| |
| |
| AMD Radeon HD 4870 & 4850 Cartes Graphiques Publié le Mercredi 25 Juin 2008 par Damien Triolet URL: /articles/725-1/amd-radeon-hd-4870-4850.html Page 1 - Introduction AMD revient en force avec de nouvelles Radeon. La série 4800 est en effet plus que prometteuse, et pas seulement sur le papier puisque nous vous avons pu le vérifier la semaine passée à travers l'aperçu des performances du petit modèle, la Radeon HD 4850. Aujourd'hui nous allons vous en proposer un test complet qui inclut la Radeon HD 4870 ainsi qu'une analyse en détails de son architecture. Faire beaucoup avec peuContrairement à Nvidia qui a le vent en poupe et malgré une Radeon HD 3800 plutôt sympathique, AMD a des difficultés à vendre ses Radeon, surtout sur le milieu et le haut de gamme. Nvidia domine nettement ce segment tant en terme de ventes qu'en terme d'image et il est comme vous vous en doutez très coûteux de se battre sur ce terrain.  Parallèlement à cela, le multi-GPU a gagné en maturité et est devenu une solution sur laquelle il est possible de se reposer d'une manière acceptable pour le très haut de gamme. Comme nous l'avons répété à plusieurs reprises, et comme les tests des GeForce GX2 et autres Radeon X2 l'ont montré, ce n'est pas la solution idéale, mais à défaut de mieux elle permet de combler un éventuel vide à ce niveau. Ayant des ressources limitées, AMD doit se concentrer sur des projets efficaces. AMD n'a pas les moyens de jouer à celui qui a la plus grosse en matière de GPU, il est donc évident que développer un énorme GPU, comme l'a fait Nvidia avec le GT200 des GeForce GTX 200, n'est pas au programme. Du coup que reste-t-il à AMD ? Se contenter du bas de gamme ? Heureusement ce n'est pas le cas. AMD a décidé de se concentrer sur le segment "performance". Un segment en général partagé par les gros modèles milieu de gamme et les produits plus haut de gamme déclassés. Entre 150 et 250 , le segment "bonne affaire" en quelque sorte. AMD a ainsi pris la base de son architecture HD 2000/3000 et essayé d'en tirer le maximum pour un budget "GPU performance", c'est-à-dire pour une puce de taille moyenne, très loin des 600 mm² du GT200 de Nvidia.  Le RV770 ainsi développé ne mesure que 260 mm², mais embarque malgré tout la bagatelle de 956 millions de transistors. Le Radeon HD 3800, ou RV670 se contentait, lui, de 190 mm² et de 666 millions de transistors. Avec 40% de plus, qu'à pu faire AMD ? Page 2 - Architecture : SIMT, SIMD, MIMD, Radeon HD SIMT vs SIMD vs MIMDAvec les GeForce 8, Nvidia a introduit une architecture en rupture totale avec le passé. Ainsi, fini les énormes unités vectorielles MIMD dont il est parfois difficile de tirer le maximum. Le choix a été fait pour des unités scalaires. Si au niveau de l'implémentation il s'agit d'unités SIMD (comme le SSE) larges de 256 bits (8 x 32 bits), sur le plan fonctionnel, ce n'est pas une instruction de 8 opérations 32 bits qui est appliquées sur 1 thread/élément à chaque cycle, mais bien 1 opération 32 bits sur 8 threads/éléments. Du coup en pratique, pour l'extérieur, ces unités se comportent comme des unités scalaires. Pour marquer cette différence avec le SIMD (Single Instruction Multiple Data), Nvidia parle de SIMT (Single Instruction Multiple Threads). Si les unités sont similaires, le SIMT permet de maximiser l'utilisation des unités naturellement si la tâche à accomplir est massivement parallèle, comme c'est le cas pour le rendu 3D. L'intérêt étant qu'en SIMT, le programmeur n'a rien à faire pour que ce soit le cas, alors qu'en SIMD, le programmeur et le compilateur doivent s'efforcer de remplir l'unité vectorielle, ce qui n'est pas toujours simple puisqu'il faut qu'une instruction identique soit exécutée plusieurs fois sur des données différentes d'un même thread et qu'elles ne soient pas dépendantes l'une de l'autre pour qu'elles puissent être traitées en parallèle. Le MIMD (Multiple Instructions Multiple Data), tel qu'exploité par AMD dans les Radeon HD 2000/3000 est plus flexible puisque la première contrainte disparaît. La seconde reste cependant très importante. Le SIMT n'est bien entendu pas la solution ultime, puisqu'il s'agit toujours de compromis. Plus efficace il est aussi plus gourmand en termes de transistors, de surface sur la puce et de consommation puisqu'il a besoin d'une logique de gestion plus complexe. Le SIMD et le MIMD permettent par contre de placer plus d'unités de calcul dans le GPU, au prix d'une efficacité moindre. Pour les Radeon il s'agit en réalité d'un mix entre le SIMT et le MIMD. Les GeForce 8 sont ainsi nées avec seulement 128 unités scalaires alors qu'une Radeon HD 3870 contient 64 unités vec5, soit l'équivalent de 320 unités scalaires. L'efficacité supérieure du SIMT n'est bien entendu pas suffisante par rapport à cette différence. Par contre, Nvidia est parvenu à implémenter des unités de calcul de type double pumped, c'est-à-dire fonctionnant à une vitesse double par rapport au scheduler. Architecture Radeon HD 2000 et 3000Le coeur des Radeon HD 2900 et 3800 repose sur 4 gros blocs d'unités de calcul que nous appellerons multiprocesseurs pour faire le parallèle avec l'architecture GeForce 8/9/GTX. Chaque multiprocesseur dispose de son propre scheduler, d'un gros fichier de registres généraux et de 16 processeurs vec5, ou vec4+1 pour être précis. L'équivalent de 80 processeurs scalaires. Première différence entre les architectures : une logique de gestion (scheduler etc.) pour 80 unités de calcul chez AMD contre une logique de gestion pour 8 unités de calcul (+ SFU) chez Nvidia. AMD a donc un coût nettement moindre en terme de gestion par unité de calcul. En contrepartie, AMD doit d'une part travailler sur des groupes d'éléments plus gros (64 contre 16 ou 32 chez Nvidia) et d'autre part fait appel à des processeurs vec4+1 et non à des processeurs scalaires. C'est dans ce sens qu'il s'agit d'un mix entre le SIMT et le MIMD. Un multiprocesseur