
Coeurs virtuels et parallélisme pour SoftMachines



Nos confrères d'EETimes nous font part de « l'émergence » d'une startup. Baptisée SoftMachines, cette société a été fondée en 2008 par deux anciens employés d'Intel et propose de résoudre les problèmes de parallélismes de nos processeurs modernes. Cette startup compte aujourd'hui 250 employés et est sur le point de boucler une nouvelle levée de fond, ce qui explique en partie leur émergence. Elle compte déjà parmi ses investisseurs Samsung, GlobalFoundries et AMD.
L'idée de base proposée par SoftMachines est de maximiser l'utilisation des cores processeurs actuels en rajoutant au-dessus d'une ISA existante (ARM ou x86) une couche d'abstraction supplémentaire dont le but est d'extraire un maximum de parallélisme. La société propose de rajouter une notion de curs virtuels, indépendante des curs physiques avec pour cela l'introduction de petits threads « hardware » qui peuvent se mapper indépendamment sur les curs physiques. La méthode semble assez différente du principe de l'HyperThreading qui permet, pour rappel, à un cur processeur de disposer de deux contextes séparés en parallèle qui lui permet d'exécuter deux flux d'instructions en parallèle.
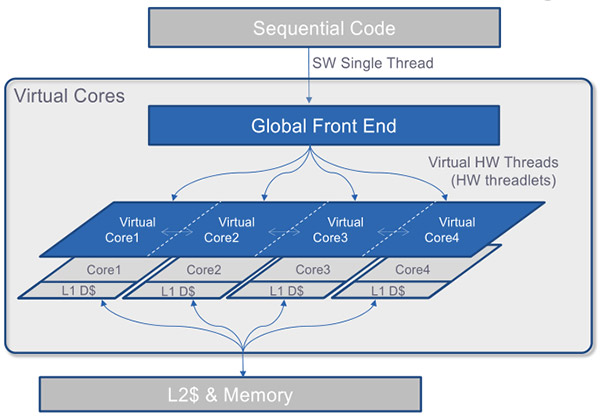
Ici, le parallélisme est extrait différemment via un front end « global » placé au-dessus des cores. C'est lui qui prendra soin de dispatcher les threads hardware qui seront exécutés par les curs traditionnels en dessous. Pour rappel, ce que l'on appelle un front end en général est la partie « en amont » de chaque cur qui s'occupe de décoder le jeu d'instruction (x86 sur nos PC) pour le traduire et le dispatcher en instructions natives. L'idée étant qu'il est ainsi possible pour ce front end magique de créer, à partir des flux d'instruction à exécuter qu'il reçoit, des threads hardware indépendants qui peuvent s'exécuter séparément sur chacun des curs.
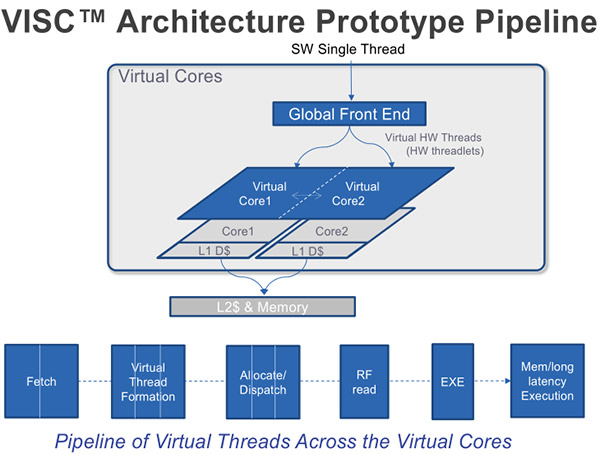
Sur le papier, le fait de rajouter un front end global par-dessus le reste permet en théorie d'utiliser les curs comme des ressources interchangeables et permet même de découper une application avec un unique thread en plusieurs mini threads qui se retrouvent dispatchés à la volée sur les curs.
En pratique, pour que la magie opère il faut que le système soit capable d'extraire du parallélisme là où il n'y en a pas. Pour cela, l'approche utilisée par SoftMachines mélange à la fois une couche logicielle et son front end global. Pour résoudre les problèmes difficiles de concurrence, la solution de SoftMachines consiste à convertir le code à exécuter dans un jeu d'instruction virtuel, celui utilisé par le front end global ci-dessus.
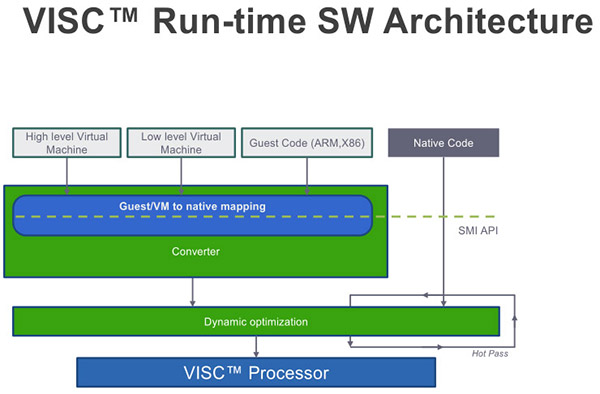
La couche logicielle et le jeu d'instruction qui ne sont pas réellement précisés permettraient ainsi de se défaire des problèmes compliqués d'extraction de parallélisme (problèmes de synchronisations, concurrence, mémoire partagée, etc...). Le manque de détails nous laisse pour l'instant circonspects sur la réalité de la solution utilisée.
