| |
| |
| L'architecture AMD Bulldozer Processeurs Publié le Vendredi 13 Mai 2011 par Franck Delattre URL: /articles/833-1/architecture-amd-bulldozer.html Page 1 - Introduction  AMD prépare son retour sur le marché du x86. L'architecture K10, bien qu'encore performante, montre ses limites face à la concurrence, en particulier face au Sandy Bridge dont l'efficacité brille sur les plateformes de bureau haut de gamme. Pour sa nouvelle gamme de processeurs, AMD a investi dans le développement de deux nouvelles micro-architectures : Bobcat et Bulldozer. Si Bobcat vise le marché occupé par l'Atom, c'est-à-dire celui des plateformes ultra-basse consommation, Bulldozer est davantage destiné aux plateformes serveur et de bureau haut de gamme. Bulldozer représente la première véritable nouvelle architecture pensée par AMD depuis 2003. La principale nouveauté de l'architecture réside dans la technologie CMT, pour Cluster Multi- Threading, qui constitue une nouvelle approche dans le compromis entre la consommation d'énergie et la performance dans le traitement multi-threads, et que nous verrons en détail dans ce dossier. AMD a également porté ses efforts sur certains points particulièrement critiques pour la bonne performance d'un microprocesseur moderne, et pour lesquels l'architecture K10 présentait quelques lacunes. Ainsi Bulldozer se voit désormais doté d'une prédiction de branchement digne de ce nom, et rejoint en ce sens les efforts menés par Intel sur ses dernières architectures. AMD prétend ainsi proposer une alternative sérieuse aux meilleurs processeurs Intel, en mettant en avant des choix technologiques originaux. Une architecture qui mise sur le partage des ressources et les hautes fréquences !  Après l'échec du Netburst qui a été dessinée dans l'optique de fournir la performance par une fréquence élevée, on pensait que les constructeurs bouderaient pour quelques temps les architectures destinées à monter en MHz. Chez AMD, K8 et K10 sont des architectures à IPC élevé (instructions par cycle), et ont fourni des performances brutes bien supérieures à ce que Netburst pouvait offrir à la même époque. Avec Bulldozer, AMD change de stratégie. Comme nous le verrons plus loin dans cet article, à nombre de cores égaux, la puissance brute de traitement du Bulldozer est en retrait par rapport à celle de l'architecture K10. Beaucoup des spécificités du K15 sont celles d'une architecture destinée à tourner à des fréquences élevées : un pipeline de traitement découpé en de nombreuses étapes, une prédiction de branchement améliorée (car critique pour l'efficacité d'une telle architecture), une architecture de caches mixant des L1 de petite taille et à faible latence avec de gros caches de niveau supérieur, et bien entendu une gestion pointue de la dissipation thermique. Cela mis à part, la grande nouveauté de Bulldozer consiste en un design très original qui mélange des ressources dédiées et des ressources partagées entre les cores, et qui porte l'acronyme de CMT (Cluster Multi-Threading). Partager les ressources matérielles signifie économiser des transistors, donc de la surface sur la puce, et donc de la puissance dissipée, tout en s'efforçant de maintenir un niveau de performance proche de celui fourni par des ressources entièrement dédiées. AMD espère ainsi concilier une gestion efficace du multi-thread avec une performance par watt consommé élevée. Page 2 - CMT technology (Cluster Multi-threading) CMT technology (Cluster Multi-threading)Bulldozer chamboule quelque peu la définition de core, telle qu'elle est implémentée sur