
Les derniers contenus liés au tag Mali
ARM annonce les Cortex-A75, A55 et Mali G72
ARM annonce le Cortex-A73 et le Mali-G71
Jugement favorable pour Samsung face à Nvidia
ARM annonce Cortex-A72, Mali-T880 et CCI-500
ARM annonce les Cortex-A75, A55 et Mali G72



ARM vient d'annoncer de nouveaux blocs processeurs pour ses partenaires, sous le nom de Cortex-A75 et A55 (pour un rappel sur la stratégie d'ARM, nous vous renvoyons au début de cet article). Ces nouveaux Cortex sont des coeurs CPU clefs en main qui peuvent être utilisés par les partenaires d'ARM pour concevoir leurs SoC.
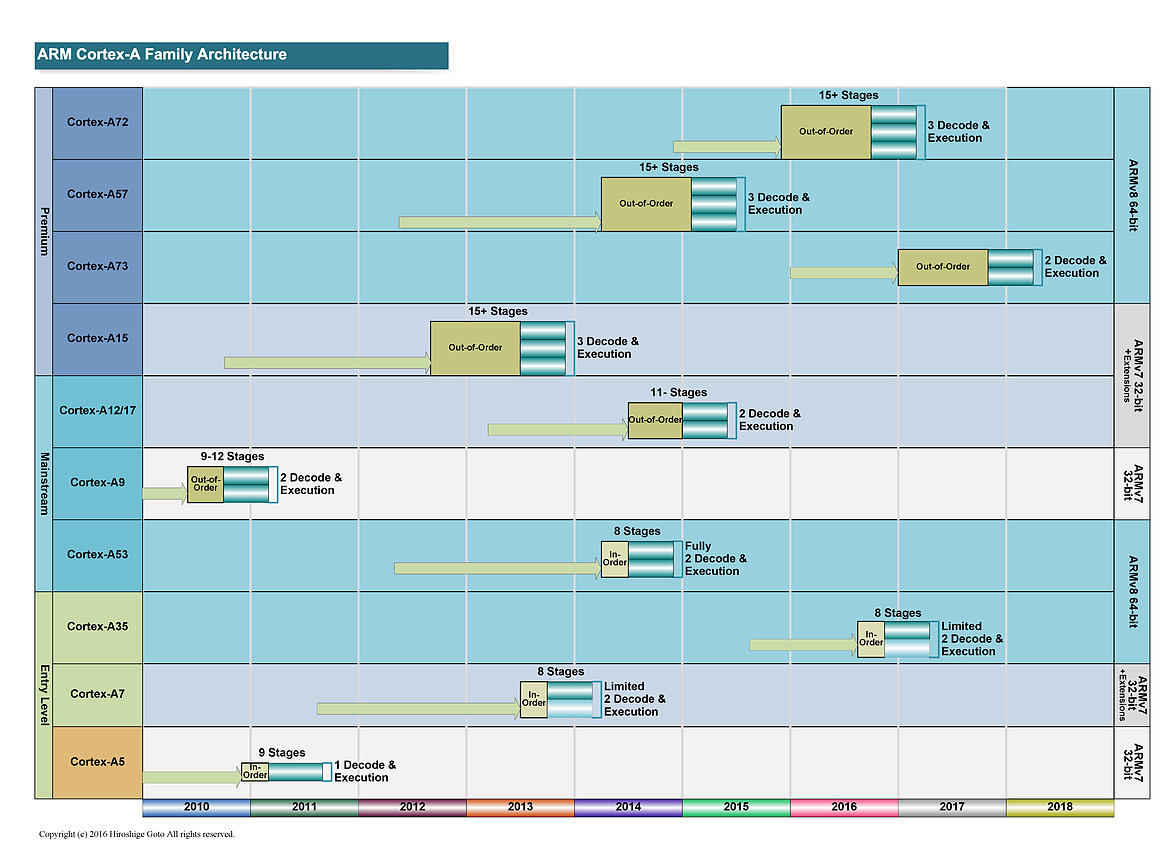
Les nomenclatures marketing d'ARM sont assez complexes à déchiffrer, la société dispose de plusieurs équipes qui font évoluer en parallèle des versions différentes de leurs architectures. Pour les "gros" coeurs, on retrouve deux familles distinctes avec d'un côté des "très gros" coeurs qui tendent à consommer significativement plus d'énergie. Ce sont les Cortex A15, A57 et A72 développés par l'équipe d'Austin. En parallèle, une autre équipe à Sophia-Antipolis développe des "gros" coeurs un peu plus efficaces comme les A12, A17 et plus récemment A73.
A l'origine, cette gamme était vue comme un intermédiaire par ARM même si la consommation élevée des "très gros" coeurs tend la société à pousser aujourd'hui les coeurs "Sophia" sur le haut de gamme mobile. Cette tendance se confirme aujourd'hui puisque l'A75 est en pratique le successeur de l'A73.
Techniquement ces puces se distinguent par un pipeline plus court, et sur ce point l'A75 ne change rien en gardant un pipeline court de 11 étapes pour les instructions entières. Le plus gros changement concerne le nombre d'instructions décodées par cycle puisque l'on passe de deux instructions décodées à trois, alignant sur cette caractéristique l'A75 avec ce qui se faisait sur les "très gros" ARM. On passe donc en pratique de 6 micro-ops par cycle à 8. Le nombre d'unités reste identique mais l'A75 ajoute des files supplémentaires pour stocker les micro-ops à traiter.
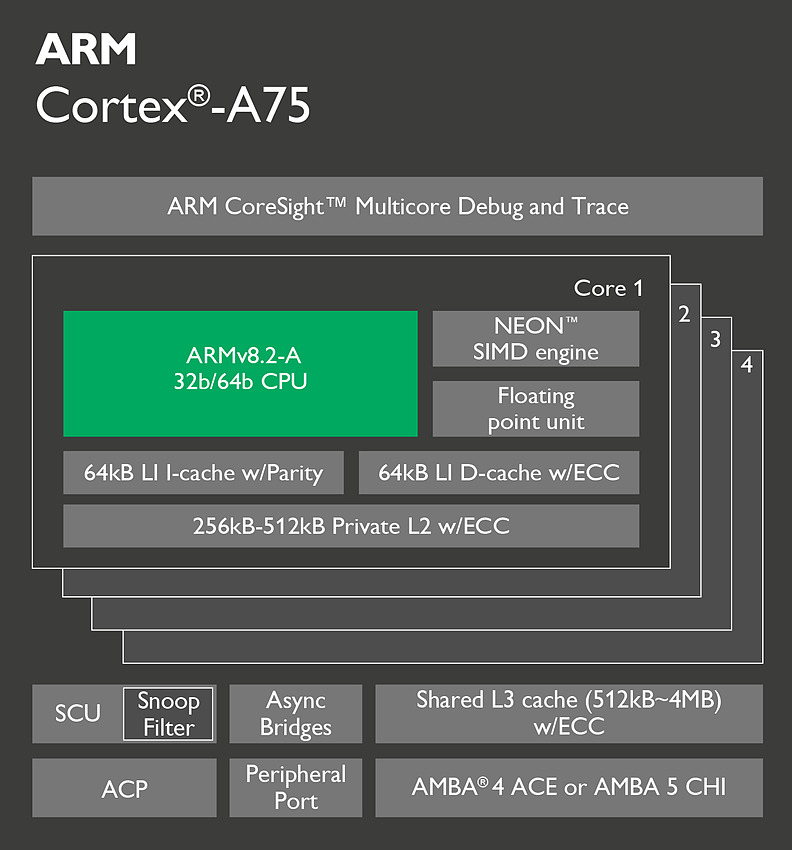
ARM applique un changement similaire pour les instructions flottantes et vectorielles (on parle de NEON dans le marketing ARM, le pendant de SSE/AVX sur x86) avec là aussi la possibilité de décoder trois instructions par cycle. Cela s'accompagne par une file supplémentaire et une troisième unité NEON spécifiquement utilisée pour les accès mémoire.
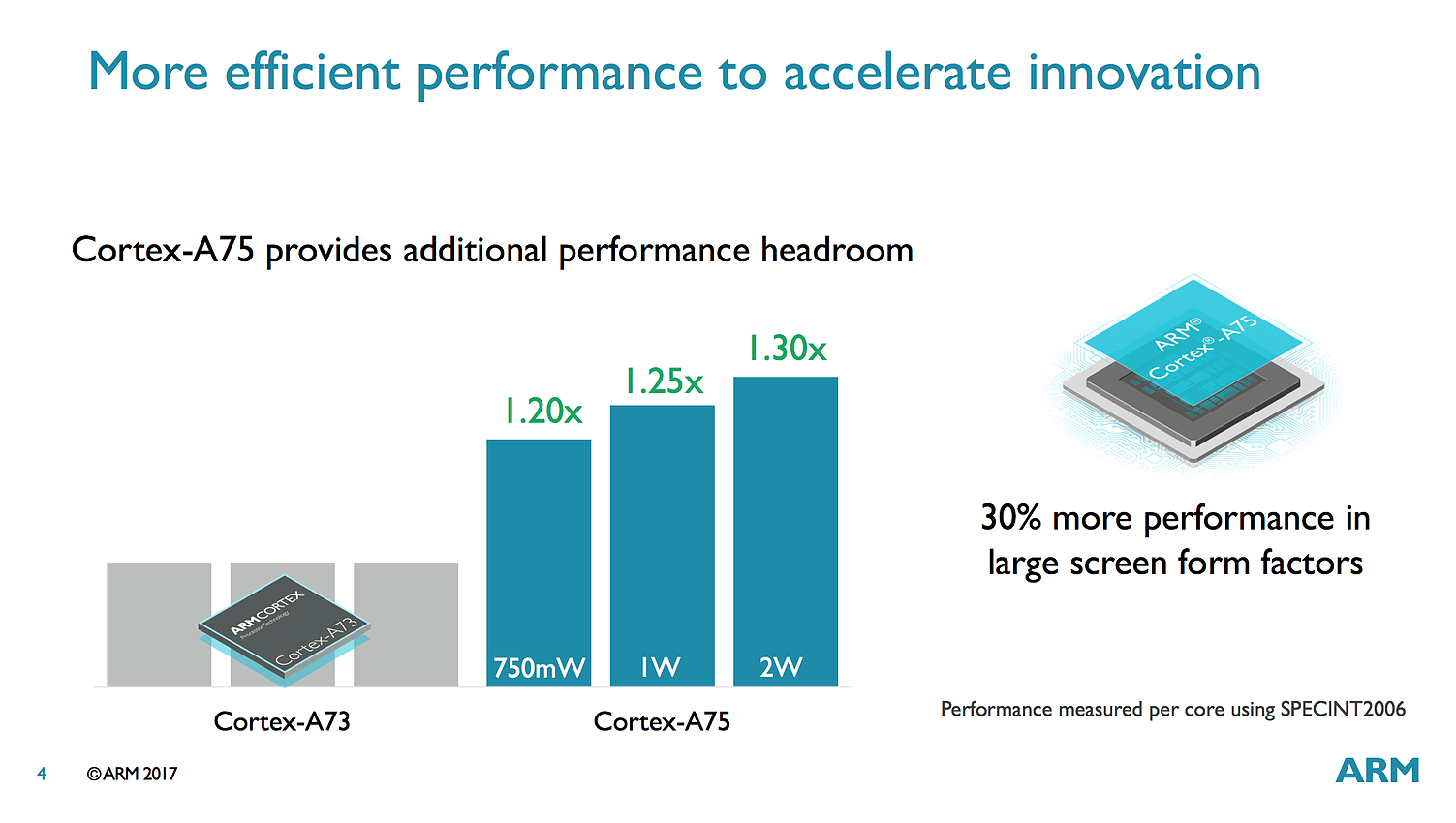
ARM annonce des gains de performance allant de 20 à 30% pour l'A75 rapport à l'A73 en fonction de la consommation autorisée, ce qui est plutôt intéressant. L'A75 est un bloc qui comme l'A73 est prévu pour le 10nm et il devrait faire son apparition en toute fin d'année ou plus probablement l'année prochaine dans des produits commerciaux.