est SIMT 16-way puisqu'il exécute les mêmes instructions sur 16 threads en parallèle mais il est également MIMD 5-way puisque il peut exécuter jusqu'à 5 instructions en même temps sur des données différentes de ces threads. Nous précisons vec4+1 puisqu'un processeur de Radeon est en réalité composé d'une unité MIMD basée autour d'une unité FMAD vec4 et d'une grosse unité scalaire qui peut prendre en charge toutes les instructions (à l'exception du produit scalaire). Autrement dit, les instructions spéciales et les instructions sur les entiers doivent toutes passer par cette unité. Parallèlement à ces 4 gros multiprocesseurs, les Radeon possèdent 4 blocs d'unités de texturing complètement découplés. Ceux-ci sont capables de sampler et de filtrer 4 texels 4D en FP16 (HDR) via leurs 4 unités de texturing principales et d'accéder à 4 texels 1D supplémentaires, mais sans les filtrer. Etant découplées, ces unités de texturing ne sont pas liées à un multiprocesseur particulier et peuvent donc toujours être utilisables, même si un multiprocesseur n'a pas besoin d'elles. Reste que par rapport aux 64 unités de filtrage d'une GeForce 9800 GTX, les 16 unités de filtrage d'une Radeon HD 3870 font un peu léger et les 16 samplers 1D supplémentaires n'y changent rien. Page 3 - Architecture : Radeon HD 4800 Architecture Radeon HD 4800Avec les Radeon HD 4000 et plus particulièrement avec le RV770, AMD devait repartir de l'architecture de base des générations précédentes, sans quoi le développement aurait été trop long et tout l'investissement du côté logiciel aurait pu être oublié. Du coup la base reste la même, à savoir des multiprocesseurs 16-way dont chacun des 16 processeurs est une unité de calcul MIMD vec5. 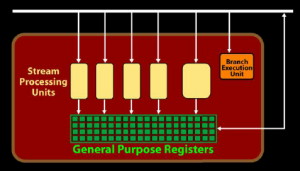 Un processeur et ses 5 unités de calcul. Petite amélioration cependant, AMD a étendu le support des instructions sur les entiers à toutes les sous unités. Si une unité reste plus évoluée avec le support des fonctions spéciales, le support des entiers est maintenant intégré à toutes les unités de calcul. Là où AMD a le plus travaillé c'est sur la simplification de l'implémentation hardware de ces multiprocesseurs. Tout en conservant un rendement similaire (et même un meilleur rendement dans le cas des opérations sur les entiers donc) AMD est parvenu à réduire significativement leur taille. AMD s'en est ensuite pris à ses unités de texturing. Elles étaient trop grosses et pas spécialement efficaces malgré le découplage. AMD a donc décidé d'abandonner celui-ci, pourtant plus élégant et de recoupler un bloc d'unités de filtrage par multiprocesseur qui en aura donc l'exclusivité. Toujours par souci d'économie, AMD est revenu en arrière sur 2 autres points : les samplers scalaires ont été effacés du design et le filtrage FP16 a été réduit à demi vitesse. Les blocs d'unités de texturing sont ainsi devenus 70% plus légers. Pour compenser en partie les différentes pertes AMD a revu la structure de ses caches pour maximiser le rendement autant que possible de "ce qui reste".  2 multiprocesseurs et leurs unités de texturing. AMD a ainsi pu rendre la base de son architecture nettement plus économe. A tel point que selon les bruits de couloir qui nous parviennent, au départ AMD visait l'implémentation de 6 multiprocesseurs, soit de 96 processeurs vec5 et 24 unités de texturing, ou encore de 480 processeurs scalaires pour donner un équivalent avec les GeForce. Par rapport à la taille de la puce fixée par le pin out, ses connexions, AMD a "malheureusement" fait un trop bon travail. Du coup les unités prenaient moins de place que prévu et une partie du die était inoccupée. Comment le remplir ? En rajoutant 4 multiprocesseurs de plus ! AMD a probablement dû pousser un peu, mais ils sont rentrés. Du coup AMD nous arrive avec un RV770 qui contient pas moins de 160 processeurs vec5, soit 800 processeurs scalaires, et 40 unités de texturing. Un net bon avant par rapport à la génération précédente. 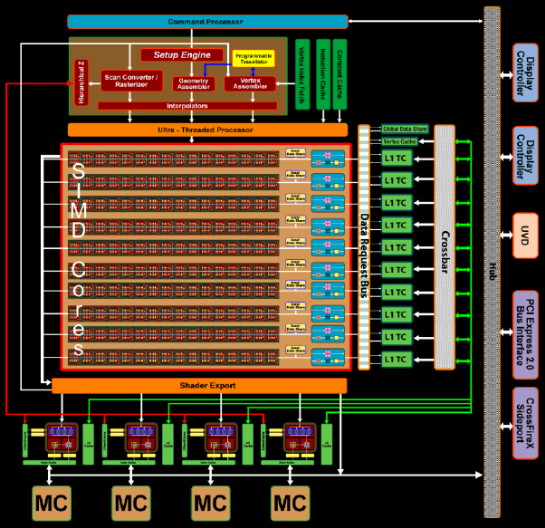 Gros défaut de cette précédente génération : les ROPs. L'efficacité de ceux-ci est en effet questionnable, surtout avec antialiasing. Si AMD n'a jamais détaillé ouvertement le problème, mais a avoué qu'il y en avait un, il semble évident qu'une partie des ROPs ne fonctionne pas ce qui grève les performances avec antialiasing. Nous supposons qu'il s'agit de l'unité de MSAA resolve ou de downsampling, dont le travail est de ramener l'image à la taille d'affichage, ce qui la filtre et fait disparaître l'aliasing. 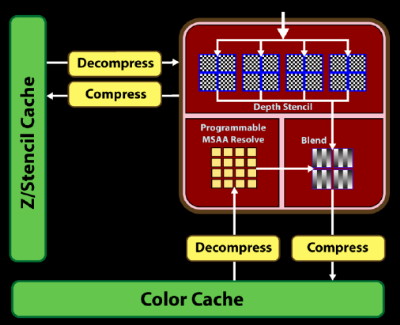 Avec le RV770, AMD introduit de nouveaux ROPs, et indique avoir corrigé le problème, encore une fois sans le détailler. Qui plus est, AMD double les débits de ses ROPs avec antialiasing, en FP16 et en Z-only. Si leur nombre reste à 16 ils gagnent donc nettement en capacité. Enfin, et c'est une surprise pour nous, AMD abandonne le ring bus tant vanté avec les précédentes générations. Si le ring bus est une solution très élégante, il est beaucoup plus gourmand en transistors qu'un contrôleur mémoire classique, tout en n'apportant en pratique que peu de gains. Du coup il passe à la trappe et AMD revient à un système plus simple dont le rendement a cependant été bien travaillé. Le bus mémoire externe, lui, ne bouge pas et reste de 4x 64 bits soit 256 bits. Page 4 - AMD premier sur la GDDR5 AMD premier sur la GDDR5AMD dispose d'un avantage stratégique sur Nvidia au niveau du support des nouvelles mémoires puisque le président du comité du JEDEC en charge du développement des mémoires DRAM est un de ses employés : Joe Macri. Il n'est donc pas étonnant de voir AMD arriver le premier sur le marché avec un produit qui embarque ce nouveau type de mémoire.  