
Les derniers contenus liés aux tags Nvidia et GPGPU
Afficher sous forme de : Titre | FluxGTC: Plus de détails sur le GK110
GTC: Tesla passe à Kepler avec les K10 et K20
GTC: Nsight évolue, s'ouvre à Linux et Mac OS
GTC: GTC 2012: la semaine du GPU computing
Nvidia GK110: 7 milliards de transistors à la GTC?

Nvidia lance les Quadro Pascal dont une GP100



Après deux premiers modèles lancés cet été, Nvidia vient de dévoiler toute une famille de Quadro de génération Pascal qui vont pousser vers le haut puissance de calcul et efficacité énergétique. Un lancement qui permet par ailleurs à Nvidia d'introduire le GPU GP100 et sa mémoire HBM2 sur une carte graphique.

Cet été, Nvidia avait débuté le renouvellement de sa gamme de cartes graphiques professionnelles avec l'introduction de deux nouvelles Quadro, les P6000 et P5000 respectivement basées sur les GPU Pascal GP102 (Titan X) et GP104 (GTX 1080). D'autres modèles étaient bien entendu au programme et viennent d'être dévoilés : les Quadro GP100, P4000, P2000, P1000, P600 et P400. En voici les spécifications :
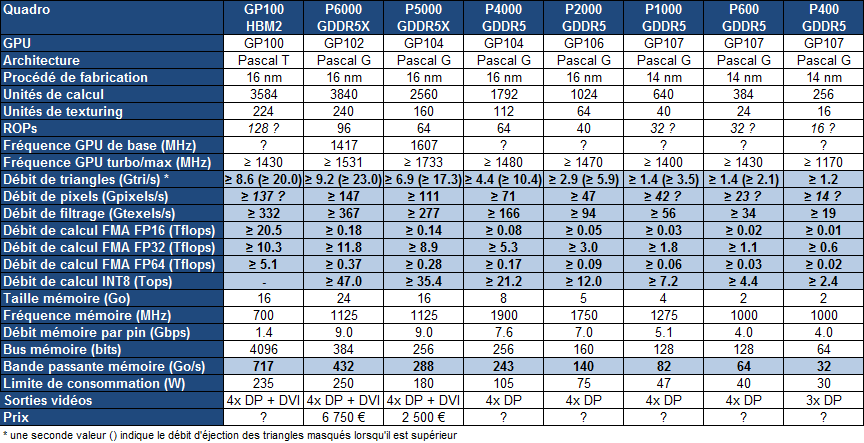
La Quadro GP100 est bien entendu la nouvelle venue la plus intéressante, mais avant d'en parler en plus de détails, intéressons-nous aux autres modèles de la famille que Nvidia positionne de la sorte :


La Quadro P6000, dont nous avions omis de parler à sa sortie, est basée sur un GPU GP102 complet et équipée de 24 Go de GDDR5X, contrairement à la Titan X qui embarquait le même GPU mais castré et avec "seulement" 12 Go de mémoire. La Quadro P6000 représente l'offre de Nvidia la plus élevée en terme de puissance de calcul en simple précision et de quantité de mémoire embarquée. Elle affiche une puissance brute 70% plus élevée que celle de la M6000 24 Go qu'elle remplace. Elle vise donc les applications de rendu les plus lourdes ou encore le GPGPU.
En-dessous, la Quadro P5000 vise des applications similaires mais est un peu moins véloce. Il s'agit d'une version professionnelle de la GeForce GTX 1080 mais équipée de 16 Go de mémoire GDDR5X. La puissance brute a cette fois été doublée par rapport à la M5000.
Les nouvelles Quadro P4000, P2000, P1000, P600 et P400 remplacent les M4000, M2000, K1200, K620 et K420, ces dernières n'ayant pas profité du passage à l'architecture Maxwell. Excepté pour la P2000 qui passe à 5 Go au lieu de 4 Go, la quantité de mémoire n'évolue pas, Nvidia faisant en sorte de forcer une forte segmentation sur ce point.
La P4000 repose sur un GPU GP104 fortement castré qui permet à Nvidia de limiter sa consommation à 105W et de proposer un format simple slot. Sa puissance de calcul est doublée par rapport la M4000.
La P2000 embarque de son côté un GPU GP106, comme sur la GeForce GTX 1060, mais castré tant au niveau des unités actives que du bus mémoire, raison pour laquelle elle embarque un ensemble inhabituel de 5 Go de mémoire. Sa puissance de calcul profite d'un boost de 65% par rapport à la M2000.
Dans l'entrée de gamme, les P1000, P600 et P400 sont toutes trois basées sur le GPU GP107 (GTX 1050) plus ou moins castré. Leur puissance de calcul est donc plutôt limitée même si elle est doublée par rapport à la génération précédente. Ce type de Quadro est plutôt utile pour profiter des pilotes professionnels dans certaines applications que pour leur puissance de calcul.

De quoi en arriver à la Quadro GP100 qui nous intéresse particulièrement. Sa nomenclature l'indique sans ambiguïté, il s'agit d'une carte à part, qui vise autant les applications traditionnelles des Quadro et que le GPU Computing qui a besoin de plus que la simple précision. Pour rappel, le GPU GP100 qui lui donne son nom est le premier à embarquer la mémoire HBM2, pour une bande passante plus élevée, ainsi qu'une interconnexion de nouvelle génération : NVLink.
Jusqu'ici, le GP100 n'était exploité qu'en format serveur, soit de type PCI Express passif, soit de type module mezzanine. Nous pouvions donc nous demander si Nvidia avait réellement équipé ce GPU de tout l'attirail nécessaire pour en faire une carte graphique, notamment le moteur d'affichage et les sorties vidéo, puisqu'il est avant tout destiné au calcul massivement parallèle. Une interrogation qui trouve donc une réponse avec son arrivée dans une Quadro au format carte graphique classique.
Au niveau de la puissance brute en simple précision (FP32), cette Quadro GP100 n'est pas impressionnante. Sur ce point, le GP100 n'est pas mieux armé que le GP102 et Nvidia a décidé de castrer le GP100 de la Quadro GP100 alors que le GP102 de la Quadro P6000 est complet. Cette dernière est ainsi 15% plus véloce à peu près à tous les niveaux liés au rendu 3D. Le GP100 est probablement équipé de 128 ROP contre 96 pour le GP102, mais ses 6 moteurs de rastérisation ne peuvent en débiter plus de 96. Par ailleurs, il faut se contenter de seulement 16 Go de mémoire contre 24 Go pour la P6000.