les architectures x86 actuelles. La nouvelle architecture d'AMD repose sur une « brique » de base appelée module et qui regroupe deux cores. Au sein du module, les deux cores partagent un certain nombre de leurs composants : - l'étage « front-end » qui regroupe l'unité de fetch (chargement) et de décodage des instructions, ainsi que le cache L1 d'instructions qui est alimenté par ces unités ; 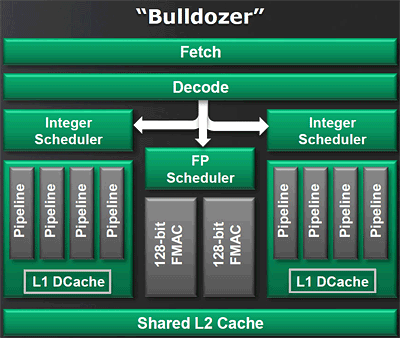 Si le partage d'un cache L2 entre les cores n'est pas une nouveauté, il en va différemment de celui d'unités jusque là propres à chaque core. Le choix des unités partagées semble judicieux : les unités qui composent le front-end sont complexes et consomment beaucoup de transistors et d'énergie. N'en utiliser qu'une seule partagée permet de réduire ces deux effets. Quant à la FPU, elle est couramment sollicitée à un taux inférieur à 50%, ce qui rend pertinent son partage par deux cores. Au final, un module est beaucoup moins gros et consommateur d'énergie que deux cores complets, tout en maintenant un niveau de performance proche. AMD avance les chiffres de 50% d'économie en surface sur la puce pour 80% des performances de deux cores complets. Un processeur « Bulldozer » sera donc composé de plusieurs de ces modules, d'un contrôleur mémoire, d'un contrôleur de bus, et pour certains modèles d'un cache L3. Le discours commercial d'AMD ne portera pas sur les modules mais bien sur le nombre de cores. Ainsi, la version 8-cores de Bulldozer sera composée de 4 modules, et Windows y verra 8 unités logiques. Si on y regarde de près, on peut voir le module Bulldozer comme un « super core » 4-way, partiellement coupé en deux, et ce afin de traiter deux threads en parallèle. La voie suivie par AMD se distingue nettement de celle prise par Intel qui a préféré conserver des « super cores » 4-way hyper-threadés (SMT). Difficile de dire quelle méthode est la meilleure, et cela dépend certainement du type d'application. SMT présente l'avantage d'une grande modularité (un seul thread peut bénéficier de 100% des performances du core), et permet une utilisation optimale du moteur OOO. CMT opère un partage plus marqué des ressources pour chaque thread, et marque ainsi le pas en terme de modularité. AMD note qu'un thread tournant seul sur un module bénéficie de la totalité des ressources partagées certes, mais la moitié des ressources dédiées reste inexploitée. Page 3 - Front-end, OOO, unités de calcul L'unité front-end 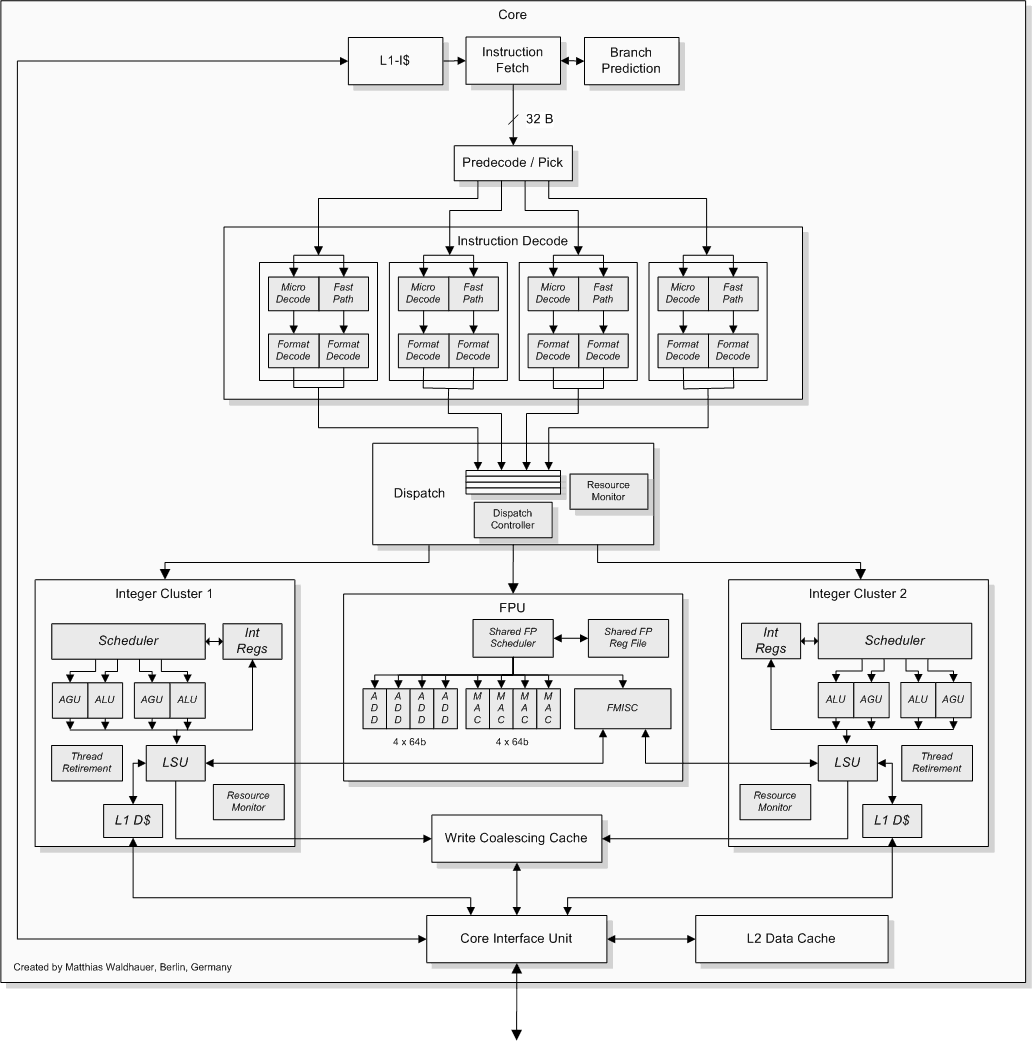 Crédit : Dresdenboy L'unité front-end est responsable de l'alimentation en instruction du reste du pipeline de traitement. Son rôle est donc essentiel dans les performances, car les capacités de traitement ne peuvent être pleinement exploitées que lorsque le flux d'instructions est élevé et constant. Le front-end du module de base du Bulldozer doit être capable d'alimenter non plus un mais deux cores en instructions, on comprend dès lors le rôle clé que cette unité occupe dans la nouvelle architecture d'AMD. Les branchements, ou sauts dans le code, sont le principal casseur de flux d'instructions, c'est pourquoi les architectures modernes ont recours à la prédiction de branchements. Plusieurs mécanismes complémentaires sont couramment utilisés afin d'obtenir une efficacité maximale. Bulldozer n'échappe pas à la règle et reprend la plupart des mécanismes que l'on trouve sur Nehalem ! : un détecteur de boucles, une gestion des branches directes et indirectes, ainsi qu'un mécanisme de prédiction hybride qui gère les branches selon leur localité (portée