| |
| |
| Intel Haswell-E, LGA 2011-v3 et DDR4 : Core i7-5960X, 5930K et 5820K Processeurs Publié le Vendredi 29 Août 2014 par Marc Prieur URL: /articles/924-1/intel-haswell-e-lga-2011-v3-ddr4-core-i7-5960x-5930k-5820k.html Page 1 - Haswell-E et LGA 2011-v3 Après avoir débarqué sur la plate-forme LGA 1150 en juin 2013, l'architecture Haswell arrive désormais sur LGA 2011-v3 avec les Core i7-5960X, 5930K et 5820K. Cette plate-forme inaugure au passage l'arrivée de la DDR4 dans nos machines.  LGA 1366 et LGA 2011, petit retour en arrièreDepuis plusieurs années maintenant, Intel fait évoluer en parallèle deux plates-formes LGA. Le cur de la gamme est ainsi constitué par les puces LGA 115x, avec au maximum 4 curs et de la mémoire gérée sur deux canaux : - 09/2009 : LGA 1156, 45nm, Lynnfield - 01/2011 : LGA 1155, 32nm, Sandy Bridge - 04/2012 : LGA 1155, 22nm, Ivy Bridge - 06/2013 : LGA 1150, 22nm, Haswell Mais des Core i7 plus haut de gamme, déclinés de processeurs initialement destinés à la gamme Xeon, existent donc sur d'autres plates-formes qui accueillent des processeurs avec plus de curs et de canaux mémoire : - 03/2010 : LGA 1366, 32nm, Gulftown - 11/2011 : LGA 2011, 32nm, Sandy Bridge-E - 09/2013 : LGA 2011, 22nm, Ivy Bridge-E  LGA 2011, LGA 1366 et LGA 1155 Si Gulftown, qui a repris le Socket initial des Core i7 introduits fin 2008, n'avait pas d'équivalent dans la gamme grand public, Sandy Bridge-E et Ivy Bridge-E sont pour leur part des versions plus évoluées de leurs pendants moins onéreux mais avec respectivement 10 et 17 mois de délai. Disponible en version 6 curs, Gulftown disposait de 3 canaux DDR3 64 bits contre 4 pour la plate-forme suivante en LGA 2011. Malgré le positionnement haut de gamme des processeurs, le compteur de curs restera par contre bloqué à 6 en version Core i7 sur Sandy Bridge-E, seuls les Xeon profitant des 8 curs intégrés sur le die. Pour Ivy Bridge-E là encore les i7 en resteront aux 6 curs, avec cette fois une version spécifique du die à 6 curs contre 12 curs au plus pour les Xeon. Haswell-E et LGA 2011-v3C'est cette fois avec 14 mois de retard sur Haswell que Haswell-E débarque dans nos machines. On retrouve au sein de ce processeur les améliorations micro-architecturales présentées à l'époque, à savoir : - Le jeu d'instruction AVX2 et les instructions FMA3 - Le jeu d'instruction TSX, qui est toutefois victime d'un bug - Un scheduler musclé - Passage de 6 à 8 ports d'exécutions - Un débit doublé pour le cache L1 - Un régulateur de tension intégré Ces améliorations sont présentes au sein d'un processeur qui n'est cette fois plus limité à 6 curs mais à 8 curs, ce décompte étant toutefois réservé comme nous le verrons plus loin au Core i7-5960X à 999$. Associé à 20 Mo de cache L3, ce processeur gravé en 22nm occupe une surface de 355,5 mm² pour un total de 2,6 milliards transistors, soit 38 et 40% de hausse par rapport à son prédécesseur ! 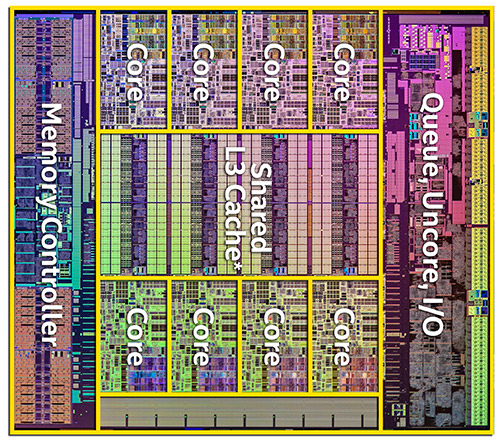 En sus des 8 curs, le processeur intègre un contrôleur PCI-Express Gen3 proposant pas moins de 40 lignes au maximum, mais bridé à 28 sur le 5820K, loin des 16 lignes gérées sur Socket LGA 1150. Ces ports peuvent être gérés de manière assez flexible, avec par exemple 2x16+1x8, 1x16+3x8 ou encore 5x8 ports, de quoi ravir ceux qui ont besoin d'une grande connectivité avec des cartes filles. Il faut toutefois préciser que pour l'usage le plus courant, à savoir un SLI ou un CrossFire X à 2 cartes, les 2 ports x8 PCIe Gen3 d'une plate-forme classique sont largement suffisants. Côté mémoire à l'instar de ses prédécesseurs Haswell-E intègre un contrôleur gérant la mémoire sur 4 canaux 64 bits. Mais alors que Sandy Bridge-E se limitait à la DDR3-1600 et qu'Ivy Bridge-E passait à la DDR3-1866, Haswell-E intègre pour la première fois un contrôleur mémoire DDR4, un type de mémoire sur lequel nous reviendrons plus loin. La vitesse officielle reste toutefois assez faible, DDR4-2133, soit une bande passante de 68,3 Go contre 59,7 Go /s auparavant. Il ne s'agit toutefois que d'une limitation théorique, en pratique via les profils XMP notamment des vitesses supérieures sont accessibles, comme c'était également le cas en DDR3 sur LGA 2011. Haswell-E prend place au sein d'un nouveau Socket, le LGA 2011-v3, qui accueillera également les futurs Broadwell-E en 14nm prévus pour l'an prochain, Intel nous ayant confirmé la compatibilité des cartes mères avec ces processeurs à venir. A noter que les systèmes de fixation pour ventirad LGA 2011 sont compatibles avec le LGA 2011-v3. Page 2 - Core i7-5960X, i7-5930K et i7-5820K Core i7-5960X, i7-5930K et i7-5820KLa gamme Core i7 LGA 2011-v3 est composée de trois déclinaisons : 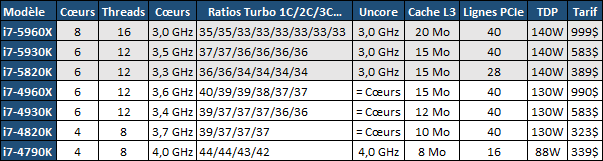  Comme vous pouvez le constater, seul l'onéreux Core i7-5960X dispose de 8 curs et d'un cache L3 de 20 Mo, un changement notable par rapport à l'i7-4960X donc. Par contre, afin de rester sur un TDP comparable, sa fréquence de fonctionnement est réduite à 3.0 GHz avec un Turbo pouvant atteindre au mieux 3.5 GHz avec 1 ou 2 curs actifs et 3.3 GHz au-delà. L'i7-5930K reste à 6 curs, comme l'i7-4930K, mais il dispose de 3 Mo de cache L3 supplémentaires. Côté fréquence on note que si la fréquence de base gagne 100 MHz, avec le Turbo le gain est nul et peut même être négatif avec 200 MHz de moins sur 1 cur ou 100 MHz de moins sur 3 et 4 curs. Enfin l'i7-5820K marque une avancée intéressante par rapport à son prédécesseur puisque Intel abandonne l'idée d'un quatre cur sur sa plate-forme haut de gamme, une bonne chose ! Forcément le prix augmente un peu au passage, mais on reste quasi 200$ en-dessous du 5930K pour des caractéristiques somme toute proches, avec seulement 100 à 200 MHz de différence. Cet état de fait ne devait toutefois pas pleinement contenter les pontes d'Intel qui se sont adonnés à un nouveau type de segmentation au niveau des lignes PCI Express Gen3 gérées par le processeur. Ainsi alors qu'Haswell-E intègre de base 40 lignes, ce qui permet des configurations de type 2x16+1x8, 1x16+3x8 voire 5x8, l'i7-5820K est bridé à 28 lignes ce qui le limite au 1x16+1x8+1x4, ou 3x8+1x4. Reste que comme nous l'indiquions précédemment, la bande passante offerte par un port x8 Gen3 est déjà largement suffisante pour une carte graphique par exemple dans le cadre d'un CrossFireX ou d'un SLI, seules des configurations à 4 ou 5 cartes dans le cadre du GPU Computing seront vraiment bridées par un i7-5820K. Vous avez dû remarquer dans notre tableau de spécifications la présence d'une colonne Uncore. En effet, à l'instar de Haswell, Haswell-E introduit une nouvelle fréquence pour l'Uncore, qui comprend entre autre le contrôleur mémoire mais aussi le cache L3. Jusqu'alors synchrone avec la fréquence des curs, cette partie est désormais découplée. Si sur LGA 1150 la fréquence de cet Uncore est égale à la fréquence de base des curs, sur tous les processeurs LGA 2011-v3 elle est de 3 GHz soit un recul notable sur les i7-5930K et i7-5820K. Rendez-vous sur la page DDR4 en pratique pour en savoir plus sur l'incidence de cette fréquence.  Point de vue extérieur on note plusieurs changements, avec tout d'abord un IHS modifié dans sa forme ainsi qu'une simplification au niveau des condensateurs arrière. Un CPU LGA 2011-v3 est légèrement plus haut (moins de 1mm de différence) qu'un LGA 2011, du fait du PCB du packaging un peu plus épais. On note également la présence d'un nombre plus important de points de contacts en comparaison d'un LGA 2011 (cf. ici), mais nous n'avons pas eu le courage d'en faire le décompte. A l'instar des processeurs LGA 2011 et contrairement au LGA 115x, les Core i7 LGA 2011-v3 ne sont pas fournis avec un ventirad. Page 3 - X99 Express et ASUS X99-Deluxe X99 ExpressL'arrivée de la plate-forme LGA 2011-v3 est l'occasion pour Intel de lancer un nouveau chipset, le X99 Express. Il vient remplacer un X79 Express vieillissant et y apporte deux grosses nouveautés : - On passe de 6 à 10 ports Serial ATA, tous en 6 Gb/s (contre 2 sur X79) - Il gère désormais l'USB 3.0 avec un maximum de 6 ports 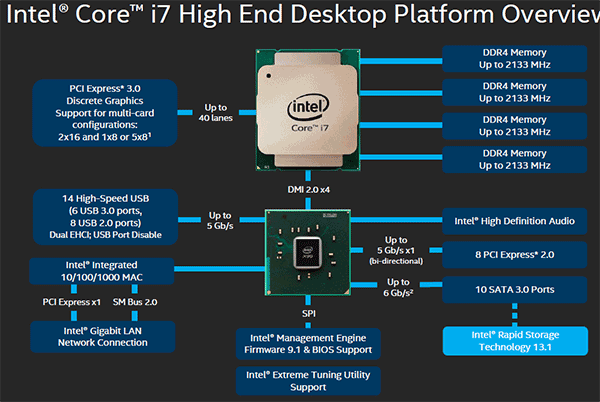 La plate-forme est donc désormais au goût du jour, il faut toutefois préciser que le passage de 6 à 10 ports SATA se fait via l'ajout d'un second contrôleur SATA qui n'est pas géré par les pilotes Intel RST et ne peut donc pas utiliser le RAID Intel, a contrario du premier contrôleur et de ses 6 ports. Le X99 n'apporte par contre rien de neuf au niveau de l'interconnexion avec le processeur qui reste de type DMI 2.0 x4, soit 2 Go /s dans chaque sens, ce qui n'est pas suffisant pour les scénarios qui satureraient pleinement les ports SATA 6 Gb/s et USB 3, puisqu'avec simplement 4 SSD on arrive à cette limite. Même si ce type d'usage reste plus qu'exceptionnel, une bande passante doublée entre processeur et chipset n'aurait pas été de refus ! ASUS X99-DeluxeLors du lancement d'une nouvelle plate-forme Intel, nous utilisions traditionnellement une carte mère de marque Intel, mais ce n'est plus possible pour la simple et bonne raison qu'Intel a fermé sa division cartes mères il y a quelques mois désormais, avec pour conséquence l'absence de mise à jour de bios pour le support d'Ivy Bridge-E sur ses X79 ou de bios pour le support des Haswell Refresh sur ses Z87, ce qui est plus que regrettable.  