Un nouveau coeur LITTLE
En plus des gros coeurs dont nous vous parlions au-dessus, ARM propose également des coeurs plus petits, à la consommation beaucoup plus faible et qui ont pour but d'être appairés à des gros coeurs dans ce qu'ARM appelait jusqu'ici des configurations big.LITTLE. Après avoir utilisé dans ce rôle l'A53 depuis plusieurs années (il avait été introduit en 2012 !), ARM propose enfin une nouvelle mouture de son petit coeur baptisée Cortex-A55.
Il s'agit toujours d'un coeur dit "In Order", les instructions ont exécutées dans l'ordre dans lequel elles arrivent (à l'opposé des processeurs plus gros/modernes qui utilisent des architectures "Out Of Order", les instructions sont réordonnancées pour optimiser l'exécution et améliorer le parallélisme).
Il y a assez peu de changements sur l'A55, le plus gros concerne la séparation des unités de lecture/écriture mémoire ainsi qu'un nouveau prédicteur de branchements. Le reste des changements se situant au niveau des caches mémoires qui ont été reconfigurés.
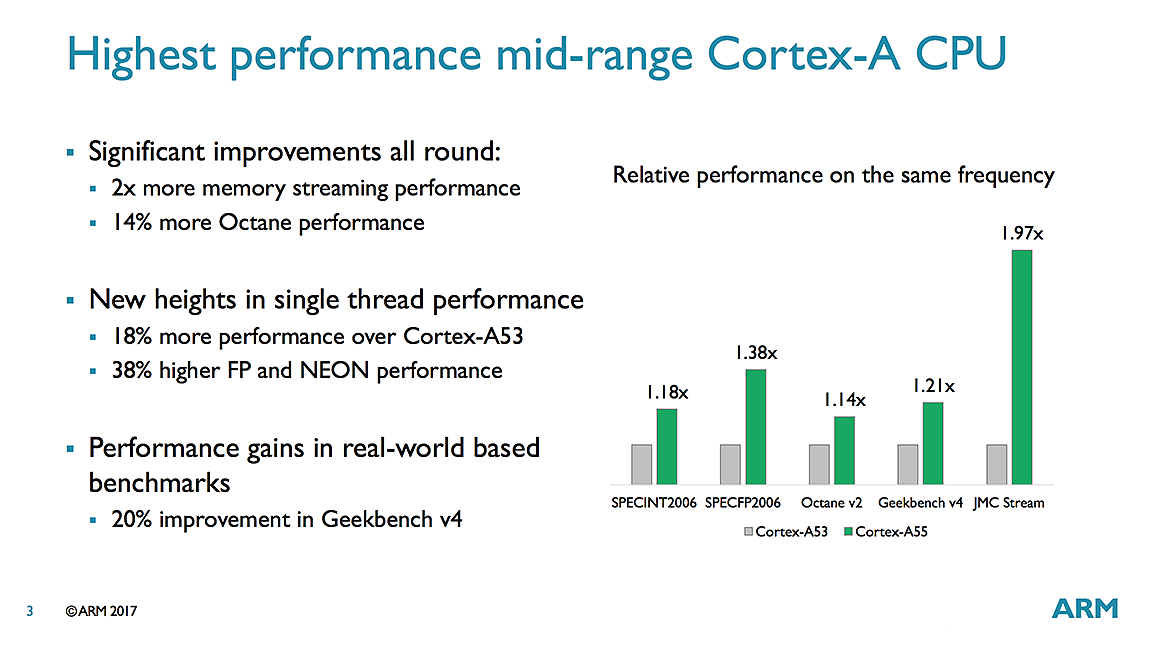
ARM annonce des gains de performances autour de 20% sur l'A55 à fréquence égale par rapport à un A53, des gains qui peuvent cependant monter beaucoup plus haut quand on prend en compte les caches. Sous SPECFP2006, la société annonce ainsi 38% de gains.
DynamIQ, big.LITTLE V2.0
Le concept du big.LITTLE évolue et prend désormais le nom de DynamIQ. ARM a repensé la manière dont il permettait de relier ses coeurs entre eux et propose un nouveau concept qui résout beaucoup de problèmes sur le papier.

L'idée principale est de remplacer big.LITTLE par des "clusters" qui peuvent regrouper jusque huit coeurs. On pourra mélanger au sein d'un cluster différents types de coeurs (par exemple quatre A75 et quatre A55) ce qui engendre un changement important au niveau de la structure des caches. Désormais, chaque coeur ARM (A55 ou A75) disposera de son propre cache L1 et de son propre cache L2. Ce changement est bienvenu et devrait éviter ces bugs embarrassants comme celui de Samsung et de son M1 qui mélangeait ses coeurs à des A53 avec des lignes de caches différentes.
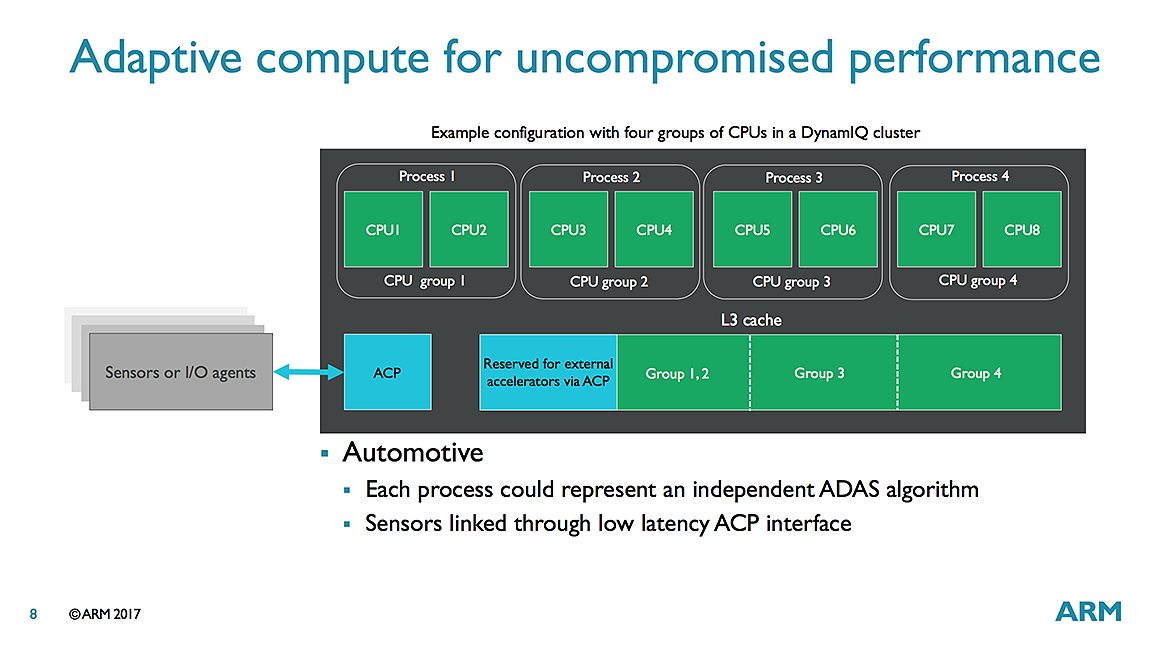
Tous les coeurs d'un cluster partageront un cache L3 commun (jusque 4 Mo) et l'on pourra disposer de plusieurs clusters - jusque 32 - au sein d'une puce (quelque chose qui devrait surtout servir pour d'éventuelles versions serveurs de ces processeurs). Une organisation qui n'est pas sans rappeler celle utilisée par AMD avec ses CCX dans Ryzen, on notera qu'ARM indique que son cache L3 peut être partitionné dynamiquement pour certains coeurs ou pour d'autres applications.
En bref
On notera également côté GPU l'arrivée une version optimisée du Mali G71, baptisé G72 pour lequel il n'y a pas de changement majeur au niveau de l'architecture Bifrost d'ARM. L'augmentation de la taille des caches permet d'augmenter l'efficacité énergétique ce qui est appréciable.
Si les modifications effectuées sur les Cortex A75 et A55 sont intéressantes, on retiendra surtout de l'annonce d'ARM l'arrivée de DynamIQ qui devrait permettre de mieux exploiter les coeurs. Car si big.LITTLE était sur le papier une bonne idée, son implémentation pratique avait montré de multiples limites. Cette nouvelle approche sous la forme de clusters contribue aussi sur les gains de performances, tout comme la réorganisation des caches.
Le sous-système mémoire des Cortex a toujours été la faiblesse de l'architecture avec des contrôleurs extrêmement optimisées pour la basse consommation, mais pas forcément pour les performances ce qui donne aux architectures ARMv8 tierces (comme celles d'Apple et même de Samsung) un avantage en général très net sur ce point.
ARM annonce le Cortex-A73 et le Mali-G71
ARM vient d'annoncer de nouveaux blocs disponibles pour ses partenaires. Pour rappel, ARM développe en parallèle des architectures (ARMv8-A pour la dernière version 64 bits, le pendant du x86-64 dans le monde du PC) et propose aussi ses propres implémentations de coeurs qui peuvent être utilisés par ses partenaires sous licence (l'équivalent dans le monde PC serait Intel qui autorise ses partenaires à faire des versions "custom" de Skylake).
