
Les derniers contenus liés au tag GCN
Afficher sous forme de : Titre | FluxDossier: AMD Radeon R9 Nano, la carte Fiji compacte en test
Les GTX 900 supportent-elles correctement DirectX 12 ?
Dossier: AMD Radeon R9 Fury : Sapphire Tri-X et Asus Strix en test
Dossier: AMD Radeon R9 Fury X : le GPU Fiji et sa mémoire HBM en test
GDC: D3D12: Une guerre des specs en vue ?
AMD annonce la restructuration de RTG
Dossier: Les Radeon RX 580 et RX 570 d'Asus, MSI et Sapphire en test : Polaris acte 2
AMD lance les Bristol Ridge desktop OEM
AMD annonce Polaris, sa future architecture GPU
Dossier: AMD Radeon R9 380X : les cartes Asus Strix et Sapphire Nitro en test
AMD annonce la restructuration de RTG



Après le "repos sabbatique" (et le départ) de Raja Koduri, Lisa Su avait annoncé reprendre temporairement la main sur la branche graphique du constructeur.
Hier, AMD a annoncé remettre en place une nouvelle direction pour son Radeon Technology Group, et la première nouvelle est que le nom RTG reste en place. C'est une petite surprise puisque l'un des problèmes qui semblait avoir conduit au départ de Raja Koduri était l'insularité du groupe et la "compétition", pour ne pas dire les relations tendues entre ce groupe et l'activité CPU d'AMD.
AMD dans son communiqué fait fi de ce problème mais il semble qu'une réorganisation interne ait bien eu lieu pour limiter, à défaut de changer les esprits d'un claquement de doigts, les problèmes rencontrés précédemment.
Ce que la société annonce, c'est l'arrivée de deux nouveaux Senior Vice President pour diriger le groupe. D'un point de vue technique d'abord, c'est le retour de David Wang lui aussi ingénieur et qui avait obtenu le titre de Corporate Vice President précédemment chez AMD pour la partie GPU. Il avait rejoint plus récemment Synaptics. Wang dispose de 25 ans d'expérience dans le monde graphique ayant travaillé pour SGI, et ayant fait parti de la (complexe) transition d'ATI vers AMD lors du rachat en 2006. D'un point de vue technique, il a travaillé sur les architectures graphiques d'AMD jusque la première version de GCN. Il aura en charge tous les sujets techniques et stratégiques, que ce soit sur l'architecture, le hardware et la partie logicielle.

La seule chose dont il ne s'occupera pas est la question commerciale et la gestion au jour le jour du groupe, qui sera à la charge de Mike Rayfield. En provenance de Micron, il est surtout connu pour avoir dirigé la division mobile/Tegra de Nvidia. Il sera également en charge des relations commerciales de l'activité "semi-custom" (qui comprend entre autres les ventes de SoC pour les consoles).
Dossier : Les Radeon RX 580 et RX 570 d'Asus, MSI et Sapphire en test : Polaris acte 2
C'est le printemps, AMD remplace les Radeon RX 400 par les RX 500. Nous avons passé en revue les RX 580 de MSI et de Sapphire ainsi que la Radeon RX 570 d'Asus. De meilleures solutions milieu de gamme pour les joueurs ?
[+] Lire la suite

AMD lance les Bristol Ridge desktop OEM
Après avoir annoncé les versions mobiles en juin, AMD lance aujourd'hui la version desktop de ses APU de "7ème génération", les Bristol Ridge. Le lancement s'est fait par le biais d'un simple communiqué de presse en ce jour férié aux Etats-Unis.
Le lancement est pourtant important puisque c'est en simultanée la première apparition de la nouvelle plateforme AM4 d'AMD, qui acceuillera non seulement les Bristol Ridge, mais également les Zen Summit Ridge. Une apparition toute relative puisque ce lancement est réservé aujourd'hui uniquement aux OEM.
Par rapport aux APU desktop précédentes (Kaveri/Godavari), on trouve un peu plus de changement que côté mobile, en grande partie parce que Carrizo (duquel Bristol Ridge est très très proche) n'avait pas été décliné sur le socket FM2+.
On reste bien entendu sur l'architecture Bulldozer, mais dans sa version Excavator contre SteamRoller précédemment, tandis que côté graphique on passe à la version 3 de GCN. De quoi proposer des gains d'efficacité par rapport a Kaveri... lancé début 2014.