Pour ce test ASUS nous a fourni une carte mère ASUS X99-Deluxe. Cette carte intègre une alimentation processeur à 8 phases et ASUS met en avant l'utilisation sur ses Socket LGA 2011-v3 de tous les points de contacts présents sur les processeurs, là où les autres constructeurs ont suivi le design d'Intel. Faute de datasheet de la part d'Intel, on ne sait pas quelle est l'utilité réelle de ces points de contacts, ils sont probablement destinés à l'alimentation et leur ajout permettrait de mieux répartir la puissance fournie au processeur lors d'overclocking extrêmes. L'ASUS X99-Deluxe permet au processeur de gérer jusqu'à 5 ports PCIe Gen3, ou 3 dans le cas d'un i7-5820K. 4 lignes PCIe sont également dédiées à un port M.2 x4 Gen3 pouvant donc atteindre 4 Go /s, mais si vous l'utilisez il ne sera pas possible d'utiliser une 5è carte fille en x8 donc. A défaut de place sur le PCB, on notera d'ailleurs le positionnement assez étrange de ce port M.2 qui vient se positionner à l'avant de la carte, à la verticale (un support est fournit pour le maintenir en place).  Ce n'est pas le seul port M.2 que peut accueillir la carte puisqu'elle est livrée avec une carte fille venant se positionner dans un port PCIe qui permet d'intégrer un second SSD M.2 ! Toujours côté stockage, en sus des 10 ports SATA gérés par le X99 dont 2 sont intégrés au sein d'un port SATA Express, ASUS intègre une puce ASMedia qui permet d'ajouter la gestion d'un second SATA Express ainsi ou de deux SATA additionnels. On trouve également un total de 14 ports USB 3, dont 10 à l'arrière, ASUS couplant les 6 natifs du X99 avec un contrôleur ASMedia additionnel ainsi que des hubs de la même origine. La partie audio est pour sa part confiée à une puce Realtek ALC1150 qui a droit à une intégration de type Crystal Sound 2 avec notamment des condensateurs de qualité et un amplificateur casque. Côté réseau on trouve 2 ports réseaux RJ45 Gigabit, le premier via une puce Intel I218-V qui fait office de PHY et permet d'utiliser le contrôleur interne du X99 et le second via une puce Intel I211-AT. Le WiFi est de la partie avec le 802.11 a/b/g/n/ac avec 3 antennes ainsi que le Bluetooth 4.  Côté ventilation on note la présence de 6 ports pouvant réguler à la fois des ventilateurs 3 ou 4 pins, et ASUS va plus loin via une carte d'extension permettant d'ajouter la gestion de 3 ventilateurs supplémentaires ainsi que 3 sondes additionnelles (une seule est fournie). Vous l'aurez compris la X99-Deluxe fait le plein de fonctionnalités et cela se ressent sur le tarif avec pas moins de 359 . Des cartes plus simples seront bien entendu disponibles, avec par exemple la X99-A qui arrivera à un tarif plus raisonnable de 229 . A noter un point toujours regrettable, ce sont les fonctionnalités d'overclocking automatique des bios. Introduites par ASUS sur Z77 puis reprises en curs par tous les concurrents qui n'avaient pas envie d'être en retard sur les benchmarks, ces fonctions modifient les réglages par défaut du processeur en alignant toutes les fréquences Turbo, quelque soit le nombre de cur, sur la fréquence Turbo maximale. Un réglage qui n'est pas toujours actif, ou, plus sournoisement, pas dans toutes les situations. Ainsi sur un 5960X spécifié pour fonctionner à 3.3 GHz au maximum avec plus de deux curs actifs, une simple modification des réglages mémoires sur la X99-Deluxe entraîne un alignement de toutes les fréquences Turbo à 3.5 GHz. Bien entendu nous n'avons pas testé le processeur dans ces conditions mais rétabli les réglages d'origine du processeur, sans quoi les performances auraient pu être jusqu'à 6% supérieures à celles par défaut ! Nous ne pouvons que condamner ces overclockings automatiques trompant les testeurs les moins attentifs. Page 4 - La DDR4 : la problématique de la fréquence Comme tous les standards de mémoire précédents, la DDR4 est destinée à poursuivre l'augmentation des débits sans devoir augmenter la vitesse à laquelle les cellules mémoires fonctionnent.  Illustration de Synopsys . A la fin des années 90, celles-ci tournaient à une fréquence de 66 à 150 MHz pour la SDR-SDRAM. Cette fréquence a progressé quelque peu lors du passage à la mémoire DDR dont les cellules évoluaient entre 100 et 300 MHz, mais il n'y a plus eu d'évolution avec les mémoires DDR2 et DDR3. Quant à la DDR4, elle se contente de 166 à 200 MHz pour les variantes standardisées par le JEDEC. Pour améliorer les performances malgré cette non évolution au niveau des cellules en elles-mêmes, des mécanismes de plus en plus complexes ont dû être mis en place. Mais pourquoi l'industrie ne peut-elle pas pousser simplement la fréquence de fonctionnement interne ? Difficile d'augmenter la fréquence des cellulesNous pourrions résumer la grande problématique de la DRAM à travers cette image : essayer de contrôler le niveau de remplissage de milliards de passoires réparties sur un vaste terrain, ce n'est pas simple à exécuter rapidement et à faible coût. C'est pourtant à peu de choses près ce qui se passe avec les milliards de cellules des puces mémoires et c'est en grande partie ce qui explique le mur rencontré en terme de fréquence des cellules. Rappelons brièvement comment fonctionne la DRAM : une cellule est capable de retenir un bit à l'aide d'un transistor et d'un condensateur. Ce dernier représente la zone de stockage et physiquement il peut ressembler à un réservoir ou à un puits qui emmagasine une charge électrique. Le transistor est la porte d'accès à ce stockage. 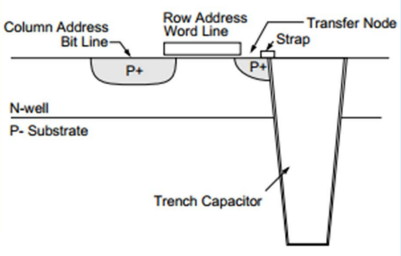 Représentation d'une cellule mémoire avec un condensateur de type puits (à droite). En microélectronique, tout ce qui est bien isolé est difficile d'accès alors que tout ce qui est mal isolé peut-être accédé très rapidement, sans devoir exercer de force importante qui userait le composant. Contrairement à la Flash, ces paramètres sont très importants pour la DRAM dont la zone de stockage se trouve donc être mal isolée. Elle peut être vue comme une passoire qui se vide progressivement. La durée de vie de ce stockage est ainsi très faible (64ms max jusqu'à 85 °C, 32ms max au-delà, selon les normes actuelles), c'est pour cela qu'un rafraîchissement régulier est nécessaire (lecture puis réécriture). 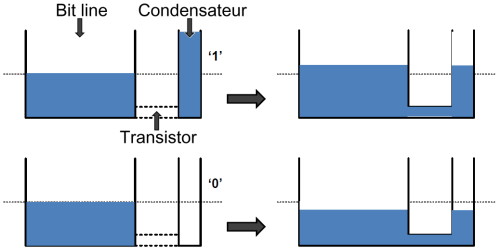 Pour lire une cellule mémoire, il n'est malheureusement pas possible de simplement vérifier si le condensateur est vide (0) ou rempli (1). C'est un petit peu plus complexe que cela. Un niveau intermédiaire de charge doit être maintenu sur son canal d'accès (bit line), c'est le préchargement. Une fois que le transistor lié au condensateur est ouvert, s'il est vide, une partie de la charge du canal d'accès va s'y déverser. S'il est plein, c'est lui qui va se déverser sur le canal d'accès, un petit peu comme différents niveaux d'eau s'égalisent. Pour retrouver la donnée stockée, un amplificateur va déterminer si le niveau de charge du canal d'accès a légèrement augmenté ou légèrement baissé. En d'autres termes il ne s'agit pas de différencier facilement un 0 et un 1 mais plutôt d'arriver à distinguer un 0.45 d'un 0.55. Une différence qui est progressivement moins marquée au fur et à mesure qu'on s'éloigne du dernier rafraîchissement. la fréquence est les timings délimitent le temps attribué aux amplificateurs pour faire la différence avec certitude entre ces niveaux très faibles. Par ailleurs, ces niveaux ont besoin d'un petit peu de temps pour se stabiliser sans quoi la différence serait encore moins marquée. Cela participe à limiter la capacité des cellules à monter en fréquence. Un autre point concerne la taille des blocs de données, appelés banques. Plusieurs banques sont exploitées dans chaque puce mémoire de manière à faciliter le pipelining, soit la possibilité par exemple de précharger une banque pendant qu'une lecture se fait dans une autre banque de manière à ne pas perdre de temps. Plus les banques sont grosses et plus il faut de temps au signal pour s'y répandre, ce qui limite aussi la fréquence. Pour réduire ce problème, les banques de mémoire DRAM sont organisées en un maillage de sous-blocs de cellules. Une complexité de l'organisation nécessaire pour faire face à l'augmentation constante de la densité, soit de la quantité de données par banque. Augmenter le nombre de niveaux de sous-blocs pourrait permettre de faciliter la montée fréquence mais au prix d'une latence en hausse et de coûts de fabrication qui exploseraient. Le coût de fabrication est critique pour les puces dédiées la mémoire centrale qui sont depuis longtemps devenues des produits sans valeur ajoutée, des matières premières dont la caractéristique principale est la densité. Il n'est pas envisageable pour l'industrie d'augmenter les coûts simplement pour monter quelque peu en fréquence. Avec des objectifs différents en termes de coûts, de densité et de latence, les puces GDDR peuvent d'ailleurs monter plus haut en fréquence, jusqu'à 650 MHz. Les fabricants de barrettes mémoires peuvent également sélectionner les meilleures puces pour proposer des produits plus avancés qui montent un petit peu plus haut en performances, par exemple avec des cellules qui sont poussées jusqu'à 300 MHz au lieu de 200 MHz. La solution jusqu'ici : le prefetchPour poursuivre l'augmentation du débit des mémoires, il a donc fallu trouver d'autres solutions que la fréquence de leurs cellules. L'une d'elle peut être d'élargir le bus mémoire, cela est fait depuis quelques temps à travers les contrôleurs multi-canaux mais il y a des limites à cette approche coûteuse, qui par ailleurs ne participe pas à réduire la latence. 