| |
| |
| AMD Radeon R9 Fury X : le GPU Fiji et sa mémoire HBM en test Cartes Graphiques Publié le Jeudi 2 Juillet 2015 par Damien Triolet URL: /articles/937-1/amd-radeon-r9-fury-x-gpu-fiji-memoire-hbm-test.html Page 1 - Introduction Après avoir dévoilé progressivement les détails concernant le GPU Fiji et la Radeon R9 Fury X, AMD lance enfin sa nouvelle solution ultra haut de gamme. Au menu, une énorme puce de 8.9 milliards de transistors, de la mémoire HBM et un refroidissement à base de watercooling. De quoi inquiéter les GeForce GTX 980 Ti ?  Le 28nm et l'architecture GCN, un long parcoursIntroduite fin 2011, l'architecture GCN (Graphics Core Next) d'AMD représente une longévité inhabituelle dans le petit monde du GPU, ce qui s'explique en partie par le fait qu'elle est liée au procédé de fabrication en 28nm, qui aura été exploité pendant 5 ans. Depuis la Radeon HD 7970 de 2011, en passant par la Radeon R9 290X, AMD a progressivement fait évoluer cette architecture pour proposer plus de performances et de fonctionnalités, mais sans réellement opérer de profondes modifications. Plus d'unités de calcul et plus de watts n'est pas une solution durable. Dans le même temps, Nvidia, qui a dû faire le constat de certains mauvais choix pour son architecture Fermi, a proposé deux évolutions significatives du cur de ses GPU avec Kepler et puis Maxwell. De quoi progressivement prendre un avantage en termes de performances qui l'a autorisé à limiter agressivement températures et nuisances sonores. Sans toucher au cur de son architecture GCN, AMD tente cependant avec Fiji et la Radeon R9 Fury X de redresser quelque peu la barre grâce à l'utilisation d'un nouveau type de mémoire, la HBM, qui permet des économies énergétiques et donc de donner plus de marge pour étendre le GPU sans faire exploser le wattmètre. Est-ce suffisant ? Mise à jour du 02/07/2015 : ajout d'une page dédiée à l'overclocking du GPU Fiji. Page 2 - Fiji : GCN 1.2, HBM, 8.9 milliards de transistors Fiji : 8.9 milliards de transistorsLe GPU Fiji d'AMD est une puce énorme, conçue dans le même esprit que le GPU GM200 de Nvidia, à savoir proposer un maximum de performances dans les jeux tout en restant sur le procédé de fabrication 28nm. Fiji : 8.9 milliards de transistors pour 598 mm² Hawaii : 6.2 milliards de transistors pour 438 mm² Tonga : 5.0 milliards de transistors pour 368 mm² GM200 : 8.0 milliards de transistors pour 601 mm² GM204 : 5.2 milliards de transistors pour 398 mm² Ce n'est pas un hasard si Fiji et le GM200 sont des puces de tailles similaires, elles s'approchent en fait du maximum autorisé par la technologie actuelle. A noter que les puces d'AMD affichent une densité de transistors légèrement supérieure ce qui peut s'expliquer par l'utilisation de règles de design différentes, par une proportion plus importante de mémoire (généralement plus dense) dans les GPU GCN, ou encore par un calcul différent du nombre de transistors, puisque ce dernier est approximatif et obtenu par conversion.  Fiji mesure à peu près 23x26mm, c'est un petit peu plus que ce à quoi nous nous attendions sur base des premières illustrations d'AMD qui n'étaient pas tout à fait correctes. L'interposer, soit le morceau de silicium qui permet d'interconnecter le GPU Fiji et la mémoire HBM, mesure quant à lui à peu près 36x28mm soit 1011 mm². C'est énorme et là aussi proche des limites de ce que permettent les technologies de fabrication actuelles, selon ce que nous a indiqué AMD. C'est une des raisons pour lesquelles AMD n'a pas cherché à faire en sorte qu'il soit possible de connecter les puces HBM en 512-bit de manière à pouvoir en connecter 8 à Fiji qui aurait ainsi pu passer à 8 Go. L'espace est limité et cher sur un interposer. L'augmentation du nombre de transistors par rapport à Hawaii permet bien entendu d'intégrer le sous-système mémoire capable de piloter le bus 4096-bit lié à la mémoire HBM. Rappelons que le principe de la mémoire HBM est de réduire la fréquence du bus tout en augmentant fortement sa largeur, ce qui permet d'améliorer l'efficacité énergétique mais exige l'utilisation d'un interposer puisqu'il n'est pas possible de tracer un tel bus directement sur un PCB. Vous pourrez retrouver plus d'informations à ce sujet dans notre focus consacré à la mémoire HBM. Voici un résumé des caractéristiques de tous les GPU de la famille GCN : Oland : GCN 1.0, 6 CU, 1 triangle par cycle, 8 ROP, L2 256 Ko, 128 bits Cape Verde : GCN 1.0, 10 CU, 1 triangle par cycle, 16 ROP, L2 512 Ko, 128 bits Bonaire : GCN 1.1, 14 CU, 2 triangles par cycle, 16 ROP, L2 512 Ko, 128 bits Pitcairn : GCN 1.0, 20 CU, 2 triangles par cycle, 32 ROP, L2 512 Ko, 256 bits Tahiti : GCN 1.0, 32 CU, 2 triangles par cycle, 32 ROP, L2 768 Ko, 384 bits Tonga : GCN 1.2, 32 CU, 4 triangles par cycle, 32 ROP, L2 768 Ko (?), 384 bits Hawaii : GCN 1.1, 44 CU, 4 triangles par cycle, 64 ROP, L2 1024 Ko, 512 bits Fiji : GCN 1.2, 64 CU, 4 triangles par cycle, 64 ROP, L2 2048 Ko, 4096 bits HBM Voici ce que cela donne en image pour Hawaii et Fiji :  [ Fiji ] [ Hawaii ] Les transistors de plus servent principalement à faire exploser le nombre d'unités de calcul. Elles passent à 4096, à comparer aux 2048 de Tonga ou aux 2816 d'Hawaii. Ces 4096 unités sont réparties dans 64 Compute Units (CU), elles-mêmes réparties dans 4 Shader Engines. Ce nombre est similaire pour Tonga et Hawaii, ce qui signifie que les débits bruts de Fiji en termes de triangles par seconde, avec ou sans tessellation, n'augmentent pas. AMD nous a confirmé que Fiji partage à ce niveau le même design que Tonga. Le nombre de ROP reste à 64, comme pour Hawaii. Autrement dit, le débit de pixels n'augmente pas non plus. AMD nous a expliqué que ses simulations avaient montré qu'il était plus intéressant sur le plan des performances de se concentrer sur les unités de calcul, alors que pousser le nombre de ROP, ce qui signifiait probablement passer de 64 à 128, aurait eu un coût important en termes de transistors, pour un gain au final moindre. Difficile cependant de ne pas penser que cela déséquilibre Fiji et que l'architecture GCN commence à montrer ses limites en termes de possibilités d'organisation interne. Malgré cela, pour pouvoir passer à 4096 unités de calcul, AMD a dû simplifier le design des CU par rapport à Hawaii. Il s'agit en fait de CU identiques à ceux de Tonga, soit en GCN "1.2", et qui ne supportent donc pas le calcul rapide en double précision. Là où Hawaii peut tourner en demi-vitesse en DP, Tonga et Fiji se contentent de 1/16ème. Fiji n'est donc pas un GPU polyvalent envers le monde professionnel, même si un dérivé FirePro pour certains usages spécifiques n'est pas exclu. Le bus mémoire de 4096-bit est organisé autour de 8 contrôleurs bidirectionnels 512-bit. Chacun de ceux-ci accède à 4 des canaux 128-bit proposés par la mémoire HBM. Etant donné que ces canaux fonctionnent de manière asynchrone, ceux qui ne sont pas en train de transmettre des données sont automatiquement en standby, ce qui participe aux économies d'énergie. Nous ne savons pas par contre si en mode 2D AMD fait en sorte de n'utiliser qu'un nombre réduit de ces canaux. AMD indique que les 8 contrôleurs 512-bit HBM de Fiji occupent moins de place sur la puce que les 8 contrôleurs 64-bit GDDR5 de Hawaii, la fréquence plus faible et la proximité des puces HBM permettent de simplifier le design. Pour accompagner le bus 4096-bit, AMD a intégré 2 Mo de cache L2, contre 1 Mo sur Hawaii. La bande passante de ce cache L2 n'évolue cependant pas, et reste à un peu plus de 1 To/s. A noter que de son côté, Nvidia a opté pour 3 Mo sur le GM200. Une tendance générale à la hausse qui est peut-être liée à l'utilisation de techniques de compression toujours plus avancées, qui demandent probablement de conserver localement un maximum de données décompressées. GCN 1.2Officiellement, AMD ne différencie pas les différentes itérations de son architecture GCN. Il y a du GCN, du GCN un peu vieux et du GCN un peu nouveau. Pas très pratique pour s'y retrouver Même s'il ne s'agit pas d'une forme sous laquelle communique AMD, nous préférons de notre côté parler de GCN 1.0 pour les premiers GPU de la famille, de GCN 1.1 pour Hawaii et Bonaire et de GCN 1.2 pour Tonga.  