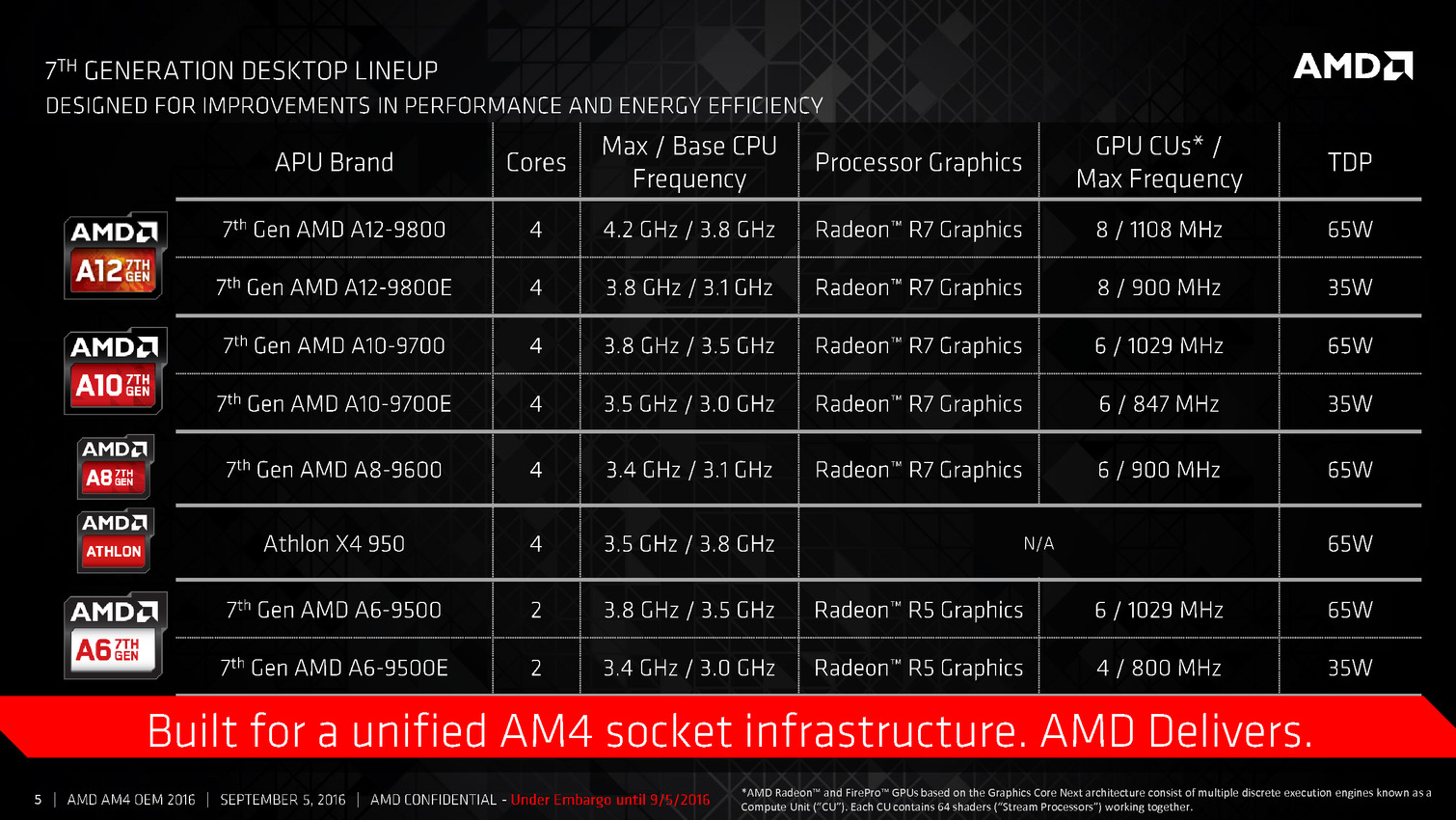
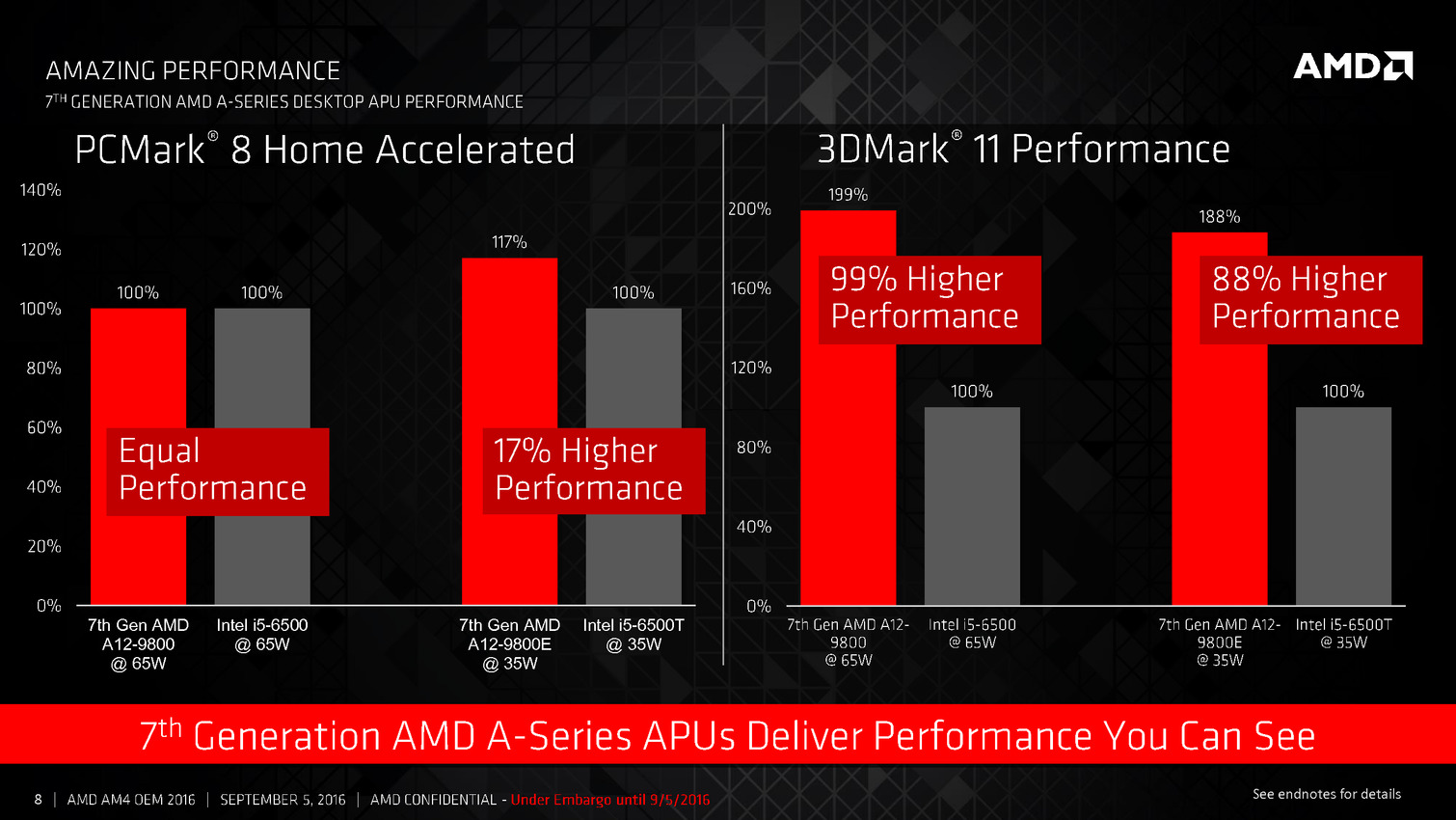
Cela permet à AMD de faire baisser le TDP : bien que l'on reste en 28nm, ces nouvelles APU sont annoncées pour 65 watts. Le modèle le plus haut de gamme, l'A12-9800 est cadencé à 3.8/4.2 GHz pour ses deux modules (4 coeurs), et 1108 MHz pour les 8 CU côté graphique. Des versions 35 watts sont également lancées.