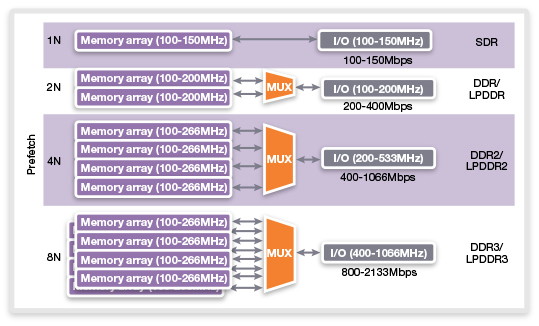 Une autre solution est d'augmenter la fréquence du bus mémoire en mettant en place des mécanismes plus complexes pour l'alimenter. C'est le cas du prefetching. Son principe est simple, il suffit de lire un nombre plus élevé de cellules mémoires en parallèle, de placer le tout dans un petit buffer qui déversera ces données en série mais à très haute vitesse sur le bus mémoire. Avec la mémoire DDR le prefetching a été introduit à 2, il est passé à 4 avec la DDR2 et à 8 avec la DDR3. De quoi profiter du mode de transmission DDR, et doubler à deux reprises la vitesse du bus.  L'évolution logique aurait donc été pour la DDR4 de passer le prefetching à 16 pour doubler à nouveau la fréquence du bus par rapport à la fréquence des cellules, mais cela aurait eu différents désavantages. Chaque banque mémoire simple est à la base subdivisée en petits blocs de cellules. Avec prefetching nX, chaque banque mémoire devient subdivisée en X tableaux de petits blocs de cellules mémoire. Une complexité qui augmente les coûts et la consommation avec une multiplication des voies de communication. Par ailleurs, le prefetching augmente la plus petite quantité de données qui peut être lue, ce qui finit par réduire l'efficacité des accès mémoire. Sur un canal 64-bit classique, un prefetching de 8 signifie que les accès se font au minimum par 64 octets. Cela s'accorde assez bien aux caches des CPU et c'est déjà une valeur relativement élevée. Aller au-delà n'aurait pas été une très bonne idée. La nouvelle solution : le bank groupingAvec la GDDR5 et avec la DDR4 qui a suivi, le Jedec a fait le choix d'une nouvelle approche dénommée bank grouping. Elle consiste à séparer les banques mémoire en plusieurs groupes, deux pour les puces de type x16 (bus de communication de 16-bit) et 4 pour les puces de type x8/x4 rencontrées sur la plupart des modules DIMM. 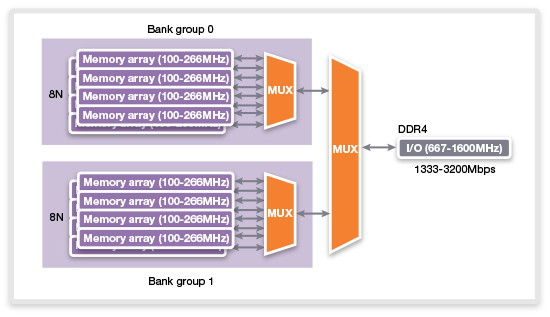 Chaque groupe de banques se comporte indépendamment des autres et un second niveau de petits buffers qui alimentent le bus mémoire est mis en place. Avec plus de données à sa disposition, il est capable de supporter un bus mémoire à plus haute fréquence. Il n'est cependant pas question de doubler voire de quadrupler la vitesse du bus mémoire dans tous les cas grâce à 2 ou 4 groupes de banques mémoire travaillant en parallèle. Le bus mémoire ne monte pas aussi haut en fréquence si facilement. Pour profiter du bank grouping, le contrôleur mémoire qui a déjà de très nombreux paramètres à gérer doit en plus faire en sorte d'alterner les accès entre différents groupes de banques. Ce n'est pas toujours possible. Les différents groupes de banques mémoires peuvent ainsi pour la plupart des niveaux de spécifications (à l'exception de la DDR4-3200) fournir plus de données que nécessaire pour alimenter le bus. De quoi permettre dans la plupart des cas de s'approcher d'un niveau d'efficacité élevé et de réduire les dégâts quand les accès mémoires ne sont pas optimaux. Par exemple, en DDR4-2400 tel que spécifié par le Jedec, les cellules mémoire tournent à 200 MHz, ce qui indique qu'il faut à leur niveau qu'elles fournissent 12 données en parallèle au total pour alimenter le bus mémoire qui tourne, lui, à 1200 MHz en DDR. Deux groupes de banques, avec prefetch de 8 chacun, permettent de débiter jusqu'à 16 données ce qui est plus que suffisant pour alimenter le bus. Mais si le contrôleur mémoire n'a pas bien organisé ses accès et qu'ils se font successivement dans le même groupe de banques, le bus ne sera pas alimenté correctement et la bande passante mémoire sera directement impactée. Tout cela est régi par 2 timings relativement peu connus : tCCD et tCCD_L. Petite réflexion : pourquoi ne pas avoir multiplié autant que possible les groupes de banques pour réduire l'occurrence d'accès successifs dans un même groupe ? Nous en revenons ici au coût trop élevé que cela pourrait engendrer notamment au niveau des voies de communication. Cela augmenterait également la consommation, chaque activation de banque étant très gourmande (une restriction empêcher d'ailleurs la mémoire d'activer plus de 4 banques dans un intervalle trop court). Opter pour 2 au 4 groupes de banques, suivant le nombre de bits de communication des puces mémoire, est un compromis qui a été fait entre performances, coûts et consommation. tCCD et tCCD_LCes timings représentent le délai entre deux lectures ou écritures successives. tCCD (également appelé tCCD_S) concerne les accès entre deux groupes de banques différents et tCCD_L à l'intérieur d'un même groupe. tCCD est en principe fixé à 4 cycles pour toutes les mémoire DDR4, ce qui correspond à ce qui est nécessaire pour alimenter le bus mémoire à pleine vitesse, ni plus (il y aurait engorgement), ni moins (la bande passante serait limitée). Certains fabricants de cartes-mères peuvent cependant être tentés de tricher à ce niveau pour faciliter l'overclocking de la mémoire, en impactant directement la bande passante mémoire exploitable. De la DDR4-3000 avec un tCCD de 6 cycles affiche une bande passante exploitable identique à celle d'une éventuelle DDR4-2000, ce qui n'a aucun sens pour l'utilisateur.  De son côté, tCCD_L augmente par contre avec le niveau de spécification de la DDR4. De 4 pour la DDR4-1333 il monte jusqu'à 8 pour la DDR4-3200. Ce paramètre définit la fréquence des cellules par rapport à la fréquence du bus mémoire. Plus il est élevé plus l'impact d'une mauvaise répartition des accès mémoire sera élevé. Bien que peu mis en avant par les fabricants de mémoire, il s'agit d'un timing crucial pour la DDR4. Le paramètre tCCD_L est défini dans le SPD des modules mémoire mais pas dans les profils XMP qui exploitent des fréquences plus élevées. Ces profils ne peuvent donc pas jouer sur ce point pour monter en fréquence, ce qui d'un côté n'est pas plus mal sur le plan des performances. Le bios des cartes-mères peut cependant décider de pousser ces valeurs à la hausse, sans forcément l'indiquer à l'utilisateur. En guise d'exemple, la DDR4-3000 de G.Skill que nous avons testée repose sur un SPD qui suit les spécifications Jedec de type DDR4-2133, soit avec un tCCD_L de 6 cycles. Alors que le Jedec définit un tCCD_L de 7 cycles pour la DDR4-2666 et de 8 cycles pour la DDR4-3200, il reste de 6 cycles via les profils XMP 2666 et 3000 de ce kit, ce qui pousse la fréquence des cellules mémoires à 222 et 266 MHz au lieu de +/- 190 et 187 MHz. Autant pour les performances (surtout en pratique quand il est plus difficile pour le contrôleur d'optimiser l'organisation des accès) que pour les capacités d'overclocking, il y a encore peu de recul sur l'impact de tCCD_L, valeur qui est modifiable dans certains bios. Globalement, nous pouvons cependant raisonnablement supposer qu'augmenter tCCD_L facilitera la montée en fréquence du bus alors que réduire tCDD_L facilitera la réduction de certains autres timings. Page 5 - Corsair et G.Skill, DDR4 en pratique Les kits G.Skill et CorsairPour ce test, Corsair comme G.Skill on pu nous fournir des kits mémoires 4x4 Go.  Chez Corsair, il s'agit d'un kit Vengeance LPX 16 Go (4x4 Go) DDR4-2666 fonctionnant avec des latences de 15-17-17-35 à une tension de 1.2V. Ce kit est décliné avec des radiateurs noir, rouge, blanc ou bleu. En pratique nous avons mesuré que les latences de 15-17-17-35 étaient équivalentes en termes de performances à un 16-16-16-39. A noter qu'un second profil DDR4-2800 16-17-17-37 à 1.35V est intégré dans ces barrettes. Point de vue format, on note plusieurs différences par rapport à la DDR3 : le détrompeur central revient un peu vers le centre, ce qui empêche à moins d'utiliser un marteau l'insertion dans un slot destiné à une ancienne norme mémoire, et le nombre de contacts passe de 240 à 288 afin d'accueillir le jeu de commande plus complexe de la DDR4. Ces contacts sont plus denses afin de conserver la même longueur de barrette. Enfin le bas de la barrette n'est plus horizontal mais a une forme d'arrondi qui est censé faciliter l'insertion et éviter la casse en cas d'insertion manquant de délicatesse.  