| |
| |
| L'architecture AMD K10 Processeurs Publié le Jeudi 13 Septembre 2007 par Franck Delattre URL: /articles/682-1/architecture-amd-k10.html Page 1 - Rester dans la course C'est cette semaine que AMD a annoncé la première déclinaison de sa nouvelle microarchitecture, la version serveur "Barcelona" du très attendu K10. Quelques mois de patience seront encore nécessaires pour voir arriver les versions desktop grand public, les Phenom X2 et X4, qui narriveront pas avant le mois de décembre. Petit coup d'il sur l'architecture qui succède au très populaire Athlon 64.  Rester dans la courseL'avènement de l'architecture Core d'Intel en juin 2006 a jeté un pavé dans la mare aux processeurs. Le nouveau processeur Intel a rapidement volé la vedette à l'Athlon 64 en termes de performance, de dissipation thermique ... et de prix. Intel a frappé très fort, forçant AMD à remanier sa grille tarifaire de façon drastique (près de 50% de baisse pour l'Athlon 64 X2) ; et ce pour rester dans la course, sinon technologique, au moins commerciale. Quelques mois seulement après l'introduction du Core 2 Duo, Intel récidive en introduisant le premier processeur à quatre cores. Nouveau coup dur pour AMD, qui en plus d'être en retard sur le 65 nm, ne propose aucune solution commercialement viable face au Core 2 Quad.  AMD temporise en tirant autant qu'il peut sur la corde K8. Une version 65 nm du processeur apparaît en décembre 2006 ; le core Brisbane est destiné à combler le retard d'AMD en terme de dissipation thermique, et le fondeur Texan ne le décline qu'en version à 512 Ko de cache L2, écartant de ce fait le processeur du marché haut de gamme. Ainsi, en août dernier, l'ultime version de l'Athlon 64 X2, le 6400+ cadencé à 3,2 GHz, est basée sur le core Windsor 90 nm. En mars, le vice-président exécutif d'AMD Mario Rivas confesse qu'il aurait souhaité voir AMD décliner une version deux fois deux cores de l'Athlon 64, afin de parer au plus pressé et être présent sur le marché des processeurs quatre cores. Au lieu de cela, la politique commerciale choisie par AMD consiste à arriver sur ce marché avec une nouvelle architecture dessinée et pensée dès l'origine en quatre cores. Le K10 passe du statut de relève du K8 à celui de sauveur d'AMD. La nouvelle architecture est supposée combler le retard d'AMD sur de nombreux points (quatre cores, unités 128 bits, gestion avancée de l'énergie ...), et on peut légitimement se demander si cela ne représente pas un peu trop de poids sur les épaules d'une architecture émergeante. Le challenge est de taille, et c'est presque logiquement que les délais s'étirent, la pression monte, les doutes s'installent. Plusieurs dirigeants d'AMD quittent la société, et des rumeurs de rachat par un grand groupe de la micro-électronique circulent. Présentation du K10Les caractéristiques du K10 sont publiques depuis plusieurs mois. - Architecture quatre cores ; - Hiérarchie de caches inédite : 128 Ko de cache L1 et 512 Ko de cache L2 par core, cache L3 unifié de 2 Mo ; - Unités SSE 128 bits ; - Contrôleur mémoire DDR2 intégré au processeur ; - Mécanisme avancé de gestion de l'énergie (Independent Dynamic Core Technology) ; - 3 liens HyperTransport 1.0 (Barcelona), un lien HyperTransport 3.0 (Phenom) ; - 463 millions de transistors gravés en technologie 65 nm SOI. Page 2 - Quatre cores, enfin Quatre cores, enfinLe K10 marque l'entrée d'AMD sur le marché des processeurs à quatre cores, marché réservé à Intel depuis près de 10 mois. Afin de marquer la différence avec son concurrent, AMD insiste sur le caractère natif de son architecture à quatre coeurs. Ce caractère natif traduit le fait qu'un certain nombre de caractéristiques concernent les quatre coeurs dans leur ensemble, plutôt que deux par deux comme c'est le cas pour le Core 2 Quad.  