AMD donne très peu de détails sur les nouveautés liées à GCN 1.2. Il est tout d'abord question d'une amélioration des performances en tessellation, un argument qui semble devenu obligatoire dans toutes les présentations de GPU. De notre côté nous n'avons pas remarqué d'évolution marquante. Ces optimisations ont probablement été mises en place pour limiter l'engorgement du GPU dans des cas spécifiques. Ensuite, pour faire face à la réduction de la bande passante mémoire, AMD a mis en place de nouveaux algorithmes de compression sans perte du framebuffer. Plus spécifiquement, il s'agit de codage différentiel pour les couleurs, également appelé compression delta. Nvidia exploite également cette technique sur ses GPU Maxwell 2. Le principe de base consiste à ne pas enregistrer directement la couleur mais sa différence par rapport à une autre. Ce n'est bien entendu utile que quand l'écart entre deux couleurs est suffisamment faible, de manière à ce que cette information représente moins de bits que la couleur en elle-même. Ce support a dû être intégré au niveau des ROP et peut-être au niveau des unités de texturing, de manière à ce qu'elles soient capables de lires ces nouveaux formats de données. En associant cette compression plus efficace du framebuffer à la mémoire HBM, Fiji profite d'une bande passante mémoire effective très élevée. De quoi accentuer notre interrogation quant à son nombre de ROP limité. Dans cette configuration, Fiji peut-il réellement tirer pleinement partie de la bande passante à sa disposition ? A noter que comme Nvidia avec les GPU Maxwell, AMD a fait l'impasse sur la compression des textures ASTC pour ses GPU GCN 1.2. Nvidia nous avait expliqué que le coût de cette technologie était encore trop élevé au niveau des unités de texturing et n'avait pas de sens dans le cadre de gros GPU. Avec GCN 1.2, AMD a mis à jour le jeu d'instruction du GPU. Il est question de nouvelles instructions 16-bit, autant en entier qu'en flottants. Une précision moindre qui permet potentiellement des gains d'énergie, suivant son implémentation. La précision 16-bit est avant tout exploitée dans le monde mobile mais elle pourrait également permettre de rendre plus efficaces certains algorithmes de traitement vidéo. D'autres instructions ont été ajoutées, dédiées aux échanges de données entre threads, pour réduire les accès à la mémoire partagée, ce que Nvidia fait également sur ses derniers GPU. De notre côté, en observant le code compilé, nous avons pu remarquer que le support de quelques instructions semble avoir été supprimé (les fmac sont par exemple remplacés par des fmad), probablement parce qu'elles ne sont plus très utiles. Le code compilé est dans bien des cas constitué de légèrement moins d'instructions, ce qui peut potentiellement le rendre plus performant sur Tonga. Comme toutes les puces GCN "1.1 et 1.2", Fiji support le niveau de fonctionnalité matérielle 12_0 de Direct3D, mais fait l'impasse sur le niveau 12_1 supporté par les GPU Nvidia Maxwell de seconde génération. Par contre, au niveau de l'autre niveau de spécification important de Direct3D12, les "Binding Resources" (le nombre de ressources à dispositions des développeurs), Fiji est au niveau maximum, Tier 3, là où les GPU Nvidia sont limités au niveau Tier 2. Autant AMD que Nvidia ont ainsi l'opportunité de proposer aux développeurs des effets graphiques qui seraient incompatibles avec le matériel de l'autre. Pas de HDMI 2.0Petite nouveauté sur le plan de l'architecture par rapport à Tonga, le moteur vidéo UVD évolue et supporte le décodage matériel du H.265 (HEVC), comme sur l'APU Carrizo. Par contre AMD n'a pas mis à jour son moteur de gestion des sorties vidéo et Fiji ne supporte pas le HDMI 2.0. Une connectique pourtant généralement nécessaire pour jouer sur une TV 4K en 60 Hz, peu de modèles intégrant une entrée DisplayPort. Plus qu'incohérent sur ce point, AMD met en avant l'intégration de Fiji dans des mini-PC mais explique qu'en fait un GPU haut de gamme n'est pas réellement adapté au salon Face à la concurrence dont les derniers produits supportent tous cette connectique, il ne s'agit malheureusement pas d'une absence anecdotique. Des adaptateurs DisplayPort vers HDMI 2.0 seront proposés sous peu, mais ils ne permettront probablement pas de support le DRM HDCP 2.2, voué à se généraliser pour le contenu 4K, qu'il s'agisse de Blu-Ray UHD ou de streaming. Page 3 - Spécifications, 4 Go de HBM Spécifications 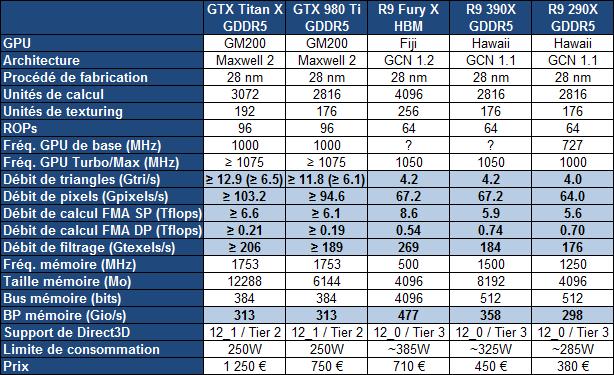 La Radeon R9 Fury X embarque un GPU Fiji complet, qualifié de « XT » par AMD, ce qui indique que la totalité de ses 4096 unités de calcul sont actives. Comme vous pouvez le constater, les débits bruts en termes de triangles et de pixels par seconde ne progressent pas et les dérivés Nvidia à base de GM200 profitent d'une large avance à ce niveau. La puissance de calcul et de texturing progresse par contre nettement sur Fiji qui affiche sur ces points une avance de 30% sur les GTX Titan X et 980 Ti. A noter cependant que les débits bruts au niveau de la puissance de calcul ne peuvent pas réellement être comparés entre architecture. Les GeForce dispose par exemple d'unités supplémentaires pour traiter les opérations complexes et ainsi décharger ces unités principales, ce qui ne se retrouve pas dans ces chiffres. Au niveau de la bande passante mémoire, l'avantage de la R9 Fury X est de 50% sur les solutions concurrentes, de 60% sur la R9 290X et de 33% sur la R9 390X. Ce à quoi il faut ajouter les gains liés à la compression sans perte du framebuffer dans le cas de ces deux dernières. AMD ne communique ni TDP, ni limite de consommation PowerTune et se contente d'un chiffre magique appelé "Typical Board Power", qui permet de brouiller les pistes sur le niveau de consommation de la Radeon R9 Fury X. A côté de ce TBP de 275W, nous avons une limite de consommation globale de la carte qui se situe à +/- 385W, un chiffre comparable au TDP de 250W communiqué par Nvidia pour les GTX 980 Ti et Titan X. AMD a légèrement revu le fonctionnement de PowerTune par rapport à Hawaii, de manière à l'adapter au nouveau format de Fiji qui intègre la mémoire dans le packaging. Pour rappel, sur Hawaii, le contrôle de PowerTune se fait directement au niveau de la consommation directe de la puce (ASIC). Celle-ci est obtenue pour un mélange de mesures (puissance VDDC) et d'estimations (consommation liée à la mémoire, au bus, etc). Pour les spécifications de référence de la R9 290X, la limite de consommation de la puce est fixée à 208, ce qui correspond à une consommation totale de la carte de +/- 285W. C'est très différent de ce que fait Nvidia avec GPU Boost qui contrôle la consommation 12V totale de la carte graphique et non du GPU. Pour Fiji, le principe reste similaire à Hawaii, si ce n'est que PowerTune contrôle dorénavant l'ensemble GPU + HBM. Ainsi, AMD nous a indiqué que la limite de consommation au niveau du packaging a été fixée à 300W pour la R9 Fury X, ce qui correspond à une limite totale de la carte d'environ 385W. PowerTune mesure toujours le canal VDDC, nous ne savons pas si le reste, y compris tout ce qui concerne la mémoire HBM, est mesuré également ou s'il s'agit d'un paramètre estimé qui s'intègre dans l'algorithme global. Réticent de prime abord à communiquer cette valeur de 300W, AMD tient à insister sur le fait qu'elle a été placée assez de manière à s'assurer que la R9 Fury X soit capable de maintenir une fréquence très élevée même dans les outils tels que Furmark. 