Les Ripjaws 4 de G.Skill sont pour leur part un kit très haut de gamme puisqu'il s'agit toujours de 16 Go en 4x4 Go mais spécifiées cette fois en DDR4-3000 avec des latences de 15-15-15-35, soit des latences inférieures au kit Corsair alors que la fréquence est supérieure. Pour atteindre un tel niveau G.Skill a toutefois dû pousser la tension qui passe cette fois à 1.35V. En pratique en charge nous n'avons pas noté d'échauffement particulier malgré cette tension en hausse. Au passage il faut noter que jusqu'à un bios numéroté 4601 fournit par ASUS avant-hier, la DDR4-3000 n'était pas correctement exploitée par la X99-Deluxe. En effet le bios utilisait un timing tCCD à 6, ce qui entraînait en pratique une bande passante équivalente à de la DDR4-2000 ! Avec le dernier bios par contre le timing tCCD était bien à 4. Le tCDD_L était lui à 6, ce qui va de base au delà des spécifications JEDEC. Comparer DDR3 et DDR4, pas si facileLors de l'arrivée de la DDR2 ou de la DDR3, la comparaison entre les technologies mémoire était facilitée car la nouvelle venue n'était pas accompagnée de nouveaux processeurs. Avec la DDR4, c'est différent puisque les Haswell-E ne supportant pas la DDR3, il n'est pas possible de faire une comparaison en ne jouant que sur la mémoire. Pour commencer il a fallu trouver des processeurs les plus proches possibles, c'est pour cette raison que nous avons utilisé un i7-5930K et un i7-4960X, tous deux étant dotés de 6 curs et 15 Mo de cache. Nous les avons cadencés à 3.5 GHz pour les curs ainsi qu'à 3.5 GHz pour l'Uncore sur l'i7-5930K, ce dernier étant pour rappel sous cadencé par défaut sur Haswell-E. Augmenter la fréquence de l'Uncore permet d'accélérer la vitesse du contrôleur mémoire comme celle du cache L3, ainsi entre 3 et 3.5 GHz on gagne 6-8% de bande passante et la latence baisse de 15.7 à 14.9ns, mais elle reste toutefois supérieure à celle mesurée sur Ivy Bridge-E (12.6ns). Pour information le gain de performance enregistré sous 7-Zip du fait de cette hausse de l'Uncore est de 2%. Pour les tests nous avons utilisés AIDA64 pour la bande passante mémoire et la latence, ainsi que 7-zip pour un test plus pratique. En sus d'être assez sensible à la mémoire, 7-zip à l'avantage de ne pas tirer beaucoup profit de l'architecture Haswell ce qui permet d'éviter un biais supplémentaire dans la comparaison. On commence par un tableau de performance général. Le résultat 7-zip est exprimé en secondes, les bandes passantes en lecture et en écriture en Go /s et la latence en nanosecondes. 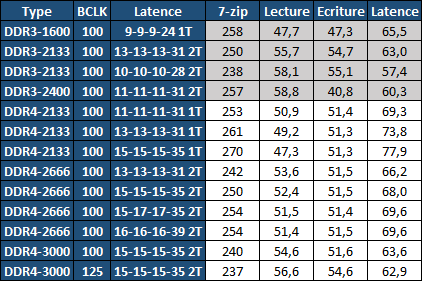 Concernant la DDR3, on note que sur la plate-forme LGA 2011 le mode DDR3-2400 n'est pas avantageux, du fait entre autre de latences moins bonnes et de performances en écritures très basses. Pour ce qui est de la DDR4 sur LGA 2011-3, les performances offertes par le mode "classique", à savoir de la DDR4-2133 que l'on trouvera généralement avec des latences de 15-15-15-35, sont en net recul face à la DDR3-1600 9-9-9-24. En effet la latence mesurée est logiquement en forte hausse, et en pratique sous 7-zip c'est la DDR3 qui l'emporte avec un avantage de plus de 4% ! Utiliser des latences plus basses, toujours en DDR4-2133, permet de prendre les devants sur la DDR3-1600 mais la DDR3-2133 est pour sa part hors d'atteinte. On notera d'ailleurs qu'en DDR3-2133 avec les mêmes timings principaux, la DDR3 est devant dans tous les secteurs ! La DDR3-2133 10-10-10-28 est en fait intouchable sauf pour les DDR4 les plus performantes, à savoir de la DDR4-3000 15-15-15-35, et pas dans n'importe quelles conditions puisqu'il faut pour obtenir les meilleures performances non pas utiliser une fréquence de base (BCLK) de 100 MHz mais plutôt une fréquence de 125 MHz, ce qui est d'ailleurs le cas par défaut avec la X99 Deluxe et le kit G.Skill Ripjaws 4 (on abaisse alors les coefficients pour avoir la même fréquence finale). On ne sait pas exactement d'où vient cet écart, cette fréquence n'étant normalement utilisée que comme base pour les autres, peut-être que le contrôleur mémoire d'Haswell-E est plus efficace avec certains ratios BLCK:DRAM qu'avec d'autres. Sous 7-zip on enregistre un gain de 12,5% à même BCLK entre de la DDR4 "classique", et de la DDR4 très haut de gamme, contre 8,4% entre de la DDR3-1600 CL9 et de la DDR3-2133 CL10. Pour rappel toutefois 7-zip est très dépendant de la vitesse de la mémoire, mais certaines applications, notamment les jeux lorsqu'ils ne sont pas limités par le GPU, sont assez friands d'une mémoire rapide, avec des écarts qui sont environ de moitié par rapport à ceux-ci. Si les latences obtenues ne sont guère étonnantes au vue des timings affichés de la DDR4, l'absence de hausse côté bande passante l'est plus. Afin de savoir d'où venait le problème, nous avons effectué quelques tests comparant la bande passante obtenue en double canal et en quadruple canal : 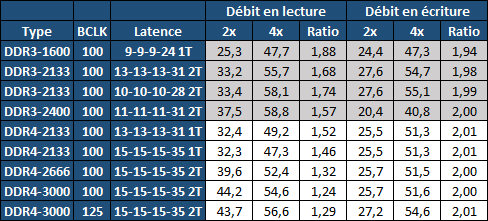 On est clairement confronté à un mur en terme de bande passante mémoire en quadruple canal, les gains inhérents à la fréquence de la DDR4 qui sont visibles en lecture double canal étant annihilés en quadruple canal. En DDR4-3000, la bande passante n'augmente que par un facteur de 1.24x à 1.29x en doublant les canaux, contre 1.88x en DDR3-1600 ! En écriture cette fois la hausse est parfaite, mais même en double canal la limitation est plus basse. On notera que fait d'utiliser un BLCK 125 MHz permet d'augmenter la bande passante en écriture même en double canal. D'où peut venir la limitation ? C'est ce que nous avons essayé de voir en jouant sur 2 paramètres en DDR4-3000 : la vitesse du BCLK et la vitesse de l'Uncore, qui s'applique pour rappel entre autre au contrôleur mémoire et au cache L3. 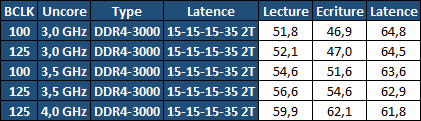 Avec un Uncore à 3 GHz comme c'est le cas par défaut, la vitesse du BLCK n'a que peu d'importance. Passer l'Uncore à 3.5 GHz permet d'augmenter notablement les débits, un gain qui peut encore être accru en utilisant de manière conjointe un BLCK de 125 MHz. Enfin utiliser un Uncore à 4 GHz permet encore de gagner en bande passante, avec près de 16% et 32% de gain en lecture et en écriture par rapport au réglage de base. 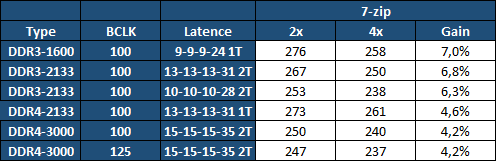 Au final l'avantage de la DDR4 en terme de bande passante est complètement bridé en quadruple canal par le contrôleur mémoire des processeurs Haswell-E, ce qui peut se voir en pratique sous 7-zip avec des gains plus importants lors du passage de 2 à 4 barrettes en DDR3 qu'en DDR4. Il faut de plus atteindre des fréquences élevées pour revenir à une latence correcte, ce qui fait qu'au final la DDR4 n'apparaît pas sous son meilleur jour à son lancement ce qui était il faut bien le dire également le cas de la DDR2 et de la DDR3 à leurs lancements respectifs ! En pratique les DDR4 les plus rapides étant chères, ce qui est certes tout relatif vu le prix de 5960X, nous vous conseillons à minima d'éviter les DDR4-2133 CL15 ou CL16. Page 6 - Overclocking OverclockingComme c'est le cas sur la plate-forme LGA 2011, la plate-forme LGA 2011-3 permet deux approches de l'overclocking, par le bus et par les coefficients. Si l'overclocking par le bus peut avoir quelques avantages, notamment pour ce qui est des performances avec une DDR4 haut de gamme comme nous l'avons vu précédemment, sachant que tous les processeurs de la gamme LGA 2011-3 disposent de coefficients multiplicateurs débloqués c'est cette méthode qui s'avère la plus simple. Au-delà d'une éventuelle utilisation d'un bus 125 MHz au lieu de 100 MHz, qui peut être automatique lors de l'activation de certains profils mémoires XMP, l'overclocking par le bus sera surtout utile aux chercheurs de records en tout genre prêts à passer du temps pour quelques points de benchmarks. Nous avons tenté d'overclocker les 3 processeurs LGA 2011-3 à notre disposition, refroidis par un Noctua NH-D14, hors boitier avec une température ambiante de 25°C. Pour chaque combinaison nous rapportons la fréquence, la tension d'alimentation du processeur (le VID), la consommation à la prise et la consommation mesurée sous l'ATX12V. Pour la charge nous optons pour Prime95 25.8 64 bits avec une taille de FFT fixe à 256K, qui nous permet à la fois de mesurer la consommation dans un cas de stress maximal, avec 35 à 45% de plus de consommation à fréquence stock que dans des logiciels plus classiques sur Haswell-E, et de valider le couple fréquence/tension. Nous commençons par une fréquence de 4 GHz et essayons ensuite de stabiliser les fréquences supérieures, en nous limitant à une tension de 1.3V, une valeur qui permet a priori d'utiliser l'overclocking sans craindre pour son CPU. Seuls les curs sont overclockés, nous laissons ici la fréquence Uncore par défaut à 3 GHz mais il faudra également veiller à l'augmenter si vous voulez obtenir les meilleures performances possibles. 