étudiants ou des développeurs. Et pas uniquement dans des domaines dont le traitement ne devient possible qu'avec la puissance de calcul 10 ou 100x supérieure apportée par les GPUs. Nombres de développeurs y voient là une opportunité de se démarquer sur des tâches déjà d'actualité et l'accès facile à la technologie permet de briser facilement les réticences pour faire quelques expérimentations. Pourquoi ne pas essayer ? En cas de succès, CUDA permet bien souvent de se démarquer de la concurrence en prenant parfois un avantage significatif.  Bien entendu, comme beaucoup, nous attendons tous avec impatience l'arrivée du premier processeur massivement multicore d'Intel, mais celui-ci n'est attendu que pour 2009. Les GPUs Nvidia sont prêts, dès aujourd'hui et ne pas se préparer à les exploiter pour les différents acteurs de l'imagerie, de la finance ou de l'analyse de toute sorte de données, représente un risque. Le risque de voir des concurrents traditionnels ou nouveaux se saisir de l'opportunité à leur place. Tout ce petit monde est donc soit sur le coup, soit s'y prépare, soit observe de près ce qui se passe, mais personne ne peut plus ignorer ces possibilités. La génération de cartes Tesla 2, ou Série 10, a donc tout les chances de son côté pour rencontrer son public, même si l'utilisation d'une GeForce, meilleur marché, mais avec moins de mémoire, sera souvent privilégiée. Nvidia a choisi de laisser CUDA complètement ouvert aux puces grand public, de quoi trouver également des débouchés sur ce marché, via des encodeurs vidéo par exemple. C'est d'ailleurs là qu'est notre principal reproche à Nvidia par rapport à CUDA : ne pas avoir été assez actif, et peut-être ne pas y avoir cru dès le départ, pour créer ces débouchés. Un encodeur vidéo, par exemple, Nvidia aurait pu le mettre au point en interne et ce il y a 1 an au lieu de s'apercevoir du potentiel quand un développeur tiers lui a présenté son travail. Pour en savoir plus sur une partie des différents projets en cours, rendez-vous sur CUDA Zone , un site récemment ouvert par Nvidia qui référence tous les projets qui lui sont soumis. Copyright © 1997-2026 HardWare.fr. Tous droits réservés. |