A commencer par les échanges entre les cores, qui bénéficient d'un formidable vecteur de communication sous la forme du cache L3 partagé entre les quatre cores. Ensuite, la politique de gestion de l'énergie bénéficie d'un contrôle des quatre cores dans leur ensemble, dans un souci de contrôle maximal. On peut ainsi véritablement parler d'architecture dessinée spécifiquement pour une configuration à quatre cores, même si les versions deux cores et mono-core en seront dérivées. L'intégration de quatre cores est à elle seule un facteur d'accélération du traitement, mais nous savons que cette accélération n'est pas proportionnelle au nombre de cores, comme le révèle la loi d'Amdahl. Cette loi permet de mesurer le gain de performance d'un programme partiellement parallélisé sur un système multiprocesseurs. Cette loi simple nous indique que la courbe de performance, bien qu'augmentant avec le nombre de cores, tend à s'aplatir alors que le nombre de cores augmente. Ce phénomène peut se comprendre dans la mesure où un programme n'est jamais entièrement parallèlisable et qu'une partie de celui-ci continue de tourner sur un seul thread. De fait, cette partie n'est en rien accélérée par l'inflation du nombre de cores, et sa part sur le temps total augmente en même temps que celle de du code parallélisé se réduit. 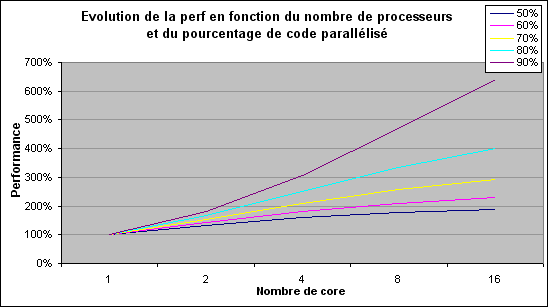 Ainsi, pour maintenir une augmentation de performance la plus constante possible, l'accélération des tâches unitaires est indispensable. Cela peut sembler paradoxal : plus le processeur comporte de cores, plus chacun d'eux doit être rapide afin que le niveau de performance globale augmente de façon significative. Chaque core de K10 a donc bénéficié de tous les soins de la part d'AMD afin de faire grimper son IPC (instructions par cycle) par rapport au K8. Page 3 - Un IPC boosté Un IPC boostéDans notre dossier sur l'architecture Core d'Intel, nous avons quantifié la puissance théorique d'une architecture par l'IPC (instructions par cycle) que celle-ci peut fournir sur les principaux jeux d'instructions (entiers, FPU, SSE). Le noyau du K10 est directement hérité de celui du K8. Doté de 3 ALUs (unités arithmétiques et logiques) dédiées aux calculs entiers, le K8 offre une capacité de calcul x86 égale à celle du Core 2 Duo. En SSE entier, les deux unités de calcul 64 bits du K8 ne permettent de traiter que 8 entiers 16 bits par cycle, alors que le Core 2 Duo peut en traiter jusqu'à 24 grâce à ses 3 unités SSE 128 bits. Même constat en SSE flottant, où les deux unités flottantes du Core 2 Duo associées aux unités SSE 128 bits permettent de traiter deux fois plus de données flottantes que le K8 à chaque cycle d'horloge. Le K10 offre la même capacité de calcul entier que son prédécesseur. En SSE entiers, il offre un pic de traitement atteignant trois opérations entières par cycle (deux opérations arithmétiques par les deux unités SSE et un déplacement par l'unité FP Move). En calcul flottant en revanche, son IPC théorique est propulsé au même niveau que celui du Core 2 et ce grâce à l'adoption de deux unités SSE capables de traiter 128 bits par cycle. 