4 Go de HBM, mais pas plusComme nous en avons déjà parlé, Fiji est actuellement limité à 4 Go de mémoire HBM. Un point délicat en 2015 autant commercialement que pour convaincre de la pérennité d'une carte graphique ultra haut de gamme. D'autant plus qu'à côté de cela, les Radeon R9 390X et 390 ne sont proposées qu'en version 8 Go, ce qui sème la confusion sur la nécessité d'aller ou pas au-delà de 4 Go. AMD explique que 4 Go est une quantité de mémoire largement suffisante pour la majorité des jeux, ce qui est vrai, et que des optimisations pourront être mises en place au niveau des pilotes pour réduire la quantité de mémoire utilisée de manière à ne pas pénaliser les performances avec les jeux plus gourmands à ce niveau. Interrogé à plusieurs reprises, AMD n'a par contre pas pu nous donner de réponse plus spécifique à ce niveau, ni nous donner le moindre exemple concret de ce qui a été optimisé ou de ce qui est envisagé pour l'avenir. AMD nous a finalement précisé que sa méthode de prédilection est de travailler directement avec les développeurs de jeux vidéo pour s'assurer qu'ils exploitent correctement les ressources à leur disposition. De notre côté, sur le peu de temps que nous avons pu passer à essayer de mettre en difficulté la R9 Fury X, nous n'avons pas constaté de problème lié à un manque de mémoire. Nous avons pu observer que le pilote se comportait différemment avec une R9 Fury X 4 Go qu'avec une R9 290X 4 Go. Dans certains jeux, la R9 Fury X consomme plus de mémoire, dans d'autre un peu moins. Et en observant la quantité de mémoire reportée par RivaTuner, nous avons l'impression que le pilote est plus agressif pour libérer de l'espace lorsqu'il estime que des données sont devenues inutiles. Bien entendu, il n'est pas impossible de placer la R9 Fury X dans une situation où sa mémoire est clairement insuffisante. Mais dans ces cas le niveau de performance n'est alors plus du tout réaliste, en mono GPU tout du moins. Nous tâcherons de passer un peu plus de temps à observer le comportement de la R9 Fury X, notamment en CrossFire, mais jusqu'ici les 4 Go ne semblent pas être un mauvais compromis avec une seule carte et un GPU offrant un tel niveau de performance. Page 4 - Performances théoriques : pixels Performances texturingNous avons mesuré les performances lors de l'accès aux textures avec filtrage bilinéaire activé et ce, pour différents formats : en 32 bits classique (4x INT8), en 64 bits "HDR" (4x FP16), en 128 bits (4x FP32), en profondeur de 32 bits (D32F) et en FP10, un format HDR introduit par DirectX 10 qui permet de stocker des textures HDR en 32 bits avec quelques compromis. Les GeForce GTX sont capables de filtrer les textures FP16 à pleine vitesse contrairement aux Radeon, ce qui leur donne un avantage considérable sur ce point. Notez que dans ce test, les GeForce à base de GK104/106/107 ont du mal à atteindre leur débit maximal alors que le GM107/200/204/206 en sont plus proches, une efficacité en hausse des unités de texturing qui est probablement liée au fait que leur proportion réduite permet de plus facilement les saturer. Les GM200, GM204 et GM206 sont capables d'accéder aux surfaces de type D32F aussi efficacement que les autres formats, comme les GPU Radeon, mais contrairement aux GPU GeForce précédents. En dehors du HDR 64-bit, le GPU Fiji dispose d'un net avantage en terme de capacités brutes de texturing. FillrateNous avons mesuré le fillrate sans et puis avec blending, et ce avec différents formats de données : [ Standard ] [ Avec Blending ] Le fillrate était l'un des points forts du GPU Hawaii qui intègre pas moins de 64 ROP chargés d'écrire les pixels en mémoire, qui plus est d'une efficacité élevée avec blending. Mais avec le GM204, Nvidia est revenu et le GM200 enfonce le clou en prenant une avance considérable. A l'inverse, Fiji n'améliore pas les débits à ce niveau. Il profite par contre de sa bande passante importante pour conserver un débit très élevé en HDR 64-bit avec blending. A noter que les GeForce depuis Kepler sont capables de transférer les formats FP10/11 et RGB9E5 à pleine vitesse vers les ROP, comme les Radeon, mais le blending de ces formats se fait toujours à demi vitesse. Par ailleurs, si tous les GPU sont capables de traiter le FP32 simple canal à pleine vitesse sans blending, seules les Radeon conservent ce débit avec blending. Page 5 - Performances théoriques : géométrie Débit de trianglesÉtant donné les différences architecturales des GPU récents au niveau du traitement de la géométrie, nous nous sommes évidemment penchés de plus près sur le sujet. Tout d'abord nous avons observé les débits de triangles dans deux cas de figure : quand tous les triangles sont affichés et quand ils sont tous rejetés (parce qu'ils tournent le dos à la caméra) : Quand les triangles peuvent être éjectés du rendu, ce qui en concerne en pratique toujours une part conséquente, la plupart des GeForce GTX peuvent profiter d'un débit supérieur pour se démarquer des Radeon. A noter cependant que notre test n'est plus adapté pour le niveau de performances énorme du GM200 et bride les résultats à un peu plus de 8 milliards de triangles par seconde. Une fois que les triangles doivent être rendus, le débit maximal théorique des GeForce Kepler chute sur certains modèles alors que leur efficacité est plus généralement en baisse, peut-être parce que ces GPU sont engorgés à un endroit ou à un autre, ou encore parce que leurs performances ont été réduites artificiellement pour différencier les Quadro des GeForce. Quoi qu'il en soit, cela ne semble plus être un problème sur Maxwell de seconde génération. Le GM206 en profite pour devancer le GK110 sur ce point et le GM200 affiche un nouveau record. Ensuite nous avons effectué un test similaire mais en utilisant la tessellation : Avec les GeForce GTX Kepler, Nvidia réaffirmait sa supériorité lorsqu'il s'agit de traiter un nombre important de petits triangles générés par un niveau de tessellation élevé. Le GM204 Maxwell de seconde génération a renforcé cet avantage lorsque les triangles ne sont pas affichés mais peinait à se démarquer du GK110 quand ils doivent être affichés. Le GM200 se détache cette fois à tous les niveaux, même si ici aussi nous suspectons notre test de la limiter quelque peu lorsque les triangles sont éjectés du rendu. Pour rappel, l'architecture des Radeon fait qu'elles peuvent être engorgées plus facilement par la quantité de données générées, ce qui réduit drastiquement leur débit dans ce cas. AMD a fait évoluer progressivement les différents buffers liés à la tessellation, et la manière de les utiliser, pour éviter autant que possible de se trouver dans ce cas. Hawaii, Tonga et Fiji profitent de leurs 4 unités de traitement de la géométrie pour afficher un gain important au niveau du débit brut, soit lorsque les triangles générés ne doivent pas être rendus. Lorsque c'est le cas, ils