Pour de nombreuses applications le choix entre ces deux Quadro sera pour le moins délicat. Là où le GP100 se démarque c'est avec un support très performant de la double précision (FP64) et de la demi-précision (FP16), et bien entendu au niveau de la bande passante mémoire largement supérieure avec 717 Go/s. Autre avantage, mais dont il est difficile d'estimer l'intérêt en pratique, la Quadro GP100 voit ses connecteurs SLI remplacés par 2 liens NVLink. Ceux-ci vont permettre de coupler 2 Quadro GP100 en donnant à chaque GPU un accès plus performant à la mémoire de l'autre.
En équipant sa nouvelle Quadro de cette connectique, Nvidia en fait notamment une solution de développement très utile pour la plateforme Tesla puisqu'il est possible de l'utiliser pour faire du développement sur station de travail en vue d'en déploiement sur serveur par la suite.
La Quadro GP100 se retrouvera dans quelques mois en face de la Radeon Instinct MI25 qui devrait profiter d'une puissance de calcul légèrement supérieure mais d'une bande passante inférieure. Comme pour le reste des nouvelles Quadro, la disponibilité de la Quadro GP100 est prévue pour mars, à un tarif qui n'a pas encore été communiqué.
Terminons par un petit mot sur ce que cela implique du côté des cartes graphiques destinées au moins en partie aux joueurs. La Quadro GP100 laisse penser que le GP100 pourrait également se retrouver dans une nouvelle Titan. De quoi pouvoir envisager le remplacement de la Titan X 12 Go actuelle par une version GP100 16 Go en même temps que le lancement d'une éventuelle GeForce GTX 1080 Ti en GP102 ?
GTC: Nvidia Tesla P100: 10 Tflops, HBM2...
Comme prévu, Jen-Hsun Huang, le CEO de Nvidia, a levé un coin du voile concernant le premier produit Pascal, l'accélérateur Tesla P100. Au menu : 15 milliards de transistors, 10 Tflops, HBM2, 4 Mo de L2

Le Tesla P100 est un nouvel accélérateur dédié au calcul massivement parallèle qui embarque un GPU GP100, auquel nous faisions référence précédemment en tant que Pascal, nom de code de son architecture. Il s'agit bel et bien d'un nouveau monstre de puissance. Pour cette première utilisation de procédé de fabrication 16nm FinFET Plus, Nvidia n'a pas eu peur de concevoir un énorme GPU et le GP100 intègre pas moins de 15.3 milliards de transistors répartis sur 610 mm². A comparer aux 8 milliards de transistors de l'actuel GM200 qui mesure également 600 mm².
De quoi pouvoir pousser la puissance de calcul vers le haut mais surtout intégrer de nouvelles fonctionnalités avant tout dédiées au monde du HPC telles que la connectique NVLink qui offre une bande passante combinée de 160 Go/s.



Le Tesla P100 se présente sous la forme d'un module au format mezzanine qui revient à superposer 2 PCB, avec un ou plusieurs connecteurs entre ceux-ci. Sur le Tesla P100 il s'agit de 2 connecteurs de 400 broches qui vont permettre de proposer la connectique NVLink. Ce format facilite également l'intégration dans les serveurs et la mise en place d'un refroidissement performant ce qui permet à Nvidia de pousser le TDP à 300W.

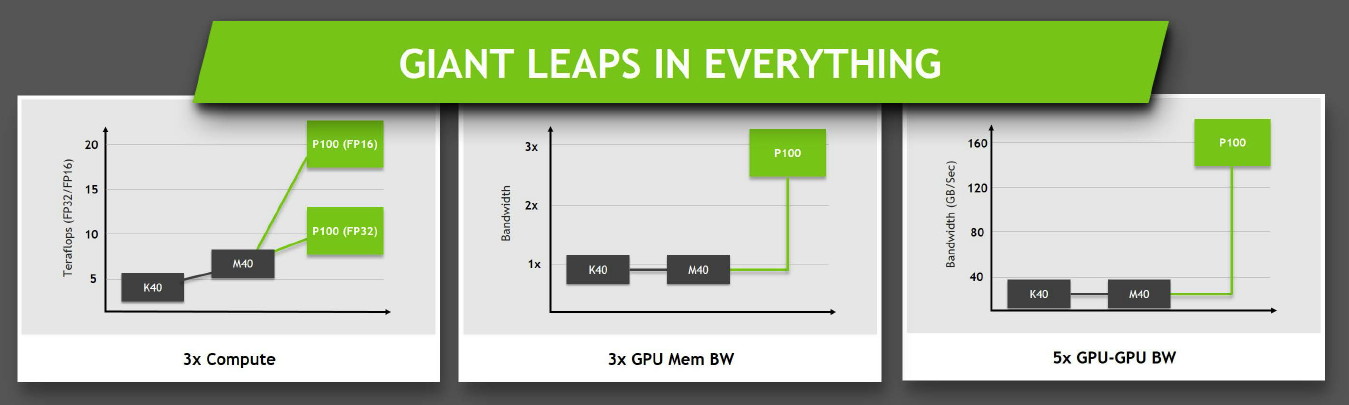
Concernant la puissance brute du Tesla P100, Nvidia annonce 10.6 Tflops avec GPU Boost en FP32, la précision classique, un gain de 60% par rapport aux 6.6 Tflops de la Titan X. L'architecture Pascal dans cette implémentation supporte également la double précision en demi-vitesse, soit 5.3 Tflops, un nouveau bond en avant par rapport au record actuel : 2.6 Tflops pour le GPU Hawaii d'AMD des FirePro W9100 et S9170. Dans l'autre sens, Pascal supporte également la demi-précision, le FP16, et peut alors monter à 21.2 Tflops.
A quelle configuration de GPU pourrait correspondre tout cela ? Au départ, nous supposions que le nombre d'unités de calcul passerait de 3072 sur le GM200 à 4608 sur le P100, réparties dans 36 blocs d'unités de calcul (SMP ?), ce qui aurait permis assez facilement d'augmenter à peu près toutes les capacités brutes du GPU de 50%. Il n'en est cependant rien et les changements sont plus profonds au niveau de l'architecture. Il s'agit ainsi pour le Tesla P100 de 3584 unités de calcul réparties dans 56 blocs de 64, mais le GP100 continent physiquement 60 de ces blocs.
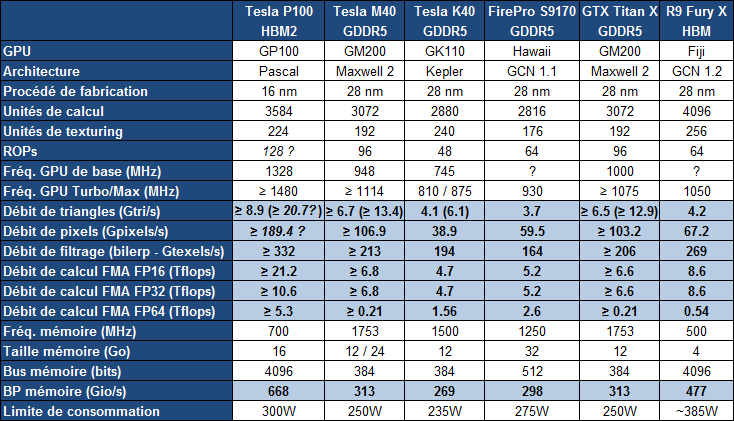
Le gain de puissance de calcul brute provient ainsi principalement d'une hausse de la fréquence du GPU (+/- 1.5 GHz) alors que le GPU computing devrait profiter de cette organisation en plus petits blocs d'unités de calcul, mais également des autres évolutions de l'architecture Pascal, pour gagner en efficacité.
Sur ce point, Nvidia se contente de parler d'une augmentation de la taille du fichier registre. Au total le GM200 embarque +/- 6 Mo de registres, ce qui correspond à 256 Ko par SMM ou encore à 512 registres 32-bit par unités de calcul. Le GP100 passe à 15 Mo de registres, ce qui implique une augmentation de 100%, soit 256 Ko par SMP ou encore 1024 registres 32-bit par unité de calcul. De quoi permettre de maintenir un meilleur taux d'occupation des unités de calcul, particulièrement en double précision.
Le cache L2 passe de son côté de 3 à 4 Mo alors que l'interface mémoire est large de 4096-bit en HBM2. Nvidia annonce une bande passante de 720 Go/s pour les 16 Go de mémoire HBM2 CoWoS, le nom donné par TSMC à sa technologie 2.5D, similaire à celle employée par AMD pour son GPU Fiji.
Ce passage à la mémoire HBM2, associé à NVLink, à la puissance de calcul en hausse et au support de la précision FP16 permet au Tesla P100 d'afficher une progression conséquente sur différents plans par rapport à ses prédécesseurs.
Jen-Hsun Huang a terminé le chapitre consacré à Pascal en déclarant que la production en volume avait débuté et que son propre serveur basé sur le Tesla P100 serait commercialisé à partir du mois de juin. Il est probablement raisonnable de s'attendre à une nouvelle GeForce Titan d'ici là, mais sera-t-elle basée sur le GP100 ?
Nvidia lance la Tesla K80: double GK210 avec Boost
Lors de l'annonce d'une nouvelle gamme de Quadro cet été, nous nous étions étonnés de ne pas voir arriver un modèle haut de gamme basé sur un nouveau "gros" GPU Kepler : le GK210. Ce dernier n'est cependant pas passé à la trappe et vient d'être introduit au travers de la nouvelle carte accélératrice Tesla K80.