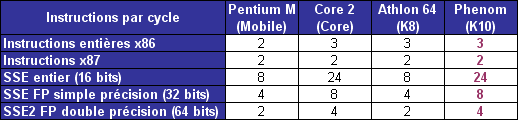 Afin d'alimenter les deux unités SSE 128 bits à plein régime, le K10 double le débit d'instructions en entrée (de 16 à 32 octets d'instructions par cycle) ainsi que la bande passante du cache L1 de données (de 2 x 64 bits à 2 x 128 bits par cycle). Nouvelles unités de prédictionsA titre de rappel, les branchements et les accès mémoire constituent les deux principales sources de réduction de l'IPC (je vous renvoie au dossier sur le Core 2 Duo pour plus de détails). Il est donc normal et bienvenu qu'AMD ait doté son K10 d'optimisations spécifiques. Une branche se traduit, dans un flux d'instructions, par un saut vers une nouvelle adresse. Ce saut a pour conséquence de perturber le fonctionnement du pipeline qui ne peut plus accueillir de nouvelle instruction avant de connaître l'adresse de destination. La solution mise en uvre par les mécanismes classiques de prédiction de branchement consiste à essayer de deviner si une branche va être prise ou non. Pour ce faire, le processeur intègre plusieurs unités de prédiction qui différent suivant leur méthode de travail, les plus efficaces se basant sur un historique des branches prises stocké dans un buffer dédié.  Les unités de prédiction du K8 sont conçus pour prédire les branches directes, c'est-à-dire celles pour lesquelles l'adresse de destination du saut est explicitement spécifiée dans le code. Le travail de l'unité de prédiction consiste alors à deviner si le branchement sera effectué ou pas. Mais ces unités se montrent peu efficaces sur les branches indirectes, c'est-à-dire celles dont l'adresse de destination est susceptible de changer au cours de l'exécution. Ce type de branche est très courant dans les langages orientés objet qui font grand usage des pointeurs de fonctions. Le K10 possède une unité de prédiction dédiée aux branches indirectes qui est capable de stocker plusieurs adresses de destination préférées pour chaque branche, améliorant ainsi l'efficacité de la prédiction. Il ne s'agit pas là d'un mécanisme inédit car il équipe les processeurs Intel depuis le Pentium 4 Prescott. Mais K8 a été dessiné bien avant cela ! Page 4 - Les caches du K10 Les caches du K10Les latences induites par les accès mémoire représentent une des principales sources de ralentissement d'un pipeline de traitement. L'arme principale du processeur pour masquer ces latences réside dans son sous-système de caches. On mesure dès lors toute l'importance que revêt la hiérarchie de caches dans les spécifications d'une architecture, et à ce titre l'Athlon 64 repose sur une hiérachie de caches qui a prouvé son efficacité. Il semble donc naturel que le K10 s'en inspire fortement, pour ne pas dire totalement pour les niveaux de cache L1 et L2 dont l'influence est la plus notable sur les performances. Nous ne ferons donc ici qu'énumérer des paramètres bien connus de tous : chacun des quatre cores intègre ainsi un gros cache L1 splitté en 64 Ko pour les instructions et 64 Ko pour les données, secondé d'un cache L2 unifié exclusif de 512 Ko. Les performances de ce sous-système largement éprouvé reposent majoritairement sur le choix d'un cache L1 de très grande capacité (la plus grande toutes architectures confondues) et rapide. Chacun des L1 de 64 Ko est associatif à deux voies, ce qui signifie qu'il est (de façon schématique) organisé en deux blocs de 32 Ko chacun. Ces caches jouent donc la carte de la localité : un bloc d'une telle taille est capable de contenir une grande quantité de données ou d'instructions contigües. Cette propension à la localité est logiquement au détriment de la spatialité, le L1 ne peut ainsi couvrir que deux régions en mémoire à un instant donnée. Le cache L2 compense cette relative faiblesse en offrant à l'inverse une associativité élevée eu-égard à sa taille (512 Ko et associatif à 16 voies). L'association de ces deux niveaux assure ainsi un bon niveau de performance en toutes circonstances.  