Certains des partenaires d'ARM disposent d'une licence dite "architecture" (Apple, Qualcomm, Samsung, Nvidia...) qui leur permet de réaliser leurs propres implémentations (de la même manière qu'AMD et Intel proposent des processeurs compatibles, mais différents derrière la même architecture x86-64), même si ces derniers proposent parfois les deux. Qualcomm propose par exemple des puces utilisant les Cortex (implémentation ARM) et ses propres Snapdragon.
La nomenclature des implémentations d'ARM a toujours été compliquée à comprendre, pour ne pas dire autre chose, et autant dire qu'aujourd'hui ARM n'arrange pas son cas avec l'A73. Il fait suite sur le papier au Cortex-A72 qui avait été annoncé en février 2015 même si d'un point de vue technique les puces sont différentes.
Ce diagramme permet d'y voir un tout petit peu plus clair. Après l'époque "simple" de l'A9, ARM a proposé d'un côté des cores de grande taille, visant les hautes performances (A15, A57 et A72), également appelés big. Il s'agit de designs "Out of Order" (le processeur peut changer l'ordre des instructions pour optimiser leur exécution).
En parallèle des coeurs de plus petite tailles ont été présentés (les coeurs LITTLE comme l'A7 et l'A53). Ils utilisent un design dit "In Order" (pas de changement d'ordre) qui simplifie l'implémentation, et réduit donc la consommation de la puce. Leur niveau de performance est plus bas, mais ils disposent d'un meilleur rapport performance/watts que les coeurs big. Leur intérêt théorique est de les mélanger pour créer une architecture asymétrique (big.LITTLE, voir la présentation ici) même si en pratique, ce n'est pas toujours ce qui s'est passé.
Les deux familles sont développées par des équipes différentes (Austin pour les big et Cambridge pour les LITTLE) et au milieu de tout cela, on retrouvait les A12 et A17, mélangés sur ce graph (par une troisième équipe a Sophia-Antipolis). Il s'agissait là aussi de designs "Out of Order" mais un peu plus optimisés pour un meilleur rapport performances/watts.