Après les Tesla K10, K20, K20X et K40, Nvidia introduit le Tesla K80 qui est le second modèle bi-GPU de la famille. Elle embarque en effet deux GK210, une petite évolution des GK110/GK110B exploités sur différents segments depuis deux ans. De quoi pousser les performances un cran plus haut tout en restant sur un même format, mais bien entendu en revoyant les demandes énergétiques à la hausse.
La Tesla K80La Tesla K80 se contente de GPU partiellement fonctionnels, seules 2496 unités de calcul sur 2880 sont actives, ce qui permet de limiter quelque peu la consommation. De quoi atteindre de 5.6 à 8.7 Tflops en simple précision et de 1.9 à 2.9 Tflops en double précision. Pour le reste, le bus mémoire est complet avec 384-bit par GPU pour une bande passante totale qui atteint 480 Go/s.
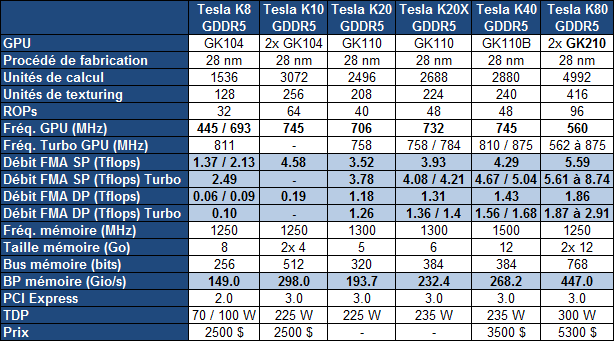
Comme pour les Tesla K40, chaque GPU de la Tesla K80 profite de 12 Go de GDDR5 avec une protection ECC optionnelle qui réduit la bande passante et la quantité de mémoire réellement disponible. Elle est alors réduite de 1/16ème et passe à 11.25 Go par GPU.
Le TDP de cet accélérateur bi-GPU est de 300W, contre 235W pour les Tesla mono-GPU. Une augmentation plutôt contenue liée au fait que le GK210 est un petit peu plus efficace sur le plan énergétique mais surtout à la mise en place d'un turbo dynamique et d'une fréquence de base relativement faible.
Les Tesla précédentes profitaient déjà d'un mode turbo, dénommé GPU Boost comme sur GeForce, mais il était statique et le TDP était défini par Nvidia comme la consommation moyenne du GPU à sa fréquence de base lors de l'exécution d'un algorithme gourmand finement optimisé pour exploiter au mieux le GPU : DGEMM. Si le GPU était exploité pour faire tourner des tâches moins lourdes, ou s'il était particulièrement bien refroidi, il était possible à travers une API spécifique de faire passer manuellement le GPU à un niveau de fréquence supérieur. Par exemple le GPU de la Tesla K40 est cadencé par défaut à 745 MHz, mais il peut être configuré en mode 810 ou 875 MHz et voir sa puissance de calcul bondir de 17%.
Nvidia justifiait l'utilisation d'un turbo statique par la nécessité de proposer un niveau de performances stable et un comportement déterministe, notamment parce que certains clusters font travailler les GPU en parallèle de manière synchrone. Un autre élément était probablement que valider un turbo dynamique était plus complexe dans le monde professionnel que grand public.
Avec la Tesla K80 cela change et par défaut c'est un turbo dynamique qui est activé et qui fonctionne de la même manière que sur les GeForce récentes à ceci près que pour des raisons de sécurité, le GPU débute à sa fréquence de base et accélère progressivement si les limites de consommation (150W par GPU) et de température n'ont pas été atteintes (il part de la fréquence maximale et la réduit sur GeForce). La plage pour ce turbo dynamique est particulièrement élevée, de 562 à 875 MHz, ce qui représente jusqu'à 55% de performances supplémentaires lorsque les tâches ne sont pas très lourdes. C'est bien entendu dans ce type de cas que cette Tesla K80 se démarquera le plus d'une K40. A noter que Nvidia propose toujours, optionnellement, la sélection de manière statique d'un certain niveau de fréquence.