Cette efficacité en association est une des raisons pour lesquelles AMD a gardé un cache L2 dédié à chacun des quatre cores de son K10, en comparaison à une solution de cache L2 partagé. C'est donc presque tout naturellement qu'un troisième niveau de cache a été introduit sur le K10. Partagé entre les quatre cores, le L3 n'a pas pour vocation première d'augmenter la performance de chaque core pris individuellement, mais plutôt d'assurer la performance des quatre cores travaillant de concert. Ce L3 participe pour une grande part au caractère "natif" de l'architecture à quatre cores du K10, assurant une voie de communication "on-die" entre les cores. 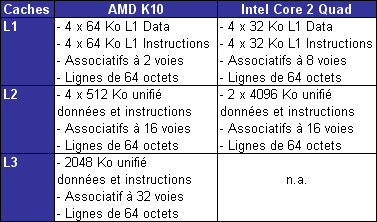 Le partage du cache entre quatre cores est une première. La mise au point d'un tel mécanisme est complexe, car les conflits entre les threads peuvent anéantir tout le bénéfice du cache, voire devenir une source de ralentissement. Afin de réduire les conflits, le L3 du K10 offre 32 voies d'associativité, soit la plus grande valeur observée jusqu'ici sur un cache de processeur x86. Il faut noter que comme sur K8, les hiérarchies de cache des processeurs AMD K10 se distinguent par la relation exclusive qui lie les niveaux successifs. A titre de rappel, un cache exclusif de niveau 2 par exemple reçoit les données évincées du cache L1, mais ne contient pas de copie des données ou des instructions remontées depuis la mémoire vers le L1. Ainsi, données et instructions sont exclusivement présentes dans un des deux niveaux de cache, mais jamais dans les deux à la fois. En comparaison à une relation de type inclusif, dans laquelle le L2 contient une copie du L1, la relation exclusive offre des performances légèrement en retrait (la mise en cache nécessite une étape supplémentaire afin de sauvegarder la ligne évincée, opération inutile en relation inclusive), à la faveur d'une quantité de cache utile plus importante (égale à la somme des tailles) et d'un souplesse dans l'implémentation (pas de contraintes sur les tailles). Bien que fortement inspirés du K8, les caches du K10 ont été adaptés aux nouvelles capacités du processeur, en particulier de la LSU (Load-Store Unit). La LSU du K10 est capable d'effectuer deux opérations de lecture / écriture 128 bits par cycle, là où le K8 est limité à deux opérations 64 bits. Afin de ne pas ralentir la LSU ainsi dopée, les L1 du K10 ont été retouchés afin de fournir une bande passante double en comparaison à celle fournie par les caches du K8. Même traitement pour le bus reliant les caches L2 au contrôleur mémoire, doublé de 64 à 128 bits. Ce dernier point devrait combler la relative faiblesse de la bande passante offerte par le cache L2 des K8, assez en retrait par rapport aux L2 hyper performants des processeurs Intel. Page 5 - Les caches, suite Latences, associativité et dissipationLes latences mesurées des caches du K10 affichent 3 cycles pour le L1, 15 cycles pour le L2 et entre 30 et 45 cycles pour le L3. Ces valeurs méritent quelques éclaircissements. La latence du L1 n'a pas changé par rapport au K8, et c'est tant mieux car elle contribue aux bonnes performances de ce dernier. La mesure de la latence du L2 est un soulagement suite à la "surprise" que nous avait réservée la version 65 nm de l'Athlon 64 (core Brisbane) dont la latence du L2 a subi une augmentation véritablement néfaste aux performances. Point de cela sur le K10 heureusement, et la latence des L2 reflète la valeur