Si en théorie ces puces étaient présentées comme dédiées au milieu de gamme, en pratique elles proposaient surtout une alternative aux gros coeurs ARM dont la consommation était trop élevée, obligeant de limiter fortement les fréquences pour rester dans l'enveloppe thermique d'un smartphone. On a pu voir un certain nombre de retards lors de la génération A57, particulièrement chez Qualcomm, et une surconsommation importante par rapport à ce qu'espérait ARM. Une situation qui a même poussé certains des partenaires d'ARM a proposer des puces n'utilisant que les coeurs LITTLE, un comble.
Cortex A73 : 10nm
Le Cortex A73 est présenté par ARM comme son nouveau coeur big. Il fait suite à l'A72 (16nm) et sera proposé pour les processus de fabrication 10nm. Mais contrairement à ses prédécesseurs big 64 bits (A57 et A72, c'est dur à suivre !), il s'agit sur le papier du successeur des A12/A17 (qui eux n'étaient disponibles qu'en 32 bits).
Contrairement aux A57/A72 qui pouvaient décoder trois instructions par cycle, on se limite cette fois ci à deux sur l'A73. En contrepartie, le pipeline (le nombre d'étapes par lequel les instructions passent) est significativement réduit, passant de 15 à 11 étapes. C'est au niveau du front end (récupération des instructions, décodage, changement d'ordre) que la réduction se fait. On retiendra deux changements importants, d'abord le fait que les instructions en virgules flottantes/NEON (l'équivalent des instructions vectorielles type SSE dans les architectures x86) soient traitées séparément via un décodeur distinct. La seconde est un changement au niveau des instructions arithmétiques entières avec des unités moins nombreuses mais plus performantes.

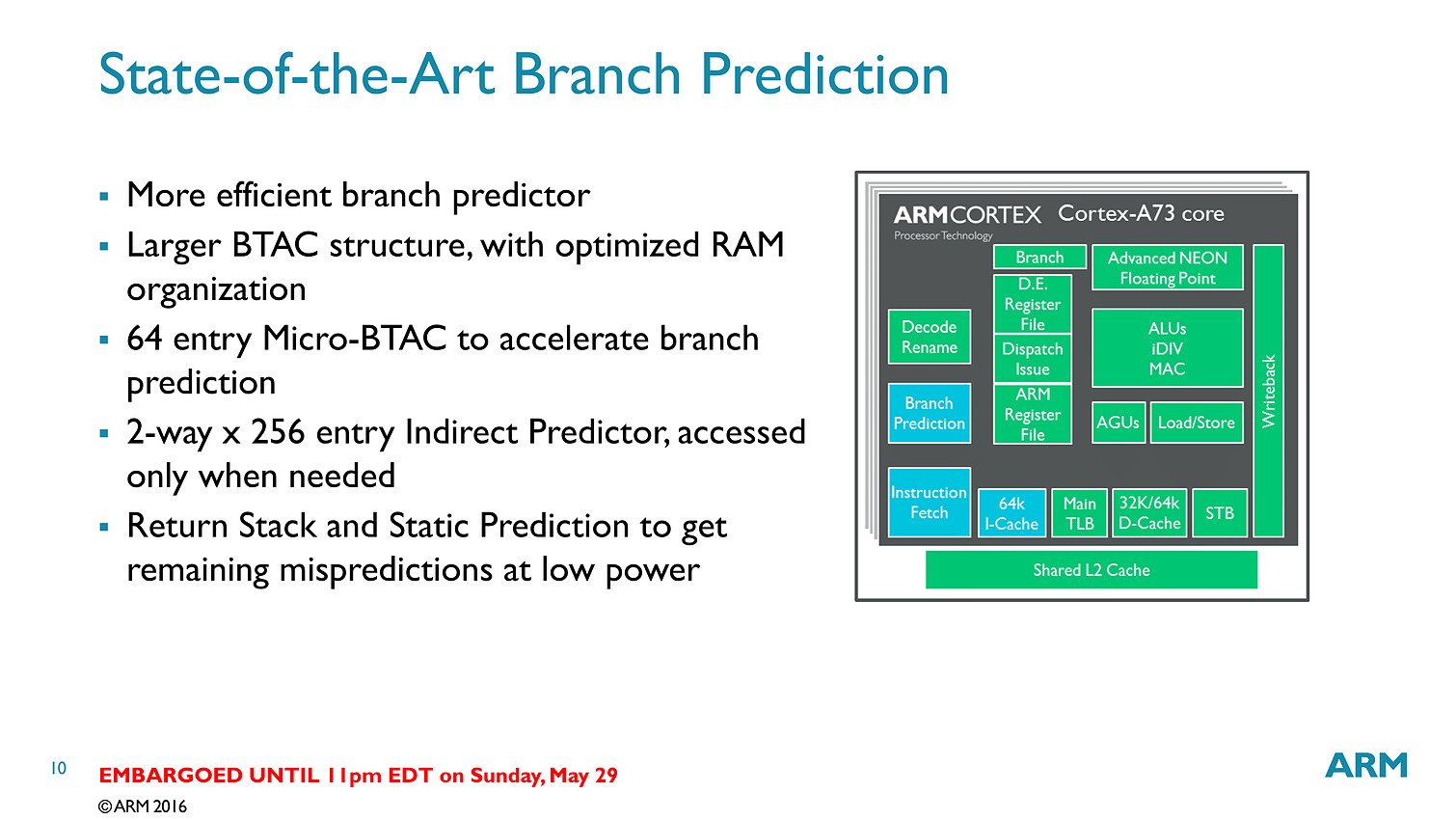


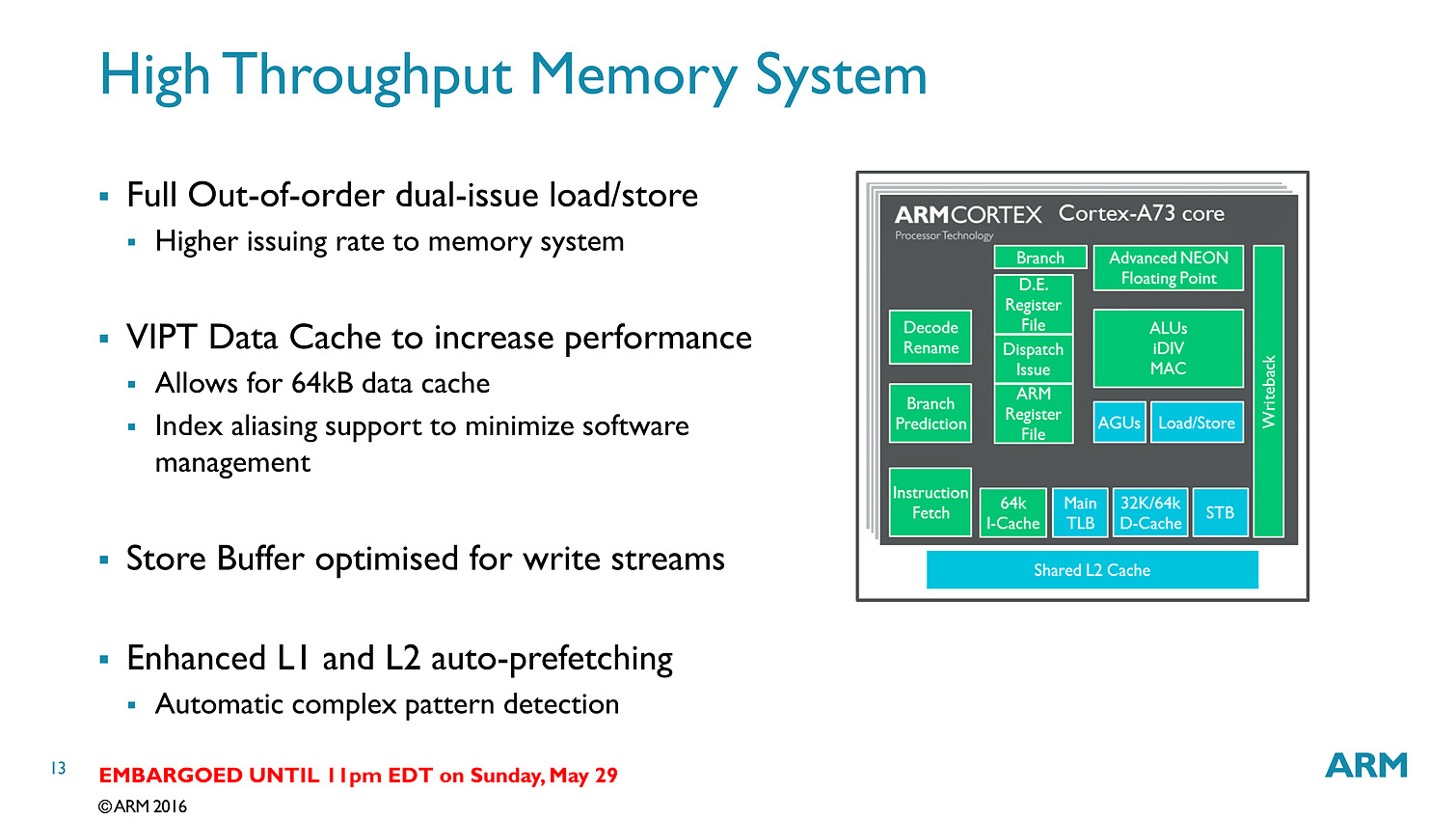
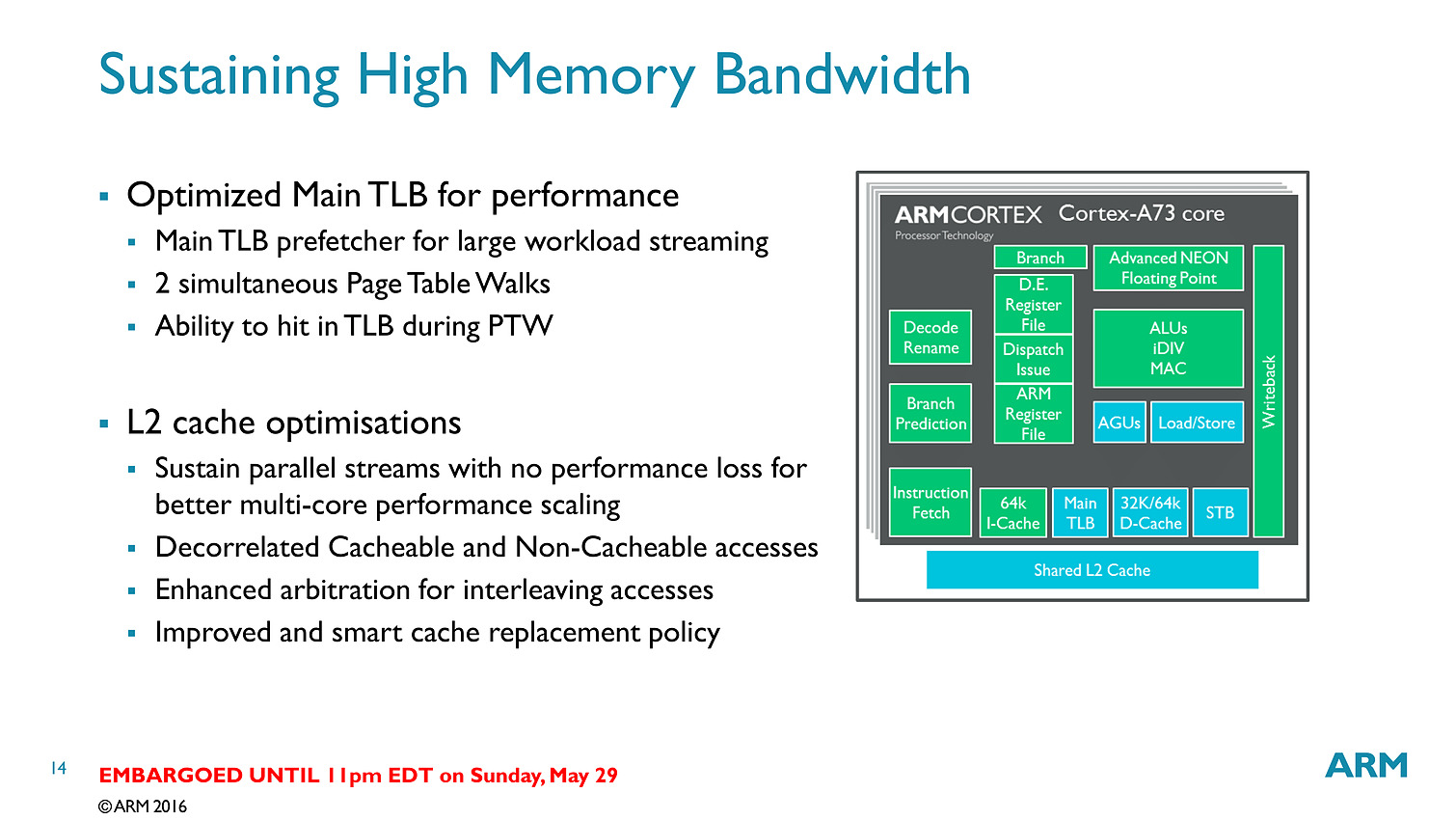
Bien que décodant une instruction par cycle en moins, l'A73 permet sur le papier au final de dispatcher 6 micro-instructions par cycle, contre 5 pour l'A72. Si l'on ajoute toutes les autres optimisations (le sous système mémoire, point faible historique des Cortex semble avoir évolué), l'A73 est annoncé comme 10% plus performant que l'A72, à fréquence/process égal.
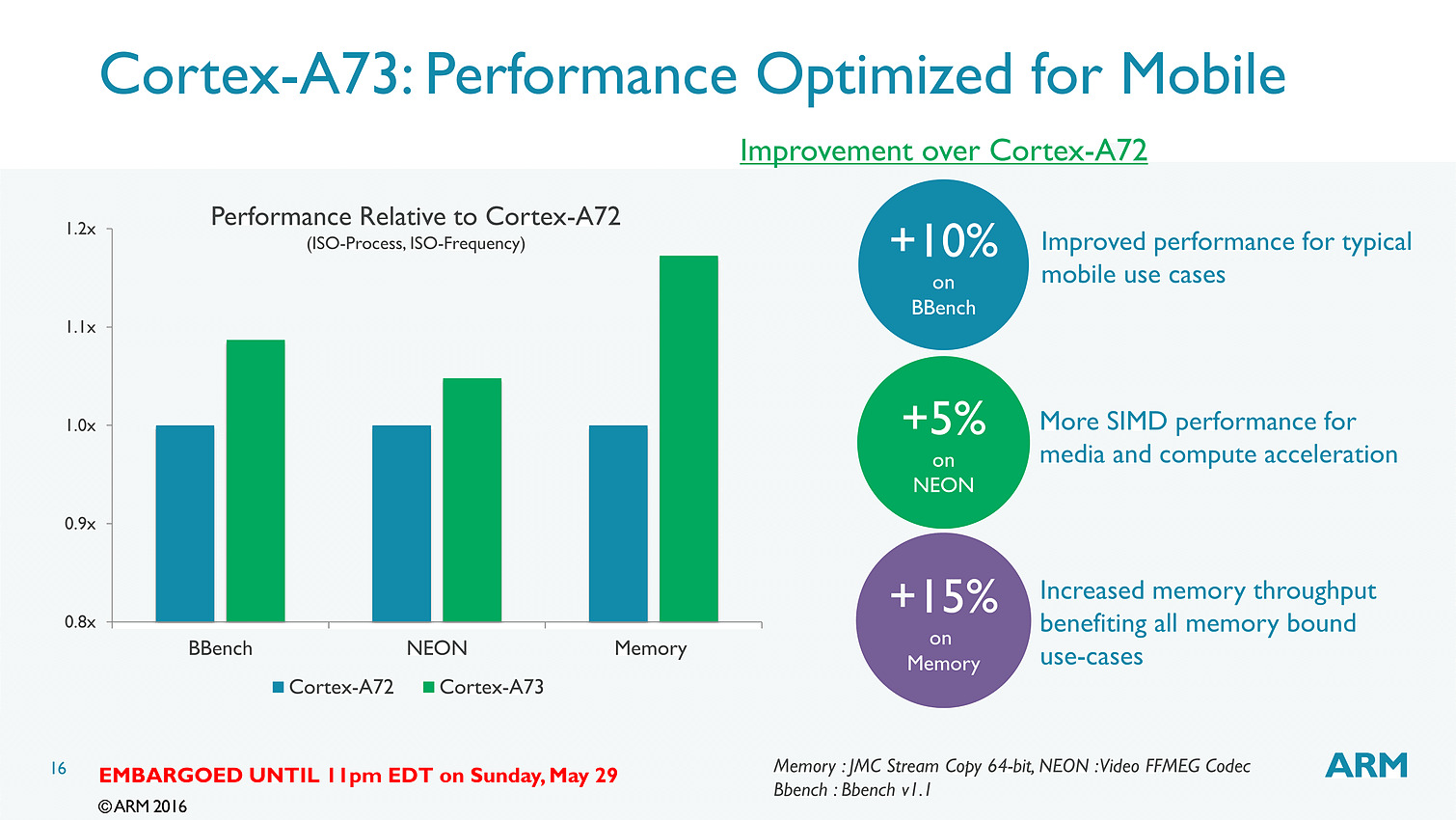
Dans le détail, ARM annonce plus spécifiquement 15% de gains sur les copies mémoire, et 5% sur un encodage FFMPEG utilisant les instructions vectorielles NEON. Notez qu'a process égal, un coeur A73 est 25% plus petit qu'un coeur A72 et consomme 20% d'énergie en moins. En 10nm, un coeur A73 ne mesure que 0.65mm2.