Joe Macri est Director of Technology chez AMD et accessoirement président du comité JEDEC qui s'occupe de définir les standards de mémoire DRAM. Mais qu'apporte cette GDDR5 ? La même chose que plus ou moins chaque nouveau type de mémoire : une consommation plus réduite et une montée en fréquence facilitée. La tension baisse et la fréquence peut être fortement réduite très facilement, ce qui permet d'économiser quelques watts. Mais pour des cartes haut de gamme l'intérêt principal n'est pas là. L'augmentation de la fréquence est par contre directement bénéfique puisqu'elle entraîne une bande passante plus élevée qui permet de laisser respirer le GPU plus librement, surtout quand l'antialiasing est utilisé. Pour permettre la montée en fréquence, tout d'abord on reste sur un prefetch de type 8n, comme sur la GDDR4 et contrairement au prefetch 4n avec la GDDR3. Cela signifie que plus de cellules mémoire fonctionnent en parallèle et par conséquent, à fréquence identique la bande passante augmente. La même opération avait eu lieu avec le passage à la DDR et puis à la DDR-2 Les DDR, DDR2, GDDR3, GDDR4 et GDDR5 envoient toutes 2 bits par cycle, sur les fronts montants et descendants. La différence est que les mémoires qui utilisent un plus gros prefetch peuvent augmenter leur débit d'envoi des données sans pousser trop la fréquence des banques mémoire. La principale nouveauté introduite par la mémoire GDDR5 est de diviser la fréquence d'envoi des commandes et des adresses par 2 par rapport à la fréquence de transfert des données, tout en modifiant les protocoles de communication pour avoir assez de marge de progression. Autre petit détail intéressant, la mémoire dispose d'un dispositif de détection des erreurs, elle peut même d'elle-même, en cas d'erreur, décider de recalibrer ses fréquences qui pourraient ne plus être parfaitement synchronisées. Ceci devrait laisser plus de marge d'overclocking.   Enfin, à terme elle permettra de baisser les coûts des cartes graphiques en permettant d'en simplifier le PCB. Puisque sa tolérance est plus large, il n'y a plus besoin d'utiliser des traces complexes. Vous pouvez observer la différence entre les traces de la mémoire GDDR3 à gauche et celles de la mémoire GDDR5 à droite. Page 5 - Performances Pixel, Vertex et Geometry Shaders Performances Pixel ShaderNous avons testé 2 shaders d'éclairage relativement simples qui représentent un bon compromis entre des débits théoriques et pratiques :  La GeForce GTX 280 est ici la plus véloce, mais la Radeon HD 4870 affiche un gain énorme par rapport à la génération précédente. Performances Vertex ShaderNous avons testé les performances en T&L, VS 1.1, VS 2.0 et VS 3.0 dans RightMark : 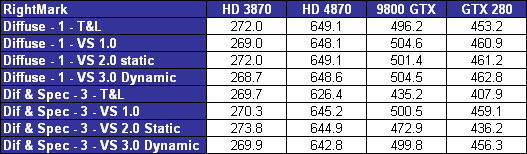 L'architecture unifiée permet aux GPUs récents d'attribuer toutes les ressources au traitement des vertex shader, ce qui entraîne un gain qui peut être conséquent. Il pourrait d'ailleurs être plus important mais est limité par le débit en triangle des GPUs qui sur toutes les GeForce testées ici est de 1 triangle par cycle. Par contre il est de 0.5 par cycle pour la Radeon HD 3870, alors qu'il était de 1 par cycle sur la Radeon HD 2900 XT, débit auquel la Radeon HD 4870 revient. La fréquence plus élevée de cette dernière joue donc ici en son avantage et fait de ce GPU le plus puissant que nous ayons pu avoir entre nos mains en matière de traitement géométrique (simple). Performances Geometry ShaderContrairement à Nvidia, AMD a intégré un cache généralisé pour les lectures/écritures en mémoire à partir du shader core. Celui-ci peut être utilisé d'une manière classique pour le Stream Output qui consiste, comme le requiert DirectX 10 à pouvoir écrire les données qui sortent du shader core sans passer par les ROPs. Il permet également de virtualiser les registres généraux qui peuvent ainsi être illimités. Une autre utilité est d'utiliser la mémoire vidéo à travers ce cache pour stocker temporairement la masse potentiellement énorme de données créées par les Geometry Shaders lors d'amplification de la géométrie sans quoi les unités de calcul pourraient être bloquées par manque de mémoire pour stocker ces nouvelles données. Nvidia prend le problème dans l'autre sens et au lieu de proposer une mémoire registres étendue, réduit le nombre d'éléments traités en parallèle à un nombre qui permette toujours d'avoir assez de mémoire dans le GPU pour stocker les nouvelles données. Autrement dit au lieu de pouvoir utiliser 128 ou 240 processeurs pour traiter un geometry shader, si Nvidia détecte qu'il peut y avoir un problème ce nombre doit être réduit. Nous ne savons pas exactement à quel point Nvidia doit réduire le traitement en parallèle, mais il est évident qu'il y a là une grosse différence entre Nvidia et AMD, à l'avantage de ce dernier, même si les développeurs font attention à ne pas utiliser de cas problématique. Pour compenser cela, avec les GeForce GTX 200, Nvidia a augmenté fortement la taille de son cache interne en sortie des geometry shaders : x6. AMD a également augmenté la taille de ce cache puisqu'il est nettement plus efficace de garder le tout sur le GPU au lieu de passer par la mémoire vidéo. Nous avons observé les performances à travers une démo de tesselation à base de geometry shader fournie par AMD au lancement des Radeon HD 2900 XT : 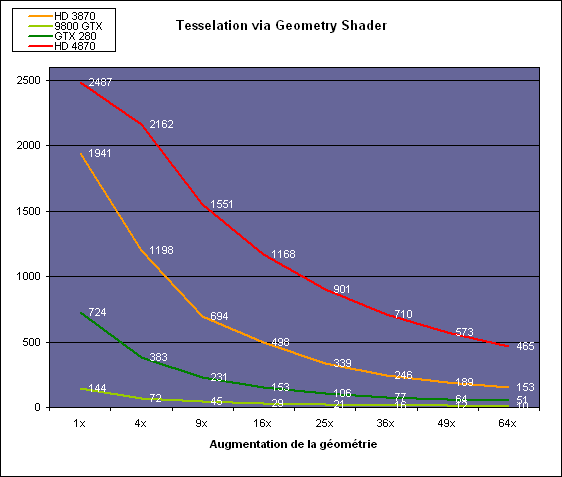 Comme vous pouvez le constater, même si les GeForce GTX 200 améliorent grandement les performances par rapport aux GeForce 8 et 9, les Radeon restent nettement devant. Nvidia indique avoir augmenté son cache en correspondance avec ce dont les développeurs utilisent et vont utiliser à moyen terme. De son côté AMD précise avoir implémenté un "fast path" pour l'amplification géométrique. En plus de cela les Radeon HD 4800 conservent bien entendu l'unité de tesselation, même si celle-ci n'est toujours utilisée par aucun jeu Page 6 - Performances Texturing et ROPs Performances accès aux texturesNous avons mesuré les performances lors de l'accès à des textures de différents formats en filtrage bilinéaire. Nous avons conservé les résultats en 32 bits classique (8x INT8), en 64 bits "HDR" (4x FP16) et en 128 bits (4x FP32). Nous avons ajouté pour information les performances en 32 bits RGB9E5, un nouveau format HDR introduit par DirectX 10 qui permet de stocker des textures HDR en 32 bits avec quelques compromis. Ces tests ont été réalisés avec un outil fourni par nos confrères et amis de Beyond 3D .  