que l'on observe sur l'Athlon 64 90 nm (core Windsor). La latence mémoire est légèrement augmentée par la présence du cache L3, dans la mesure où un accès mémoire a lieu dès lors que chacun des trois niveaux de cache n'a pas répondu positivement à la requête. Certes, cela prend un peu plus de temps pour accéder à la mémoire, mais il ne faut pas en conclure pour autant que l'ajout d'un niveau de cache ralentit les accès mémoire ! C'est même l'inverse qui se produit, car la présence du L3 diminue de façon significative le nombre d'accès à la mémoire. 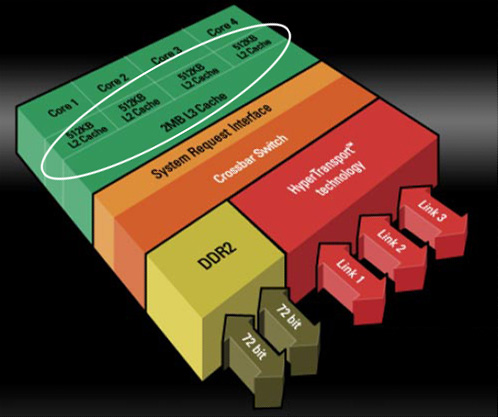 Enfin, sachez que si la latence du L3 du K10 est exprimée en cycles processeurs, cee cache est solidaire du "power plane" du contrôleur mémoire, ce qui signifie qu'il ne fonctionne pas à la fréquence du processeur mais à celle du contrôleur mémoire (soit entre 200 et 400 MHz de moins que le noyau). Pour finir, nous pouvons supposer que la latence élevée du L3 du K10 peut refléter la volonté de réduire la dissipation thermique du cache. Pour bien comprendre le lien entre la latence et la dissipation thermique, il faut se pencher un peu sur les mécanismes régissant le cache. Lorsqu'une donnée (ou une instruction) est lue en mémoire et écrite dans le cache, celle-ci est placée à une adresse à laquelle le contrôleur sait pouvoir la retrouver, et définie à partir de l'adresse originale de la donnée en mémoire. Le cache étant moins volumineux que la mémoire, les adresses de cache sont comprises dans une fourchette bien plus petite que les adresses mémoire, et l'adresse de cache est souvent générée à partir des premières unités de l'adresse mémoire concernée. A titre d'exemple, si l'adresse mémoire vaut 0xF01C0123, l'adresse de cache est 0xC0123. Ainsi, les données situées aux adresses 0xF01C0123 et 0xF2C0123 partagent la même adresse de cache, et si les deux données sont mises en cache il y a conflit d'adresses. Pour régler ce conflit, un cache peut réserver non pas un emplacement pour l'adresse de cache 0xC0123, mais deux, quatre, huit .... on parle alors de cache associatif à 2, 4 ou 8 voies. De cette façon, plus l'associativité du cache est élevée, plus le risque de conflit est faible. Tout se passe comme si le cache était organisé en autant de blocs qu'il y a de voies d'associativité, et plus les blocs sont de faible taille, moins ils peuvent contenir de données ou d'instructions contigües en mémoire. Il s'agit donc de trouver le compromis idéal entre taille et associativité du cache, mais de façon générale, plus un cache est volumineux et associatif, meilleures sont les performances. Une associativité élevée pose un problème cependant. Une requête dans le cache à partir d'une adresse déclenche la lecture de toutes les données partageant la même adresse, soit autant que le nombre de voies. Bien entendu, une seule de ces données est celle recherchée, les autres ayant été activées pour rien. Hélas, chacune de ces lectures active une partie du cache, et provoque un dégagement de chaleur. Ainsi, plus le cache est associatif, plus sa dissipation thermique est importante à chaque requête. Comment conserver une associativité élevée tout en réduisant le dégagement de chaleur ? La solution consiste à ne plus activer toutes les voies simultanément en cas de lecture, mais seulement quelques-unes à la fois (voire une seule), jusqu'à ce la donnée recherchée soit trouvée. Cette sérialisation de la lecture se traduit par un cache économe en énergie et dissipant peu de chaleur, mais dont la latence apparente a été multipliée. Ce pourquoi la technique est