se contentent par contre dans notre test d'une progression très légère. Notre test étant relativement lourd en termes de données générées par triangles, nous supposons que ces GPU souffrent d'un embouteillage à un endroit ou à un autre, peut-être au niveau du canal de transfert de ces données vers les contrôleurs mémoire (mais pas directement au niveau de la bande passante globale qui est loin d'être saturée). Page 6 - La Radeon R9 Fury X, overclocking La Radeon R9 Fury XVous ne l'ignorez probablement pas, la carte de référence fait appel à un système de watercooling AIO pour son refroidissement. Un passage jugé nécessaire par AMD compte tenu du niveau de consommation potentiellement élevé de Fiji XT. Sans cela températures et nuisances sonores auraient peut-être été problématiques, comme pour les Radeon R9 290X et 290 de référence. Une situation qu'AMD a de toute évidence voulu éviter. AMD nous a fourni un échantillon de la carte de référence :  Contrairement à la R9 295 X2, AMD n'a pas simplement apposé un kit AIO à peu près standard sur le GPU Fiji. AMD a cette fois pris le temps de développer une solution spécifique, en partenariat avec Cooler Master, plus efficace et qui permet de refroidir également l'étage d'alimentation. Plus aucun ventilateur n'est donc nécessaire sur la carte. AMD parle d'une température GPU qui resterait autour de 50 °C et de nuisances sonores réduites. Comme nous allons le voir, la pression sonore reste effectivement très faible en charge, mais de petits bruits aigus liés à la pompe se font entendre, comme c'est en général le cas avec ce type de designs. L'avantage de cette solution est d'autoriser un design compact pour la carte graphique (un peu moins de 20cm) et de profiter donc pleinement du gain lié à la HBM de ce côté. Ce à quoi il faut bien entendu ajouter l'espace occupé par le radiateur et son ventilateur (155x120x65mm), les tuyaux ayant une longueur de 40cm. AMD a cherché à travailler l'esthétique de la carte en travaillant notamment l'aluminium avec différentes finitions de qualité dont une texture "soft-touch" pour les panneaux avant et arrière. AMD proposera d'ailleurs sous peu un modèle 3D de la face avant de manière à ce qu'il soit possible de la personnaliser par exemple avant une imprimante 3D.  Outre le logo Radeon illuminé, un système de LED dénommé GPU Tach permet de visualiser le niveau de charge du GPU. Une LED verte indique quand le GPU est un mode ZeroCore Power, et 8 autres qui peuvent être configurées en rouge ou en bleu, représentent l'intensité de la charge GPU, sans que nous ne sachions à quoi cela correspond exactement. AMD a conservé la fonction de double bios, mais il ne s'agit ici que d'un backup. D'origine, les deux bios seront identiques. Au niveau de la connectique, nous retrouvons 3 DisplayPort et un HDMI. De toute évidence un adaptateur DP vers DVI ou HDMI vers DVI sera fourni avec ces cartes. A noter que nous ne sommes pas parvenus à connecteur un écran 30" en DVI Dual Link avec les adaptateurs que nous avions à notre disposition (y compris DP vers Dual Link actif alimenté). Au niveau de l'alimentation, 2 connecteurs 8 broches sont nécessaires. La carte peut donc consommer jusqu'à 375W en restant dans les normes PCI Express. Pour alimenter le GPU, AMD a opté pour un étage d'alimentation à 6 phases capable de délivrer jusqu'à 400A, de quoi laisser suffisamment de marge pour l'overclocking, tout du moins si son refroidissement est suffisant.  AMD nous a conseillé d'éviter de démonter la carte pour ne pas prendre le risque d'endommager le module GPU + HBM, probablement plus fragile qu'un GPU classique, ainsi que pour conserver l'interface thermique d'origine intacte. La plaque arrière peut cependant se retirer sans problème, tout comme la face avant.  Sous le capot, nous pouvons observer le bloc de refroidissement signé Cooler Master. Entre la pompe et l'un des tuyaux du circuit de watercooling, un conduit en cuivre est collé contre la structure du système de refroidissement de manière à s'occuper du dégagement calorifique de l'étage d'alimentation. A l'arrière, nous pouvons observer quelques composants du PCB liés à l'étage d'alimentation du GPU, de quoi nous permettre, d'ailleurs, de prendre un cliché thermique de celui-ci. A noter que cette plaque arrière peut poser problème sur certaines cartes-mères dont les DIMM sont proches du premier slot PCIE. C'est le cas sur notre système de test. AMD nous a finalement fait parvenir ses propres clichés du PCB et du ventirad démonté :  OverclockingL'overclocking de la Radeon R9 Fury X est à la base pour le moins limité. La seule possibilité offerte officiellement pour le moment est d'augmenter la fréquence GPU ou la limite de consommation PowerTune. Cette dernière est cependant placée par défaut à un niveau déjà très élevé. La relever, jusqu'à 50% de plus, n'aurait aucun intérêt. Reste à pousser le GPU. Cadencé à 1050 MHz d'origine, nous avons pu monter jusqu'à 1125 MHz. A 1150 MHz, artéfacts et plantages apparaissent rapidement. Un gain de 7% relativement modeste au vu de ce dont sont capables les GeForce concurrentes. Il n'est pas possible de modifier la tension GPU mais au vu des températures VRM qui vont suivre, ce dernier point n'est par contre pas plus mal. Dans le cas de la mémoire HBM, des outils tels qu'Afterburner permettent de débloquer la situation. La mémoire HBM a ainsi pu être poussée de 500 à 550 MHz. Page 7 - Consommation et efficacité énergétique ConsommationNous avons utilisé le protocole de test qui nous permet de mesurer la consommation de la carte graphique seule. Nous avons effectué ces mesures au repos sur le bureau Windows 7 et en veille écran. Compte tenu du très large écart entre la consommation affichée dans les jeux les plus gourmands par la Radeon R9 Fury X fournie par AMD et sa la limite de consommation de 385W, nous avons fait en sorte de mettre la main sur un second échantillon de manière à observer s'il n'y aurait pas une trop grosse variabilité à ce niveau. AMD spécifiant pour le GPU Fiji une fréquence maximale alors que la tension est variable, le niveau de consommation peut varier plus que sur les GeForce pour lesquelles Nvidia fait l'inverse et spécifie une tension maximale alors que la fréquence est variable, ce qui fait alors varier le niveau de performances. Pour la charge, nous testons d'une part Anno 2070 en mode de qualité maximale qui représente un jeu très lourd et d'autre part Battlefield 4 en mode Ultra qui représente un jeu moins lourd. A noter que nous avons refait toutes nos mesures de consommation en 1440p. Elles étaient auparavant effectuées en 1080p, résolution qui pouvait pousser les solutions les plus performants dans la limite CPU. La Radeon R9 Fury X affiche un niveau de consommation élevé, mais qui reste inférieur à ce que nous aurions pu penser. Le TBP de 275W mis en avant par AMD n'est pas totalement délirant au vu de nos résultats. Le second échantillon sur lequel nous avons pu mesurer la consommation est quelque peu plus gourmand, mais cet écart n'est pas plus important que ce que nous avons pu observer sur de nombreuses cartes graphiques (dans un sens comme dans l'autre) et ne permet pas de conclure qu'AMD aurait par exemple trié les échantillons presse au niveau de leur consommation. Bien que ces données soient approximatives, compte tenu de la variation entre échantillons d'un même modèle, nous avons mis en relation ces mesures de consommation avec les performances, en retenant des fps par 100W pour que les données soient plus lisibles, de