Vous remarquerez la différence évidente entre la GeForce 8800 Ultra et la GeForce 9800 GTX capable de filtrer les textures 32 bits 2x plus rapidement grâce à la présence de plus d'unités d'adressage. La GeForce GTX 280 est nettement devant la GeForce 9800 GTX alors qui si nous regardons les débits théoriques, ils sont très proches avec respectivement 43.2 GTexels/s et 48.2 GTexels/s. Autrement dit, Nvidia a bel et bien amélioré le rendement de ses unités de texturing puisque nous passons d'un rendement de 78% à 98%. Pas mal. Du côté de la Radeon HD 4870, plusieurs choses sont à noter. Premièrement alors que son débit maximal est de 30 GTexels, nous n'en obtenons que 24. La raison est que le RV770 ne dispose que de 32 interpolateurs qui ne peuvent donc pas alimenter les 40 unités de texturing quand celles-ci se basent sur des adresses interpolées. Ensuite, si le filtrage des textures RGB9E5 reste effectué à pleine vitesse, celui des textures FP16 (HDR 64 bits) voit, lui, son débit divisé par 2 et cette fois nous pouvons mesurer le débit maximal. S'il reste supérieur à celui de la Radeon HD 3870, il faut garder en tête que celle-ci ne dispose que de 16 unités de texturing, contre 40 pour la Radeon HD 4870. Compte tenu du nombre d'unités de texturing et du nombre d'interpolateurs, nous obtenons 100% des débits théoriques, ce qui est surprenant et démontre de l'effort apporté au rendement de ces unités. Performances des ROPsLe GeForce GTX 280 dispose de 32 ROPs, contre 24 pour le GeForce 8800 Ultra et 16 pour les GeForce 9800 GTX et les Radeon HD 3870 et 4870. Pour rappel les ROPs sont les unités chargées des derniers traitements à effectuer sur les pixels (mélange des couleurs, antialiasing, compression des données et écriture de celles-ci en mémoire). La taille du bus mémoire est en partie liée au nombre de ROPs. Pour rappel, non content d'en avoir augmenté le nombre, Nvidia en a amélioré l'efficacité sur GeForce 8 lors des passes qui n'écrivent que la valeur Z en mémoire. Sans antialiasing, AMD est très loin en terme de débit à ce niveau :  Les GeForce sont ici très véloces, mais avec la Radeon HD 4870, AMD a doublé les débits dès que l'antialiasing est activé. Si les GeForce voient leurs performances plonger avec l'antialiasing 8x, ce n'est pas le cas des Radeon. Nous avons ensuite, ici aussi à l'aide d'un outil fourni par nos confrères de Beyond 3D , testé le débit des ROPs quand ils écrivent des pixels en mémoire, d'une manière classique tout d'abord et ensuite avec mélange des couleurs (blending), notamment utilisé pour les effets de transparence.  Sur GeForce et sur la Radeon HD 3870, les résultats sont logiques et collent au nombre de ROPs. Le 64 bits est 2x plus lent que le 32 bits et le 128 bits encore 2x plus lent. Quant au 32 bits "FP10", il est géré de la même manière que le FP16 et donc ne profite malheureusement pas d'un débit plus élevé, ce qui n'est pas le cas sur la Radeon HD 4870, qui peut le traiter plus rapidement, ce qui est une bonne nouvelle. Par contre étrangement, alors que le FP32 semble être 2x plus rapide, le FP16 est un petit peu plus lent. Il s'agit probablement d'un problème d'une erreur liée aux drivers.  Une fois le blending utilisé, nous pouvons constater un net gain pour la GeForce GTX 280 qui profite d'une implémentation à pleine vitesse de cette fonction, contrairement à la GeForce 9800 GTX. Avec le Radeon HD 4800, il semblerait qu'AMD ait modifié les capacités de blending de ses ROPs. Ainsi, si le Radeon HD 3800 est capable de 8 blending FP16 par cycle et de 2 blending FP32, la Radeon HD 4800 n'est capable que de 4 blending FP16 par cycle mais de 4 blending FP32 également. AMD aurait donc placé une unité de blending FP32 (et donc capable de blending en FP16 aussi) par bloc de 4 ROPs au lieu de 2 unités FP16 utilisées pour gérer (lentement) le FP32. Page 7 - Performances Branchements Performances branchementsL'une des principales nouveautés qui a été introduite avec l'évolution de la programmabilité des GPUs est le branchement dynamique. Cela permet de rendre l'écriture de certains shaders plus naturelle et d'augmenter l'efficacité d'autres shaders en évitant de calculer une partie de ceux-ci sur les pixels qui n'en ont pas besoin. Par exemple pourquoi appliquer le filtrage très coûteux de l'adoucissement de bordure d'une ombre si le pixel est au milieu de l'ombre ? Un branchement dynamique permet de détecter si le pixel en a besoin ou pas. 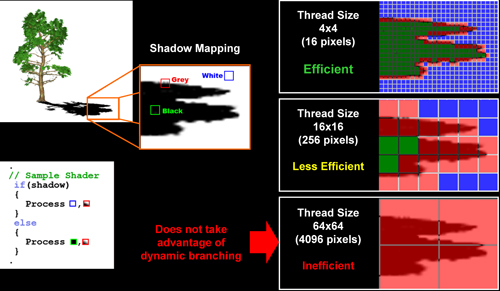 Mais tout n'est pas si rose puisque ceux-ci ne sont efficaces que dans des cas bien précis. Les branchements ont une réputation d'être difficile à gérer, c'est particulièrement le cas dans les CPUs qui doivent prédire le résultat du branchement à l'avance pour masquer la latence du calcul de celui-ci. Dans un GPU, les pixels sont traités par groupes de dizaines, de centaines voire de milliers de pixels, ce qui permet de masquer automatiquement cette latence. Le problème des CPUs n'existe donc pas réellement. Par contre un autre problème se pose. Les GPUs exécutent leurs instructions sur des groupes d'éléments ou threads. Lors d'un branchement, tous les threads doivent prendre la même branche sans quoi les 2 branches doivent être calculées pour tous, avec des masques pour n'écrire que le résultat de la branche requise. Dans le cas des GeForce 8, 9 et GTX 200, le GPU travaille sur des groupes de 16 ou 32 threads (vertices, pixels etc.). Pourquoi ces 2 possibilités ? Tout d'abord ce sont des unités SIMT 8-way qui sont utilisées. Il faut donc des