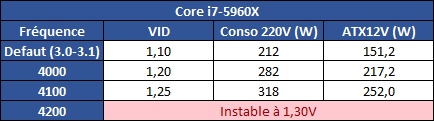 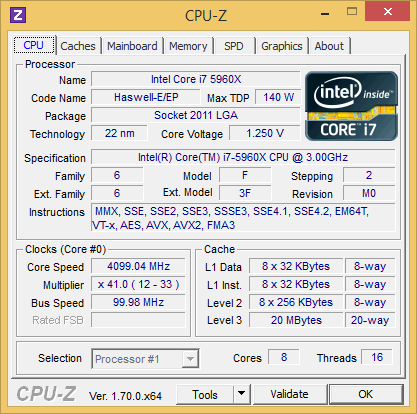 On commence par le Core i7-5960X, qui affiche tout de même près de 151W sur l'ATX12V à son réglage de base. La limite de TDP est atteinte ce qui ne permet pas au processeur d'être à son turbo maximal de 3.3 GHz sur 8 curs, la fréquence varie entre 3.0 et 3.1 GHz. Les 4 GHz ont pu être stabilisés à 1.2V, et il aura fallu 1.25V à 4.1 GHz. Malgré une tension de 1.3V les 4.2 GHz n'étaient pas stables. Au passage, côté température, on atteint environ 60°C par défaut contre 75°C en overclocking, loin de la température maximale fixée à 105°C par Intel. S'il faut rappeler que les conditions sont optimales puisqu'il s'agit d'un test hors boitier, Prime95 charge également nettement plus ces processeurs qu'en usage classique. La taille du die relativement importante ainsi que l'IHS qui est soudé aident à la dissipation de la chaleur produite par ces nouveaux processeurs. 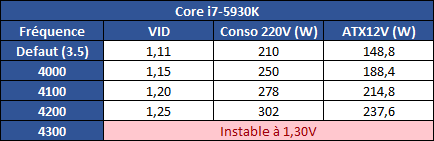 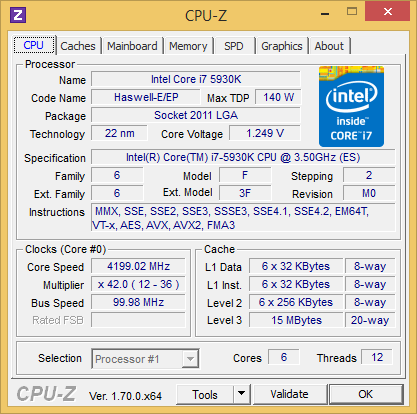 Le Core i7-5930K n'arrive pas non plus à son Turbo maximal sous Prime95, avec 3.5 GHz au lieu de 3.6 GHz. Cette fois nous avons pu atteindre 4 GHz à 1.15V, 4.1 GHz à 1.2V et 4.2 GHz à 1.25V. Les 4.3 GHz n'ont pu être stabilisés. A noter que nous avons pris le temps de voir quelle était la marge pour l'undervolting sur ce processeur, il a pu tenir les 3.5 GHz à 1.05V, mais pas 1.00V. 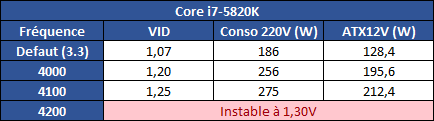  Enfin le Core i7-5820K a obtenu les mêmes couples de fréquence/tension que l'i7-5960X, avec 1.2V à 4 GHz et 1.25V à 4.1 GHz. Bien qu'il soit toujours délicat de tirer des conclusions sur la base d'un nombre de processeur restreints, on trouve tout de même des limites basses sur nos 3 processeurs, avec 4.1 à 4.2 GHz. Si les 4.5 GHz étaient accessibles avec Sandy Bridge-E avec une tension raisonnable, il fallait se contenter de 200 à 300 MHz de moins avec Ivy Bridge-E et Haswell-E ne semble pas faire mieux, voire un peu moins bien. Pour se consoler on peut se dire que vue la fréquence de base relativement réduite de l'i7-5960X, le gain est tout de même non négligeable. Page 7 - Protocole de test Protocole de testNous avons profité de l'été pour remettre à plat notre suite logicielle nous permettant d'évaluer les performances des processeurs. Une mise à jour nécessaire sachant que les fondations du protocole précédent dataient du lancement de l'AMD FX 8150 en octobre 2011, avec une mise à jour en octobre 2012 lors de l'arrivée du FX 8350 ! Nous avons conservé la même philosophie qu'initialement, à savoir une partie applicative avec deux logiciels pour un même usage, et une partie jeu mettant l'accent sur la limitation inhérente au processeur.  Côté 3D, on passe à la version 2015 de 3ds Max. Nous utilisons toujours deux scènes proches fournies par Evermotion, l'une préparée pour le moteur intégré, Mental Ray qui passe en version 3.12, et l'autre pour un auteur moteur de rendu très populaire, V-Ray qui est cette fois en version 3.0. La compilation est toujours de la partie mais nous utilisons cette fois Visual Studio 2013 ainsi que MinGW-w64 avec GCC 4.7.1. C'est cette fois le code source de Blender qui est compilé. La compression de fichier fait désormais la part belle au multithreading, puisqu'en sus de 7-zip 9.2 qui était déjà présent, WinRAR passe en version 5.1 et au RAR5 ce qui lui permet cette fois de vraiment tirer partie des processeurs à plus de 2 curs. Côté encodage vidéo nous passons à une version plus récente de x264 et intégrons à la place de MainConcept H.264, qui a des résultats assez symétriques, le codec x265. Dans les deux cas l'encodage en deux passes, précédemment limité par le serveur d'image Avisynth peu multithreadé, est abandonné au profit d'un encodage en une passe en mode CRF. Le traitement des photos en RAW est également conservé, avec d'une part une mise à jour d'Adobe Photoshop Lightroom qui passe en version 5.5, mais également l'intégration de DxO Pro Optics 9.5. A noter que par défaut Lightroom ne tire guère partie de plus de 3-4 curs, nous contournons cette limitation en lançant deux exports en parallèle. DxO n'a pas cette limitation et charge environ 6 curs avec son réglage par défaut qui traite 2 images en parallèle (chaque traitement étant lui-même multithreadé). Afin de tirer pleinement parti des processeurs à plus de curs nous réglons le logiciel pour utiliser 3 images sur les processeurs 6 curs/thread, 4 sur les 8 curs/thread, etc. Enfin nous terminons ce tour d'horizon applicatif par un type d'application assez particulier, à savoir des algorithmes d'intelligence artificielle destinés aux échecs. Nous abandonnons Fritz Chess Benchmarking qui est somme toute assez simple voir simpliste, mais qui est conservé pour la partie consommation, au profit de Stockfish qui est dans sa version 5 repassé devant Houdini en terme de classement. Ce dernier est conservé mais passe à la version 4. Tous ces tests applicatifs sont effectués les uns à la suite des autres, mais afin de réduire la marge d'erreur sous 1% la suite de test est répétée une seconde fois après un redémarrage. C'est le meilleur des deux scores qui est pris en compte.  Viennent ensuite les tests destinés à évaluer les performances ludiques des processeurs. Pas moins de 8 jeux sont utilisés : - Crysis 3 - Arma III - X-Plane 10 - F1 2013 - Watchs Dogs - Total War : Rome II - Company Of Heroes 2 - Anno 2070 Les tests sont effectués avec un niveau de détail maximal (hors anti aliasing) en 1920*1080, tout en cherchant des scènes assez lourdes qui nous permettent d'être limités en performance par le processeur. Pour Crysis 3, nous utilisons une sauvegarde solo à un endroit particulièrement chargé graphiquement et avançons simplement dans la scène, alors que pour Arma III nous effectuons un survol en hélicoptère. Pour X-Plane 10 nous utilisons une partie du survol du benchmark intégré, et le départ d'un grand prix d'Abu Dhabi pour F1 2013. Le framerate de Watch Dogs est pour sa part mesuré lors d'une course dans une partie assez chargée du jeu, il faut noter que cette fois nous avons trouvé des parties avec des framerate 10 à 20% inférieurs mais le système de sauvegarde automatique nous a empêché de les utiliser de manière très reproductible, tout comme l'environnement changeant. Pour Total War : Rome II nous mesurons simplement le framerate lors de la première scène de jeu du prologue, alors que la partie la plus lourde du benchmark intégré est exploitée pour Company of Heroes 2. Enfin pour Anno 2010 nous chargeons une sauvegarde d'une cité de 220 000 habitants que nous visualisons depuis une vue éloignée. Plus sujets aux variations, les tests jeux sont exécutés trois fois, les uns après les autres. Après un redémarrage ils sont de nouveau lancés trois fois les uns après les autres. La moyenne des 6 scores est utilisée. Enfin nous passons à Windows 8.1, afin entre autre d'avoir la dernière version du scheduler Microsoft. Voici les configurations de test utilisées : - ASUS X99 Deluxe (LGA 2011-v3) - ASUS P9X79 (LGA 2011) - ASUS Z97-A (LGA 1150) - ASUS Sabertooth 990FX R2.0 (AM3+) - 4x4 Go DDR4-2133 13-13-13 (LGA 2011-v3) - 4x4 Go DDR3-1600 9-9-9 (LGA 2011) - 2x4 Go DDR3-1600 9-9-9 (LGA 1150/AM3+) - GeForce GTX 780 Ti - SSD Sandisk Ultra II - Alimentation Corsair AX650 Gold - Windows 8.1 Avec l'important travail de mise en place de notre nouveau protocole, les processeurs intégrés dans ce comparatif sont de fait limités. Ainsi en sus des 3 processeurs LGA 2011-v3 lancés ce jour nous avons intégré les Core i7-4960X et 3970X (les seuls processeurs LGA 2011 à notre disposition à ce jour), ainsi que quelques processeurs Haswell LGA 1150 (i7-4790K, i7-4770K et i5-4670K) et deux processeurs AMD FX AM3+ (FX-9590 et FX-8350). Dans les semaines et les mois à venir nous re-testerons des processeurs afin de disposer d'une base comparative plus large, couvrant notamment des modèles plus anciens. Vous remarquerez que nous nous limitons à la DDR4-2133 sur plate-forme LGA 2011-v3, tout en utilisant des timings un peu moins laxistes que ceux de nombreux kits disponibles. Nous nous limitons à ce mode parce qu'il s'agit de la spécification officielle Intel d'une part, et d'autre part parce que sur les autres plates-formes nous n'utilisons pas forcément la mémoire DDR3 la plus rapide disponible dans le commerce non plus. Au passage, comme nous l'avions indiqué sur notre test de l'i7-4960X, bizarrement l'i7-3970X était plus lent qu'attendu dans certains jeux sur la P9X79 d'ASUS. Le constructeur nous a indiqué que cette baisse était liée à l'arrivée du support d'Ivy Bridge-E, sans plus de détails. Pour en avoir le cur net nous avons retesté l'i7-3970X avec le bios 3501 au lieu du bios 4701, et comme par magie dans les deux jeux problématiques à savoir Arma III et Anno 2070 les performances sont remontées de 12 et 9% environ, avec cette fois des écarts plus cohérents en IVB-E et SNB-E. Les performances de l'i7-3970X sont celles obtenues avec ce bios 3501. Page 8 - Consommation et efficacité énergétique Consommation et efficacité énergétiquePour le test de consommation nous essayons d'utiliser un logiciel qui est pour toutes les architectures assez représentatif de ce que nous obtenons dans les applications en termes de performances et de consommation. Notre choix se porte actuellement sur Fritz Chess Benchmark que vous pouvez télécharger ici, qui a de plus l'avantage de pouvoir facilement fixer le nombre de threads à utiliser.  