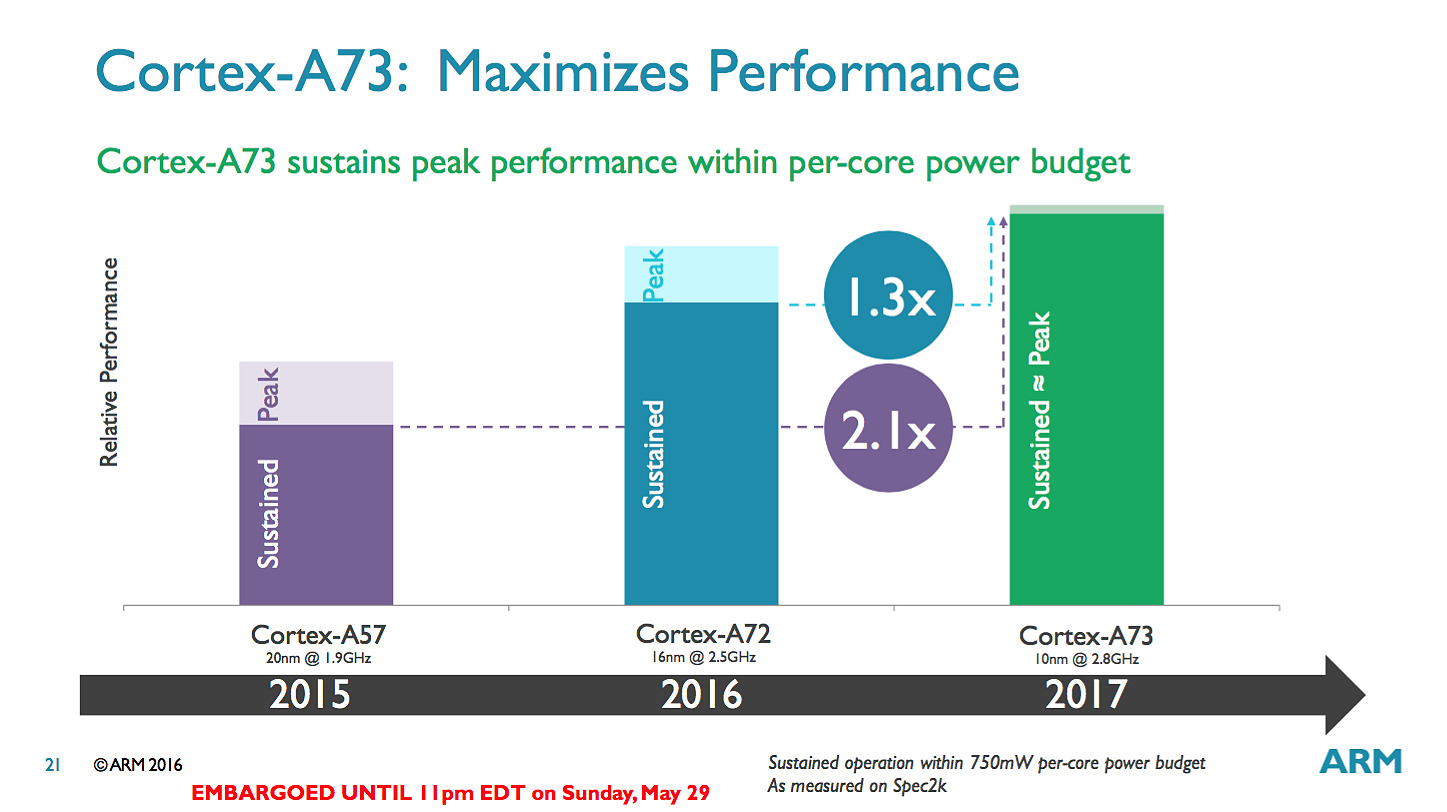
Pour les puces que l'on retrouvera dans le commerce, ARM annonce 30% de performances en plus par rapport aux A72 en profitant du 10nm et de la baisse de consommation pour augmenter la fréquence. Un autre gain significatif mis en avant par le constructeur est que ses puces ne devraient plus voir leur fréquence chuter drastiquement lorsque l'on utilise tous les coeurs en simultanée.
Sur le papier l'A73 est un meilleur compromis côté architecture que ses prédécesseurs, ce qui devrait ravir les partenaires d'ARM, assez peu heureux des A57. Si ARM vise le 10nm, en pratique il propose à ses partenaires des designs A73 en 28, 16 et 10nm. D'ici la fin de l'année, des SoC 16nm devraient faire leur apparition et c'est probablement là qu'on les trouvera en masse (le 10nm sera probablement, pour rappel, réservé au moins dans un premier temps aux gros acteurs du marché comme Qualcomm et Apple à l'image de ce que l'on avait vu avec le 20nm).
Mali-T71 et Bifrost
L'autre annonce d'ARM concerne les GPU. En plus de blocs CPU, ARM propose également à ses partenaires des blocs graphiques qu'ils peuvent utiliser ou non (d'autres sociétés comme Imagination Technologies proposent par exemple leur PowerVR) pour créer leurs SoC.
La nouvelle puce est baptisée T71 et vient faire suite aux GPU T800 dont nous vous avions parlé l'année dernière. Le changement de nomenclature annonce en réalité un changement d'architecture, on passe de l'architecture Midgard à la bien nommée Bifrost.
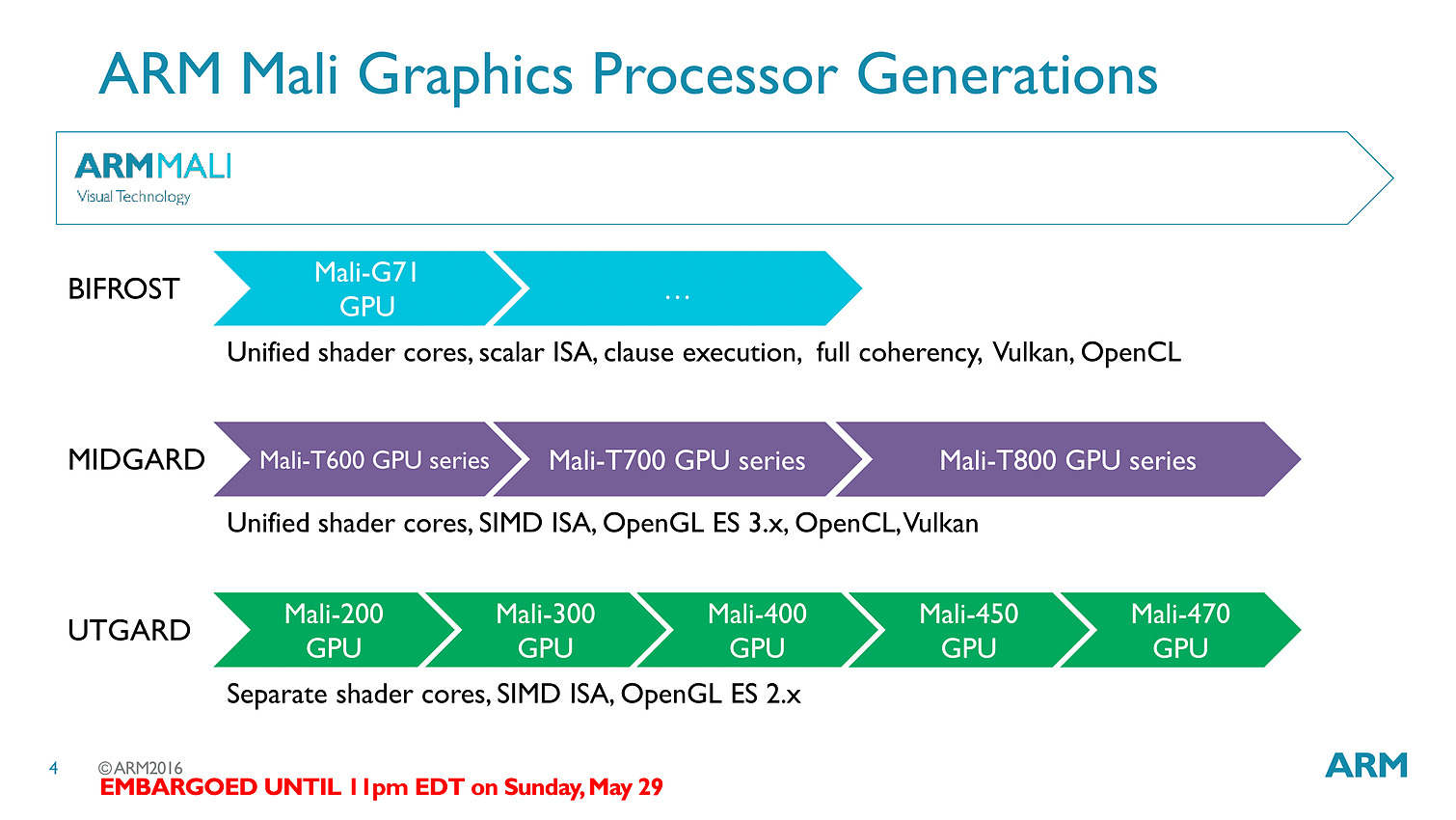
La transition est importante avec un changement complet de philosophie, passant d'un modèle VLIW (Very Long Instruction Word) à un modèle scalaire... soit exactement la transition qu'avait effectué AMD avec GCN !