groupes d'au moins 8 threads. Ensuite rappelez-vous que les unités de calcul sont double pumped et fonctionnent à la fréquence double du scheduler. Il ne peut donc envoyer une commande qu'un cycle sur 2 du point de vue des unités de calcul. Travailler sur des groupes de 16 threads permet aux unités de calcul d'avoir assez de travail et de ne pas attendre un scheduler plus lent qu'elles. Enfin, travailler sur 32 threads autorise la dual issue. Un coup le scheduler va envoyer une instruction à l'unité SIMT 8-way, un autre coup il va envoyer une instruction aux unités spéciales. Il peut gérer les 2 en alternance et à plein débit grâce aux groupes de 32 threads. Nvidia peut configurer ses GPUs pour 16 ou 32 threads. Dans le premier cas, les performances en branchement sont améliorées, dans le second cas la puissance de calcul est améliorée grâce à la dual issue. Les groupes de 16 sont activés pour les vertex et geometry shader alors que les groupes de 32 le sont pour les pixel shaders et pour CUDA. Nous avons développé un petit test qui nous permet de modifier la granularité du branchement, c'est-à-dire le nombre moyen, dans notre exemple, de pixels consécutifs qui vont prendre une même branche. Nous spécifions la branche à prendre par colonne de pixels, une colonne sur 2 doit afficher un shader complexe et l'autre peut passer cette partie du rendu. Des triangles de taille moyenne en mouvement sont affichés à l'écran et traversent ces zones qui utilisent différentes branches, ce qui implique que tant les triangles et leur position que la taille de la colonne influent sur l'efficacité du branchement ce qui est proche d'une situation réelle. 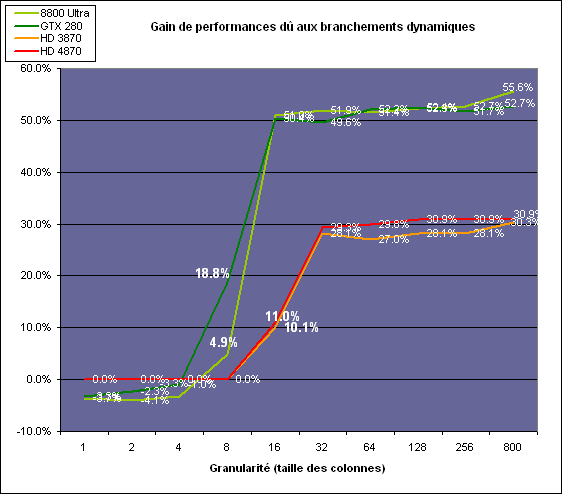 Avec des colonnes étroites, les GPUs ne peuvent pas profiter du branchement pour éviter la partie complexe sur la moitié des pixels, mais par contre doivent traiter les instructions de branchement, ce qui fait baisser légèrement les performances au lieu de les augmenter. Tout du moins sur les GeForce 8, 9 et GTX 280. Tous ces GPUs disposent d'une unité dédiée aux branchements qui travaille en parallèle et masque le coût des instructions de branchement. Les Radeon semblent cependant les seules à masquer complètement la latence des branchements. La taille des groupes de pixels sur le GeForce 8800 est de 32 contre 64 pour le Radeon HD3870 et 4870, ce qui permet aux puces de Nvidia de prendre les devants. Nous avons mis en évidence une différence surprenante entre le GeForce 9800 GTX et le GeForce GTX 280 qui avec une colonne de 8 pixels est beaucoup plus efficace. Il est probable que le découpage des triangles en pixels se fassent de manière à mieux grouper les pixels proches (et donc susceptibles de prendre la même branche) entre eux, ce qui est bénéfique dans ce cas. Page 8 - Les Radeon HD 4800 Les Radeon HD 4800Pour ce test, nous avons reçu des Radeon HD 4870 et 4850 de marques Force3D et PowerColor, respectivement. Il s'agit cependant de cartes de référence sur lesquelles ont été posées (à la va-vite) des autocollants au nom de la marque. La première devrait se trouver rapidement au prix de 250 alors que la seconde est déjà disponible à 160. La Radeon HD 4870 reçoit un système de refroidissement double slot et est équipée de 512 Mo de mémoire GDDR5 1.8 GHz Qimonda.    La Radeon HD 4850 se contente d'un système de refroidissement simple slot. Elle est équipée elle aussi de 512 Mo, mais cette fois de GDDR3 à près de 1 GHz.    La Radeon HD 4870 a besoin de 2 connecteurs d'alimentation 6 broches alors qu'un seul suffit pour la Radeon HD 4850 :  Page 9 - Réaction de Nvidia Réaction de NvidiaNvidia n'a pas tardé à réagir face à ces Radeon HD 4800 et a dévoilé officiellement une GeForce GTX v2. Celle-ci est destinée à remplacer l'ancienne et est équipée d'un nouveau GPU, le G92b. Similaire au G92, il a l'avantage d'être fabriqué en 55 nanomètres au lieu de 65, et donc d'être plus petit, soit moins cher, moins gourmand en Watts. Qui plus est il peut potentiellement, à priori, monter un petit peu plus facilement en fréquence. Du coup Nvidia passe les fréquences de 675/1688 sur la GeForce 9800 GTX à 738/1836 sur la nouvelle version, soit une augmentation de 9%. La mémoire, par contre, ne bouge pas et reste à 1100 MHz, tout comme le design de la carte qui est parfaitement identique :  Le passage à la finesse de gravure de 55 nanomètres réduit la taille du G92 de 324 mm² à 264 mm², soit la même taille à peu de chose près que le RV770.  PhysXNvidia ne s'est pas contenté de préannoncer cette carte pour contrer les Radeon et a également sorti aussi vite que possible la première version de son driver PhysX. Pour rappel, suite au rachat d'Ageia, Nvidia a converti le module "hardware" (destiné au PPU) de l'API PhysX en version CUDA de manière à pouvoir l'accélérer via les GPUs GeForce 8, 9 et GTX. Attention, ce n'est pas l'API PhysX que Nvidia a converti et accélère à travers ses GPUs mais uniquement ce module. Actuellement l'accélération est fonctionnelle dans les maps spéciales PhysX d'UT3 et dans le test CPU2 de 3DMark Vantage. Un argument de poids selon Nvidia en faveur de ses GPUs. Reste que Nvidia ne veut accélérer de cette manière que les jeux qui pouvaient profiter du PPU et ceux-ci sont très peu nombreux et très limités. S'il semble évident que vu le parc énorme de GeForce compatibles déjà prêt, les développeurs de jeux vont maintenant s'y intéresser, il reste à voir quand ces jeux qui utiliseront l'accélération, à travers les GPUs, de ce module de l'API PhysX débarqueront. Page 10 - DirectX 10, GPGPU, Vidéo HD DirectX 10.1Avec les Radeon HD 4870, AMD supporte bien entendu toujours DirectX 10.1. Nvidia pour sa part continue de l'ignorer et ne semble pas pressé de faire les modifications matérielles nécessaires à son support. Par contre il y a un détail qu'il est intéressant de préciser. Un des intérêts principaux de DirectX 10.1 est d'améliorer le MSAA readback