Les mesures de consommation ne sont donc pas à prendre comme des valeurs maximales absolues mais plutôt typiques d'une charge lourde, puisque des logiciels spécialisés dans le stress processeur tels que Prime95 peuvent consommer 20% à 30% de plus. Nous donnons pour rappel deux types de relevés, la première à la prise 220V via un wattmètre pour la configuration de test dans son intégralité, et la seconde sur l'ATX12V via une pince ampèremétrique. Cette mesure permet d'isoler le gros de la consommation du processeur, mais elle n'est malheureusement pas exactement comparable d'une plate-forme à une autre puisque dans certains cas une petite partie de la consommation du CPU est issue de la prise ATX 24 pins standard. Comme indiqué dans la configuration de test, la configuration intègre une GTX 780 Ti ce qui entraîne environ 13 watts de plus de consommation à la prise. On commence à titre informatif par les performances obtenues sous Fritz Chess Benchmark : Rien à signaler, on notera toutefois que sur ce bench en particulier les gains liés à l'architecture Haswell sont minimes. Et voici maintenant le relevé des consommations : [ATX 12V] [220V] Plusieurs choses sont à noter, la première c'est une relative gourmandise des Core i7 LGA 2011-3 au repos comparés à leurs prédécesseurs sur l'ATX12V, ce qui est confirmé au passage par les mesures de consommations du processeur lui-même. Malgré la carte mère bourrée de fonctionnalité que nous utilisons, la plate-forme est malgré tout au global un peu plus économe au repos qu'auparavant, mais on reste loin des résultats obtenus sur LGA 1150 qui a également une consommation sur l'ATX12V qui pourrait être plus basse. En charge la consommation est par contre nettement en dessous du TDP de 140W qui ne sera atteint qu'avec des logiciels poussant le processeur dans ces derniers retranchements tels que Prime95. On est loin des niveaux enregistrés sur SNB-E, mais au-dessus de ce que permettrait d'obtenir IVB-E sur l'ATX12V et à des niveaux comparables en terme de plate-forme. Le FX-9590 est de loin le processeur le plus gourmand. Passons à l'efficacité énergétique du processeur. Pour ce faire il s'agit de diviser la performance obtenue sous Fritz Chess Benchmark par la consommation du CPU. Seul problème, il n'est pas possible de connaitre exactement celle-ci : la mesure sur l'ATX12V n'est pas 100% comparable d'une plate-forme à une autre, et la mesure à la prise ne permet pas complètement d'isoler tout ceci. Nous avons donc fait le choix d'utiliser deux méthodes de calcul pour isoler la consommation de processeur : - Consommation sur l'ATX12V - 90% du delta de consommation à la prise entre charge et repos Nous utilisons les 90% afin d'exclure le rendement de l'alimentation à proprement parler. Il faut noter que si la première mesure favorise les processeurs tirant une petite partie de leur énergie via la prise ATX classique, la seconde favorise ceux qui ont une consommation élevée au repos. Malheureusement aucune méthode n'est parfaite. [Efficacité ATX 12V] [Efficacité 220V] Sachant que l'efficacité est variable d'un logiciel à l'autre et que les deux calculs peuvent offrir des résultats variables comme évoqué ci-dessus, il s'agit ici de tirer de grandes lignes plus que de faire dans le détail. Au global on note que HSW-E est à un niveau similaire à IVB-E, bien au-dessus de SNB-E grâce à l'apport du 22nm. La plate-forme LGA 1150 est notablement plus efficace en charge légère, mais à un niveau comparable en charge plus lourde. Les processeurs AMD FX sont à la traine. Page 9 - Rendu 3D : Mental Ray et V-Ray 3d studio max 2015 - Mental Ray 3.12  Notre première mesure de performance s'effectue sous 3d Studio Max 2015 en utilisant le moteur de rendu Mental Ray sur une scène d'Evermotion. Le rendu est effectué en 480*300 afin de conserver un temps de test raisonnable, ni trop faible pour ne pas permettre à des mécanismes de Turbo très temporaires d'avoir un impact important, ni trop élevé pour la durée du protocole. Mental Ray apprécie fortement l'architecture Haswell, si bien que malgré 300 MHz de plus (soit + 8,8%) l'i7-4960X est nettement dépassé par un i7-5820K. L'i7-5960X permet de creuser encore l'écart, le logiciel étant capable d'utiliser pleinement les 8 curs. On notera que les 6 curs LGA 2011 étaient dépassés par l'i7-4790K LGA 1150 à 4 curs du fait de son architecture et de sa fréquence. 3d studio max 2015 - V-Ray 3.0 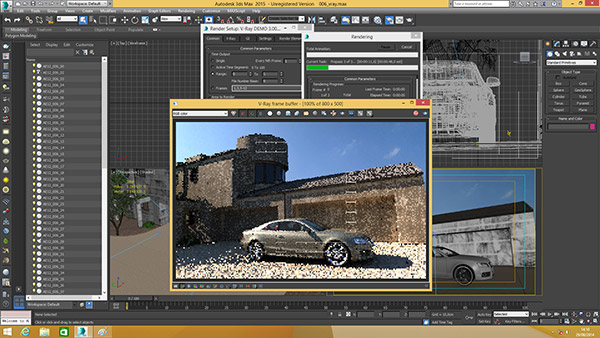 Toujours sous 3d Studio Max 2015, nous changeons cette fois de moteur de rendu pour le moteur tiers le plus populaire, V-Ray 3. On utilise une autre version de la même scène préparée par Evermotion pour ce moteur, le rendu étant cette fois effectué en 800*500. V-Ray est en effet nettement plus rapide pour rendre la scène, mais il ne s'agit pas de comparer les moteurs entre eux puisqu'il faudrait également observer de manière très attentive la qualité des fichiers finaux. Les résultats sous V-Ray sont assez proches avec de nouveau un gain architectural important lié à Haswell combiné à l'apport de 8 curs sur l'i7-5960X. V-Ray tire encore mieux partie des 8 curs ce qui permet à l'i7-5960X d'être 42,1% plus véloce que l'i7-4960X ! Page 10 - Compilation : Visual Studio et MinGW-w64/GCC Visual Studio 2013 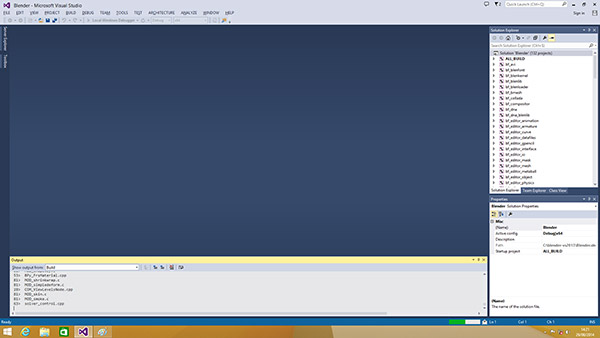 Nous compilons le logiciel d'animation 3D Open Source Blender sous Visual Studio 2013. Nous utilisons le code source de la dernière version stable au moment de la création de notre protocole, à savoir la version 2.71. Le projet est compilé avec les dépendances par défaut. Visual Studio 2013 est capable de compiler des modules non dépendants en parallèle. L'i7-5820K se positionne de nouveau devant l'i7-4960X à la faveur des gains liés à l'architecture Haswell, par contre l'écart creusé par l'i7-5960X par rapport à l'i7-5930K est cette fois moins important. Il faut toutefois rappeler qu'avec leurs configurations par défaut, l'i7-5930K dispose d'une fréquence supérieure d'environ 9% en pratique dans ce test. Les 8 curs font donc plus que compenser cet écart. MinGW-w64 - GCC 4.7.1 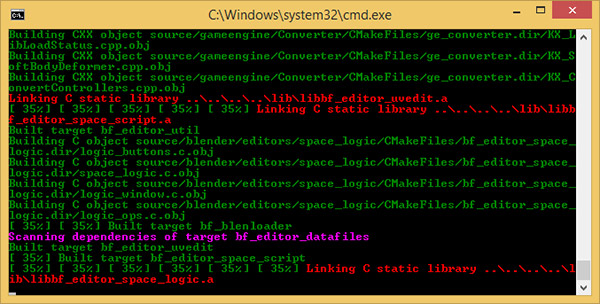 Nous utilisons une fois de plus le même code source de Blender 2.71, cette fois ci compilé sous MinGW-w64 / GCC 4.7.1. Les dépendances sont identiques à celles utilisées pour Visual Studio. Nous forçons la compilation multithread via la commande make. Un grand merci à Guillaume pour l'élaboration de ces deux tests ! De nouveau l'architecture Haswell permet des gains significatifs ce qui permet à l'i7-5820K de dépasser un i7-4960X. Cette fois le gain est plus notable avec le passage à 8 curs ce qui permet à l'i7-5960X de creuser un écart plus important. Page 11 - Compression : WinRAR et 7-Zip WinRAR 5.10 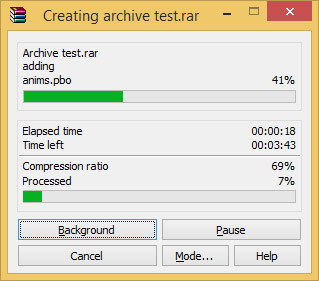 Environ 7,5 Go de fichiers issus d'une version de Arma II avec ses extensions sont compressées à l'aide de WinRAR. Nous utilisons le format de compression RAR5 en mode Ultra. Introduit avec les dernières versions du logiciel, RAR5 permet entre autre de mieux tirer parti du multithreading. Cette fois les choses sont différentes puisque les nouveaux 6 curs ne battent pas les LGA 2011, seul l'i7-5960X prenant les devants. Il faut dire que l'architecture Haswell ne fait pas beaucoup mieux sous WinRAR et que dans le même temps la fréquence plus réduite de l'Uncore augmente entre-autre la latence du cache L3. Combiné à une DDR4 qui n'est pas forcément avantageuse, on arrive à ce résultat final. 