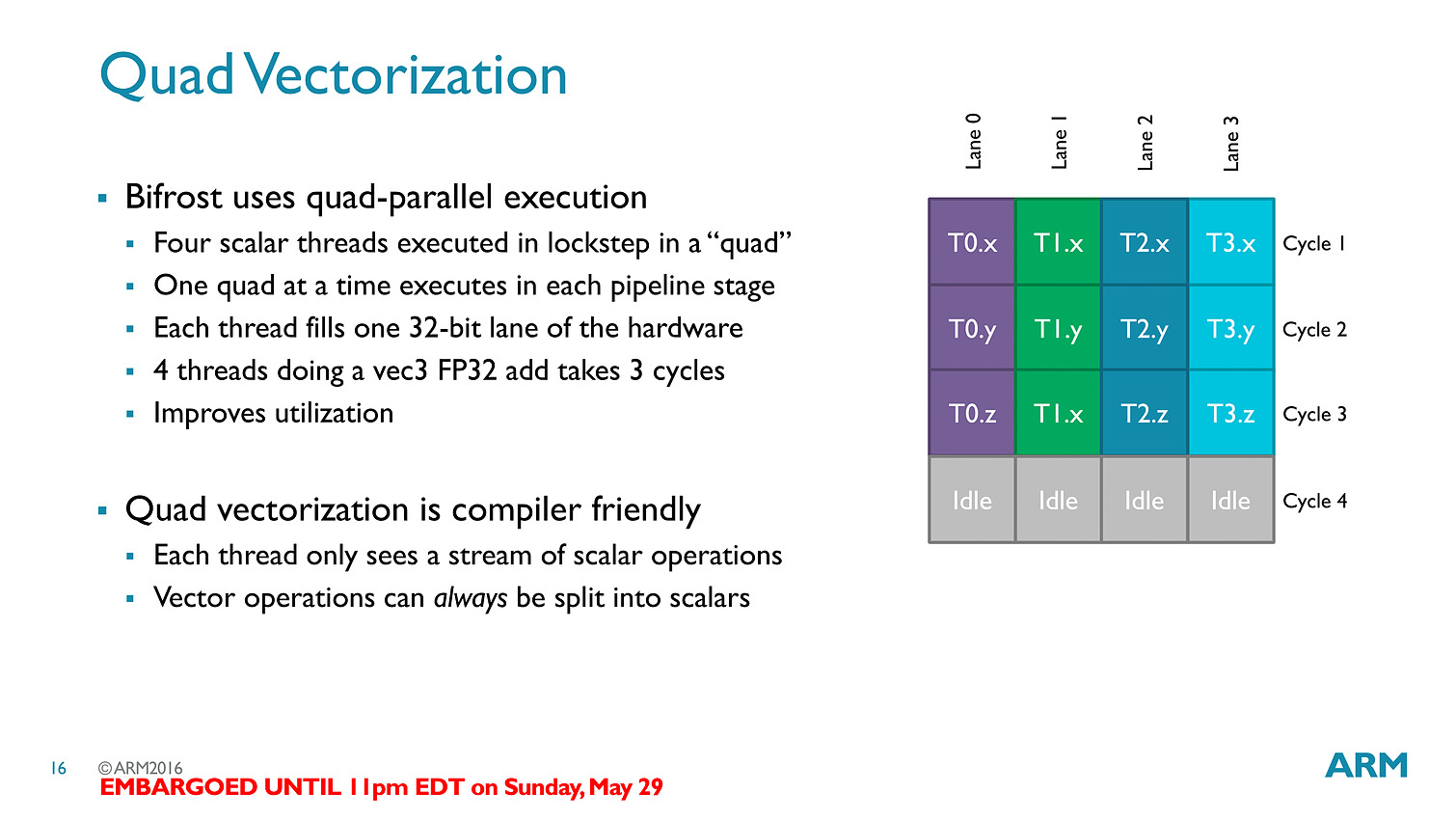
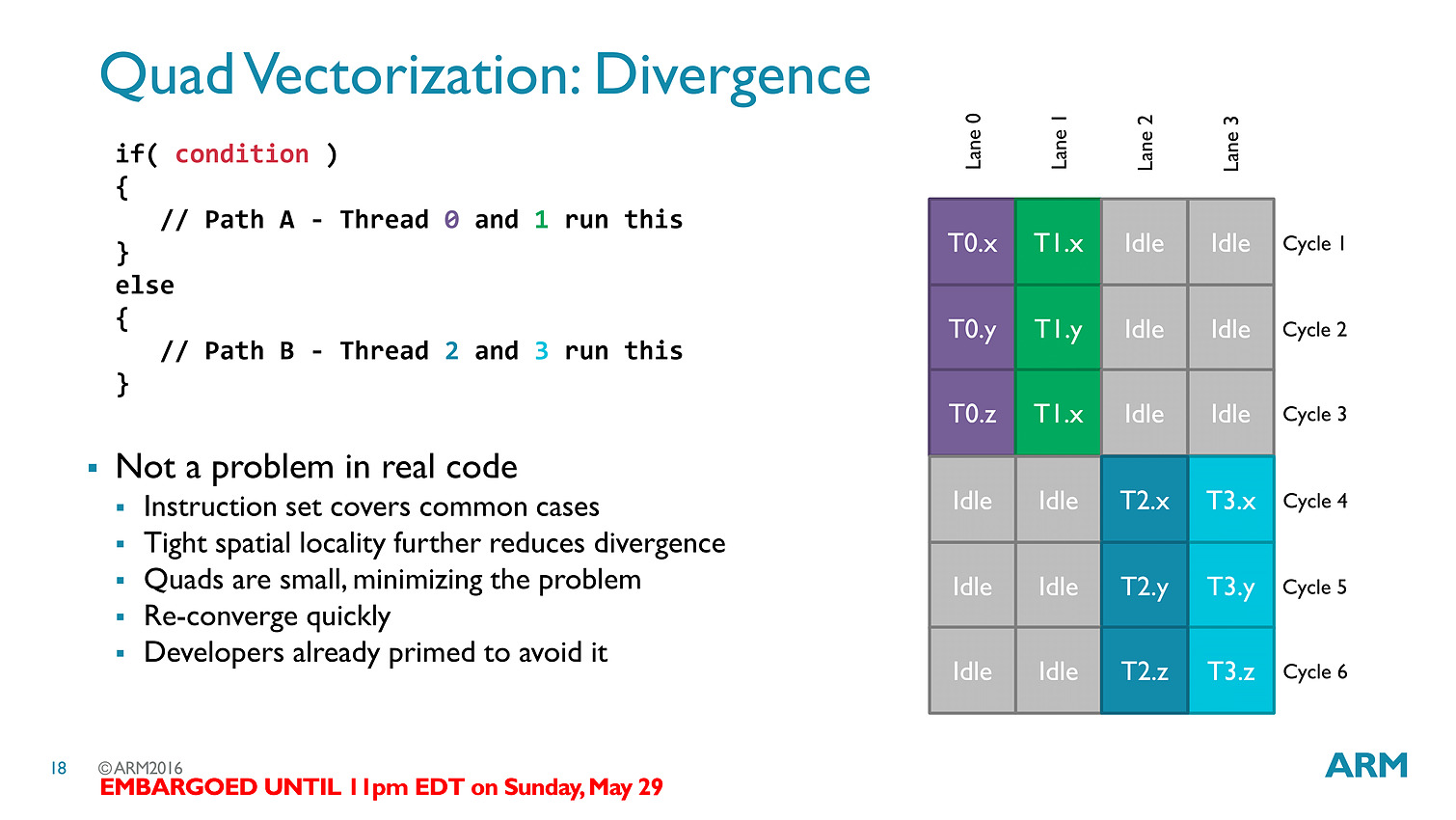
La transition aux unités scalaires change en pratique l'ordre dans lequel les données sont traitées, en simplifiant la compilation des shaders (le parallélisme étant extrait des threads, et non d'assemblage d'instructions par le compilateur).

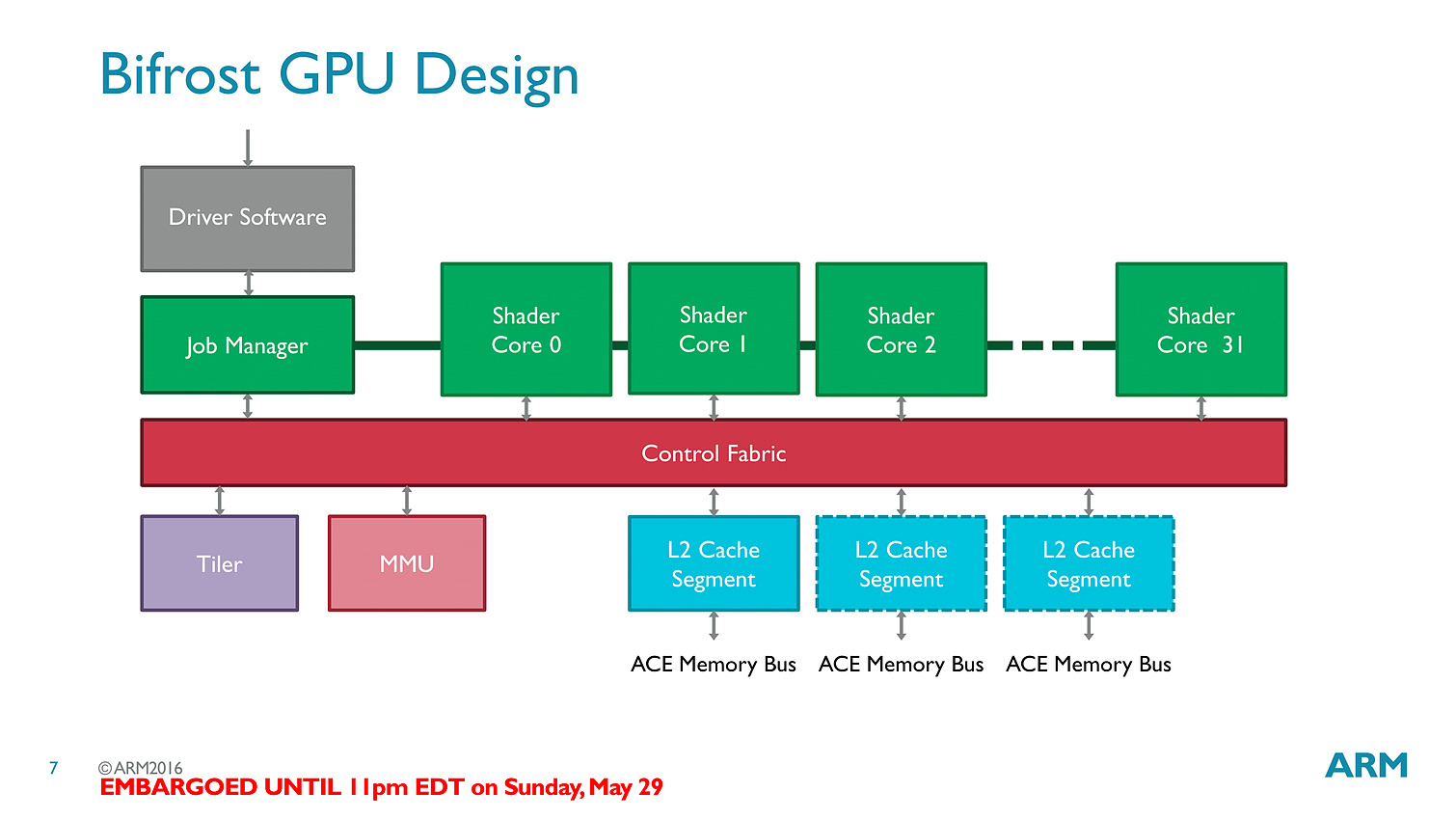
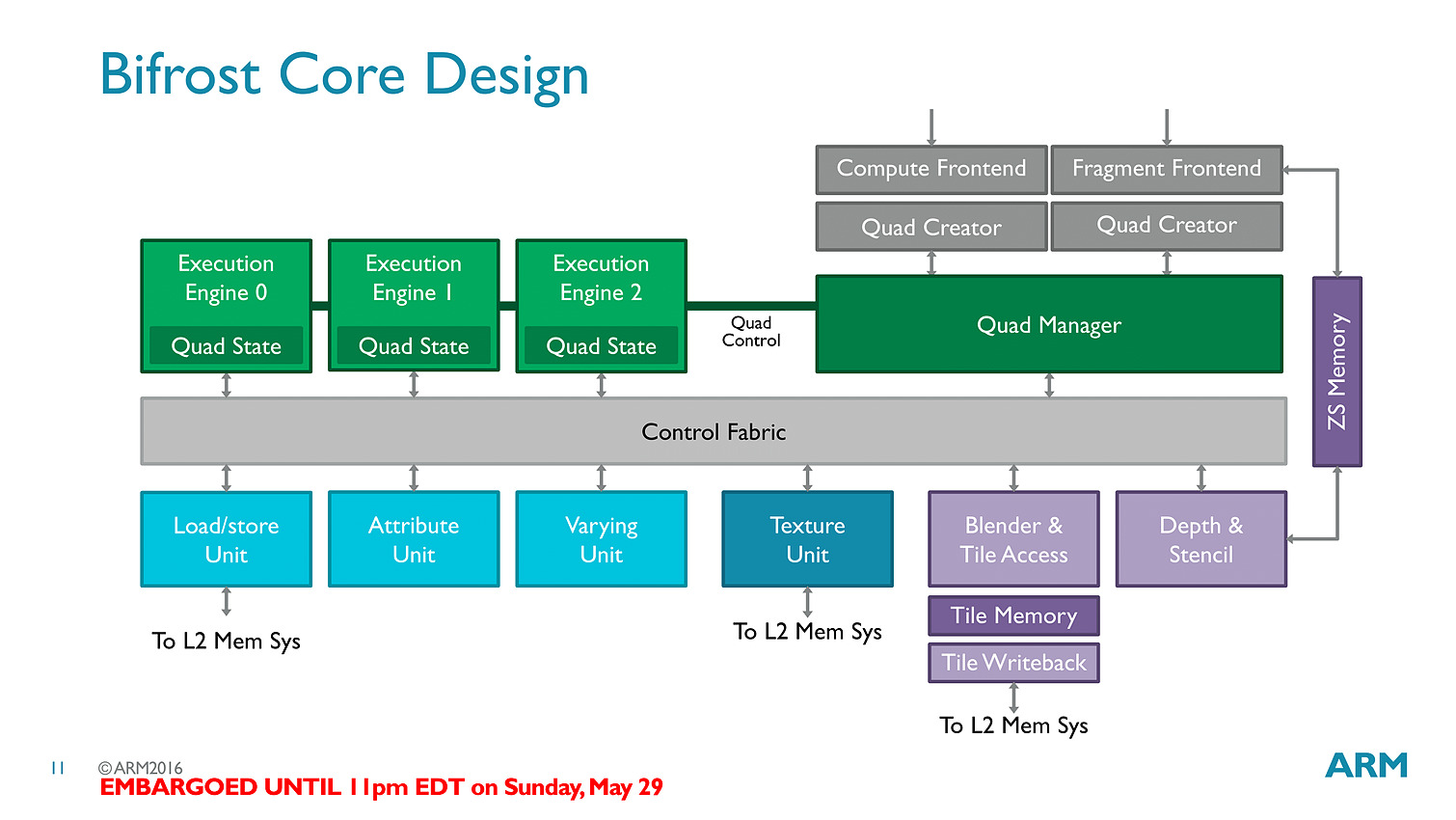
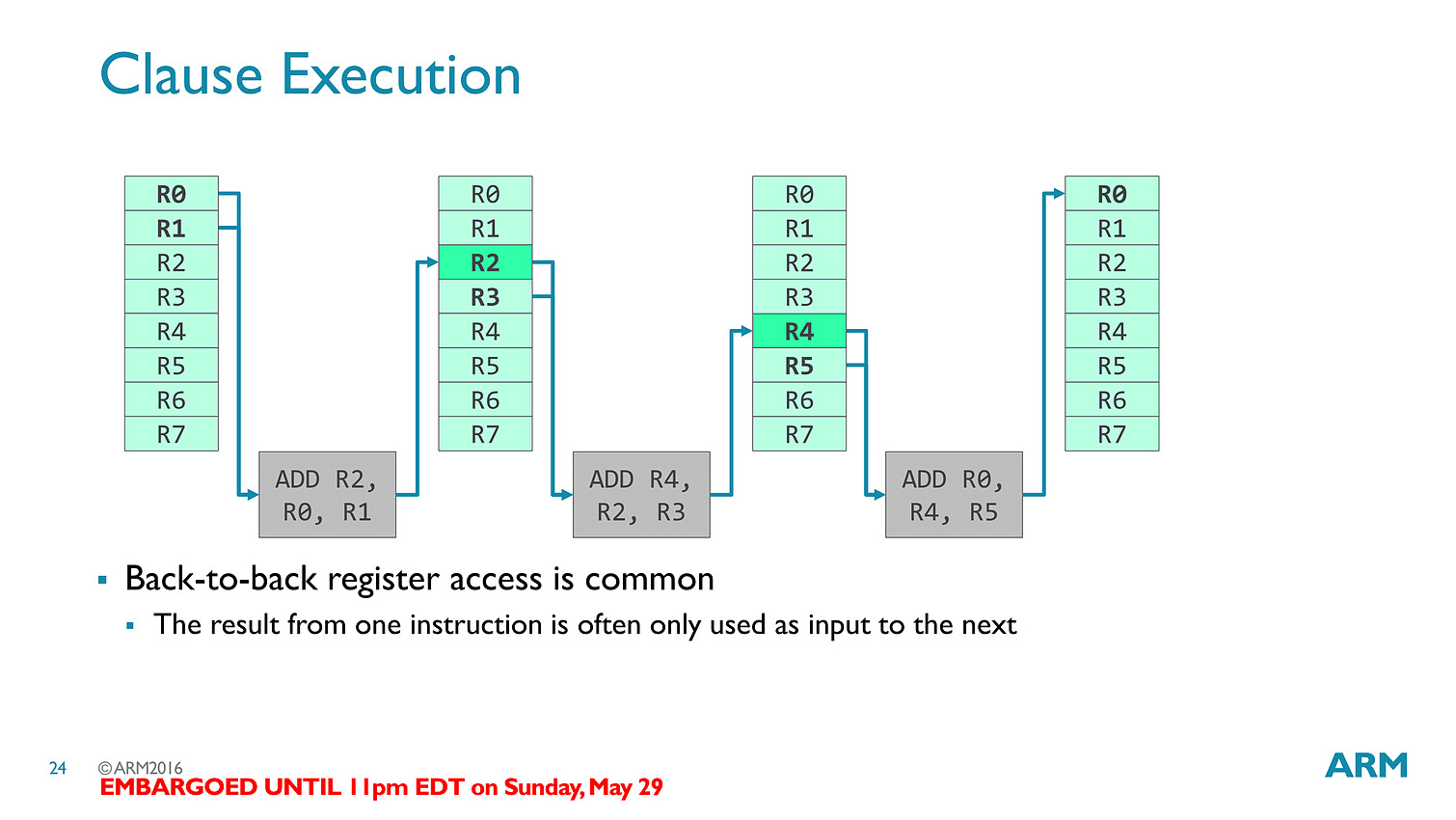