soit la possibilité pour le GPU de travailler sur les buffers qui reçoivent un antialiasing de type multisampling, de manière à pouvoir appliquer facilement de l'antialiasing avec des techniques de rendu complexes. DirectX 10.1 permet notamment au GPU d'avoir accès au buffer de profondeur. Et cela, les GeForce 8, 9 et GTX en sont capables aussi, bien que Nvidia ne puisse pas l'exposer puisque DirectX 10 a abandonné les caps. Nvidia peut malgré tout l'implémenter dans ses drivers et travailler avec les développeurs qui comptent l'utiliser de manière à ce que cela fonctionne aussi en DirectX 10 sur GeForce. Notez que c'est également vrai pour DirectX 9 puisque c'est via cette technologie que Nvidia est parvenu à implémenter le support du MSAA dans S.T.A.L.K.E.R. GPGPUCe n'est plus un secret, les GPUs sont capables de bien plus que de calculer des images tridimensionnelles. AMD a apporté quelques petites améliorations qui permettent de mieux exploiter et plus facilement la puissance de calcul du Radeon HD 4800. Tout d'abord, la capacité (non cachée) d'écrire et de lire n'importe où en mémoire a gagné en performances. Mais surtout, AMD introduit un cache local partagé spécifique à chacun des multiprocesseurs du GPU. Ce cache de 16 Ko permet aux différents threads d'un même groupe de communiquer entre eux. Cela permet d'optimiser fortement certains algorithmes. Par ailleurs un cache global partagé de 16 Ko permet aux threads de différents multiprocesseurs de communiquer eux aussi entre eux. Les plus assidus auront remarqué que le cache local est similaire à la mémoire partagée de 16 Ko elle aussi spécifique à chaque multiprocesseur sur les GeForce 8, 9 et GTX. L'apparition de ce cache chez AMD ne rendrait-elle pas possible de porter CUDA sur Radeon ? Nous espérons que cela puisse être le cas, puisque CUDA est nettement plus efficace et mieux documenté que les solutions actuellement proposées par AMD. Vidéo HDLes Radeon HD 4800 embarquent un UVD revu pour la lecture des vidéos HD. Cette version 2 prend ainsi en charge l'accélération du MPEG2 HD, ce qui n'était pas le cas avant, ainsi que des modes Picture-in-Picture définis par le format Bluray via le support du dual stream. AMD a également mis à jour la gestion du HDMI qui passe en version 1.3 et permet donc de supporter les flux audio 7.1 et les encodages Dolby TrueHD et DTS HD, alors que toutes les autres solutions sont limitées au HDMI 1.2 et donc au son 5.1. En réponse aux annonces de Nvidia autour de l'accélération de l'encodage des vidéos via CUDA, AMD met en avant l'AVT (Accelerated Video Transcoding) qui est une interface présente (ou qui le sera bientôt) dans les drivers qui permet à toute application qui le désire d'exploiter le GPU pour l'encodage des vidéos en H.264 ou en MPEG2. Power Director 7 de Cyberlink sera la première application à exploiter l'AVT. Pour rappel, du côté de Nvidia il s'agit d'un développeur tiers qui a développé un logiciel d'encodage payant. Page 11 - Spécifications, consommation, le test Les spécifications 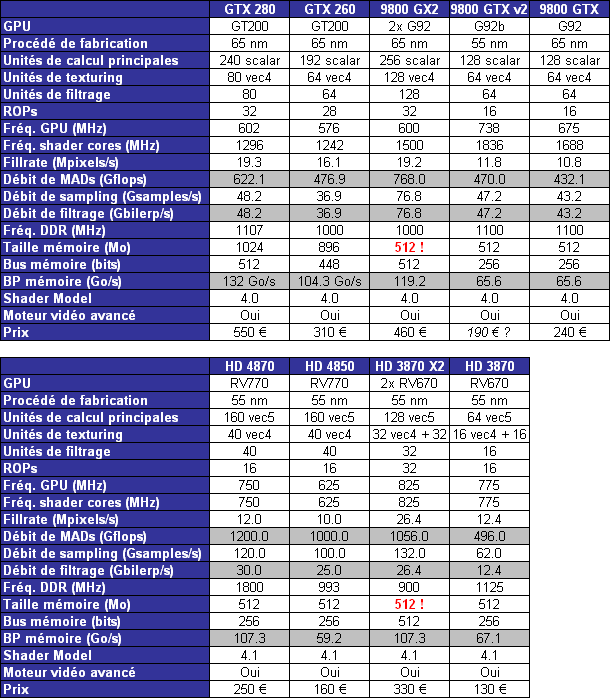 Notez une fois de plus que les cartes graphiques bi-GPU testées ici sont l'équivalent d'une carte 512 Mo et pas d'une carte 1 Go telle que la GeForce GTX 280 ! AMD a mis en place une redondance plutôt efficace qui lui permet de conserver toutes les unités actives sur toutes les Radeon HD 4800, contrairement à Nvidia qui doit désactiver des blocs entiers de son GPUs pour ne pas avoir à jeter des GPUs qui présentent des défauts. Consommation et bruitNous avons mesuré la consommation des différentes cartes. Ces données sont obtenues à partir des mesures effectuées à la sortie de la prise de courant : il s'agit donc de la consommation totale de l'alimentation de la machine, ici une Cooler Master Real Power M1000 (1000 watts). 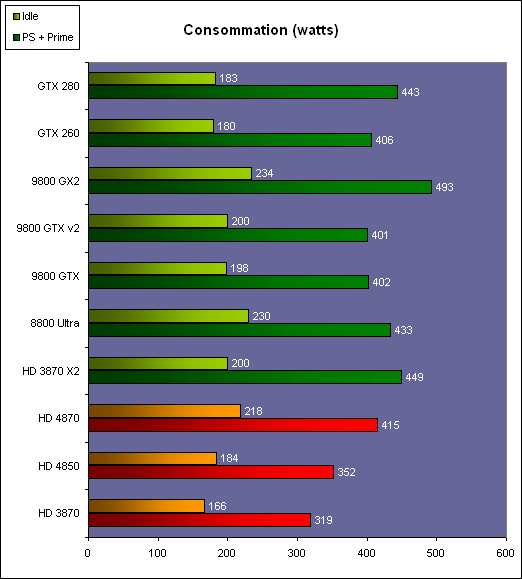 La consommation des Radeon HD 4800 est revue à la hausse par rapport à la Radeon HD 3870, ce qui n'a rien d'étonnant. Si elle reste maîtrisée sur la Radeon HD 4850, elle explose, surtout au repos, sur la Radeon HD 4870. Etant donné qu'AMD nous a indiqué avoir introduit de nouvelles fonctionnalités destinées à réduire la consommation, nous ne pouvons qu'espérer qu'elles ne sont pas encore activées et qu'un futur driver corrigera cela. Au niveau du bruit, la Radeon HD 4850 est similaire à la Radeon HD 3850 et reste donc relativement silencieuse, comme celle-ci. Par contre elle a tendance à atteindre de hautes températures, même au repos. Nous avons noté 80°C au repos de notre côté. La Radeon HD 4870 est, elle, mieux refroidie et reste elle aussi silencieuse. Quant à la nouvelle GeForce 9800 GTX elle affiche une consommation similaire à l'ancienne. La légère augmentation de la fréquence annule donc le gain en terme de consommation lié au passage à la fabrication en 55 nanomètres. Au niveau du bruit, la GeForce 9800 GTX v2 est identique à la GeForce 9800 GTX, c'est-à-dire qu'elle reste discrète au repos mais est plus bruyante qu'une GeForce 8800 GTX ou Ultra en charge, le ventilateur tournant visiblement un peu plus vite ou tout du moins le flux d'air se fait entendre beaucoup plus. Le testPour ce test, nous avons fait appel à 10 jeux dont 4 supportent DirectX 10. Les tests ont été exécutés en 1920x1200 uniquement, parce qu'une résolution plus faible n'est en général pas adaptée à un produit haut de gamme. DirectX 10, le filtrage anisotrope ainsi que le HDR ont été activés dans tous les cas où ils sont disponibles dans le jeu. Enfin, le transparency / adaptive antialiasing était activé en mode multisampling. Toutes les mises à jour pour Windows Vista disponibles à ce jour en plus du SP1 étaient installées. ConfigurationIntel Core 2 Extreme QX9770 Asus Striker II 4 Go DDR3 1066 Windows Vista SP1 Forceware 177.34 Catalyst 8.501.1 (= 8.6 hotfix) Page 12 - Enemy Territory : Quake Wars Enemy Territory : Quake Wars  Si Quake Wars est basé sur le moteur de Doom 3, celui-ci a subi quelques évolutions telles que le megatexturing qui permet de faciliter le travail des artistes mais entraîne un surcoût au niveau du "décodage" et de l'accès aux megatextures. Quake Wars est donc un petit peu plus gourmand que Doom 3 et Quake 4. Nous avons enregistré une démo lors d'une partie contre 8 bots. L'intelligence artificielle n'étant pas reproduite lors du timedemo, elle ne limite pas les résultats qui sont donc moins limités par le CPU qu'en situation réelle, tout du moins contre des bots. Toutes les options sont poussées au maximum dans le jeu, ce qui inclus un filtrage anisotrope 16x. Le patch 1.4 est utilisé. 