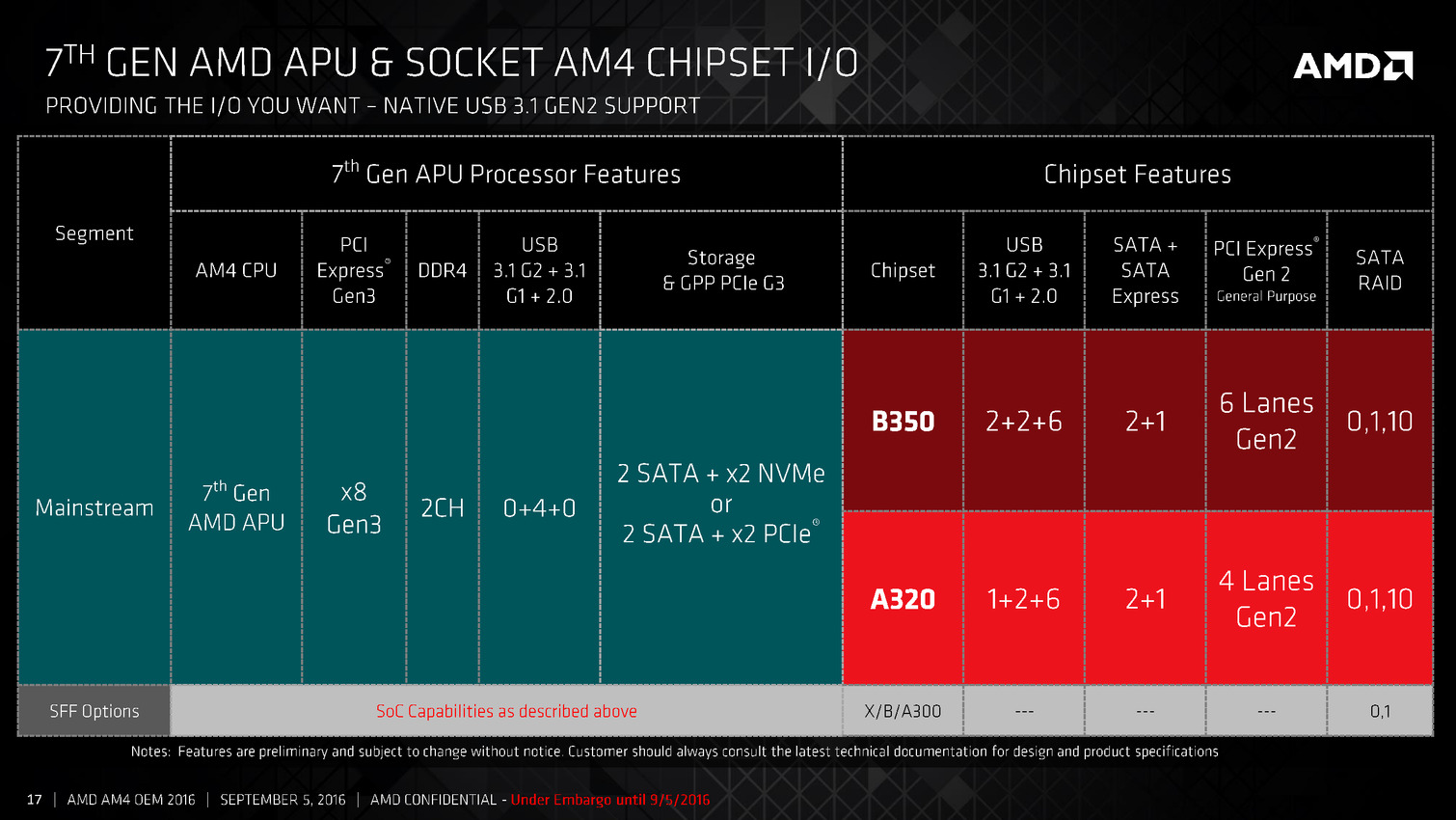
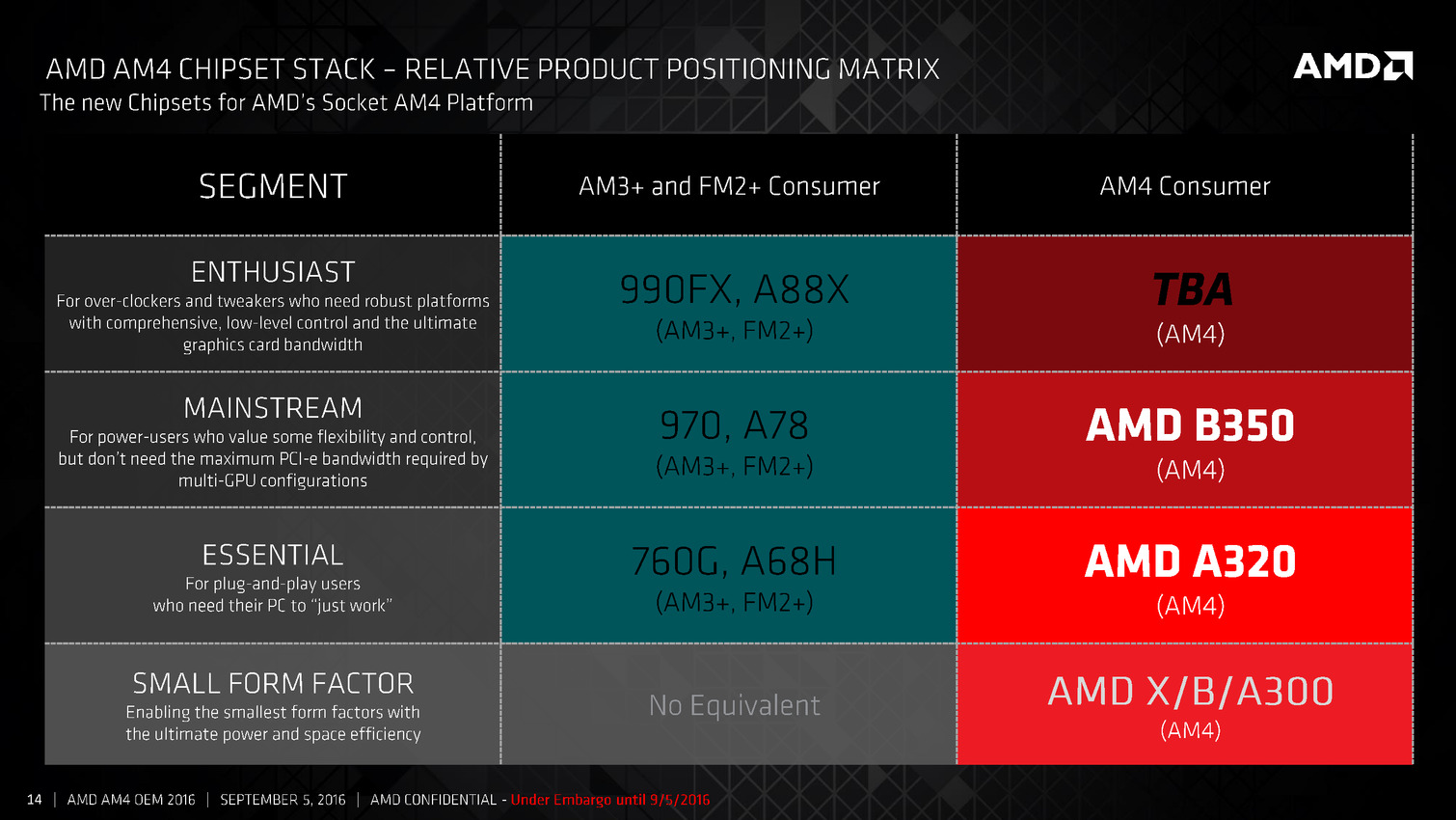
Les Bristol Ridge sont pour rappel des SoC et intègrent entre autre 8 lignes PCIe Gen3, la gestion de quatre ports USB 3.0 ainsi que 2 SATA et deux lignes PCIe Gen3 supplémentaires pouvant être utilisées pour des ports NVMe. AMD lance en simultanée deux chipsets, les A320 (!) et B350 qui rajoutent des ports USB, y compris des ports 3.1 ainsi qu'un plus grand nombre de ports SATA et de lignes PCIe. Un modèle spécifique "Enthusiast" sera annoncé plus tard, on l'imagine à l'occasion de la sortie de Zen.
AMD indique que ces puces seront disponibles dans un premier temps uniquement dans des configurations HP et Lenovo, et que d'autres OEM suivront.
Le communiqué de presse évite par contre la question d'une disponibilité de ces puces en dehors des OEM, ce qui élude la question du prix (la liste de prix d'AMD n'a pas encore été mise à jour au moment ou nous écrivons ces lignes).
Vous pouvez retrouver l'intégralité de la présentation ci-dessous :
















AMD annonce Polaris, sa future architecture GPU
Enfin, après 4 années de GCN en 28nm, les Radeon vont accueillir une nouvelle architecture gravée en 14nm : Polaris. Et pour AMD le focus se portera sur l'efficacité énergétique avec un bond en avant annoncé sans précédent !

Le Radeon Technology Group d'AMD profite de ce début d'année pour lever un (très petit) coin du voile qui entoure sa prochaine génération de GPU, notamment en donnant un nom de code à son architecture : Polaris (l'étoile polaire). Et pour positionner sans équivoque ses objectifs avec cette architecture, AMD explique avoir opté pour ce nom de code en faisant le parallèle entre l'efficacité des étoiles à générer des photons et l'efficacité demandée aux GPU pour générer des pixels.
Comme vous le savez, l'architecture actuelle des Radeon est globalement en retrait par rapport à l'architecture Maxwell de Nvidia au niveau de l'efficacité énergétique. Fort de larges parts de marché et ayant bien anticipé le très long passage par le procédé de fabrication 28nm (exploité pour les GPU depuis 4 ans déjà !), Nvidia a développé deux architectures pour celui-ci : Kepler et Maxwell. En face, AMD est resté sur une architecture GCN moins efficace en se contentant d'évolutions mineures de son cur. Pourquoi ? Probablement parce que, contrairement à Nvidia, AMD avait parié sur l'exploitation d'un procédé en 20nm qui ne s'est jamais concrétisée pour les GPU.