locale ou globale) ; pour finir, un mécanisme dédié au stockage des adresses de retour (à la différence des BTB Branch Target Buffer - qui stockent les adresses de destination). AMD évoque également la présence d'un trace-cache (un cache contenant des micro-instructions déjà décodées), permettant de diminuer les pénalités en cas d'erreur de prédiction de branchement. A noter qu'on retrouve la présence d'un tel cache dans le détecteur de boucles du Nehalem. Le module Bulldozer intègre un unique cache L1 d'instructions de 64Ko. Celui-ci est associatif à deux voies, soit une voie pour chaque core. L'unité de décodage de Bulldozer a été élargie par rapport à celle du K10, et ce dans l'optique de répondre aux besoins de deux cores. Un module Bulldozer peut ainsi décoder jusqu'à 4 instructions par cycle, soit une de plus que le K10. Présent depuis le Core 2 chez Intel, le mécanisme de fusion fait son apparition pour la première fois sur un processeur AMD. A titre de rappel, la fusion consiste en le décodage de certains couples d'instructions comme une seule instruction, en l'occurrence pour le Bulldozer les couples composés d'une instruction de comparaison ou de test suivie d'une instruction de saut (on parle de fusion de branche). Ainsi, quand une telle occurrence se produit, le module peut décoder jusqu'à 5 instructions par cycle. Moteur OOO et unités de calculLors de notre étude de l'architecture Sandy Bridge, nous avions évoqué le changement que constituait l'utilisation d'un fichier de registres physiques (PRF). A titre de rappel, le fichier de registres physiques consiste en une table de registres de travail utilisés par le moteur d'exécution out-of-order (OOO), vers laquelle pointent les entrées du buffer de réordonnancement (ROB). Ce mécanisme de pointage permet un ROB de taille plus importante en comparaison à un système où le ROB contient lui-même les données des micro-opérations. Bulldozer utilise également un fichier de registres physiques, et tout comme pour Sandy Bridge, la motivation de ce choix tient dans la taille des opérandes du jeu d'instructions AVX. Chacune des deux unités d'exécution x86 du module Bulldozer est composé de deux ALUs (unités arithmétiques et logiques) ainsi que de deux AGUs (unités de génération d'adresse). Là où l'architecture K10 offre trois ALUs, pour un débit maximum de 3 instructions exécutées par cycle, le module Bulldozer offre un débit maximal de 2 x 2 instructions entières par cycle. La performance brute entière théorique d'un module Bulldozer est donc égale à 2 x 2 / 3 x 3 = 67% de celle d'un K10 double core. Cela étant, il s'agit du cas théorique le plus défavorable au Bulldozer par rapport au K10 et AMD indique que l'IPC devrait être amélioré en pratique. De plus, il faut garder à l'esprit que l'intérêt du module ne tient pas tant dans la performance pure, mais dans le rapport entre la performance et la puissance consommée, et à ce titre un module de Bulldozer devrait se montrer beaucoup plus efficace que deux cores K10. L'unité de calcul flottant est une des ressources partagées par les deux cores du module Bulldozer. Elle consiste en deux pipelines de traitement de type FMAC 128-bits (fused multiply accumulate), ce qui signifie que les unités sont capables d'effectuer directement une opération de produit scalaire (que l'on trouve couramment dans les traitements graphiques et les moteurs géométriques). Outre le gain de performance, l'intérêt réside dans la précision de calcul : aucun arrondi n'est effectué entre les deux opérations (multiplication et addition), ce qui