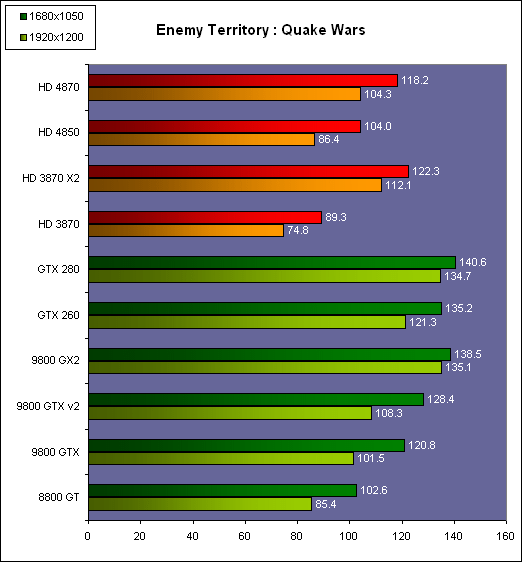 Sans antialiasing, dans ce premier jeu testé, les GeForce dominent.  La Radeon HD 4850 affiche un gain très important par rapport à la Radeon HD 3870 une fois que l'antialiasing est activé et passe du coup devant la GeForce 9800 GTX, mais la v2 de cette carte repasse à son tour légèrement devant. La Radeon HD 4870 se rapproche de la GeForce GTX 260 en 1920x1200. Page 13 - Half Life 2 Episode 2 Half Life 2 Episode 2  Toujours basé sur le Source Engine, Half Life 2 Episode 2 n'apporte pas de réelle nouveauté sur le plan technique et se contente de mieux utiliser et d'utiliser plus souvent ce dont est capable le moteur, ce qui rend le jeu plus gourmand que ses prédécesseurs. Nous exécutons une démo et toutes les options du jeu sont poussées au maximum, y compris le filtrage anisotrope qui est donc en 16x. 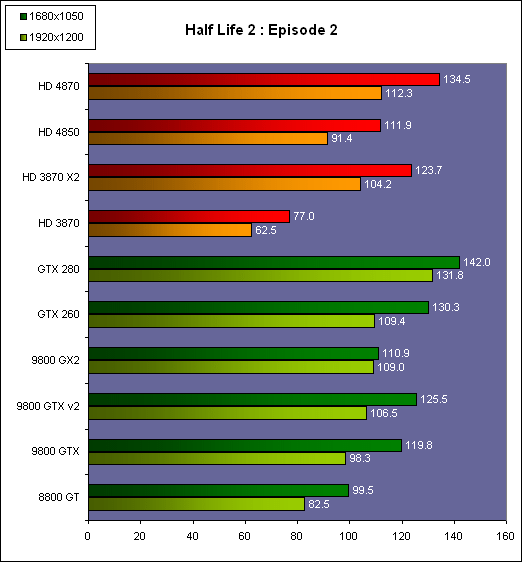 La Radeon HD 4870 dépasse ici la GeForce GTX 260. 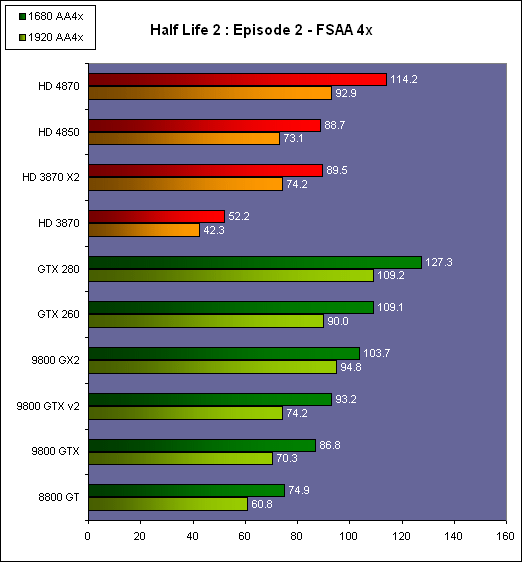 Sous Half Life 2 Episode 2, le gain le plus important est également avec antialiasing activé. Il est de plus de 70% par rapport à la Radeon HD 3870 ! La Radeon HD 4850 se place ainsi entre les 9800 GTX 1 et 2 alors que la Radeon HD 4870 dépasse également la GeForce GTX 260. Page 14 - S.T.A.L.K.E.R. S.T.A.L.K.E.R.  Nous effectuons un déplacement toujours identique et mesurons le framerate avec fraps. Nous testons le jeu avec un niveau de qualité élevé, éclairage dynamique complet, détails maximums (avec filtrage anisotrope 16x) et ombres des herbes. S.T.A.L.K.E.R. utilise un moteur à base de rendu différé ce qui est fondamentalement incompatible avec du MSAA classique, ce qui rends l'utilisation de l'antialiasing impossible, tout du moins c'est ce que nous pensions, Nvidia ayant fini par trouver une astuce pour l'appliquer malgré tout ! Le patch 1.00006 est utilisé. 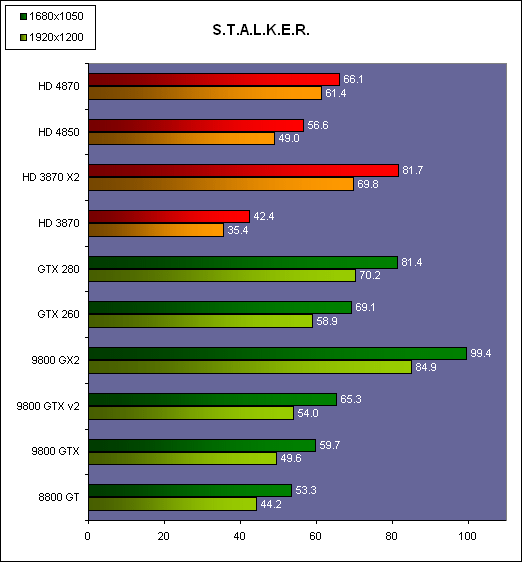 La Radeon HD 4850 fait jeu égal avec la GeForce 9800 GTX alors que la GeForce 9800 GTX v2 voit ses performances augmenter dans de même proportions que ses fréquences GPU et gagne donc 9%. 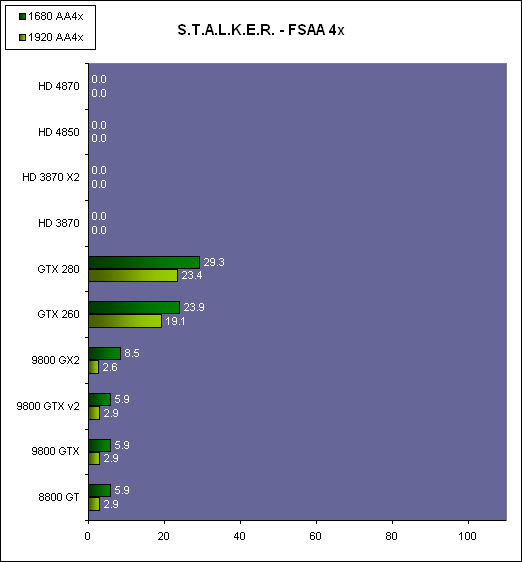 Les Radeon ne permettent toujours pas d'utiliser l'antialiasing. Page 15 - Rainbow Six : Vegas Rainbow Six : Vegas  Premier jeu PC basé sur l'Unreal Engine 3.0, Rainbow Six : Vegas reste un jeu très gourmand. Nous mesurons les performances sur la scène d'introduction. Le mode HDR est activé, et est plus ou moins obligatoire sans quoi le banding est très présent. Les ombres sont réglées sur "bas", les modes supérieurs entraînant une trop forte baisse de performances à certains endroits. 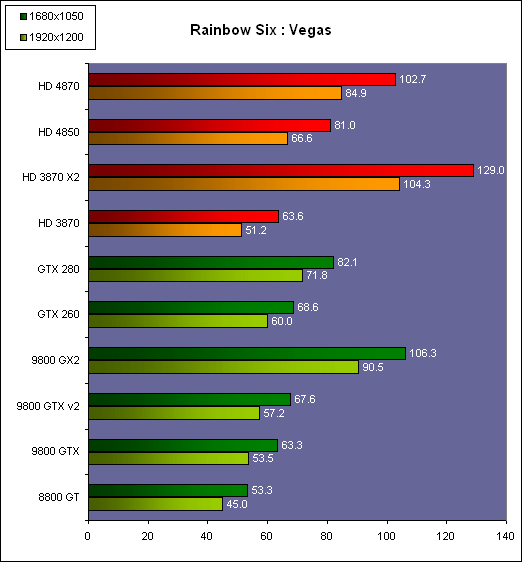 Portage de la Xbox 360, le jeu semble naturellement bien aimer les Radeon HD qui partagent une architecture similaire à celle de la puce graphique de la console. C'est donc la Radeon HD 3870 X2 qui domine. La Radeon HD 4870 devance ici elle aussi la GeForce GTX 280. La Radeon HD 4850 parvient même à dépasser de 10% la nouvelle GeForce GTX 260 sans antialiasing.  La Radeon HD 4850 affiche un gain une nouvelle fois plus important avec antialiasing que sans et se place facilement devant les GeForce 9800 GTX. Rappelons que le jeu ne supporte pas l'antialiasing mais que Nvidia et AMD l'ont implémenté dans leurs drivers. Page 16 - Oblivion Oblivion  Nous effectuons un déplacement précisément défini afin qu'il soit toujours identique et que le test soit reproductible. Le HDR est bien entendu de la partie et les détails très élevés ont été sélectionnés.  Sans antialiasing, le gain apporté par la Radeon HD 4850 par rapport à la Radeon HD 3870 est contenu puisqu'il n'est que de 10%.  Il est un peu plus élevé avec antialiasing, bien qu'à la base les Radeon soient déjà étonnement performantes dans ce jeu avec ce mode, et dépasse ainsi la GeForce GTX 260. La Radeon HD 4870, elle, dépasse facilement la GeForce GTX 280. Page 17 - RaceDriver GRID RaceDriver GRID  Pour tester le dernier opus de Codemaster, nous réalisons un déplacement bien défini en mode qualité élevée. Il est basé sur une évolution du moteur de Colin McRae DIRT qui fait disparaître le côté usine à gaz. Le patch 1.1 est appliqué.  Dans ce jeu le gain est de plus de 50% par rapport à la précédente génération. Du coup la Radeon HD 4850 dépasse allégrement la GeForce 9800 GTX et se place juste devant la GeForce GTX 260.  Si la GeForce 9800 GTX v2 arrive au même niveau que la Radeon HD 4850 et que la GTX 260 sans antialiasing, avec ce filtre, elle reste derrière. Avec ou sans antialiasing, la Radeon HD 4870 domine. Page 18 - Bioshock Bioshock  Premier jeu basé sur l'Unreal Engine 3.0 à supporter DirectX 10, Bioshock est un jeu très réussi graphiquement et ce même en mode DirectX 9 alors qu'il est moins gourmand que Rainbow Six : Vegas. Nous effectuons un déplacement bien défini et toutes les options sont poussées au maximum, en mode DirectX 10. 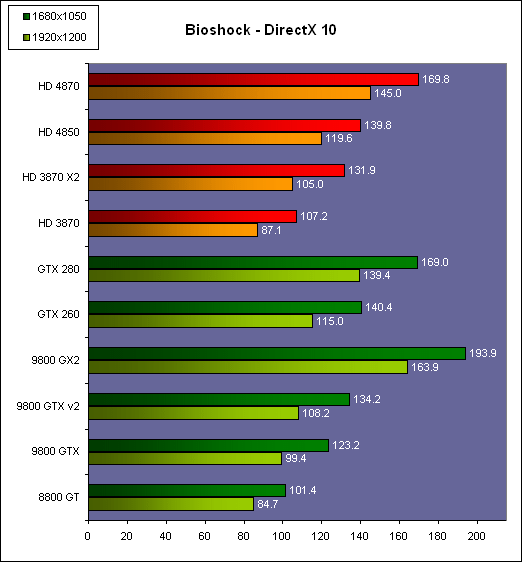 Avec un gain d'un peu plus de 35%, la Radeon HD 4850 parvient à devancer la GeForce GTX 260, tout du moins sans antialiasing puisque AMD ne permet toujours pas de l'activer en mode DirectX 10. Les 9% de plus affichés par la GeForce 9800 GTX v2 sont insuffisants pour rattraper la nouvelle Radeon. La Radeon HD 4870 termine pour sa part tout juste devant la GeForce GTX 280.  