Il s'agit d'un format dédié au serveur et donc passif, pour cette carte de 267mm de long, qui semble reprendre le même PCB que celui de la GeForce GTX Titan Z. Petite nouveauté, la Tesla K80 n'est pas alimentée via des connecteurs PCI Express mais bien via un seul connecteur d'alimentation CPU 8 broches, plus adapté aux serveurs et qui simplifie le câblage (les traces pour ce connecteur sont présentes sur la GTX Titan Z mais il n'a pas été utilisé).
La Tesla K80 est disponible dès à présent à un tarif de 5300$ et a été validée par Cray (CS-Storm, 8 K80 par nud 2U), Dell (C4130, 4 K80 par nud 1U), HP (SL270, 8 K80 par nud 4U half-width) et Quanta (S2BV, 4 K80 par nud 1U). De quoi pousser à la hausse la densité des capacités de calcul et atteindre de 7.5 à 11.6 Tflops en double précision par U suivant la tâche.
A noter que la concurrence n'est pas pour autant larguée. AMD a implémenté une proportion plus élevée d'unités de calcul double précision dans son dernier GPU haut de gamme (Hawaii), ce qui permet à la FirePro S9150 d'afficher un débit similaire à celui de la Tesla K80 et une densité de 10.1 Tflops par U dans le même type de serveurs.
La Tesla K8En octobre Nvidia a discrètement lancé un autre membre dans la famille Tesla : la K8. Celle-ci est en fait équipée d'un GPU Kepler GK104, non-adapté au calcul en double précision. Grossièrement il s'agit de l'équivalent Tesla d'une GeForce GTX 770/680. Le design proposé par Nvidia a la particularité d'être single slot et actif mais est prévu exclusivement pour l'intégration dans un serveur et non dans une station de travail.