Extraire du parallélisme à partir d'un thread unique est une tâche excessivement difficile qui occupe les chercheurs depuis 30 ans. La plupart des compilateurs modernes se sont lancés dans ce type d'optimisation avec des succès variables. Il s'agit en général de paralléliser les boucles en dispatchant leur exécution sur plusieurs threads avant de regrouper le tout à la fin pour obtenir le résultat attendu. Dans certains cas cela peut être particulièrement bénéfique, GCC en version 4.8 est par exemple capable d'obtenir des gains allant de 1.25x à 4.5x dans SPEC2006 sur une architecture Power8. Des gains qui sont obtenus grâce à des conditions assez spécifiques, notamment l'existence d'informations de profilage (le compilateur regarde le programme s'exécuter avant de le recompiler en utilisant les informations qu'il a glané sur le fonctionnement « réel » du programme).
Une des difficultés pour les compilateurs est que si leur connaissance du code du programme est complète, ils ne savent pas distinguer les morceaux de codes qui sont réellement importants des autres sans que l'on les aide. A l'inverse, un processeur sait exactement ce qu'il doit faire tourner, mais n'a qu'une vision très partielle (quelques instructions à l'avance) de ce qui arrive, limitant ses opportunités d'optimisation.
Si certains algorithmes, comme les benchmarks répétitifs de SPEC, se plient assez bien à l'extraction de parallélisme, ce n'est pas forcément le cas de la majorité des programmes dont l'exécution est souvent beaucoup plus aléatoire et moins faciles à profiler pour les compilateurs.
Tenter de paralléliser au niveau d'un front end en amont déplace le problème et si cela peut donner des opportunités, cela crée aussi quelques problèmes importants à gérer niveau latence par exemple, un point vite balayé auprès de nos confrères d'EETimes par la startup.
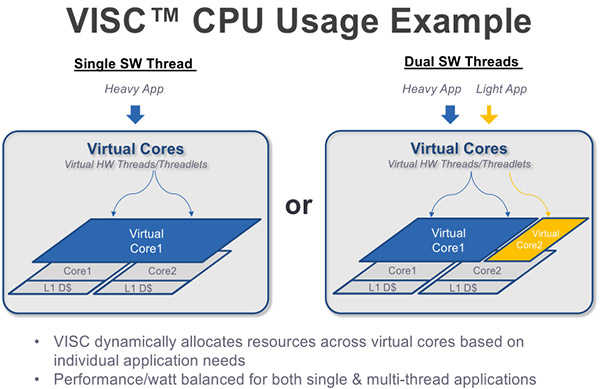
Un découpage efficace et magique, mais sans explication technique!
En soit, les gains annoncés (2x à TDP égal), sachant qu'ils ont été mesurés sous SPEC dans des conditions de compilations inconnues (on imagine sans AutoPar) ne sont pas forcément très importants d'autant que la comparaison se fait face à un ARM Cortex A15. L'overhead sur la consommation impliqué par le front end n'est pas évoqué là non plus, même s'il semble non négligeable (environ 50% par rapport à l'A15 si l'on croise les chiffres donnés).
L'idée de base de SoftMachine d'utiliser un front end global peut être intéressante mais en pratique, le peu d'information donné nous laisse penser qu'il s'agit avant tout pour la startup de faire parler d'elle avant son nouveau tour de financement. Le fait que la solution soit vendue comme un ajout aux architectures existantes, plutôt qu'une nouvelle architecture pleinement repensée pour résoudre la concurrence nous laisse également penser qu'il s'agit là aussi d'un argument plus commercial que technique. La société indique qu'elle pense pouvoir indiquer un premier partenariat dès l'année prochaine ce que nous ne manquerons pas de suivre.
Contenus relatifs
- [+] 09/05: AMD Ryzen 7 2700, Ryzen 5 2600 et I...
- [+] 04/05: Un Coffee Lake 8 coeurs en préparat...
- [+] 27/04: Le 10nm d'Intel (encore) retardé, l...
- [+] 26/04: Jim Keller rejoint... Intel !
- [+] 23/04: MAJ de notre test des Ryzen 7 2700X...
- [+] 20/04: MAJ de notre comparatif CPU géant
- [+] 19/04: AMD Ryzen 2700X et 2600X : Les même...
- [+] 19/04: 2008-2018 : tests de 62 processeurs...
- [+] 13/04: Les AMD Ryzen Pinnacle Ridge en pré...
- [+] 10/04: LGA4189 pour les Xeon Ice Lake !