Page 19 - Company of Heroes Company of Heroes  Company of Heroes ayant reçu un patch DirectX 10 qui apporte un réel plus sur le plan graphique, nous avons décidé de l'ajouter à notre protocole de test. Toutes les options sont poussées à leur maximum. Nous exécutons le test intégré sur la version 1.72. 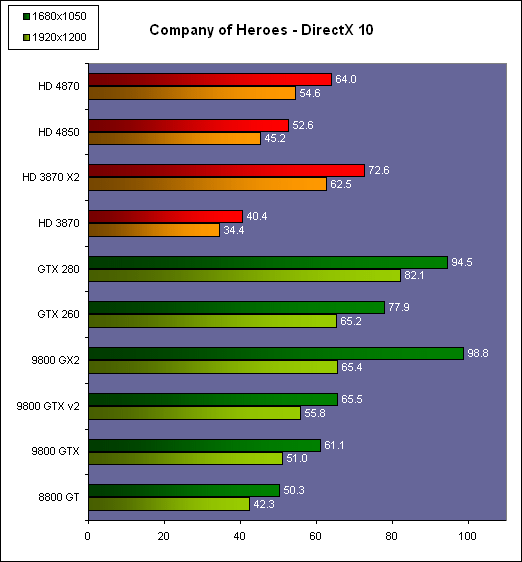 Sous ce jeu en mode DirectX 10 la puissance de calcul est très importante. La Radeon HD 4850 profite donc de sa puissance de calcul à la hausse avec un gain de 40% sans antialiasing. 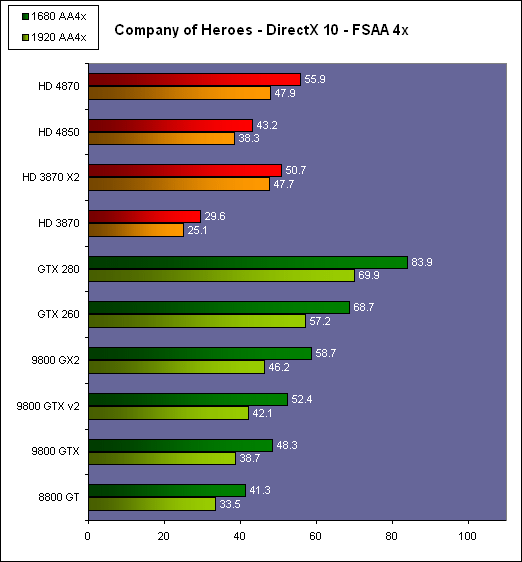 Le gain monte à 60% avec antialiasing. De quoi se rapprocher de la GeForce 9800 GTX, mais pas suffisant pour la devancer. La v2 prend donc les devants. Page 20 - World in Conflict World in Conflict  Très réussi visuellement et très gourmand, il était logique de voir World in Conflict joindre notre suite de tests. Nous exécutons le test interne avec le patch 1.0002. Toutes les options sont poussées au maximum ce qui inclus le mode DirectX 10 et le filtrage anisotrope 16x.  Pour une raison inconnue, les performances en 1680x1050 des Radeon sont limitées. 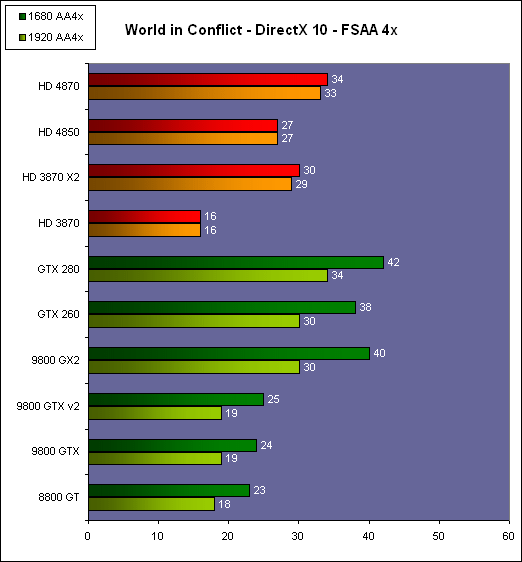 Avec près de 70% de gain avec antialiasing, la Radeon HD 4850 devance nettement la GeForce 9800 GTX, qui souffre, comme toutes les cartes Nvidia, beaucoup plus du manque de mémoire que les Radeon. Page 21 - Crysis Crysis  Jeu incontournable, Crysis a été testé avec son patch en version 1.21 (optimisé pour le multi-GPU). Nous exécutons notre propre démo enregistrée sur Harbor. Le test est effectué en mode "High" et en DirectX 10.  Si le succès de Crysis est plutôt mitigé, il reste le jeu le plus gourmand à l'heure actuelle, le jeu pour lequel nous avons besoin de plus de puissance graphique. Le gain est ici plus réduit avec "seulement" 20% sans antialiasing. La Radeon HD 4850 reste donc légèrement derrière la GeForce 9800 GTX sans ce filtre. 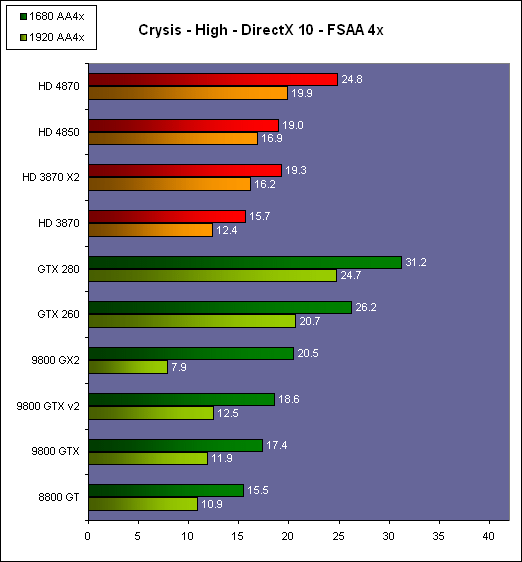 Elle mais passe par contre nettement devant avec puisque cette dernière est dépassée par la consommation mémoire de Crysis. La nouvelle GeForce 9800 GTX ne permet pas de revenir avec ce filtre. La Radeon HD 4870 n'arrive pas, ici, à atteindre la GeForce GTX 260. Page 22 - Récapitulatif des performances RécapitulatifBien que les résultats de chaque jeu aient tous un intérêt, nous avons calculé un indice de performances en se basant sur l'ensemble de résultats et en donnant le même poids à chacun des jeux. L'indice 100 a été attribué à la GeForce 9800 GTX en 1920x1200. 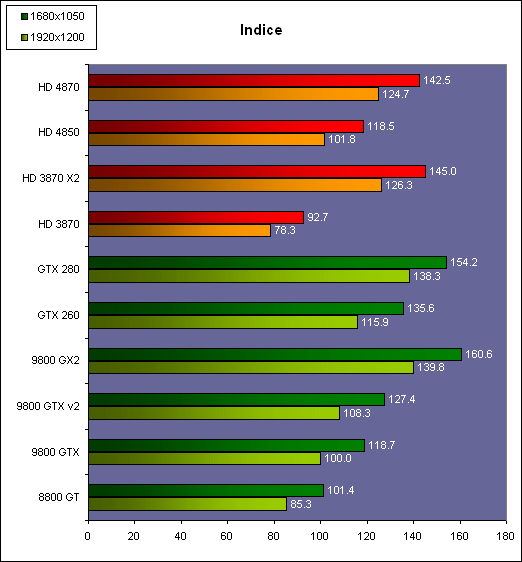 Sans antialiasing, la Radeon HD 4850 coiffe la GeForce 9800 GTX au poteau. La GeForce 9800 GTX v2 affiche cependant un gain moyen de 8.3% sur la première, ce qui est pas mal pour une augmentation des fréquences de 9% ! Du coup elle passe devant la Radeon HD 4850. Sa grande soeur, la Radeon HD 4870 n'a aucun mal à se défaire de la GeForce 9800 GTX v2 puisqu'elle devant même la GeForce GTX 260. 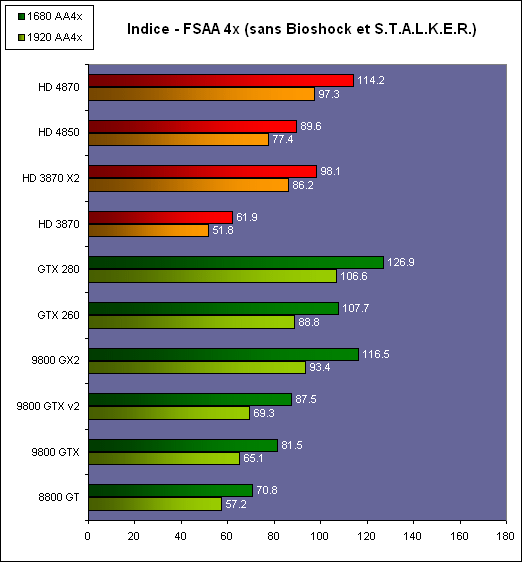 Avec antialiasing, la Radeon HD 4850 passe par contre devant, avec une avance de 18% sur la première GeForce 9800 GTX et de 11% sur la nouvelle version. Elle dépasse par ailleurs la Radeon HD 3870 X2, qui a souvent du mal avec ce filtre. La Radeon HD 4870 se rapproche, elle, de la GeForce GTX 280. Notez que pour la partie antialiasing (uniquement) les résultats obtenus sous Bioshock et S.T.A.L.K.E.R. ne sont pas pris en compte, les Radeon ne supportant pas ce filtre dans ces jeux. Vous pouvez cependant consulter le graphe qui les prend en compte ici. Page 23 - Conclusion ConclusionAvec les Radeon HD 4800, AMD nous a réservé une belle surprise ! Autant être clairs, nous ne nous attendions pas à un tel niveau de performances. En se focalisant sur l'optimisation de son architecture précédente, tant en terme de rendement qu'en terme de coût, AMD est parvenu à concevoir un GPU à l'efficacité redoutable.  Le RV770 qui anime ces Radeon HD 4800 est ainsi capable d'aller lutter avec le GT200 des GeForce GTX 200 alors qu'ils sont censés jouer dans des catégories très différentes, l'un étant plus de 2x plus gros que l'autre. Autant le GT200 nous a séduit au départ, autant force est de constater qu'AMD a fait nettement mieux en terme d'efficacité. Certes Nvidia a des objectifs plus ambitieux et pressés autour du GPGPU, ce qui induit des influences technologiques différentes, mais ce n'est pas suffisant pour nous empêcher de penser, après coup, que Nvidia aurait pu ou dû faire mieux. La Radeon HD 4850 lancée initialement à 160 se trouve déjà à 140 et n'a à ce prix aucune concurrence de la part de Nvidia qui a visiblement été aussi surpris que nous par ce RV770. La GeForce 9800 GTX v2 qui est une tentative de réponse n'arrivera que vers la mi juillet et à un prix plus élevé puisqu'il est supposé être de 180 à 190 .  La Radeon HD 4870, qui débarque à 250 , profite de la bande passante élevée amenée par la mémoire GDDR5 pour surpasser la GeForce GTX 260 et même pour régulièrement taquiner la GeForce GTX 280 qui coûte plus du double. Pour qu'elles restent compétitives, Nvidia va devoir revoir rapidement sa position tarifaire, ce qui n'est pas simple compte tenu des coûts de production élevés du GT200 et des cartes qui l'embarquent. Bien entendu, Nvidia n'a pas tout perdu : le fabricant garde la première place en terme de performances absolues avec la GeForce GTX 280 et a pu démontrer être plus en avance qu'AMD sur le plan de la prise en charge de l'accélération, via ses GPUs, d'une API physique. D'autre part, les Radeon HD 4800 ne sont pas exemptes de défauts, avec une consommation étrangement beaucoup trop élevée au repos sur la Radeon HD 4870 par exemple. Mais ces petits détails ne changent rien au fait que nous avons affaire ici à un coup de maître incontestable de la part d'AMD. Copyright © 1997-2025 HardWare.fr. Tous droits réservés. |