Le GPU, qui affiche de 1.4 à 2.5 Tflops en simple précision, est associé à 8 Go de mémoire. Par défaut, il est cadencé à 693 MHz (2.1 Tflops) et affiche un TDP de 100W. Pour les tâches légères il peut être poussé à 811 MHz et il est également possible d'activer un mode 70W dans lequel la fréquence tombe alors à 445 MHz. Par ailleurs, l'interface PCI Express de ce GPU est limitée au PCI Express 2.0 dans le monde professionnel.
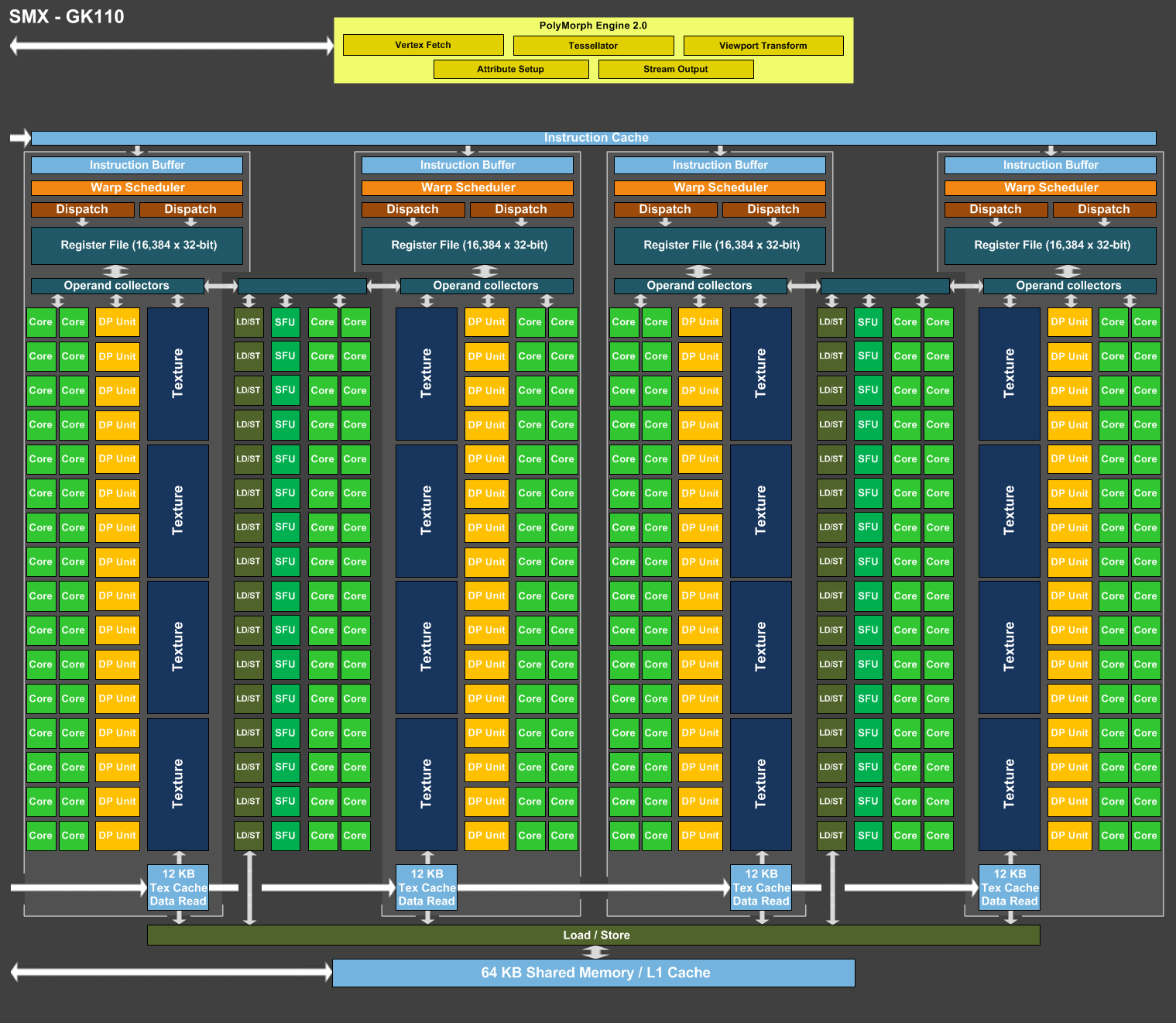
GK210, quoi de neuf ?
Alors que la génération de GPU Maxwell a pris place dans le haut de gamme grand public, c'est un nouveau GPU de la famille Kepler que Nvidia vient d'introduire dans sa gamme Tesla. Nvidia ne communique que peu de détails sur les évolutions apportées par le GK210 qui reste fabriqué en 28 nanomètres et présente une configuration globale similaire à celle du GK110. Nvidia se contente de préciser que le fichier registre et la mémoire partagée ont été doublés, ce qui dans les deux cas permet de mieux alimenter les unités de calcul du GPU et donc son rendement.
[ GK110 ] [ GK210 ]
Plus en détail, sur le GK110 comme sur tous les autres GPU Kepler, les unités de calcul sont intégrées dans les SMX, les blocs fondamentaux de l'architecture Kepler. Chaque SMX est subdivisé en 4 partitions qui se partagent l'accès aux unités de calcul, dont 192 FMA simple précision et 64 FMA double précision dans le cas des GPU GK110 et GK210. Chacune de ces partitions dispose d'un ordonnanceur et d'un fichier registres indépendant de 64 Ko, ce qui équivaut à 16384 registres 32-bit ou 8192 registres 64-bit. Le GPU étant une machine optimisée pour le débit, ces imposants fichiers registres sont exploités pour s'assurer que suffisamment d'éléments ("threads") puissent résider en interne de manière à ce que leur traitement successif puisque masquer la latence qui peut être très élevée pour certaines opérations.
Bien qu'imposants, ces fichiers registres ne sont pas sans limite et lorsqu'elle est atteinte, le taux d'utilisation des unités de calcul peut chuter fortement. Cela peut arriver quand le code à exécuter a besoin d'un nombre important de registres, quand de nombreuses opérations à latence élevée sont exécutées ou encore en 64-bit, mode deux fois plus gourmand sur ce point. Il peut ainsi s'agir d'un facteur limitant dans le cadre du calcul massivement parallèle et avec le GK210, Nvidia fait évoluer ces fichiers registres qui passent pour chaque partition de 64 Ko à 128 Ko (soit de 256 à 512 Ko par SMX et 7.5 Mo au total à l'échelle du GPU). De quoi s'assurer un taux de remplissage moyen plus élevé et donc de meilleures performances.
Le principe est le même pour le bloc qui regroupe la mémoire partagée et le cache L1. Chaque groupe d'éléments à traiter peut se voir attribuer une certaine quantité de mémoire partagée. Plus la quantité de mémoire partagée nécessaire est élevée, moins de groupes peuvent résider en même temps dans le GPU : la latence peut alors ne plus être totalement masquée ou un algorithme moins efficace, mais exigeant moins de mémoire partagée doit être utilisé, ce qui fait chuter les performances dans les deux cas.
Avec le GK210, Nvidia fait donc évoluer cette mémoire de 64 Ko à 128 Ko par SMX, mais, détail important, la totalité de la mémoire supplémentaire est attribuée à la mémoire partagée. Ainsi, alors que la répartition L1/mémoire partagée pouvait être sur GK110 de 16/48 Ko, 32/32 Ko ou 48/16 Ko, elle pourra être soit de 16/112 Ko, soit 32/96 Ko, soit de 48/80 Ko sur GK210 (suivant la quantité de L1 jugée nécessaire par le compilateur). En d'autres termes, la mémoire partagée sera en pratique de 2.33x à 5x supérieure sur ce nouveau GPU, ce qui pourra apporter un net gain de performances pour certaines tâches. Pour rappel sur les GPU Maxwell de seconde génération, la mémoire partagée n'est plus liée au L1 et est de 96 Ko.
Contrairement à ce que nous supposions au départ face à l'absence de réponse de Nvidia à cette question, le GK210 ne reprend pas la modification apportée aux autres GPU de la lignée GK2xx par rapport à la lignée GK1xx : la réduction de moitié du nombre d'unités de texturing. Un compromis qui permet de réduire la taille des SMX avec un impact sur les performances lors du rendu 3D, mais qui n'a pas été retenu dans le cas du GK210 qui conserve ses 240 unités de texturing, soit 16 par SMX. De quoi lui permettre de conserver l'ensemble de 4 petits caches de 12 Ko spécifiques aux unités de texturing (48 Ko par SMX). Ces derniers peuvent être déviés de leur rôle principal pour faire office de cache en lecture très performant.
Du côté grand public, ce GPU GK210 n'aura peut-être aucune existence et dans tous les cas un intérêt limité étant donné que les GPU de la nouvelle génération Maxwell y sont déjà commercialisés et sont plus performants et plus évolués sur le plan des fonctionnalités. Il permet par contre à Nvidia de proposer un GPU plus efficace dans le domaine du calcul massivement parallèle et pourrait bien être le premier GPU conçu spécialement pour cet usage. Dans tous les cas, Nvidia a de toute évidence stoppé la production de puces GK110B et, si nécessaire, pourra simplement remplacer le GK110/110B par un GK210 sur n'importe lequel de ses produits.
Reste que le timing de son arrivée peut évidemment sembler étrange. Pourquoi concevoir et introduire fin 2014 un nouveau GPU de l'ancienne architecture Kepler, alors que l'architecture Maxwell est déjà disponible ? Et qu'un plus gros GPU Maxwell, le GM200, est attendu ? Il peut y avoir plusieurs raisons à cela et deux d'entre elles nous paraissent les plus probables : soit le GM200 est très loin d'être prêt à être commercialisé, soit le GM200 n'est pas un GPU adapté au monde du HPC, par exemple parce qu'il ne serait pas équipé pour le calcul double précision.
Rien ne dit qu'il faille y voir une quelconque confirmation, mais cette seconde possibilité ne serait pas incompatible avec les roadmaps présentées par Nvidia. En mars 2013, la roadmap faisait état de l'évolution du rendement énergétique en double précision en passant de Kepler à Maxwell et enfin à Volta. En mars 2014, l'unité utilisée par Nvidia était cette fois du calcul en simple précision et une architecture Pascal, clairement pensée pour le monde du HPC, a été intercalée entre Maxwell et Volta. Ceci dit, il nous semble difficile d'imaginer Nvidia se contenter du GK210 en 2015, et de patienter jusqu'à l'arrivée de Pascal en 2016 pour proposer une évolution plus importante sur ce marché
IBM Power9 et Nvidia Volta : 100+ petaFlops en 2017
Le département de l'énergie américain a tranché il y a quelques jours : les prochains supercalculateurs qu'il finance seront mis en place par IBM sur base d'une plateforme OpenPower équipée de ses futurs CPU Power9 et des GPU Volta de Nvidia associés via l'interconnexion NVLink.