7-Zip 9.20  7-Zip est le second logiciel de compression utilisé. Nous utilisons cette fois le mode LZMA2 en compression Ultra, toujours sur une version d'Arma II mais dépourvu cette fois des extensions (3.5 Go) afin de limiter le temps de test. WinRAR est donc plus rapide mais là encore il ne s'agit pas de comparer les logiciels entre eux, ce qui nécessiterait de comparer les tailles des archives obtenues. Sous 7-Zip les mêmes conséquences ont exactement les mêmes effets avec des performances décevantes pour les Haswell-E, exception faite du Core i7-5960X qui bénéficie de l'apport de 2 curs supplémentaires. Page 12 - Encodage : x264 et x265 x264 v2453  Notre premier test d'encodage vidéo est fait sous x264, plus précisément une build compilée sous GCC 4.9.1 par Komisar, avec la compression d'un extrait de Blu-ray d'une minute en 1080p avec un débit moyen de 23 Mbps. C'est ffmpeg qui fait office de serveur d'image, nous utilisons un encodage d'une passe en mode CRF 20 en profil slower, nous tenons à remercier Sagittaire au passage pour ces échanges sur le sujet. La ligne de commande exacte est --preset slower --tune grain --crf 20 --ssim --psnr. x264 profite notablement de l'apport de Haswell ce qui permet à l'i7-5820K de dépasser l'i7-4960X. L'i7-5960X prend le large du fait de la présence de 8 curs avec un gain de 22,7% face à l'i7-5930K et de 32,1% face à l'i7-4960X. x265 v1.2+507  On passe ensuite à x265 qui permet d'encoder des vidéos en H.265, un nouveau format de vidéo très performant puisqu'il promet à qualité équivalente au H.264 un débit divisé par deux mais avec en contrepartie une charge de décodage et d'encodage bien plus lourde. x265 est utilisé dans une version compilée avec GCC 4.9.1 par snayper. C'est de nouveau ffmpeg qui fait office de serveur d'image pour un encodage en CRF 16 cette fois, afin de profiter de l'efficacité accrue de x265 pour gagner en qualité, toujours en profil slower mais en l'adaptant quelque peu afin de réduire l'écart par rapport au profil slow tout en profitant des options psychovisuelles. La ligne de commande exacte est --crf 16 --preset slower --me hex --no-rect --no-amp --rd 4 --aq-mode 2 --aq-strength 0.5 --psy-rd 1.0 --psy-rdoq 0.1 --bframes 3 --min-keyint 1 --ipratio 1.1 --pbratio 1.1 --ssim psnr. x265 ne bénéficie pas autant des apports d'Haswell et cette fois l'i7-5820K est légèrement derrière l'i7-4960X. De plus le gain lié au passage à 8 curs est plus faible avec 14,9% de mieux pour l'i7-5960X face à l'i7-5930K, ce qui est peut être la conséquence d'une maturité moindre du logiciel face à son prédécesseur. Page 13 - Traitement photo : Lightroom et DxO Lightroom 5.5  On passe maintenant au traitement des photos RAW par lot avec pour débuter Lightroom. Nous exportons en JPEG deux lots de 96 photos issues d'un 5D Mark II tout en leur appliquant divers effets, tels que des corrections colorimétriques, d'objectifs ou encore le traitement du bruit. Il faut noter que de base, Lightroom ne tire guère partie de plus de 3-4 curs, ce qui est ici contourné via l'export simultané de deux lots de photos qui permet de gagner un temps significatif. Sous Lightroom l'i7-5930K passe devant l'i7-4960X au contraire de l'i7-5820K qui reste derrière, les gains liés à Haswell ne permettant pas de combler tout l'écart lié à la fréquence. Malgré l'utilisation de 2 exports simultanés le fait de passer de 6 curs / 12 threads à 8 curs / 16 threads n'offre que de très légers gains qui ne compensent même pas le delta de fréquence en défaveur de l'i7-5960X. DxO Optics Pro 9.5  DxO Optics Pro est notre second logiciel de traitement photo. Ce sont cette fois 48 photos issues d'un 5D Mark II qui sont traitées avec notamment de la compensation d'exposition, d'éclairage, de couleurs, la réduction du bruit et les corrections optiques. Nous avons réduit le nombre de photos traitées afin de conserver un temps de test raisonnable, mais là encore il ne s'agit pas de comparer DxO à Lightroom sur la base de la rapidité puisque les effets ne sont pas les mêmes et les fichiers finaux ne sont pas équivalents. A noter que par défaut DxO traite 2 images en parallèle (chaque traitement étant lui-même multithreadé). Afin de tirer pleinement parti des processeurs à plus de curs nous réglons le logiciel pour utiliser 3 images sur les processeurs 6 curs/thread, 4 sur les 8 curs/thread, etc. DxO montre un tout autre visage. D'une part, les gains liés à Haswell sont plus important ce qui permet à l'i7-5820K de se rapprocher de l'i7-4960X, et surtout cette fois l'i7-5960X enregistre un gain de performance et est 15,7% plus véloce que l'i7-5930K. Page 14 - IA d'échecs : Stockfish et Fritz Stockfish 5  Enfin nous terminons ce tour d'horizon applicatif par un type d'application assez particulier, à savoir des algorithmes d'intelligence artificielle destiné aux échecs. On commence par Stockfish 5, un moteur open source qui vient de détrôner Houdini qui était considéré jusqu'alors comme le plus efficace. Stockfish est compilé avec GCC 4.8 et dispose de trois versions, une classique, une SSE4 permettant un gain de 3% environ sur processeurs Intel et AMD et une version utilisant les instructions BMI des Haswell qui permet de gagner encore 2%. La version la plus rapide est utilisée. Nous laissons tourner le moteur jusqu'au 31è tour en début de partie et notons la vitesse exprimée en Kilonoeuds par secondes. Sous Stockfish les gains liés à Haswell permettent à l'i7-5820K de passer devant l'i7-4960X, alors que l'i7-5960X profite d'un gain de 20,9% face à l'i7-5930K grâce à ses 8 curs. Houdini 4 Pro  L'autre moteur d'échec utilisé est Houdini dans sa version 4. Il dispose lui aussi de deux exécutables, l'un étant plus rapide sur processeur AMD et l'autre plus rapide sur processeur Intel. La version la plus rapide est utilisée. Nous laissons tourner le moteur jusqu'au 27è tour en début de partie et notons la vitesse exprimée en Kilonoeuds par secondes. Houdini 4 est le logiciel qui profite le plus du passage à Haswell. Ainsi, malgré un déficit de fréquence de 3% environ, l'i7-5930K est 19% plus véloce qu'un i7-4960X. L'i7-5960X et ses 8 curs permettent d'obtenir au final un gain de 39,5% face à la génération précédente. Page 15 - Jeux 3D : Crysis 3 et Arma III Crysis 3  Crysis 3 inaugure la partie jeux 3D de ce comparatif. Nous utilisons une sauvegarde sur une zone particulièrement chargée du jeu dans laquelle nous avançons pendant 20s afin d'avoir un framerate moyen. Les tests sont effectués en 1920*1080 Very High, sans anti-aliasing. Sur des parties lourdes avec beaucoup de végétation comme la scène de test utilisée, Crysis 3 arrive à assez bien exploiter plus de 4 curs ce qui permet aux Core i7 6 curs de prendre une avance nette sur les Core i7 LGA 1150. Les Haswell-E enfoncent encore le clou avec un net gain face à leur prédécesseurs, par contre on ne note pas d'écart entre les différentes versions. Il ne s'agit pas a priori d'une limite GPU, l'abaissement de la résolution n'y changeant rien. Arma III  Pour Arma III nous chargeons une sauvegarde lors d'un entrainement en hélicoptère dans laquelle nous survolons pendant 20s l'ile de Stratis. Les tests sont effectués en 1920*1080 Ultra, sans anti-aliasing. Au contraire Arma III n'est que peu dépendant du nombre de curs. Du fait des gains liés à l'architecture Haswell, les Haswell-E arrivent tout de même devant leurs prédécesseurs, mais la version 8 curs est moins rapide que les versions 6 curs du fait du déficit de fréquence. Un "simple" i5-4670K est plus rapide. Page 16 - Jeux 3D : X-Plane 10 et F1 2013 X-Plane 10  X-Plane 10 est autant un jeu qu'un logiciel de simulation de vol. Nous utilisons 20s du benchmark intégré qui est un replay d'une approche d'un survol en basse altitude d'une ville et d'un aéroport avec les options fps 3 qui correspondent à un niveau de détail très élevé, en 1920*1080 sans anti-aliasing. Il faut noter que X-Plane n'aime pas du tout l'Hyperthreading, avec des performances en hausse de 15 à 20% lorsque celui-ci est désactivé et assez variables entre les benchmarks, probablement du fait d'une répartition peu optimale des threads sur les curs logiques. Vu cet écart important nous reportons ici les valeurs avec Hyperthreading désactivé. L'écart est cette fois encore plus grand en faveur des processeurs LGA 1150 classiques sous ce jeu qui semble d'une part tirer pleinement profit du passage à Haswell tout en ne tirant pas de bénéfice de la présence d'un nombre important de curs. F1 2013  F1 2013 est notre quatrième jeu, nous utilisons le benchmark intégré qui est modifié afin d'avoir un départ du GP d'Abu Dhabi sous un temps pluvieux. Nous mesurons le framerate moyen durant les 20 premières secondes du départ, en 1920*1080 Ultra sans anti-aliasing. F1 2013 perd un peu en performances du fait de l'Hyperthreading, d'où la position de l'i7-4770K face à l'i5-4670K, mais l'écart étant assez faible nous reportons les valeurs avec HT actif cette fois. Le jeu tire légèrement parti de la présence de plus de 4 curs, ce qui explique un meilleur positionnement des Core i7 LGA 2011 et 2011-3. L'i7-5960X se permet même, malgré une fréquence moindre, d'être devant l'i7-5930K bien que l'écart ne soit pas exceptionnel. Page 17 - Jeux 3D : Watch Dogs et Total War : Rome 2 Watch Dogs  Le framerate de Watch Dogs est pour sa part mesuré lors d'une course de 20s dans une partie assez chargée du jeu. Nous avons trouvé des scènes avec des framerate 10 à 20% inférieurs mais le système de sauvegarde automatique nous a empêché de les utiliser de manière très reproductible, tout comme l'environnement