Tout cela va enfin changer en 2016 avec l'arrivée de GPU fabriqués en 16nm FinFET+ chez TSMC et en 14nm LPP chez GlobalFoundries et Samsung. Ces nouveaux procédés de fabrication ont pour point commun de donner enfin aux GPU l'accès à la technologie FinFET, de quoi donner un coup de pied dans une fourmilière bien trop tranquille à notre goût !
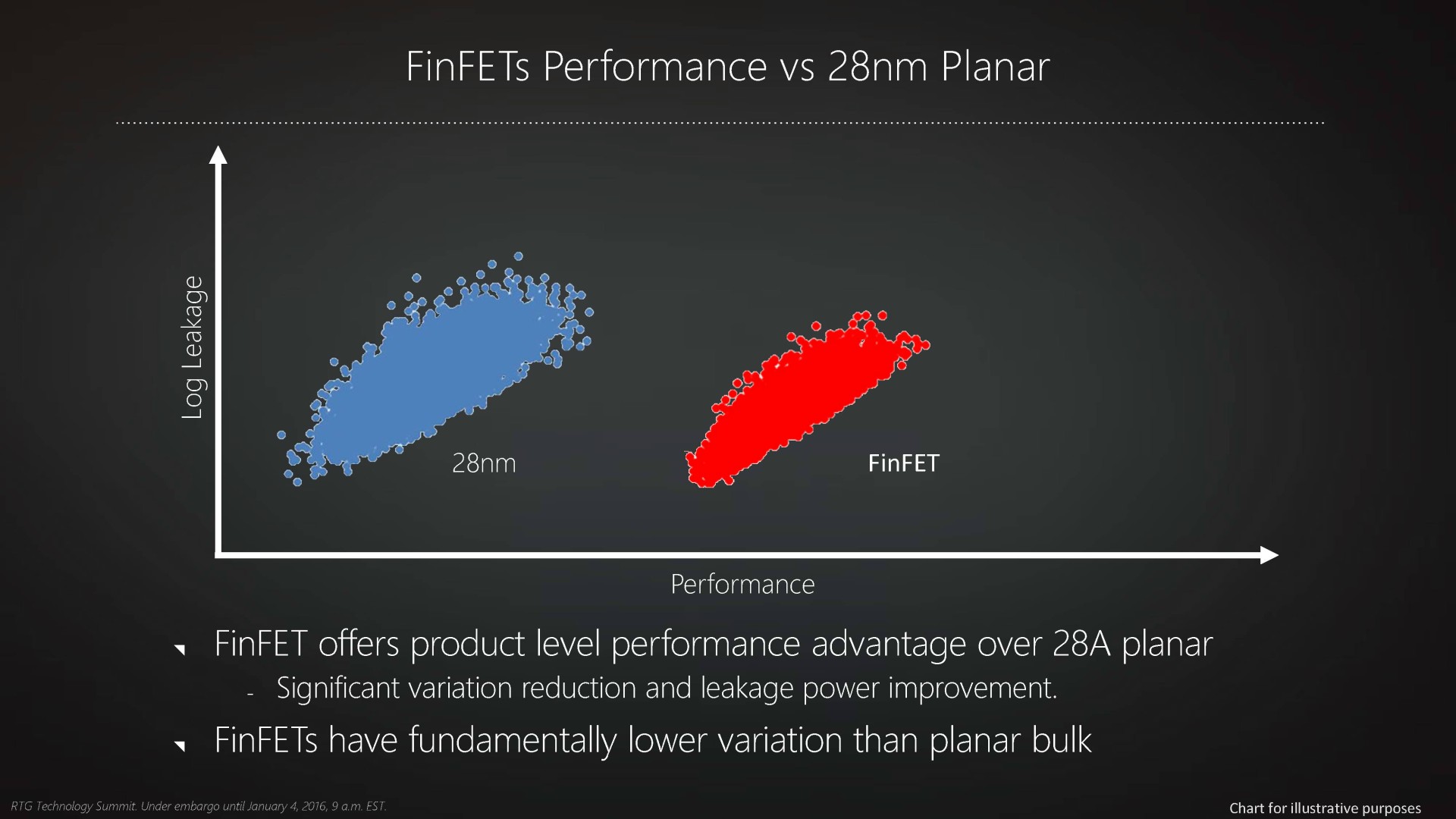
Introduit par Intel en 2012 sous les noms de "transistors tri-gates" ou de "transistors 3D", le FinFET se détache de la construction planaire classique des transistors en donnant une troisième dimension à la porte ce qui permet d'en augmenter la surface de contact et de mieux l'isoler. Les courants de fuite, qui peuvent représenter une grosse partie de la consommation d'un transistors classique, sont alors nettement réduits.