Cinq années, cela semble être la durée de vie des supercalculateurs pour lesquels le département de l'énergie américain (DoE) met la main à la poche. Délivré mi-2012 sur base d'une plateforme IBM Blue Gene/Q et de CPU Power8 à l'administration nationale pour la sécurité nucléaire, Sequoia et ses 20 petaFlops (17 petaFlops mesurés) prendra sa retraite en 2017. Il en ira de même pour le supercalculateur Titan exploité par le laboratoire national d'Oak Ridge qui affiche 27 petaFlops au compteur (17.5 petaFlops mesurés). Pour rappel, ce dernier est basé sur une plateforme Cray XK7 équipée d'Opteron 6274 et d'accélérateurs Tesla K20X.
La course à la puissance ne s'arrête jamais, d'autant plus que la Chine a volé la première place du podium aux Etats-Unis avec Tianhe-2, une plateforme 100% Intel qui affiche 55 petaFlops au compteur (34 petaFlops mesurés) à travers ses Xeon E5-2692 et ses Xeon Phi 31S1P. Si ce dernier est plus performant, à noter cependant que sa consommation explose pour atteindre près de 18 mégawatts là où les actuels supercalculateurs américains se contentent de 8 à 9 mégawatts.
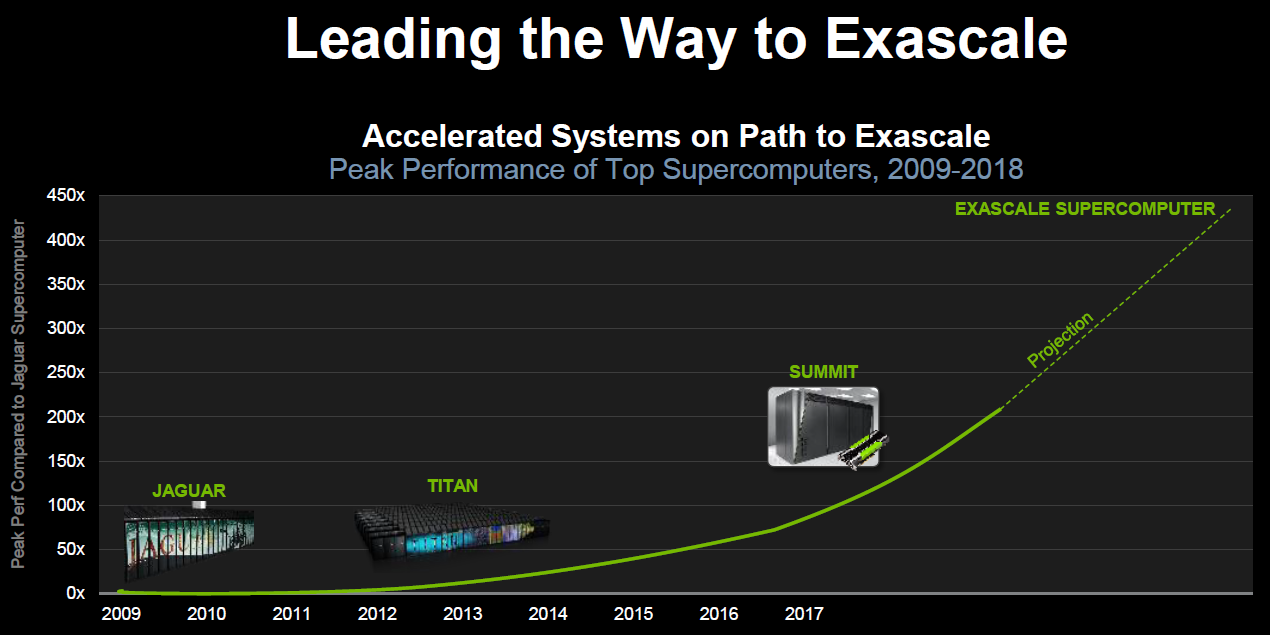
Ce détail est en fait très important. Nul doute en effet que le cahier des charges du DoE pour ses futurs supercalculateurs, baptisés Sierra et Summit, exigeait de ne pas trop augmenter le budget énergétique de ses futures installations, en plus bien entendu de pousser la puissance de calcul vers le haut en attendant l'arrivée des systèmes exaFlops, prévus pour la génération suivante.
Pour les deux systèmes, une même plateforme de plus de 100 petaFlops a cette fois été retenue et c'est IBM qui a reçu ce contrat de 325 millions de $. La plateforme proposée par IBM a pour particularité de s'efforcer de rapprocher les données de la puissance de calcul pour réduire les déplacements coûteux tant en performances qu'en énergie. Un argument important à l'heure où la quantité de données à traiter explose.
Alors que l'actuel Sequoia était de type 100% CPU IBM, le DoE a favorisé une solution hétérogène, étant visiblement satisfait des résultats du Titan, et a renouvelé sa confiance dans les GPU Nvidia et l'écosystème CUDA. Une étape cruciale pour Nvidia qui voit donc sa place de fournisseur de puissance de calcul confirmée sur un marché dans lequel il est difficile de percer.