changeant. Les performances sont mesurées en 1920*1080 avec un niveau de qualité générale à Ultra mais sans anti-aliasing. Watch Dogs permet d'exploiter plus de 4 curs et les processeurs six curs peuvent donc faire concurrence à l'i7-4790K malgré des fréquences moindres. Les 8 curs ne semblent par contre pas bénéfiques, d'où un framerate en baisse sur l'i7-5960X face à l'i7-5930K du fait de la fréquence. Total War : Rome II  Pour Total War : Rome II nous mesurons simplement le framerate lors de la première scène de jeu du prologue, en 1920*1080 Extreme mais en désactivant l'AA et le SSAO. Cette fois le fait d'aller au-delà de 4 curs n'est pas vraiment utile et c'est donc le Core i7-4790K qui l'emporte avec une avance notable sur les processeurs Intel 6 et 8 curs. Logiquement l'i7-5960X est un peu derrière l'i7-5930K, mais il faut tout de même mieux que l'i7-5820K. Page 18 - Jeux 3D : Company of Heroes 2 et Anno 2070 Company of Heroes 2  Pour Company of Heroes 2 nous utilisons les 20 dernières secondes du benchmark intégré pour obtenir un framerate moyen en 1920*1080 et qualité maximale exception faite de l'anti-aliasing. CoH 2 ne tire pas vraiment partie de plus de 4 curs, si bien que les performances sont très resserrées entre un i5-4670K et un i7-5960X. C'est du coup l'i7-4790K qui profite de sa fréquence pour prendre le large. Anno 2070  Enfin pour Anno 2070 nous chargeons une sauvegarde d'une cité de 220 000 habitants que nous visualisons pendant 20s depuis une vue éloignée, le tout en 1920*1080 avec réglages très élevés et toujours sans anti-aliasing. Dernier jeu de notre suite de test, Anno 2070 n'aime pas l'Hyperthreading dès lors qu'il est présent sur un processeur qui dispose de plus de 4 curs. Le fait de le désactiver permet en effet de gagner 12% de performances environ sur 6 curs, et carrément 30% avec un 8 curs, signe d'un positionnement des thread probablement forcé par le jeu et assez mal fait. Du fait de cet écart important sur les processeurs 6 et 8 curs l'Hyperthreading est désactivé pour ce test. Comme beaucoup des autres jeux la présence de plus de 4 curs n'influence pas beaucoup les perfs d'Anno 2070 qui fait du coup la part belle à l'i7-4790K alors que les autres i7 se tiennent dans un mouchoir de poche. Page 19 - Indices de performance Indices de performancePassons maintenant aux moyennes. Bien que les résultats de chaque application aient tous un intérêt, nous avons calculé des indices de performances en nous basant sur l'ensemble de résultats et en donnant le même poids à chacun des tests. Nous présentons deux moyennes, l'une applicative intègre tous les tests en dehors des jeux 3D et l'autre est spécifique aux jeux 3D qui sont généralement moins multithreadés. En applicatif les résultats de ces nouveaux processeurs LGA 2011-3 sont probants. D'une part, l'arrivée de l'architecture Haswell permet des gains notables face à la génération précédente, ainsi l'i7-5930K est en moyenne 6,4% et 10,6% plus véloce que les i7-4960X et i7-3970X malgré un déficit de fréquence de 2,8%. L'i7-5960X permet de plus d'enfoncer le clou puisqu'il est 17,3% et 22,4% plus véloce que les i7-5930K et i7-5820K alors que ces derniers bénéficient de fréquences 5,9 et 3% supérieures. Le nouveau Extreme Edition est au final 24,8% plus véloce que son prédécesseur. Ces gains permettent à la plate-forme Intel haut de gamme de reprendre un peu du poil de la bête alors que les processeurs LGA 2011 voyaient dangereusement se rapprocher les Core i7 LGA 1150 qui profitaient jusqu'alors en exclusivité de l'architecture Haswell. Vous noterez enfin qu'à la faveur du nouveau protocole qui est entre autre plus multithreadé qu'auparavant (via les modifications sous WinRAR et Lightroom), l'AMD FX-8350 creuse l'écart sur l'i5-4670K puisqu'il est désormais environ 15,2% plus véloce contre 3,7% auparavant. Dans les jeux 3D les résultats sont bien différents puisqu'en moyenne les nouveaux arrivants ne permettent pas de faire mieux que le haut de gamme LGA 1150 que constitue l'i7-4790K. On est toutefois au-dessus d'un i7-4770K, mais les 8 curs n'apportent rien en pratique et les 6 curs pas beaucoup plus à l'exception notable de Crysis 3. Les gains liés à Haswell sont malgré tout là puisque le Core i7-5930K est 6,9% et 9,3% plus véloce que les i7-4960X et 3970X malgré une fréquence inférieure de 2,8%. On notera que le nouveau protocole permet également au FX-8350 de voir sa note grimper face à l'i5-4670K puisque le processeur Intel n'est désormais "que" 26,1% plus rapide contre 42,2% auparavant, un pourcentage qui varie beaucoup selon les jeux. A noter que nous n'avons pas encore pu intégrer une plate-forme plus ancienne avec par exemple un Core i7-990X, sachez toutefois que l'écart entre i7-990X et i7-3970X est de l'ordre de 15%. Page 20 - Conclusion ConclusionAvec le LGA 2011-v3 et son chipset X99 Express, Intel remet au gout du jour une plate-forme haut de gamme qui en avait besoin. Cette dernière bénéficie désormais d'avancées notables en matière d'E/S avec la présence de pas moins de 10 ports SATA 6 Gbps et la gestion native de l'USB 3 qui faisait défaut au X79, tout en conservant les avantages de la plate-forme avec la gestion d'un volume important de mémoire (64 Go, et même 128 Go lorsque les barrettes 16 Go arriveront) et de nombreuses lignes PCIe (sauf sur l'i7-5820K !).  Mais au-delà de la plate-forme c'est bien entendu les performances des nouveaux processeurs Haswell-E qui nous intéressent le plus. A fréquence égale, le gain est de l'ordre de 8-9% par rapport au IVB-E et de 11-12% face à SNB-E, soit des niveaux assez attendus. Mais c'est surtout via l'arrivée (enfin !) d'une version 8 curs, l'i7-5960X, que le gros du gain de performance se fait face à la génération précédente. Malgré une fréquence contenue afin de ne pas faire exploser le TDP, ce dernier s'avère au final être 25% plus véloce que son prédécesseur i7-4960X en applicatif, bien loin devant le FX-9590 d'AMD avec un avantage de 55%. Seul problème ce processeur de gamme X est, comme d'habitude, affiché au tarif mirobolant de 999$. Certes, la présence de 8 curs justifie plus ce tarif que celui de l'i7-4960X par le passé, mais cela n'en reste pas moins très cher à la vue du gain de performances obtenu. Il ne faut de plus pas perdre de vue que si en applicatif les 8 curs peuvent être utiles, c'est loin d'être le cas dans les jeux si bien qu'un i7-4790K sera plus véloce et un i5-4690K pas forcément très éloigné. Il faut toutefois préciser que si la fréquence que nous avons obtenue en overclocking, 4.1 GHz, parait assez faible au premier abord, cela représente un surplus de 24% par rapport au Turbo 8 curs ce qui n'est pas négligeable et qui permettra à l'i7-5960X d'exprimer pleinement son potentiel. L'i7-5930K n'a pas cet avantage et n'en a en fait pas beaucoup d'autres sur le papier du fait de l'arrivée de l'i7-5820K qui a notre préférence. Alors que les i7-3820 et i7-4820K étaient dôtés de 4 curs, cette fois Intel a eu la bonne idée de proposer un processeur LGA 2011-v3 "d'entrée de gamme" à 6 curs. Il est du coup nettement moins cher que le 5930K, 389$ contre 583$ (et 339$ pour un i7-4790K), et ne se distingue que par une fréquence inférieure de 200 MHz et un bridage au niveau des lignes PCIe, une invention dont on se serait bien passé mais qui n'aura généralement pas d'impact. Malheureusement au-delà du coût du processeur, la plate-forme LGA 2011-v3 entraine d'autres surcoûts par rapport au LGA 1150 plus classique. On pense bien entendu aux cartes mères, qui sont environ 100 plus onéreuses, mais aussi à la mémoire DDR4 pour laquelle le surcoût est encore une fois de l'ordre de 100 pour 16 Go. On notera au passage que, c'est une habitude à chaque lancement de nouveau type de mémoire, la DDR4 nous a globalement déçu même si il faut bien dire qu'elle n'est pas complètement fautive puisque bridée par le contrôleur mémoire en quad channel. Reste qu'avec des latences en hausse il faut viser les kits les plus rapides, en DDR4-3000, pour arriver au niveau de la DDR3-2133. Au final l'intérêt du LGA 2011-v3 dépendra bien entendu de vos besoins, de votre budget mais aussi de votre configuration actuelle. Il faudra ainsi avoir besoin de hautes performances lors de charges fortement multithreadés ou des bénéfices de la plate-forme en terme de mémoire ou de PCIe, sans pour autant en bénéficier déjà au travers d'une plate-forme LGA 2011 hexacore auquel cas l'upgrade est, en dehors de la simple envie de changer de machine, peu justifiable. Bien entendu le passage à l'octocore a un impact significatif sur les performances mais bien qu'alléchant il est loin d'être raisonnable du point de vue tarifaire, ce qui réduit l'intérêt global de la plate-forme LGA 2011-v3. Un point qui on l'espère sera résolu lorsqu'elle accueillera l'an prochain les Broadwell-E en 14nm ! Copyright © 1997-2024 HardWare.fr. Tous droits réservés. |
{kind=link}