utilisée principalement sur les processeurs mobiles. Pour tout dire nous ignorons si le cache L3 du K10 utilise véritablement une associativité en série telle que celle que nous avons décrite. Cela étant, nous sommes confortés dans cette hypothèse par la latence mesurée assez élevée, eu égard à la taille du cache (les caches Intel sont deux fois plus volumineux mais affichent une latence bien inférieure), mais également par le fait que la relative lenteur du L2 du Brisbane s'explique probablement par l'emploi de la même technique. Page 6 - Contrôleur mémoire Contrôleur mémoire intégré seconde générationL'intégration du contrôleur mémoire dans le processeur a été une des innovations majeures apportées par le K8. La performance est là, au détriment certes d'un certain manque de souplesse. On sait maintenant qu'Intel prévoit un contrôleur mémoire intégré sur certains modèles de sa future architecture, preuve s'il en est besoin de la pertinence du choix qu'a fait AMD depuis quelques années déjà. Le support de la DDR2 et le besoin accru en bande passante mémoire des versions double core de l'Athlon 64 ont nécessité un remaniement du contrôleur intégré en 2006. La nouvelle architecture K10 impose de nouvelles contraintes au contrôleur mémoire intégré, qui subit cette fois de plus profondes évolutions.  Avec K10, ce sont désormais quatre cores qui se partagent un unique contrôleur mémoire DDR2 / DDR3. Les principales améliorations visent donc à améliorer l'efficacité du contrôleur mémoire : buffers de plus grande taille (afin d'augmenter les opportunités de transferts en parallèle), gestion des pages mémoire optimisée (pour réduire les conflits et les ralentissements qui en découlent), et ajout d'un prefetcher comme nous l'avons évoqué plus haut. La gestion des canaux mémoire a gagné en souplesse, les deux canaux 64 bits pouvant opérer de concert pour fournir une bande passante maximale, ou indépendamment pour des opérations de lecture / écritures simultanées. Souplesse également en ce qui concerne l'alimentation et la vitesse de fonctionnement du contrôleur mémoire. La technologie "split plane" permet en effet de séparer l'alimentation du contrôleur mémoire de celle du reste du processeur. Outre une gestion plus fine de la dissipation thermique, cette technologie permet également d'augmenter ponctuellement la tension délivrée au contrôleur mémoire, ce qui offre la possibilité d'augmenter sa fréquence de fonctionnement (et son débit) en cas de besoin.  Attention cependant, car seules les cartes mères "AM2+ (ou Socket F+ dans le cas du Barcelona) supporteront le "split-plane". Sur plateforme AM2, le contrôleur fonctionnera en mode "uni-plane", c'est-à-dire qu'il partagera la tension du CPU. Pour éviter que la dissipation thermique ne s'envole, la fréquence de fonctionnement du contrôleur mémoire et du L3 est alors réduite de 200 MHz par rapport au mode "split-plane". Prudence donc, si la compatibilité avec la plateforme AM2 est une réalité, elle ne se fera pas sans quelques petits désagréments. Page 7 - Optimisations diverses PrefetchersLe sous-système de cache du K10 bénéficie également de prefetchers hardware plus performants que celui du K8. A titre de rappel, le fonctionnement du prefetcher repose sur le principe qu'un échec de lecture en cache a de fortes probabilités de se reproduire, ce qui déclenche donc la remontée d'instructions ou de données depuis la mémoire centrale. Le K10 possède deux prefetchers hardware qui alimentent ses caches L1, alors que ceux du K8 opèrent dans le cache L2. Le K10 bénéficie en outre d'un nouveau