Les raisons du choix du couple IBM/Nvidia sont bien entendu nombreuses et ne sont pas dues au hasard. Les deux acteurs travaillent ensemble depuis quelques temps déjà, Nvidia ayant annoncé en mars dernier une interconnexion NVLink développée en partenariat avec IBM. Pour rappel, celle-ci permet de s'affranchir du PCI Express et de ses limitations pour proposer une voie de communication plus performante entre les GPU mais également entre les GPU et les CPU. Cela implique des changements importants, notamment au niveau du format physique qui passera à un socket de type mezzanine.
Ce support de NVLink est une évolution logique du côté d'IBM qui propose déjà sur ses CPU Power8 une interface CAPI (Coherent Accelerator Processor Interface) dédiée au support d'accélérateurs spécifiques basés sur des modules FPGA interconnectés en PCI Express. De toute évidence IBM a étendu l'interface CAPI de manière à y intégrer le support de NVLink mais les spécificités à ce niveau restent inconnues.
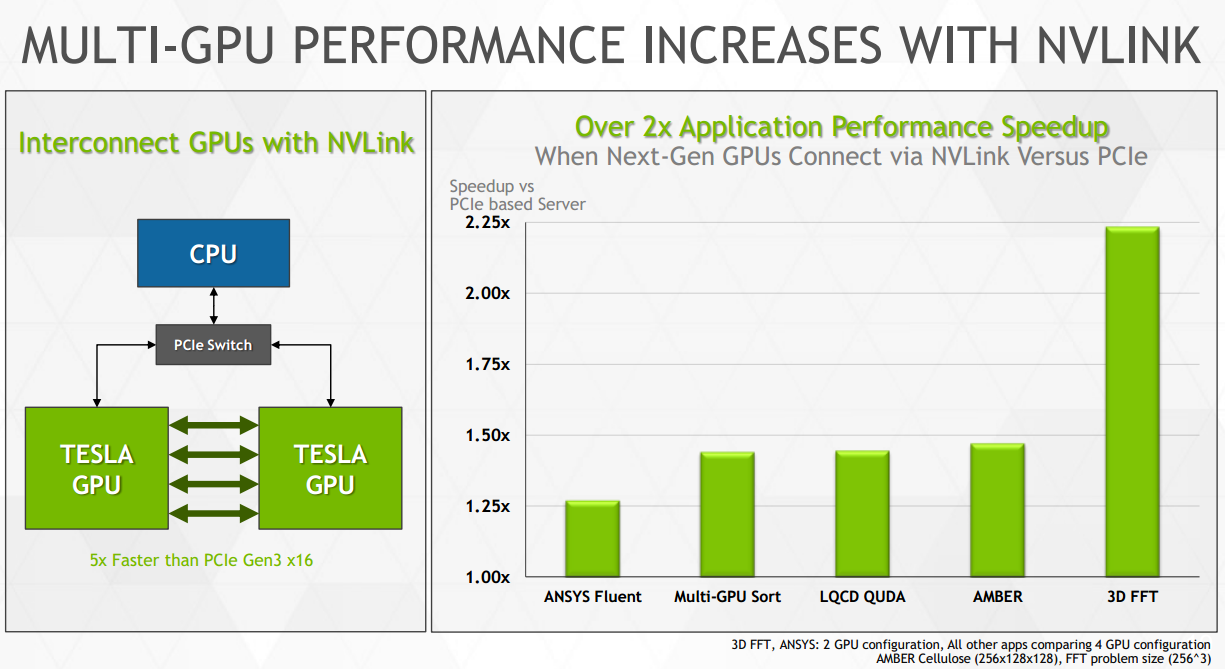
Chaque lien NVLink est constitué d'un certain nombre de couples de lignes point-à-point et dans le cas de la première version de NVLink il est question d'une bande passante de 20 Go/s par lien (16 Go/s effectifs). Nvidia prend pour exemple un GPU équipé de 4 de ces liens qui pourrait ainsi profiter au total de 64 Go/s pour ses voies de communications vers les autres GPU et vers le CPU auquel il est rattaché, contre seulement 12 Go/s en PCI Express 3.0. De quoi booster les performances sur certains algorithmes : dans sa documentation Nvidia met en avant des projections avec +20% à +400% de mieux suivant les algorithmes observés.
Toujours au niveau de la mémoire, avec Volta, chaque GPU pourra alors être équipé d'une quantité importante de mémoire haute performances grâce à la technologie HBM. Pas question cependant de tester tout cela lors de la mise en place de ces supercalculateurs, ces technologies devront être éprouvées avant. C'est ce qu'a prévu Nvidia. En 2016, le GPU Pascal sera le premier à supporter NVLink, la mémoire HBM et le nouveau format. De quoi être prêt pour 2017 et le GPU Volta qui profitera de la version 2.0 de NVLink dont l'évolution principale sera la possibilité de supporter un espace mémoire totalement cohérent entre le ou les CPU et le ou les GPU. Pour en profiter une bande passante élevée sera nécessaire, elle pourra monter jusqu'à 200 Go/s à travers l'ensemble des liens NVLink (5 liens à 40 Go/s ?). De quoi permettre de revoir en profondeur l'architecture des supercalculateurs.
Alors que Titan par exemple est un ensemble de 18688 nuds équipés chacun d'un Opteron 16 curs avec 32 Go de DDR3 et d'une Tesla K20X avec 6 Go de GDDR5, Sierra et Summit se contenteront de beaucoup moins de nuds mais bien plus costauds et chacun équipé d'une zone de stockage locale.
Les informations concernant Sierra restent actuellement limitées, puisqu'il remplacera Sequoia dans le domaine sensible de la sécurité nucléaire. Par contre plus de détails ont été communiqués au sujet de Summit, qui remplacera Titan avec une puissance de calcul théorique qui se situera entre 150 et 300 petaFlops pour une consommation qui ne devrait augmenter que de 10% alors que l'encombrement sera nettement réduit.
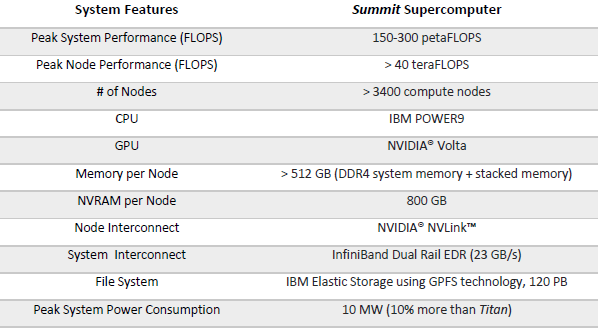
Summit sera constitué de plus de 3400 nuds, chacun présenté avec une puissance de calcul théorique de plus de 40 teraFlops (probablement bien plus puisque cela ne représente que 136 petaFlops). Chacun de ces nuds sera équipé de plusieurs CPU Power9 et de plusieurs accélérateurs Tesla dérivés du GPU Volta. Nous pouvons raisonnablement supposer qu'il s'agira de 4 à 8 composants de chaque type par nud. Ils seront accompagnés par un ensemble de plus de 512 Go de mémoire DDR4 (côté CPU) et HBM (côté GPU) qui formeront un seul et unique espace cohérent, même si les accès mémoire resteront optimisés pour des usages différents de part et d'autre. Par ailleurs 800 Go supplémentaires de mémoire flash seront installés, de quoi par exemple faire office de buffer pour le système de stockage de 120 petaOctets qui devra se "contenter" d'une bande passante de 1 To/s.
Ce type de contrat est très important en terme d'image de marque pour un acteur tel que Nvidia, mais il lui restera à démontrer de l'intérêt, en pratique, d'une plateforme basée autour de NVLink dans les plus petits systèmes qui représentent le gros du marché. Si seul le Power9 d'IBM et le Volta de Nvidia supportent NVLink, ils resteront dépendants l'un de l'autre pour être exploités au maximum de leurs capacités. Un pari risqué ? Sans commenter le fond de cette question, Nvidia précise qu'un petit ensemble de 4 nuds similaires à ceux développés par IBM pour Summit suffirait à placer la machine dans la liste Top500 des supercalculateurs actuels.
Pour en savoir plus, vous pourrez retrouver deux whitepapers chez Nvidia , l'un tourné autour de ces supercalculateurs, l'autre autour de NVLink et de ses promesses (sans prendre en compte le support CPU).
Nvidia annonce la Tesla K40 et CUDA 6
La semaine passée, à l'occasion du SC13 (Supercomputing 2013), Nvidia a annoncé deux nouveautés liées au calcul haute performance : l'accélérateur Tesla K40 et la version 6 de CUDA.
Pour rappel, c'est la gamme Tesla qui a été la première à profiter du plus gros GPU de la famille Kepler, le GK110. Contrairement aux Quadro K6000 et GeForce GTX 780 Ti plus récentes, cette gamme Tesla n'accueillait cependant toujours pas de version complète du GK110, c'est-à-dire avec l'ensemble de ses unités d'exécution actives. Une configuration facilitée par l'arrivée de la révision B1 du GPU.
La Tesla K40 profite ainsi de 15 SMX, de 2880 unités de calcul FMA 32-bit et de 960 unités FMA 64-bit pour afficher une puissance de calcul en hausse de près de 10% par rapport à la Tesla K20X. Par ailleurs, comme pour le Quadro K6000, Nvidia profite de la disponibilité effective de la GDDR5 4 Gbits pour faire passer la mémoire dédiée de son accélérateur de 6 à 12 Go. Sa fréquence est par ailleurs revue à la hausse ce qui profite à la bande passante mémoire en hausse de 15%.