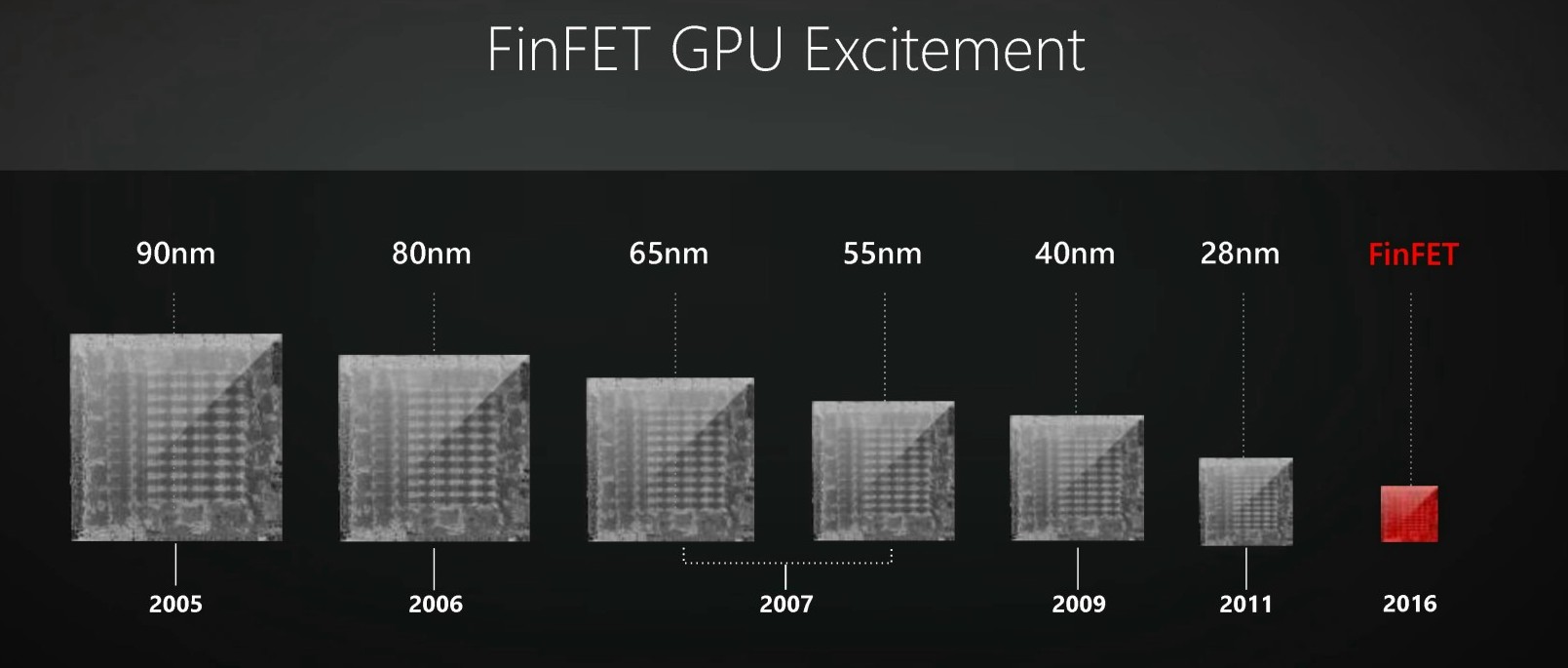
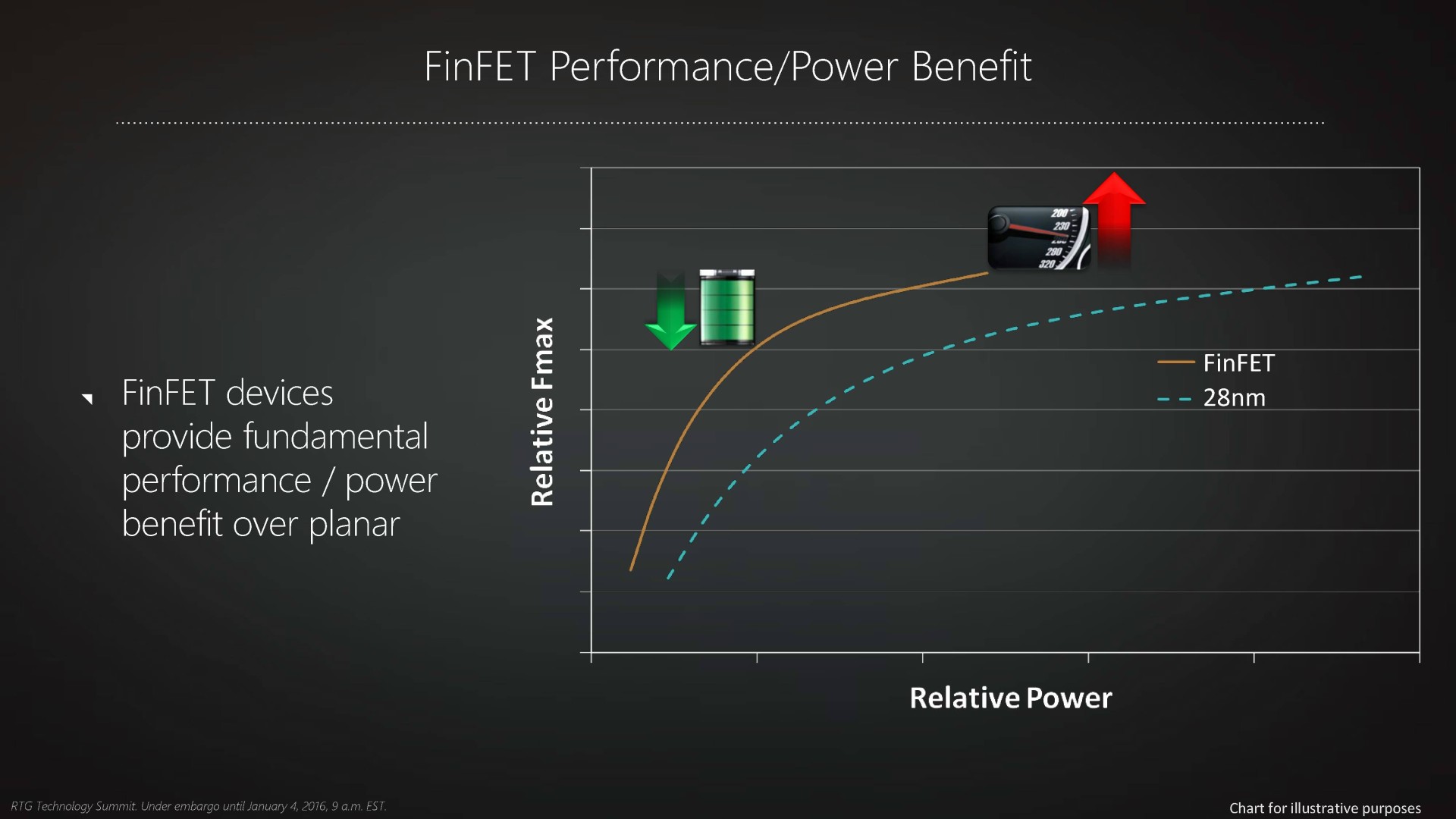
Autant, voire plus, que la finesse de gravure, c'est ainsi le passage au FinFET qui autorise une avancée significative dans les performances des transistors, ce qui peut se traduire par un gain de fréquence, une nette réduction de la consommation ou un mélange de ces deux points selon le positionnement de la puce. Autre avantage selon AMD, le FinFET permet d'obtenir un comportement plus homogène de l'ensemble des transistors, ce qui réduirait la variabilité dans les échantillons produits.