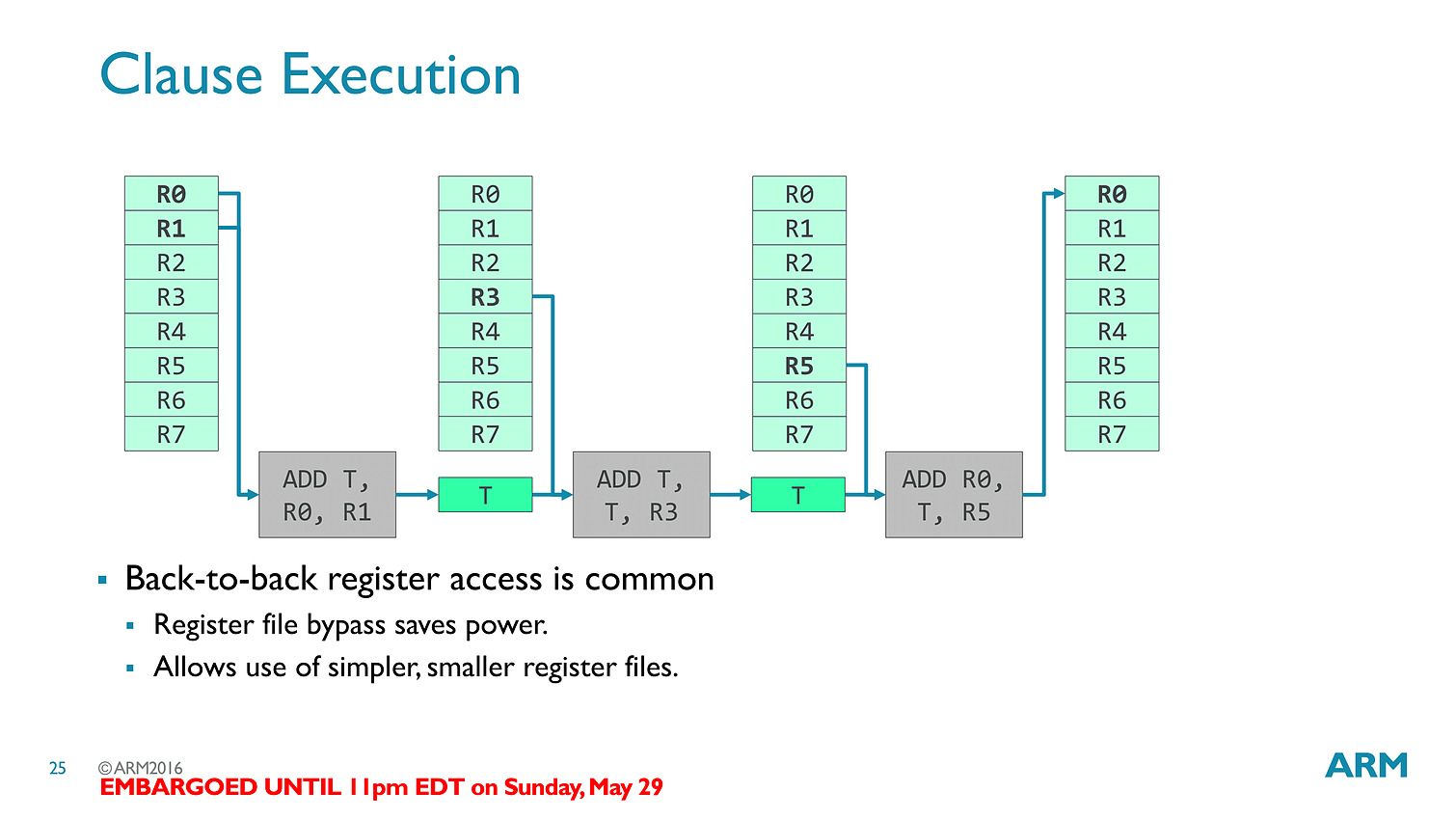

Les threads - clauses dans le langage ARM - sont particulièrement optimisées avec des caches a tous les niveaux (sous la forme de register file) pour s'assurer que les accès mémoires soient optimisés au mieux. Cumulé à tout les autres changements architecturaux (le tiler a également été modifié pour réduire sa consommation mémoire), ARM annonce 50% de gains de performances avec Bifrost.