dispositif de prefetch dans le contrôleur mémoire qui possède un buffer de stockage dédié. Optimisations diversesLe K10 s'efforce de corriger les quelques défauts de son prédécesseur. Le K8 souffre ainsi d'une division entière passablement lente en comparaison à l'architecture Core de son concurrent (et en particulier face à la version 45 nm qui, rappelons-le, bénéficie d'une optimisation spécifique à ce type d'opération). Le K10 corrige le tir, sans pour autant atteindre la performance de la version 45 nm du Core 2. L'adoption de la gestion out-of-order des instructions de lecture mémoire est beaucoup plus intéressante. Présent sur le Core 2 et appelé Memory Disambiguation par Intel, ce mécanisme spéculatif a pour objectif de prédire si une instruction de lecture est susceptible de dépendre des écritures en cours ; dans le cas contraire, la lecture est traitée sans délai. Notons également une gestion de la pile améliorée (les instructions de gestion de la pile sont désormais prises en charge par une unité dédiée), ainsi que quelques mises à niveau dans le support des instructions étendues, en particulier quelques instructions SSE3 absentes du K8 et une nouvelle série d'instructions SIMD regroupées sous la dénomination SSE4A (mais qui n'ont rien à voir avec les SSE4.1 et SSE4.2 d'Intel, ce serait trop facile). Support amélioré de la virtualisation  Le K10 propose une série d'optimisations visant à accélérer le traitement des machines virtuelles, citons par exemple une gestion mémoire améliorée, ou la réduction du temps de transition entre l'hyperviseur et les machines virtuelles. Page 8 - Gestion de l'énergie Une gestion pointue de l'énergieS'il est une chose qu'Intel a bien retenue de l'expérience "Prescott" (consultez notre dossier sur l'architecture Core pour vous rafraîchir la mémoire), c'est que la dissipation thermique est devenue le facteur limitant la performance des architectures modernes. L'impact de ce nouveau paramètre est tel que le design des architectures n'est plus guidé par le potentiel de performance qu'elles peuvent générer mais par le rapport entre la performance et les watts consommés. AMD introduit en même temps que son architecture un nouvel indice de consommation appelé ACP (Average CPU Power, pour puissance dissipée en moyenne), annoncée comme étant plus représentative de la dissipation réelle que le TDP, qui reflète davantage une valeur maximale de puissance. Et bien entendu, l'ACP affiche des valeurs inférieures au TDP. AMD reste cependant prudent dans la mesure où il compte communiquer sur les deux valeurs et non sur le seul ACP. AMD communique beaucoup sur un point essentiel lié à la consommation de ses processeurs en rappelant ceux-ci intègrent le contrôleur mémoire, et qu'il est donc naturel que ceux-ci dissipent davantage que les produits à contrôleur séparé. AMD prétend que l'intégration du contrôleur mémoire diminue l'enveloppe thermique globale du couple processeur + northbridge en comparaison à une solution à contrôleur séparé ; ce qui est certainement exact, mais passe sur le fait que la chaleur est ainsi concentrée sur une plus petite surface, et est donc plus difficile à dissiper. 