quoi donner une idée globale sur le rendement énergétique de toutes ces cartes : [ Battlefield 4 ] [ Anno 2070 ] Enfin, le rendement énergétique des Radeon repart à la hausse ! Ce n'est pas encore suffisant pour égaler les GeForce GTX 900, mais ces résultats sont encourageants. Page 8 - Températures et nuisances sonores Nuisances sonoresNous plaçons les cartes dans un boîtier Cooler Master RC-690 II Advanced et mesurons le bruit d'une part au repos et d'autre part en charge sous le test1 de 3DMark11. Un SSD est utilisé et tous les ventilateurs du boîtier ainsi que celui du CPU sont coupés pour la mesure. Le sonomètre est placé à 60cm du boîtier fermé et le niveau de bruit ambiant se situe à moins de 20 dBA, ce qui est la limite de sensibilité pour laquelle il est certifié et calibré. Au repos, le R9 Fury X n'est pas la plus discrète. Sa pompe semble fonctionner tout le temps à plein régime et se fait clairement entendre et produit un bruit strident très agaçant (type acouphène), en tout cas en ce qui nous concerne, la sensibilité de chacun étant différente sur ce point. En charge, la pression sonore reste faible pour la R9 Fury X, son système de refroidissement faisant un bon boulot. Le bruit de la pompe reste cependant gênant, même si cela ne se traduit pas dans ces chiffres, et nous avons tendance à préférer le soufflement sourd de ventilateurs axiaux de cartes customs ou de blower de bonne qualité (comme c'est le cas des GTX 900 de référence) même si les dBA sont autrement plus élevés. Il faut cependant noter que AMD nous a indiqué ce matin même avoir travaillé avec Cooler Master afin d'améliorer le profil acoustique de la pompe sur les productions les plus récentes... à voir, ou plutôt, à écouter ! TempératuresToujours dans le même boîtier, nous avons relevé la température du GPU rapportée par la sonde interne : La R9 Fury X profite du watercooling pour afficher une température raisonnable au vu de sa consommation. Nous sommes par contre loin des 50 °C avancés par AMD une fois que la carte fait tourner un jeu lourd (3DMark tel qu'utilisé ici représente une charge similaire à celle d'Anno 2070) et prend place dans un boîtier fermé. Thermographie infrarougeVoici les photos thermiques obtenues pour la Fury X avec à chaque fois 45 minutes de mise en situation :  [ Repos ] [ Charge ] [ Charge sans plaque arrière ] Une fois la plaque arrière retirée, nous pouvons observer que les VRM atteignent un peu plus de 100 °C. Cette plaque ne participant pas au refroidissement, leur température est probablement un petit peu plus élevée quand elle est en place. Même si ces composants sont prévus pour de telles températures, le système de refroidissement de la R9 Fury X montre à ce niveau ses limites et nous ne vous conseillons pas d'éventuels gros overclockings avec vmod. Page 9 - Protocole de test Protocole de testPour ce test, comme pour la GTX 980 Ti, nous avons laissé Metro Last Light de côté mais intégré Project Cars et The Witcher 3. Nous avons bien entendu conservé Dying Light et Evolve qui ont été intégrés récemment. Tous les derniers patchs au 19/06/2015 ont été installés, la plupart des jeux étant maintenus à jour via Steam/Origin/Uplay. Nous avons opté d'une part pour la résolution de 1440p avec un niveau de détail très élevé, de manière à obtenir à peu près 60 fps sur les solutions haut de gamme, ou plus si le jeu ne permet pas un niveau de détail plus élevé autre que du SSAA. Nous avons évité d'activer ce type d'antialiasing, que nous jugeons beaucoup trop gourmand par rapport à ce qu'il apporte. D'autre part, nous avons mesuré les performances en 4K en faisant en sorte de sélectionner un niveau de qualité jouable sur les solutions ciblées par ce test. Nous avons intégré une Radeon HD 7970 pour contextualiser quelque peu l'évolution des performances ainsi qu'une GeForce GTX 980 Ti personnalisée, le modèle SC+ d'EVGA, de manière à illustrer ce dont est capable le GM200 quand il sort des limites du ventirad de référence. Pour rappel, nous n'affichons plus les décimales dans les résultats de performances dans les jeux pour rendre les graphiques plus lisibles. Ces décimales sont néanmoins bien notées et prises en compte pour le calcul de l'indice. Toutes les cartes ont été testées avec les pilotes Catalyst 15.15 beta et GeForce 353.30 WHQL. Nous avons forcé l'activation du PCI Express 3.0 sur la plateforme X79 pour les GeForce. Toutes les cartes ont été testées telles quelles avec une température ambiante contrôlée à 26 °C et, pour chaque jeux, nous avons pris le temps nécessaire pour que la fréquence GPU se stabilise. Les performances des GeForce peuvent potentiellement être surévaluées du fait de leur fréquence turbo variable. Mais nous ne cherchons plus à la limiter aux spécifications officielles depuis la génération GTX 700 avec laquelle a été introduite un contrôle de la température qui est devenu de fait l'élément de limitation principal pour les GeForce de référence. Nous somme cependant en train de reconsidérer cette approche étant donné que nous pouvons observer, avec les GTX Titan X et GTX 980 Ti, que nos échantillons de test reprennent un avantage parfois significatif par rapport aux fréquences officielles. Il n'est donc pas impossible qu'à l'avenir nous revenions à imposer à la carte de respecter la fréquence turbo officiellement garantie. Voici les fréquences moyennes approximatives que nous avons pu observer durant nos mesures de performances :  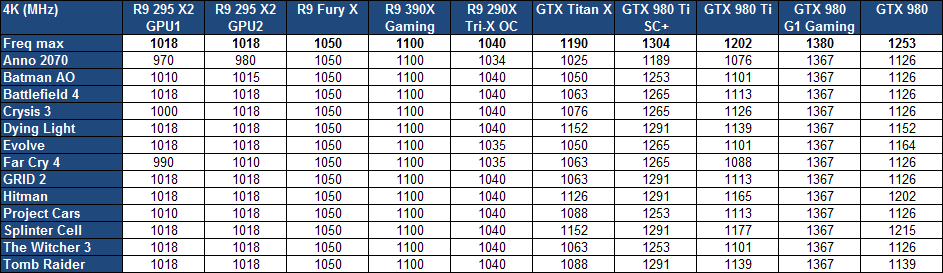 Nous pouvons y observer que la Radeon R9 Fury X est capable de maintenir sa fréquence maximale en permanence, tout comme le fait la R9 390X Gaming de MSI.  Configuration de testIntel Core i7 3960X (HT off, Turbo 1/2/3/4/6 cores: 4 GHz) Asus P9X79 WS 8 Go DDR3 2133 Corsair Windows 7 64 bits Pilotes GeForce 353.30 WHQL Catalyst 15.15 beta Page 10 - Benchmark : 3DMark et Unigine 3DMark Fire Strike  Nous lançons le test Fire Strike avec les 3 presets proposés par Futuremark : [ Fire Strike ] [ Fire Strike Extreme ] [ Fire Strike Ultra ] La Radeon R9 Fury X se positionne ici derrière la GeForce GTX 980 Ti. Unigine Valley 1.0 & Heaven 4.0Les tests sont effectués avec tous les paramètres au maximum en 1920*1080 et MSAA 8x. [ Valley ] [ Heaven ] Décidemment, la R9 Fury X n'apprécie pas trop ces premiers benchmarks. Page 11 - Benchmark : Anno 2070 Anno 2070  Anno 2070 reprend une évolution du moteur d'Anno 1404 qui intègre un support de DirectX 11. Nous utilisons le mode de qualité maximale ou très élevée du jeu et effectuons un déplacement sur une carte en mesurant les performances avec Fraps. En général, dans Anno 2070, c'est avant tout la puissance de calcul qui compte et les GPU sont mis à rude épreuve par rapport à leurs limites de consommation ou de température. Nous nous attendions du coup à ce que la Radeon R9 Fury X se démarque dans ce jeu mais le gain est limité par rapport à la Radeon R9 290X. C'est encore un petit peu moins bien en 4K, ce qui nous laisse penser que le GPU Fiji souffre d'une limitation interne. Page 12 - Benchmark : Batman Arkham Origins Batman Arkham Origins  Avant-dernier opus de la série, son successeur venant tout juste de sortir, Batman Arkham Origins est toujours basé sur l'Unreal Engine 3 mais pousse un petit peu plus loin les effets graphiques dont certains ont été implémentés sur PC en collaboration avec Nvidia. C'est le cas du TXAA et d'effets GPU PhysX réservés aux GeForce (il n'est plus possible d'activer une version CPU de tous ces effets), mais également de l'occlusion ambiante de type