En pratique le Mali-T71 est le premier GPU ARM utilisant Bifrost, il regroupera jusqu'à 32 shader cores (qui comptent chacun 12 unités scalaires) et reste compatible comme ses prédécesseurs avec OpenGL ES 3.x, OpenCL 2.0 et Vulkan. On rajoutera un dernier mot sur l'interconnexion puisque l'on a droit à un accès au cache fully coherent, ce qui signifie que CPU et GPU peuvent partager la même mémoire cache en opérant en parallèle sans blocage (à la manière de Kaveri chez AMD qui utilisait cependant deux bus distincts), ce qui pourra être utile pour des tâches compute ou l'on fait travailler de concert CPU et GPU (ce qui n'est pas forcément la majorité des usages sur les plateformes mobiles).
Jugement favorable pour Samsung face à Nvidia
 En septembre 2014, Nvidia avait décidé de déposer plainte devant l'ITC (U.S. International Trade Commission) envers Samsung et Qualcomm, demandant le retrait du marché américain de produits dont Nvidia estimait qu'ils violaient certains de ses brevets. Ce dépôt de plainte faisait suite à la « licence Kepler » que Nvidia avait tenté de négocier, laissant penser dans un premier que Nvidia proposerait ses GPU sous forme d'IP aux développeurs de SoC (de la même manière qu'ARM propose des blocs CPU tout faits sous la forme des Cortex, des GPU sont disponibles sous licence pour les constructeurs de SoC comme les Mali d'ARM, ou les PowerVR d'Imagination Technologies), alors qu'il s'agissait plus simplement d'un accord de licence. Cette stratégie infructueuse - aucun accord n'aurait été signé - faisait suite à l'échec des dernières générations de SoC Tegra sur le marché excessivement compétitif des SoC smartphone et tablettes (qui avait déjà fait d'autres victimes comme Texas Instruments), Nvidia s'étant recentré plus récemment sur ses propres produits et le marché automobile.
En septembre 2014, Nvidia avait décidé de déposer plainte devant l'ITC (U.S. International Trade Commission) envers Samsung et Qualcomm, demandant le retrait du marché américain de produits dont Nvidia estimait qu'ils violaient certains de ses brevets. Ce dépôt de plainte faisait suite à la « licence Kepler » que Nvidia avait tenté de négocier, laissant penser dans un premier que Nvidia proposerait ses GPU sous forme d'IP aux développeurs de SoC (de la même manière qu'ARM propose des blocs CPU tout faits sous la forme des Cortex, des GPU sont disponibles sous licence pour les constructeurs de SoC comme les Mali d'ARM, ou les PowerVR d'Imagination Technologies), alors qu'il s'agissait plus simplement d'un accord de licence. Cette stratégie infructueuse - aucun accord n'aurait été signé - faisait suite à l'échec des dernières générations de SoC Tegra sur le marché excessivement compétitif des SoC smartphone et tablettes (qui avait déjà fait d'autres victimes comme Texas Instruments), Nvidia s'étant recentré plus récemment sur ses propres produits et le marché automobile.
La plainte de Nvidia comprenait sept brevets dont certains nous semblaient à l'époque, comme celui sur le T&L, ne plus directement s'appliquer au matériel moderne (les GPU s'étant transformés au fil des années en puces plus génériques utilisant de larges blocs d'unités programmables pour exécuter les shaders, associés à des unités fixes pour gérer les textures par exemple). Au cours du mois de juin dernier , Nvidia avait retiré de lui-même quatre de ses brevets en contention (dont celui sur le T&L ) ainsi que différentes revendications de ses autres brevets. L'ITC détermine en effet pour chaque brevet si les revendications qui le compose (« claims » en anglais) sont effectivement utilisées dans les produits pour lesquels la plainte a été déposée. Lors de l'examen cependant, l'ITC peut décider d'invalider un brevet, ce qui peut être extrêmement couteux pour les entreprises (une grande partie de la valeur des brevets tient sur la présomption de leur validité), bien au-delà de la simple plainte concernée.
Il restait donc trois brevets sur lesquels l'ITC devait statuer, ce qui a été fait la semaine dernière . On notera que si Nvidia s'en est pris à Samsung et Qualcomm, c'est avant tout pour pouvoir interdire l'import des produits sur le territoire américain. En pratique, ce sont les IP des GPU qui étaient visées, Samsung ne produit pour rappel pas (encore) de GPU propre (une architecture CPU ARMv8 propre à Samsung est en développement pour 2016, et potentiellement une architecture GPU même si peu d'informations existent sur cette dernière). Trois familles de GPU étaient visées directement dans la plainte, les Mali (blocs d'IP développés par ARM), les PowerVR (blocs d'IP développés par Imagination Technologies) et les Adreno (l'architecture GPU de Qualcomm).
Le juge a déterminé que ces trois familles de GPU ne contrevenaient pas à deux des trois brevets restants (sur des techniques liées aux opérations sur les vertex , et l'autre sur une méthode de multithreading ). Pour le troisième, un brevet sur le shadow mapping , une des revendications a été considérée comme enfreinte par les GPU (claim 23), mais le juge l'a invalidée (tout comme la claim 24) considérant qu'elle n'était pas nouvelle et non évidente. D'autres revendications individuelles ont également été déclarées invalides par le jugement (ce qui n'a pas d'incidence directe, si ce n'est de faire diminuer la valeur de ces brevets pour Nvidia dans ses autres accords de licence).
Nvidia indique par un post de blog avoir demandé le réexamen de l'invalidation du brevet sur le shadow mapping, ce qui laisse une lueur d'espoir mais si le brevet est bel et bien invalidé, c'est la totalité de la plainte du constructeur qui sera rejetée définitivement par l'ITC.
Un coup dur pour Nvidia dont la stratégie offensive vis-à-vis de ces brevets semblait inhabituelle. On se souvient que Nvidia s'était battu de longues années contre Rambus - jusqu'en février 2012 - face aux brevets sur la SDRAM et la DDR. Une stratégie d'autant plus risquée que comme nous l'indiquions, les GPU modernes n'ont plus grand-chose à voir avec ceux de la fin des années 90, DirectX ayant joué son rôle d'uniformisation pour le meilleur et pour le pire. Si Nvidia a voulu communiquer sur son rôle de « précurseur » dans le domaine du GPU face au monde nouveau des smartphones, cela néglige la réalité de l'histoire. Les acteurs principaux comme Imagination Technologies ne sont pas de nouveaux entrants sur le marché, la société ayant été fondé en 1985 bien avant que Nvidia n'existe et proposait en 1996 ses premiers PowerVR, avant même les Riva, TNT et autres GeForce. On se rappellera également que les Adreno de Qualcomm étaient nés d'une division d'ATI (Imageon).
Et si l'on remonte encore plus en arrière, on pourra dire que l'industrie du GPU a été construite sur le travail préalable de Silicon Graphics, une réalité à laquelle il est difficile d'échapper encore aujourd'hui car si la société a déposé le bilan, ses brevets se retrouvent désormais dans une entité appelée « Graphics Properties » qui s'attaque elle aussi aux fabricants de smartphones (voir ici , là et là ).
ARM annonce Cortex-A72, Mali-T880 et CCI-500
La société ARM vient d'annoncer un nouveau design de processeur basé sur son architecture ARMv8-A, baptisé Cortex-A72. Pour rappel, ARM est une société qui fournit à ses clients différents types de services. ARM définit ainsi des architectures (comme le ARMv8-A qui apporte un jeu d'instruction 64 bits) et propose également ses propres designs de processeurs basé sur ses propres architectures (les gammes Cortex). Si certains de ses clients disposent d'une licence « architecture » qui leur permet de créer leurs propres implémentations de processeurs (c'est notamment le cas de Qualcomm avec ses Krait, d'Apple avec ses A7/A8 et plus récemment de Nvidia avec son annonce autour de Denver), la majorité des clients (y compris ceux qui disposent d'une licence architecture) utilise les designs de processeurs Cortex qu'il peuvent ajouter dans leurs propres SoC en les accolant à un GPU et d'autres blocs fonctionnels.



ARM avait annoncé en 2012 ses Cortex A50 destinés spécifiquement aux process 20nm et de nombreux SoC ont été annoncés autour de ces cores (y compris par AMD) même si la disponibilité de ces derniers reste limitée à quelques références aujourd'hui.
Pour le Cortex-A72, il s'agit d'un design « big » dans le langage ARM (hautes performances) qui vient faire suite au Cortex-A57 et qui a pour but de se retrouver dans les smartphones haut de gamme, tablettes et « autres périphériques mobiles à large écran ». Il est cette fois ci destiné aux process 16nm, ARM mentionnant même à plusieurs reprises le 16nm FinFet+ de TSMC. Côté détails sur l'implémentation, il faudra attendre encore : ARM n'ayant rien communiqué de précis au-delà des tailles des caches qui restent identiques à celles des Cortex-A57. Côté performances, le constructeur évoque une augmentation de 84% par rapport à l'A57 dans une enveloppe thermique équivalente ce qui laisse penser qu'il ne s'agit d'un peu plus qu'un simple die shrink de l'A57. ARM évoque des fréquences pouvant monter à 2.5 GHz dans une enveloppe thermique « mobile ».
On notera que contrairement à l'annonce des A50, ARM n'annonce pas de core basse consommation (« LITTLE », des cores utilisant une architecture in order ou les instructions sont exécutés sans réordonnancement, contrairement aux architectures out of order utilisées sur les cores « big » où sur les processeurs x86 modernes) et il faudra dans un premier temps appairer des cores Cortex-A53 pour réaliser des SoC big.LITTLE. On soulignera par contre qu'ARM annonce une nouvelle version de son interconnexion système (Cache Coherent Interconnect) qui améliore de 30% les performances mémoires et permet désormais d'interconnecter jusque quatre groupes de curs (une architecture big.LITTLE en interconnecte deux).

Une nouvelle référence de GPU baptisée Mali-T880 vient également s'ajouter à la gamme des designs proposés par ARM. A l'image du Cortex-A72 il s'agit là aussi d'un design fait pour le 16nm. On y retrouve une architecture proche voir identique à celle du Mali-T860, précédent haut de gamme, avec toujours 16 « curs » graphiques. La fréquence évolue par contre à la hausse passant de 650 à 850 MHz ce qui vaut des performances annoncées de 1700 Mtriangles/s et 13.6 Gpixels/s (contre 1300 Mtriangles/s et 10.4 Gpixels/s pour le Mali-T860).
Plusieurs partenaires comme HiSilicon, MediaTek et Rockchip ont déjà pris la licence pour ce nouveau core qui devrait débarquer en 2016 dans des implémentations SoC selon ARM.