garantit une précision de calcul maximale. Ces deux unités peuvent être unifiées en une unité 256-bits pour le traitement des instructions AVX. A noter que la FPU du Bulldozer semble être capable de tourner en mode « économie d'énergie », en n'opérant pas sur tous les bits des opérandes. Page 4 - Le sous-système mémoire Les cachesNous avons vu précédemment que le module Bulldozer comporte un cache d'instructions L1 commun aux deux cores. Celui-ci a une taille de 64 Ko, et est associatif à deux voies (une voie par core). Chacun des deux cores du module Bulldozer possède son propre cache L1 de données, d'une taille de 16 Ko, et associatif à 4 voies. AMD a beaucoup travaillé sur la performance de ces L1D, condition essentielle dans la performance optimale d'une architcture haute fréquence (on se rappelle du Pentium 4 Northwood dont le L1D affichait une latence record de 2 cycles). AMD a eu recours au mécanisme de replay, déjà utilisé par Intel sur le Pentium 4. Le replay, logic-track, re-execute est une technique de prédiction qui permet de spéculer sur la voie du cache où se trouve la donnée requise. En cas d'échec, c'est-à-dire si la donnée pré-extraite est mauvaise, seules les instructions concernées sont exécutées à nouveau. La latence du L1D du Bulldozer devrait ainsi tourner autour de 4 cycles. Toujours au niveau du module, un cache L2 de 2 Mo associatif à 16 voies est partagé par les deux cores. Pour finir, certaines implémentations de Bulldozer utiliseront un cache L3 partagé entre les modules qui constituent le processeur. Ce L3 pourra atteindre 8 Mo, avec une associativité à 64 voies. Les relations qui lient les niveaux de caches du Bulldozer évoluent par rapport aux architectures précédentes. En effet, traditionnellement, AMD utilise des relations de type exclusives entre les niveaux de cache, c'est-à-dire que deux niveaux de caches successifs ne contiennent pas les mêmes données (le L2 par exemple contient les données qui ont été évincées du L1). Pour comprendre ce qui change avec Bulldozer, il faut se pencher sur la politique de mise à jour des données dans les caches. Les L1D de Bulldozer utilisent une politique de mise à jour des données de type write-through (WT), c'est-à-dire que lorsque la donnée est modifiée localement, la nouvelle valeur est mise à jour dans le L1D et dans le L2. La conséquence immédiate est alors la relation inclusive des deux caches : une donnée copiée dans le L1D l'est aussi dans le L2. On peut se demander la motivation du choix d'une politique write-through, qui se montre moins performante que la méthode write-back (WB) dans laquelle la donnée n'est copiée dans le L2 que lorsque la ligne est invalidée dans le L1, ce qui permet de différer une partie des écritures. La raison du choix du mode WT, dans le cas du Bulldozer, est de réduire la pénalité en cas d'échec de cache. En effet, dans ce cas, une ligne du L1 est évincée, et une relation WB déclencherait l'écriture dans le L2. En mode WT au contraire, l'écriture a déjà eu lieu lors de la copie de la donnée dans le L1, et aucune opération n'est donc nécessaire. De plus, la politique WT garantit des données identiques entre les niveaux de cache, ce qui, dans un contexte de partage du L2, simplifie le maintien de la cohérence. La politique WT présente toutefois l'inconvénient de multiplier les écritures dans le cache L2, ce qui consomme beaucoup de sa bande passante. Pour pallier au problème, AMD a intégré dans le L2 un petit cache destiné à recevoir les écritures du L1D et appelé WCC (write coalescing cache, ou cache d'écritures