HBAO+, d'un effet de Depth of Field plus évolué (NVDOF), d'ombres adoucies (PCSS) et de la tessellation (pour la cape et la neige) qui sont utilisables sur tous les GPU DirectX 11. Nous utilisons le mode de qualité maximale du jeu, avec du MSAA 8x ou du FXAA High. Nous relevons les performances avec Fraps, sur un parcours bien défini. Le jeu est maintenu à jour via Steam. La R9 Fury X se rapproche ici quelque peu de la GTX 980 Ti, mais ne parvient pas à l'égaler. En 4K avec FXAA, les résultats de la nouvelle Radeon reculent quelque peu. Page 13 - Benchmark : Battlefield 4 Battlefield 4  Battlefield 4 repose sur le moteur Frostbite 3, une évolution de la version 2 présente dans Battlefield 3. La base du rendu reste très proche (rendu différé, calcul de l'éclairage via compute shaders) et les évolutions visibles sont mineures, DICE ayant principalement optimisé son moteur pour les consoles de nouvelle génération. Parmi les petites nouveautés, citons un support plus avancé de la tessellation et une amélioration du module "destruction" du moteur. Sur PC, un mode Mantle spécifique aux Radeon et qui permet de réduire le coût CPU du rendu est proposé mais nous ne l'avons pas utilisé pour ce test. Pour rappel, il s'agit d'une API propriétaire de plus bas niveau dédiée aux Radeon HD 7000 et supérieures, qui a été développée par AMD et DICE. Nous testons le mode Ultra avec ou sans MSAA 4x et nous relevons les performances avec Fraps, sur un parcours bien défini. Le jeu est maintenu à jour via Origin. Les GeForce Maxwell apprécient particulièrement ce jeu, d'autant plus qu'il ne les pousse pas dans leurs limites de consommation et permet à leurs GPU de tourner à des fréquences élevées. Une nouvelle fois, la R9 Fury X souffre un peu plus en 4K que les GeForce, qui apprécient probablement plus que les Radeon de ne plus devoir appliquer le MSAA. Page 14 - Benchmark : Crysis 3 Crysis 3  Crysis 3 reprend le même moteur que Crysis 2 : le CryEngine 3. Ce dernier profite cependant de quelques petites évolutions telles qu'un support plus avancé de l'antialiasing : FXAA, MSAA et TXAA sont au programme, tout comme un nouveau mode appelé SMAA. Ce dernier est une évolution du MLAA qui permet, optionnellement, de prendre en compte des données de type sous-pixels soit à travers la combinaison avec du MSAA 2x, soit avec une composante temporelle calculée à partir de l'image précédente. Le SMAA 1x est la simple évolution du MLAA, le SMAA 2tx utilise une composante temporelle relativement complexe et le SMAA 4x y ajoute le MSAA 2x. Notez qu'il ne faut pas confondre le SMAA 2tx proposé en mono-GPU avec le SMAA 2x proposé en multi-GPU, ce dernier utilisant du MSAA 2x sans composante temporelle. Nous mesurons les performances avec Fraps et le jeu est maintenu à jour via Origin. Crysis 3 est un jeu très gourmand au niveau de la puissance de calcul et les Radeon R9 Fury X talonne les GTX 980 Ti et Titan X. La R9 Fury X se comporte également assez bien en 4K mais n'affiche toujours pas de victoire. Page 15 - Benchmark : Dying Light Dying Light  Dying Light est un jeu de type survival horror animé par le Chrome Engine 6 de Techland et dans lequel le monde est plutôt vaste et ouvert. Nvidia a travaillé avec Techland pour y inclure certains effets issus de ses librairies Gameworks tels que le HBAO+ et le Depth of Field. Nous avons mesuré les performances avec Fraps sur un parcours bien défini. Le jeu est maintenu à jour à travers Steam. Dying Light entraîne une charge plutôt légère sur les GPU, ce qui s'explique principalement par des micro-saccades régulières qui impactent fortement la fluidité sous Windows 7. Elles sont présentes autant avec les Radeon qu'avec les GeForce, mais uniquement en mode plein écran. Les développeurs ont visiblement bien du mal à corriger ces petits bugs La R9 Fury X ne se comporte pas très bien dans ce jeu qui affiche une consommation mémoire très élevée. Nous n'avons pas constaté de saccades et ne savons pas pourquoi ses performances sont limitées à un niveau similaire à celui de la R9 390X. Ce n'est guère mieux en 4K. Page 16 - Benchmark : Evolve Evolve  Evolve, développé par Turtle Rock Studios, est basé sur le Cry Engine 3. Contrairement à ce dernier, les modes d'antialiasing à base de MSAA, extrêmement gourmands avec ce moteur, ne sont pas proposés. Un nouveau mode de SMAA a par contre été développé par Crytek et intégré dans les branches plus récentes de son moteur : le 1tx. Il s'agit d'une version quelque peu simplifiée du SMAA 2tx, antialiasing à base de composante temporelle, qui a la particularité d'être compatible avec le multi-GPU. Nous mesurons les performances à l'aide de Fraps sur un parcours bien défini et le jeu est maintenu à jour avec Steam. Les Radeon R9 290X/390X semblent apprécier particulièrement ce titre. La R9 Fury X se positionne également plutôt bien par rapport à la concurrence, au niveau de la GTX 980 Ti de référence En 4K, c'est encore mieux pour les Radeon et la R9 Fury X égale la GTX 980 Ti SuperClocked d'EVGA. Page 17 - Benchmark : Far Cry 4 Far Cry 4  Dernier opus de la série, il est basé sur une petite évolution du Dunia Engine 2 qui avait été introduit avec Far Cry 3. Ses caractéristiques sont donc similaires et parmi les petites évolutions nous notons l'ajout par les développeurs du support de l'antialiasing SMAA 1x en plus du MSAA qui est très, voire trop, gourmand avec ce moteur. Nous activons le niveau de qualité Ultra ou Medium avec du SMAA 1x et utilisons Fraps sur un parcours bien défini. Les Radeon s'en tirent également assez bien dans ce jeu. En 4K, la R9 Fury X devance la GTX 980 Ti de référence mais se fait rattraper par la carte personnalisée par EVGA. Page 18 - Benchmark : GRID 2 GRID 2  Dernier né chez Codemaster, GRID 2 reprend une évolution légère du moteur DirectX 11 maison exploité par DiRT Showdown. Pour rappel, en partenariat avec AMD, les développeurs avaient mis en place un éclairage avancé qui prend en compte de nombreuses sources de lumières directes et indirectes ainsi qu'une approximation du rendu de type illumination globale. Ces techniques sont toujours exploitées, même si le partenaire principal de Codemaster est cette fois Intel qui a aidé à la mise en place d'optimisations spécifiques aux GPU intégrés à Haswell. Pour mesurer les performances, nous poussons toutes les options graphiques à leur maximum, y compris l'adoucissement de l'effet d'occlusion ambiante, et activons le MSAA 8x. Nous utilisons Fraps sur l'environnement de Barcelone, le plus lourd dans le jeu. Les GeForce GTX 980 Ti et Titan X ont ici une avance confortable. Cela se tasse quelque peu en 4K, mais le R9 Fury X reste en retrait. Page 19 - Benchmark : Hitman Absolution Hitman Absolution  Hitman Absolution utilise un moteur plutôt lourd et qui manque probablement d'optimisations. La charge CPU est par ailleurs relativement élevée dans certaines scènes dans lesquelles une foule importante peut être animée. Différents effets DirectX 11 ont été intégrés avec la coopération d'AMD. Pour mesurer les performances, nous poussons les options graphiques au niveau ultra et utilisons fraps dans le jeu. Hitman Absolution est le jeu testé dans lequel les GeForce GTX 900 souffrent le plus, la bande passante mémoire ou les ROP étant visiblement un aspect primordial des performances. La R9 Fury X ayant du mal à se distinguer de la R9 390X, nous sommes tentés de supposer que la seconde option est la bonne. La R9 Fury X reste malgré tout proche de la GTX 980 Ti. La R9 Fury X passe de peu devant la GTX 980 Ti. Page 