Comme c'est traditionnellement le cas pour les Radeon, c'est lors de ce changement de process qu'AMD va introduire une évolution significative de son architecture GPU, sur laquelle le Radeon Technology Group va bien entendu vouloir communiquer. Et pour cela il faut pouvoir lui mettre un nom.
La nomenclature des architectures GPU d'AMD, ou plutôt son absence, a été source de confusion ces dernières années. En l'absence de communication d'AMD, nous avons ainsi fait référence à GCN 1.1 et GCN 1.2 pour parler des petites évolutions apportées depuis la Radeon HD 7970 de décembre 2011. AMD préfère cependant concentrer le terme GCN sur les unités de calcul du GPU (ses "curs"), d'autres éléments du GPU pouvant évoluer indépendamment. Polaris représente ainsi le nom global de la nouvelle architecture et GCN 4 la nouvelle version de ses unités d'exécution (après GCN 1 / 1.0, GCN 2 / 1.1 et GCN 3 / 1.2).
Raja Koduri, qui dirige Le Radeon Technology Group, nous a indiqué vouloir faire en sorte que les cartes graphiques qui embarqueront un GPU de type Polaris soient clairement identifiables. Pragmatique et réaliste, il est bien conscient qu'avec une éventuelle future gamme de cartes graphiques, il pourra être difficile pour ses équipes de résister à la tentation d'y intégrer d'anciens GPU. Il sera ainsi important de permettre aux GPU Polaris d'être mis en avant de manière explicite.
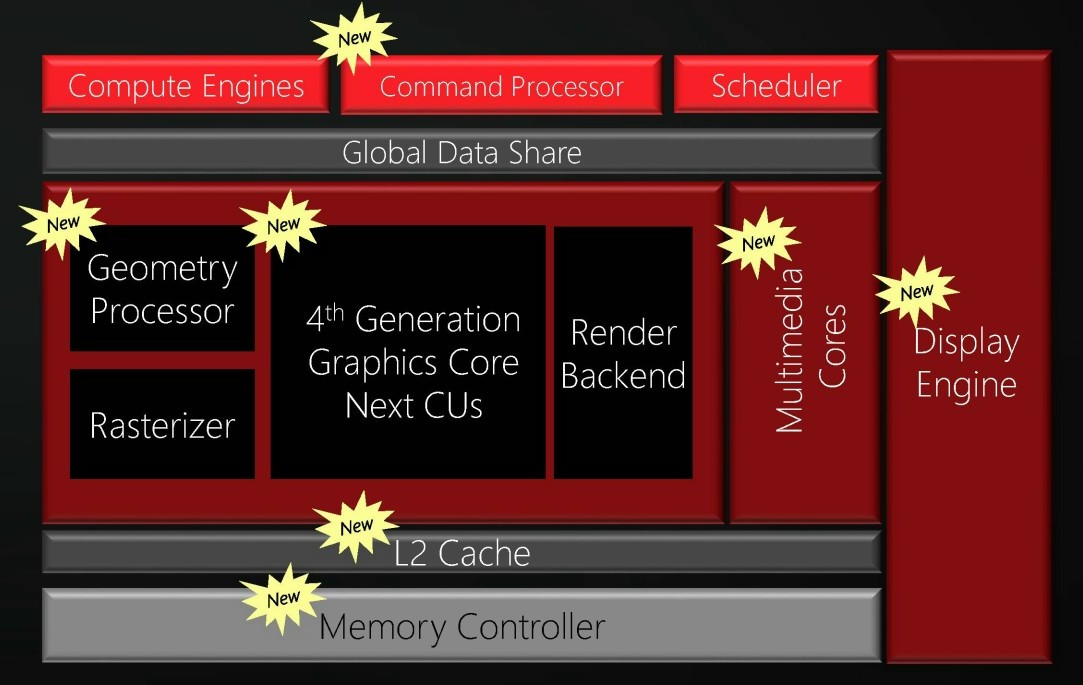
Avec Polaris, à peu près tous les blocs du GPU vont être mis à jour. Nous vous avons déjà parlé de l'aspect affichage et vidéo le mois passé. Pour rappel, les GPU Polaris supporteront le HDMI 2.0a, le DisplayPort 1.3 et le décodage des vidéo 4K en H.265.
Les processeurs de commandes (grahiques et compute), les processeurs géométriques, le cache L2 et le contrôleur mémoire seront également revus pour accompagner le passage aux Compute Units (CU) de type GCN de 4ème génération. Sur ce dernier point AMD précise que Polaris pourra supporter soit un bus GDDR5 soit un bus HBM, suivant les GPU.
Malheureusement, AMD en dit très peu sur les évolutions et ne donne que ces quelques maigres détails :

AMD indique tout d'abord que le cur de l'architecture a été amélioré pour une meilleure efficacité énergétique. Comme Nvidia a commencé à le faire à partir de la génération Kepler, nous pouvons supposer qu'AMD va essayer de ne plus avoir besoin d'une logique d'ordonnancement complexe et gourmande à l'intérieur des CU, là où le comportement d'une suite de certaines instruction est totalement déterministe et peut donc se contenter d'un ordonnancement statique préparé lors de la compilation.