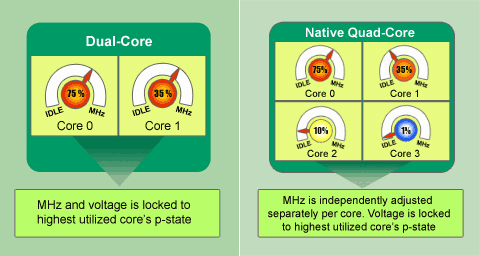 Le K10 pallie en partie à ce défaut par la séparation de l'alimentation et de l'horloge du contrôleur mémoire de celles du coeur du processeur, permettant ainsi de moduler les deux tensions de façon séparée en fonction de l'activité respective des deux sous-systèmes. Le K10 propose ainsi deux mécanismes de gestion des multiplicateurs (FID) et des tensions (VID) : un pour le CPU et un pour le contrôleur mémoire. En ce qui concerne le coeur du processeur, celui-ci inaugure un mécanisme de gestion de l'énergie appelé "Independent Dynamic Core Technology" reposant sur la modulation dynamique et indépendante des fréquence de chaque core, dans le but de maîtriser l'enveloppe thermique globale du processeur. Page 9 - La gamme, conclusion La gamme  L'Opteron Quad Core, nom de code Barcelona, est la version serveur du K10, premier processeur disponible exploitant la nouvelle architecture. - Quatre cores, 512 Ko de cache L2 par core, cache L3 partagé de 2 Mo ; - Gravure 65 nm, SOI ; - Fréquences entre 1,7 et 2 GHz, pour un TDP de 68 à 95W ; - Socket F/F+ (LGA 1207) ; - Trois liens HyperTransport 1.0 ; - Support DDR2-667 Registered. Cinq modèles sont prévus en plateforme biprocesseurs (Opteron 23xx en 95W et 23xx HE en 68W) pour des tarifs entre $206 et $370 selon les versions ; quatre modèles Opteron 83xx sont également disponibles pour être installés dans des configurations jusqu'à huit processeurs (donc 32 cores !), à des tarifs compris entre $690 et $1000. AMD compte monter en fréquence et annonce pour la fin de lannée des versions atteignant jusquà 2.5 GHz. La déclinaison desktop du K10 prendra le nom de Phenom et narrivera quau mois de décembre. On distingue : Le Phenom X4, nom de code "Agena" : - Quatre cores, 512 Ko de cache L2 par core, cache L3 partagé de 2 Mo - Gravure 65 nm, SOI ; - Socket AM2+ (PGA 940); - Un lien HyperTransport 3.0 ; - Support DDR2-1066. Le Phenom FX partage ces caractéristiques, mais bénéficiera d'une fréquence d'horloge qui sera certainement légèrement supérieure. Il existera également en version Socket F+. Le Phenom X2 "Kuma"est la version deux cores du X4 : - Deux cores, 512 Ko de cache L2 par core, cache L3 partagé de 2 Mo ; - Gravure 65nm, SOI ; - Socket AM2+ (PGA 940); AMD prévoit deux déclinaisons en entrée de gamme. - L'Athlon X2 "Rana", un Phenom X2 privé de son cache L3, en socket AM2+ ; - Le Sempron "Spica", comprenant un seul core et pas de L3, également en socket AM2+. Quid face au Core 2 ?L'étude du K10 révèle qu'AMD a opté pour un compromis judicieux entre innovations et techniques rôdées pour le dessin de sa nouvelle architecture. Le K10 hérite des qualités du K8 tout en apportant son lot de nouveautés nécessaires pour rester à la pointe de l'innovation. K10 est à n'en pas douter une architecture équilibrée et performante. Reste à déterminer si ces qualités suffiront à le rentre compétitif face au Core 2 aujourd'hui, et si AMD arrivera à augmenter rapidement la fréquence du K10. Les premiers tests de larchitecture K10 sur des applications « desktop » laisse entrevoir un gain de performances moyen de 14% par rapport à K8 à fréquence égale, avec des pointes à 21%, ce qui est un peu décevant sachant que lavance de larchitecture Core sur larchitecture K8 est denviron 25%. Ces tests ont toutefois été faits sur plate-forme Opteron, et la plate-forme desktop pourrait bénéficier de gains supérieurs. Par exemple, on ne sait pas encore dans quelle mesure les performances du K10 sont lié à la vitesse mémoire par rapport au K8, peut-être lest-il plus, auquel cas il est forcément désavantagé lors de tests en DDR2-667.  Enfin, si K10 possède du potentiel, cela ne suffit plus. Le nouveau challenge de la performance passe par la maîtrise de la dissipation thermique, et dans ce domaine Intel est indéniablement en avance sur les procédés de fabrication. Mais rien n'est joué, et le combat n'est même pas commencé. Copyright © 1997-2025 HardWare.fr. Tous droits réservés. |