20 - Benchmark : Project Cars Project Cars  Project Cars est un jeu de course automobile développé depuis 2011 sur base d'un système de beta participative qui permettait d'accéder aux nouvelles builds régulières et d'interagir avec les développeurs de Slightlymad Studios (à l'origine des Need For Speed Shift). Son moteur au rendu différé supporte DirectX 11 et c'est ce mode que nous avons testé en poussant toutes les options au maximum ou en mode High à l'exception de l'antialiasing pour lequel nous nous somme contenté du seul SMAA Ultra ou High. Nous avons testé le jeu via Fraps sur un parcours bien défini et avec de la pluie au niveau des conditions météo. Un détail important à préciser puisqu'il réduit significativement les performances. Nous avons opté pour 7 concurrents qui restent devant nous pendant la mesure des performances. Les Radeon ont beaucoup de mal dans ce jeu très attendu et ce n'est pas nouveau. Critiqué pour avoir favorisé Nvidia, le développeur s'est justifié en expliquant que ce n'était pas du tout le cas, mais qu'AMD n'avait pas voulu collaborer en amont de la sortie du jeu pour s'assurer d'optimiser les performances. Difficile de savoir ce qu'il s'est réellement passé, mais depuis AMD a commencé à introduire des optimisations spécifiques dans ses pilotes. Les cartes les plus haut de gamme des deux fabricants sont ici limitées au niveau du CPU, mais à un niveau bien plus bas chez AMD. Contacté à ce sujet AMD nous a indiqué qu'il s'agissait probablement d'un problème dans la gestion du multithreading DX11 dans ses pilotes et qu'il travaillait dessus. En 4K avec un niveau de détails inférieur, la limite CPU se place à un niveau bien plus élevé, ce qui permet aux Radeon de bien mieux se positionner. A noter que le jeu s'est avéré instable sur les GeForce GTX 900. Un plantage du pilote survenait régulièrement, ce qui nous a demandé de recommencer plusieurs fois nos mesures. Page 21 - Benchmark : Splinter Cell Blacklist Splinter Cell Blacklist  Basé sur le LEAD engine, une version retravaillée en interne de l'Unreal Engine 2.5, Splinter Cell Blacklist profite pour la version PC d'effets graphiques supplémentaires mis en place en collaboration avec Nvidia tels que le HBAO+, la tessellation ou encore le TXAA. Notez au niveau de l'occlusion ambiante que le jeu propose de nombreuses options dont les plus avancées représentent l'effet le plus lourd du jeu. Nous mesurons les performances avec Fraps sur un parcours bien défini et le jeu est maintenu à jour via Uplay. La R9 Fury X se contente ici du niveau de performances de la GTX 980 G1 Gaming de Gigabyte. En 4K c'est beaucoup mieux pour la R9 Fury X qui revient au niveau des GTX 980 Ti et GTX Titan X. Page 22 - Benchmark : The Witcher 3 Wild Hunt The Witcher 3 : Wild Hunt  Très attendu, le dernier opus de The Witcher ne déçoit pas. Développé par CD Projekt RED, il repose sur le REDengine 3, un moteur conçu pour gérer de vastes mondes ouverts, raison pour laquelle il tourne exclusivement en 64-bit. CD Projekt RED s'est associé à Nvidia pour intégrer deux effets gaphique de la suite Gameworks : le HBAO+ et surtout HairWorks. Réponse au TressFX d'AMD, HairWorks améliore la chevelure des personnages, la crinière des chevaux et la fourrure de plusieurs animaux ou créatures rencontrés dans le jeux en faisant appel à un niveau de tessellation très élevé pour chaque brindille. HairWorks est donc très gourmand et Nvidia a ferait en sorte que son implémentation complique le travail d'optimisation d'AMD, ce qui n'a pas manqué de créer la polémique, même si en pratique désactiver cet effet ne dénature pas vraiment le jeu. Nous avons d'ailleurs décidé de le tester avec et sans HairWorks en 1440p. Lors de la moyenne, chacun de ces modes testés se verra attribuer un coefficient de 0.5, de manière à ce que ce jeu n'ait pas plus de poids que les autres. Tous les autres paramètres sont poussés à leur maximum en 1440p alors que nous nous contentons du niveau Medium en 4K. Nous effectuons un parcours bien défini avec Fraps. A noter qu'avec ses pilotes récents, AMD a eu la mauvaise idée de s'attaquer à HairWorks en limitant via ses pilotes le niveau de tesselation maximal autorisé dans The Witcher III. Une optimisation que nous avons désactivée pour ce test. [ Sans HairWorks ] [ Avec HairWorks ] Sans HairWorks, la R9 Fury X se positionne entre la GTX 980 G1 Gaming et la GTX 980 Ti de référence, mais avec cet effet activé, elle recule derrière la GTX 980 de référence. En 4K, sans HairWorks, c'est nettement mieux pour la R9 Fury X qui égale les GTX 980 Ti et GTX Titan X. A noter que les pilotes d'AMD ont toujours des problèmes dans ce jeu au niveau du support du multi-GPU. Page 23 - Benchmark : Tomb Raider Tomb Raider  Tomb Raider a été l'une des meilleures surprises de 2013. Le rendu graphique est plutôt réussi, AMD ayant collaboré avec les développeurs pour s'assurer d'une version PC de bon niveau. C'est particulièrement le cas pour TressFX, l'option de rendu avancé des cheveux de Lara qui apporte une bonne dose de réalisme. Nous avons testé Tomb Raider en mode de qualité Ultime+ en 1440p qui inclut l'effet TressFX et le niveau de qualité maximal pour les ombres. En 4K, nous désactivons cependant ce dernier et nous nous contentons du mode Ultime classique. Nous avons mesuré les performances avec Fraps, sans utiliser le bench intégré qui correspond plus aux cinématiques qu'aux scènes de jeu classiques. La Radeon R9 Fury X fait ici plus ou moins jeu égal avec la GeForce GTX 980 Ti. Il en va de même en 4K. Page 24 - Récapitulatif des performances RécapitulatifBien que les résultats de chaque jeu aient tous un intérêt, d'autant que dans le cas de la Fury X son positionnement est assez variable d'un titre à l'autre, nous avons calculé un indice de performances en nous basant sur l'ensemble de résultats et en attachant une importance particulière à donner le même poids à chacun des jeux. Nous avons attribué un indice de 100 à la GeForce GTX 980 de référence : Depuis le lancement de son premier GPU haut de gamme en 28nm équipant la Radeon HD 7970, AMD affiche un gain de performance de 86% en 1440p sur notre indice. Par rapport à Hawaii tel qu'intégré sur la R9 290X de référence en mode Quiet on est à +39% mais seulement à +22% face au modèle Sapphire Tri-X et 13% par rapport à la R9 390X Gaming qui est par contre nettement plus énergivore. Ces gains ne permettent toutefois pas à la Fury X d'égaler la 980 Ti de référence qui est 12% plus rapide, l'écart grimpant à 21% avec un modèle personnalisé tel que l'EVGA. La Fury X n'affiche en fait qu'un gain de 4% face à une 980 poussée telle que la Gigabyte. Le 4K et ses réglages associés sont plus à l'avantage de la Fury X qui affiche cette fois un gain de quasi 30% face à la R9 290X de Sapphire et de 13% par rapport à la GTX 980 Gigabyte. La GTX 980 Ti de référence reste 5% plus rapide, l'avantage passant à 14% sur l'EVGA 980 Ti. Page 25 - Overclocking du GPU Fiji Overclocking du GPU FijiContrairement à ce que nous vous indiquions lors de la publication originale de ce dossier, il est possible d'overclocker la mémoire HBM, ou tout du moins un domaine de fréquence qui y est lié. Rappelons que plusieurs domaines de fréquences peuvent être exploités dans un GPU et qu'il est difficile de savoir avec certitude tout ce qui est impacté par une modification de fréquence. Pousser celle du bus mémoire pourrait ainsi également avoir un impact sur une autre partie du sous-système mémoire du GPU, ce qui inclus le cache L2, les ROP etc. Nos tests n'ont cependant pas mis en évidence de différence notable sur ce point entre Fiji et ses prédécesseurs. Comme expliqué sur la page dédiée à la Radeon Fury X, nous avons pu stabiliser parfaitement son GPU à 1125 MHz, contre 1050 MHz par défaut. Un overclocking relativement modeste de 7.1%. Des artéfacts apparaissent rapidement à 1150 MHz, suivis de plantages. Il est possible de pousser la limite de consommation de 385W à plus de 500W, mais en pratique ce n'est pas nécessaire, la consommation en jeu reste bien inférieure et ne limite jamais la fréquence GPU, d'autant plus qu'il n'est pas possible à l'heure actuelle de pousser la tension GPU pour aller au-delà. Pour overclocker la mémoire, ce qui n'est pas possible à la base, nous avons dû activer une option dans le logiciel Afterburner de MSI : "Extend official overclocking limits". Une fois celle-ci activée et après un reboot du système, il est possible de modifier la fréquence mémoire, y compris dans la page Overdrive du Catalyst Control Center. Nous ne savons pas pourquoi cette possibilité a été masquée par AMD.  