communes). Le WCC reçoit les écritures successives, et une fois plein envoie les données dans le L2, qui ne reçoit alors plus qu'une seule écriture. Le cache L3 est décrit par AMD comme étant de type « cache victime à relation non-inclusive ». Victime, car les données du L3 sont les données qui ont été évincées du L2. En cas de succès de lecture dans le L3, la donnée est remontée dans le L1D du core concerné. A ce stade, il est important de noter qu'une donnée présente dans le L1D n'est pas forcément présente dans le L2 , et donc la relation entre les caches n'est pas 100% inclusive. Et alors ? Eh bien une relation de caches non intégralement inclusive ne permet pas d'affirmer qu'une donnée qui n'est pas dans le L2 ne se trouve pas dans un des L1D, et le maintien de la cohérence nécessite alors de vérifier les caches L1D de chaque core, ce que l'on appelle « cache snooping » et dont nous avons déjà parlé lors de l'étude du Nehalem. Cette étape de maintien de la cohérence est une forte source de ralentissement, et c'est l'un des défauts majeurs du sous-système de caches du K10, défaut d'autant plus pénalisant que le nombre de cores est élevé. AMD n'a pas dévoilé si le Bulldozer intégrait une parade à ce problème. Le contrôleur mémoire intégréLe contrôleur mémoire intégré dans les variantes desktop de Bulldozer supporte la DDR3-1866 (soit 933 MHz réels, ou PC3-15000) sur deux canaux 64 bits, alors que les Phenom II étaient officiellement limités à la DDR3-1333. Les modèles serveurs sont quant à eux capables de gérer quatre canaux de DDR3-1600. A noter que le contrôleur intègre un prefetcher de données, c'est-à-dire un mécanisme de préchargement des données, qui ne remonte pas les données dans les caches du processeur mais possède son propre buffer de stockage. Page 5 - Instructions, gestion d'énergie Jeux d'instructionsBulldozer supporte 100% des jeux d'instructions x86 actuels, y compris l'AVX (Advanced Vector Extension), inauguré par Intel sur son Sandy Bridge. A titre de rappel, AVX est un jeu d'instructions SIMD oprant sur des nombres flottants et dont les opérandes peuvent atteindre 256 bits. Un des atouts de ce nouveau jeu d'instructions réside dans l'existence d'instructions destinées à faciliter la mise en forme des données dans les registres 256 bits, facilitant ainsi le travail des développeurs. Bulldozer propose quelques instructions propres, regroupées sous les noms de XOP, FMA4, et CVT16. Ces jeux d'instructions correspondent en réalité au SSE5 (annoncé par AMD en 2007 mais jamais implémenté) adapté au format AVX. XOP opère principalement sur des opérandes entières, FMA4 sur les flottants 128-bits, et CVT16 regroupe des instructions de conversion de flottants haute précision en flottants de moyenne et basse précision. A noter qu'AMD a été forcé d'utiliser un codage de ses instructions propres différent de celui d'Intel, afin d'éviter toute interférence avec une future extension de l'AVX. Reste à espérer pour AMD que les compilateurs adopteront cette spécificité, sans quoi personne n'utilisera ces instructions. Gestion d'énergieComme nous l'avons vu, l'architecture du Bulldozer repose sur un module qui est étudié pour fournir 80% de la performance de deux cores pour une consommation deux fois moindre. A ce titre, Bulldozer peut être qualifié d'architecture économe en énergie. Mais elle intègre également son lot de mécanismes destinés à baisser la consommation d'énergie du processeur en utilisation courante. En plus du PowerNow! (l'équivalent du SpeedStep d'Intel) qui opère sur le processeur dans sa globalité, Bulldozer intègre des mécanismes de granularité inférieure, c'est-à-dire qui agissent au niveau des unités. Outre le fait que certaines unités peuvent être mises en veille, certaines fonctionnalités se révèlent intéressantes, notamment un mode de calcul de la FPU « basse consommation » (donc basse précision). Les caches peuvent être également mis en veille, et pour les plus gros (L3 notamment) la veille ne peut concerner que certains secteurs. Un mécanisme qui existe depuis le Pentium M chez Intel ! 