AMD parle également d'amélioration des ordonnanceurs matériels, mais cette fois nous supposons qu'ils ne font pas référence aux CU mais au front-end et aux tâches globales initiées par les processeurs de commandes. Il s'agit ainsi probablement d'améliorations destinées au support du multi-engine de Direct3D 12. Il est également question de nouveaux modes de compression. Il pourrait s'agir de la compression ASTC, coûteuse à implémenter (mais le 14nm règle ce problème) et qu'AMD et Nvidia avaient évité jusqu'ici, contrairement aux concepteurs de GPU pour SoC pour lesquels quelques transistors de plus ne sont jamais trop chers payés pour économiser de la bande passante mémoire et de l'énergie.
Enfin, AMD mentionne un Primitive Discard Accelerator, soit un système d'éjection des triangles masqués du pipeline de rendu. Pour rappel, statistiquement, à peu près la moitié des triangles d'un objet tournent le dos à la caméra et peuvent être éjectés du rendu dès que cet état est confirmé. Pouvoir le faire rapidement permet de booster les performances géométriques en situation réelle.
Actuellement, les moteurs géométriques des Radeon ne sont pas capables d'effectuer cette tâche plus rapidement que le rendu d'un triangle, contrairement aux GeForce qui en profitent pour se démarquer dans certaines scènes, notamment quand la tesselation génère de nombreux triangles masqués. Avec Polaris, AMD devrait enfin combler ce déficit, probablement en doublant le nombre de moteurs d'éjection des primitives par moteur de rastérisation (Nvidia a opté pour une autre approche en décentralisant une partie du traitement géométrique mais nous ne nous attendons pas à ce qu'AMD suive cette voie).

Pour introduire Polaris, contrairement à ce qui se passe habituellement (à l'exception de Maxwell 1 et des GTX 750), AMD met en avant non pas son futur haut de gamme mais un petit GPU prévu pour les PC compacts et pour les portables. Il est équipé de mémoire GDDR5. Nous n'avons pas encore de nom pour ce GPU et n'avons pu l'apercevoir que brièvement sans pouvoir en prendre une photo. Tout juste de quoi apercevoir qu'il s'agit effectivement d'une petite puce et d'un packaging compact.
Sans confirmer que ce serait le premier GPU Polaris disponible, AMD a indiqué que ce petit GPU était important pour sa division graphique, qu'il serait lancé mi-2016 et qu'il serait fabriqué en 14nm chez GlobalFoundries. En précisant ne pas exclure que d'autres GPU soient fabriqués ailleurs, chez Samsung (probablement) ou chez TSMC (de moins en moins probable).
Au niveau de ses spécifications, nous ne saurons rien. Il faudra encore patienter quelque peu, le but d'AMD aujourd'hui étant de nous mettre l'eau à la bouche pour nous faire patienter quelques mois de plus.

Nous avons par contre pu voir ce GPU en action dans une version alpha lors d'un événement presse organisé il y a quelques semaines. AMD a voulu illustrer les gains d'efficacité énergétique apportés par Polaris par rapport à un GPU Maxwell, déjà très efficace. Des chiffres à prendre avec des pincettes, puisqu'ils restent dans le fond assez vagues et avec des conditions de mesure discutables, mais qui font état d'une progression fulgurante du rendement de l'architecture GCN.
Un système équipé d'un petit GPU Polaris est ainsi capable de maintenir 60 fps dans Star Wars Battlefront avec une consommation totale mesurée à la prise de 86W là où un même système équipé d'une GTX 950 demande 140W. Difficile d'en déduire exactement la consommation GPU et ce gain peut en partie être lié à la combinaison d'une puissance GPU supérieure avec un V-Sync à 60 Hz qui permet de rester à une plus faible fréquence, d'ailleurs le GPU utilisé est configuré à 850 MHz pour 0,8375v seulement. Mais de toute évidence Polaris en 14nm va enfin permettre à AMD de faire mieux que Maxwell en 28nm.
AMD tient d'ailleurs à préciser que cette démonstration a été effectuée avec un support partiel de Polaris par les pilotes. Les gains d'efficacité proviennent ainsi uniquement du 14nm et des CU GCN 4, le support des nouveaux mécanismes dédiés à économiser de l'énergie n'ayant pas encore été implémenté.
Bien entendu, les GPU Polaris n'auront pas simplement affaire aux GPU Maxwell actuels mais bien aux GPU Pascal et peut-être à de petits GPU Maxwell 2 fabriqués en 16/14nm. Et il est beaucoup trop tôt pour savoir comment s'opposeront ces futurs concurrents. Pour la première fois depuis très longtemps, il est d'ailleurs intéressant de noter qu'un élément tiers pourra venir semer le trouble dans le combat AMD vs Nvidia : les fondeurs. En effet, il semble de plus en plus probable qu'AMD exploite principalement les process 14nm de GlobalFoundries et Samsung alors que Nvidia exploiterait plutôt le 16nm de TSMC. Si l'un de ces process s'avère meilleur que l'autre, le fabricant de GPU qui aura misé sur le bon cheval s'en trouvera mécaniquement avantagé même si le process ne fait pas tout.
Vous retrouverez la présentation complète ci-dessous :















Dossier : AMD Radeon R9 380X : les cartes Asus Strix et Sapphire Nitro en test
Pour renforcer son offre face aux GTX 900, AMD introduit la Radeon R9 380X avec un GPU Tonga qui monte enfin en puissance. Est-ce suffisant pour faire la différence ? La réponse dans notre dossier complet.
[+] Lire la suite