Si la fréquence GPU ne progresse que très peu pour la Tesla K40, c'est uniquement pour garantir que l'enveloppe thermique ne soit pas atteinte dans les tâches de type calcul, sachant que, contrairement aux GeForce, Nvidia ne propose pas de turbo pour ces cartes afin d'éviter que leurs performances soient variables. Par contre, pour la Tesla K40, Nvidia propose 2 modes avec des fréquences GPU différentes : optionnellement, il sera ainsi possible de passer le GPU de 745 à 810 ou 875 MHz. Il ne s'agit pas d'un overclocking dans le sens où ces fréquences sont validées par Nvidia, ni d'un turbo automatique, même si Nvidia place cette possibilité sous l'appellation GPU Boost, marque du turbo des GeForce... Si la personne qui exploite ces Tesla K40 constate qu'elles restent loin de leur TDP dans une certaine situation, elle aura la possibilité de passer à un de ces modes de fréquence supérieure. De quoi profiter 9% voire 17% de puissance supplémentaire.
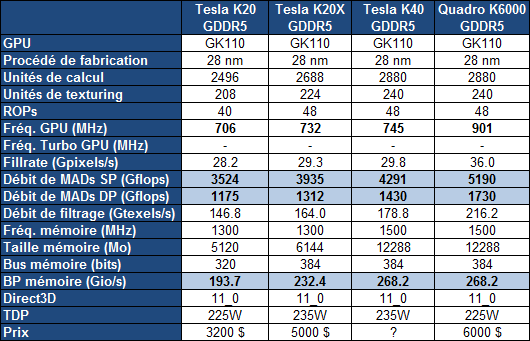
A noter que la Tesla K40 sera proposée autant avec un refroidissement actif, comme la K20, qu'avec un refroidissement passif en vue d'intégration dans un serveur, comme la K20X. Enfin, le PCI Express 3.0 est activé sur la K40 contrairement aux K20/X.
Nvidia ne communique pas au niveau de la tarification, mais elle devrait rester inférieure à celle de la Quadro K6000, probablement passer à 5000$ alors que les K20/X devraient voir leur tarif baisser. Il faut cependant garder en tête que sur ce marché de niche, les prix sont fortement variables, les grossistes n'hésitant pas à se réserver des marges conséquentes. Ainsi pour des tarifs annoncés par Nvidia de 3200$ et de 5000$ pour les K20 et K20X, en pratique, il fallait en général compter plutôt 4000$ et 7500$, la même chose en euros.
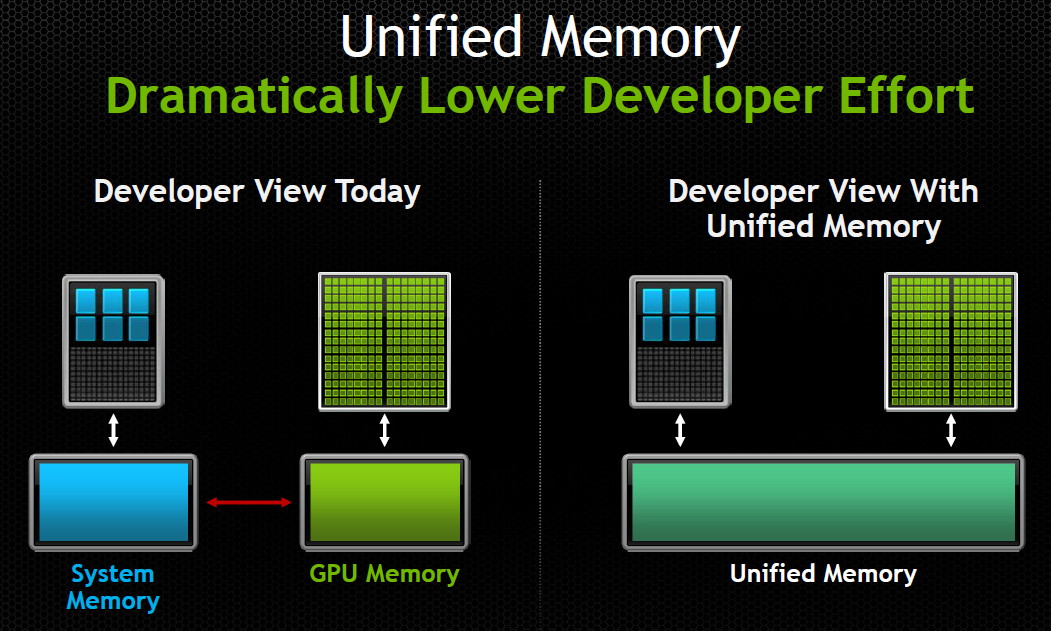
Parallèlement à l'arrivée de cette nouvelle Tesla, Nvidia a annoncé CUDA 6 qui apporte une nouveauté majeure et très attendue : la prise en charge d'une mémoire unifiée. Une fonctionnalité qui donne l'impression d'être annoncée et réannoncée régulièrement, AMD et Nvidia ayant régulièrement joué sur les mots à ce niveau. Pour rappel, depuis quelques temps, CUDA supporte un adressage de mémoire virtuelle unifié, qui facilite quelque peu le développement mais n'était qu'un premier pas. La mémoire unifiée, représente cette fois une abstraction totale de la gestion de la mémoire : il n'est plus nécessaire que le développeur gère les transferts de données de la mémoire centrale vers la mémoire de l'accélérateur.
Une gestion manuelle de la mémoire restera possible, étant donné qu'aussi bénéfique soit cette simplification, elle peut avoir un coût sur le plan des performances et de l'efficacité puisqu'il reviendra aux pilotes et/ou aux compilateurs d'essayer de placer automatiquement les données au bon endroit.

Confiant dans l'avenir, Nvidia termine par annoncer que l'ouverture par IBM, cet été, de sa plateforme serveur POWERn, va permettre d'y intégrer des accélérateurs Tesla dès 2014. Des accélérateurs qui seront ainsi exploités non plus uniquement sur x86 mais également sur architectures POWER et ARMv8.