Du côté de la mémoire HBM, nous avons pu pousser la fréquence de 500 à 550 MHz, un gain de 10%. Au-delà, des artéfacts de plus en plus nombreux apparaissent, même si aucun plantage n'est à signaler à 575 ou à 600 MHz. Pour analyser l'impact sur les performances de l'augmentation des fréquences GPU et mémoire, nous avons voulu appliquer un overclocking identique à ces deux éléments. Nous avons opté pour +8%. Pour cela nous avons dû pousser le GPU à 1135 MHz, fréquence à laquelle il est suffisamment stable pour exécuter notre suite de tests sans artéfacts si nous le maintenons au frais en poussant la ventilation à une vitesse élevée. Et du côté de la HBM, nous nous sommes donc contentés de 540 MHz. Voici les résultats que nous avons obtenus en 1440p HQ : [ Gains (%) ] [ Performances (fps) ] Nous pouvons observer qu'overclocker le GPU de 8% apporte un gain de 2.3 à 6.6% avec une moyenne de 5.0% au niveau de notre indice, si nous ne prenons pas en compte Project Cars qui est limité par le CPU au niveau des pilotes AMD. Un même overclocking de 8% de la mémoire HBM entraîne une augmentation des performances de 0.8 et 4.6%, avec une moyenne de 2.5%. Son impact est donc moindre en pratique que l'overclocking du GPU. A l'exception de GRID 2, les gains les plus importants se retrouvent assez logiquement dans les jeux pour lesquels nous avons activé un niveau élevé de MSAA. En moyenne le gain de l'overclocking combiné s'élève à 7.4%. Les performances sont boostées de 5.4 à 8.3% selon les jeux, un petit dépassement du gain théorique maximal qui peut s'expliquer par la précision de nos mesures limitée à 0.1 fps ainsi qu'à la marge d'erreur lors de ces mesures. Page 26 - Conclusion ConclusionEn découvrant les résultats de la Radeon R9 Fury X, il est difficile de ne pas être déçu. Support d'une nouvelle génération de mémoire avec bande passante massive, nouveau monstre de 8.9 milliards de transistors avec record de puissance de calcul, recours au watercooling pour repousser les limites thermiques Sur le papier, nous ne pouvions qu'espérer une victoire de la R9 Fury X face à la GTX 980 Ti de Nvidia, ou tout du moins un match nul. Mais ce n'est pas aussi simple.  Nvidia a frappé fort avec l'architecture Maxwell de seconde génération, qui a permis la mise au point de GPU particulièrement bien équilibrés pour les jeux vidéo. C'est justement ce qui semble faire quelque peu défaut au GPU Fiji qui nous donne l'impression d'être limité en interne par un ou plusieurs goulets d'étranglement. Peut-être un manque de ROP, peut-être des Shader Engines trop gros, peut-être autre chose, nous n'avons pas assez de recul pour en être certains. Mais quelque chose le retient et l'empêche de profiter pleinement de toute la puissance de calcul et de toute la bande passante mémoire à sa disposition. Cela ne veut pas dire que les ingénieurs d'AMD n'ont pas effectué correctement leur travail de simulation et pris les meilleures décisions possibles pour l'organisation interne de Fiji. En fait, il est probable que les limites techniques des procédés de fabrication actuels et de flexibilité d'une architecture GCN vieillissante aient en quelque sorte imposé ces directions à AMD qui ne correspondent pas à un idéal en terme d'équilibre. C'est d'autant plus dommage que Fiji reste une prouesse technique de la part des équipes d'AMD qui inaugure pour les GPU l'utilisation de larges interposers et de la mémoire HBM. Des techniques de fabrication vouées à se généraliser et qui ont demandé énormément de travail. En pratique, la Radeon R9 Fury X affiche un gain de 22% en 1440p et de 30% en 2160p sur une Radeon R9 290X telle que celle proposée par Sapphire. C'est insuffisant pour battre la GeForce GTX 980 Ti de référence qui reste en moyenne 12 à 5% sur notre indice moyen suivant la résolution, et les versions personnalisées des partenaires Nvidia enfoncent le clou. Avec un tarif de lancement de 710 , l'écart de prix face aux GTX 980 Ti ne parait pas suffisant alors que le surcoût face aux R9 390X ou GTX 980 personnalisées parait important, surtout pour une utilisation en 1440p. Si nous ignorons cette concurrence un instant, tout n'est pas noir pour la R9 Fury X. Elle parvient à proposer un nouveau gain de performances malgré la non évolution du process de fabrication qui reste en 28nm, pousse enfin le rendement énergétique des Radeon vers le haut, et montre qu'AMD est également capable de travailler la finition de ses cartes graphiques haut de gamme. De quoi convaincre sans aucun doute certains passionnés de la marque, même s'ils devront prendre en compte deux réserves importantes. Tout d'abord, la pérennité de la solution. Si 4 Go de mémoire sont suffisants à l'heure actuelle pour une puce offrant un tel niveau de performance, en mono GPU tout du moins, et que le HDCP 2.2 n'est pas primordial pour le contenu vidéo 4K officiel aujourd'hui, nous ne nous risquerons pas à estimer que ce sera toujours le cas dans 2 ans par exemple. La R9 Fury X s'adresse ainsi plutôt à un public qui met à jour sa carte graphique chaque année. Ensuite, si le recours au watercooling peut réduire nettement le niveau sonore et la température GPU, il introduit également un sifflement aigu constant lié à la pompe sur les deux cartes que nous avons pu avoir entre nos mains. AMD nous a indiqué à la dernière minute avoir amélioré ce point sur les cartes produites récemment, reste à savoir dans quelle mesure. En attendant si vous y êtes sensibles et/ou que votre boîtier n'est pas très bien isolé, n'oubliez pas que ce sifflement peut être agaçant sur la R9 Fury X.  Terminons par un petit mot sur le futur. Proche de nous tout d'abord avec l'arrivée le mois prochain d'une Radeon R9 Fury équipée d'un GPU Fiji quelque peu bridé et de systèmes de refroidissement classiques. Cette solution pourrait s'avérer très intéressante puisque si AMD désactive quelques unités de calcul alors que le GPU est limité ailleurs, le niveau de performances pourrait rester très proche de celui de la R9 Fury X. Un peu plus tard, la Radeon R9 Nano pourrait également proposer un compromis très intéressant en associant design ultra compact et performances haut de gamme. Enfin, cette première expérience d'AMD avec la mémoire HBM pourrait se révéler cruciale pour de nombreux produits qui seront introduits par la société l'an prochain, dont bien entendu une nouvelle génération de GPU fabriqués en 16nm ou en 14nm. Copyright © 1997-2024 HardWare.fr. Tous droits réservés. |