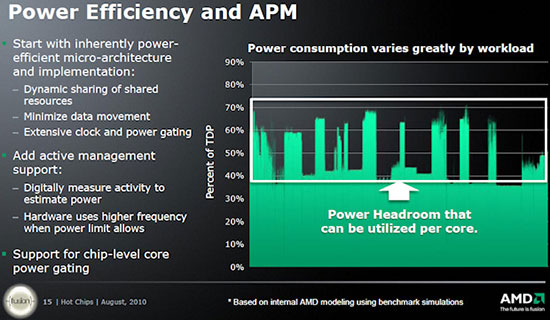 A noter que certaines implémentations de Bulldozer incluent un mode Turbo, asservit sur la puissance consommée qui est évaluée à chaque instant par le processeur. Page 6 - Conclusion Les premiers modèles de Bulldozer en quelques chiffres La première implémentation de l'architecture Bulldozer sur plateforme bureautique est la série FX, nom de code Zambezi. Voyons ses caractéristiques principales connues, ou estimées (fréquences). Attention elles pourront varier d'ici au lancement et ne sont données qu'à titre indicatif : - disponible en 4 (FX-4110), 6 (FX-6110) et 8 (FX-8110 et FX-8130P) cores, soit respectivement 2, 3 et 4 modules ;La rétrocompatibilité avec le Socket AM3 a fait grand bruit, et officiellement la position d'AMD est que le fonctionnement des CPU AM3+ n'est garanti que sur les cartes mères AM3+. Cela n'a toutefois pas empêché des constructeurs tels que ASUS ou MSI d'annoncer des listes de cartes AM3 compatibles avec les processeurs AM3+, ce qui ravira ceux qui les possèdent. AMD précise toutefois que toutes les fonctionnalités de Bulldozer, notamment dans le domaine de la gestion de l'énergie, ne seront pas supportés sur ces cartes, sans plus de précisions. D'ores et déjà, des cartes mères AM3+ à base de chipset AMD 800 sont disponibles chez Gigabyte et ASRock. ASUS et MSI, fort de leurs cartes mères AM3 compatibles, attendront pour leur part la sortie des chipsets AMD 900 au Computex pour lancer modèles AM3+. Deux versions Opteron devraient voir le jour cet été également. Interlagos est le nom de code de la version haut de gamme, destinée aux machines bi et quad socket. Il s'agit d'un dual-chip (deux die sur le même package) sur socket G34 (1974 pins) composé de pas moins de 8 à 16 cores et pouvant gérer jusqu'à quatre canaux de DDR3-1600. Valencia est pour sa part la version mono-die qui prendra place sur le socket C32 (1207 pins) destiné aux machines mono et bi socket. Cette fois on aura droit à 6 à 8 core et la DDR3 sera gérée sur deux canaux. Il faudra attendre 2012 et la prochaine APU Komodo pour voir l'architecture Bulldozer débarquer sur portables. ConclusionAMD joue gros avec sa nouvelle gamme de produits, et notamment avec son architecture Bulldozer qui devra faire face aujourd'hui au Sandy Bridge, demain au Sandy Bridge-E, et plus tard à l'Ivy Bridge. Cependant, l'architecture d'AMD a de sérieux atouts en poche, et est capable de faire une jolie carrière. La souplesse des modules promet des versions à plus de 8 cores dans un proche avenir, et si les fréquences sont bien au rendez-vous, la performance sera présente, surtout dans le traitement multi-threads.  Reste qu'il faudra encore être patient. Si les premiers échantillons de Zambezi commencent à être distribués, son lancement ne devrait pas avoir lieu avant Juillet. Il faudra attendre encore un peu pour juger de l'efficacité de la nouvelle architecture en pratique et voir si AMD a gagné son pari, un rendez-vous à ne pas manquer donc ! Copyright © 1997-2024 HardWare.fr. Tous droits réservés. |