
Preview : AMD RX Vega64 et RX Vega56 en test



Vega 10 : 12.5 milliards de transistors
Vega 10 est un très gros GPU annoncé à 12.5 milliards de transistors pour 486mm2 de superficie.

Si l'on reprend la liste des derniers GPU :
- GP100 : 15.3 milliards de transistors pour 610 mm²
- Vega 10 : 12.5 milliards de transistors pour 486 mm²
- GP102 : 12.0 milliards de transistors pour 471 mm²
- Fiji : 8.9 milliards de transistors pour 598 mm²
- GM200 : 8.0 milliards de transistors pour 601 mm²
- GP104 : 7.2 milliards de transistors pour 314 mm²
- GK110 : 7.1 milliards de transistors pour 561 mm²
- Hawaii : 6.2 milliards de transistors pour 438 mm²
- Polaris 10 : 5.7 milliards de transistors pour 232 mm²
- GM204 : 5.2 milliards de transistors pour 398 mm²
- Tonga : 5.0 milliards de transistors pour 368 mm²
- GP106 : 4.4 milliards de transistors pour 200 mm²
- GK104 : 3.5 milliards de transistors pour 294 mm²
- GM206 : 2.9 milliards de transistors pour 228 mm²
- Pitcairn : 2.8 milliards de transistors pour 212 mm²
- GK106 : 2.5 milliards de transistors pour 214 mm²
- Bonaire : 2.1 milliards de transistors pour 158 mm²
Vega est donc légèrement plus gros que le GP102, utilisé chez Nvidia sur les GTX 1080 Ti (les GTX 1080/1070 utilisent le GP104, significativement plus petit pour rappel).
- Vega 10 : 25.7 millions de transistors par mm²
- GP102 : 25.4 millions de transistors par mm²
- GP100 : 25.1 millions de transistors par mm²
- Polaris 10 : 24.6 millions de transistors par mm²
- Tonga : 13.6 millions de transistors par mm²
- Pitcairn : 13.2 millions de transistors par mm²
- GP104 : 22.9 millions de transistors par mm²
- GM204 : 13.1 millions de transistors par mm²
- GM206 : 12.7 millions de transistors par mm²
Côté densité, Vega se place légèrement en tête du classement, ce qui n'est en soit pas très important. La densité est un peu meilleure que sur Polaris 10, mais l'écart est plutôt léger. Comme Polaris, Vega est fabriqué par GlobalFoundries sur leur process 14 LPP.
HBM2
Du côté de la mémoire, on passe de la HBM de première génération utilisée sur Fiji à la HBM2. Techniquement la HBM2 multiplie par deux la bande passante par pin, tout en augmentant la capacité, ce qui permet à AMD de n'utiliser que deux dies de HBM2.
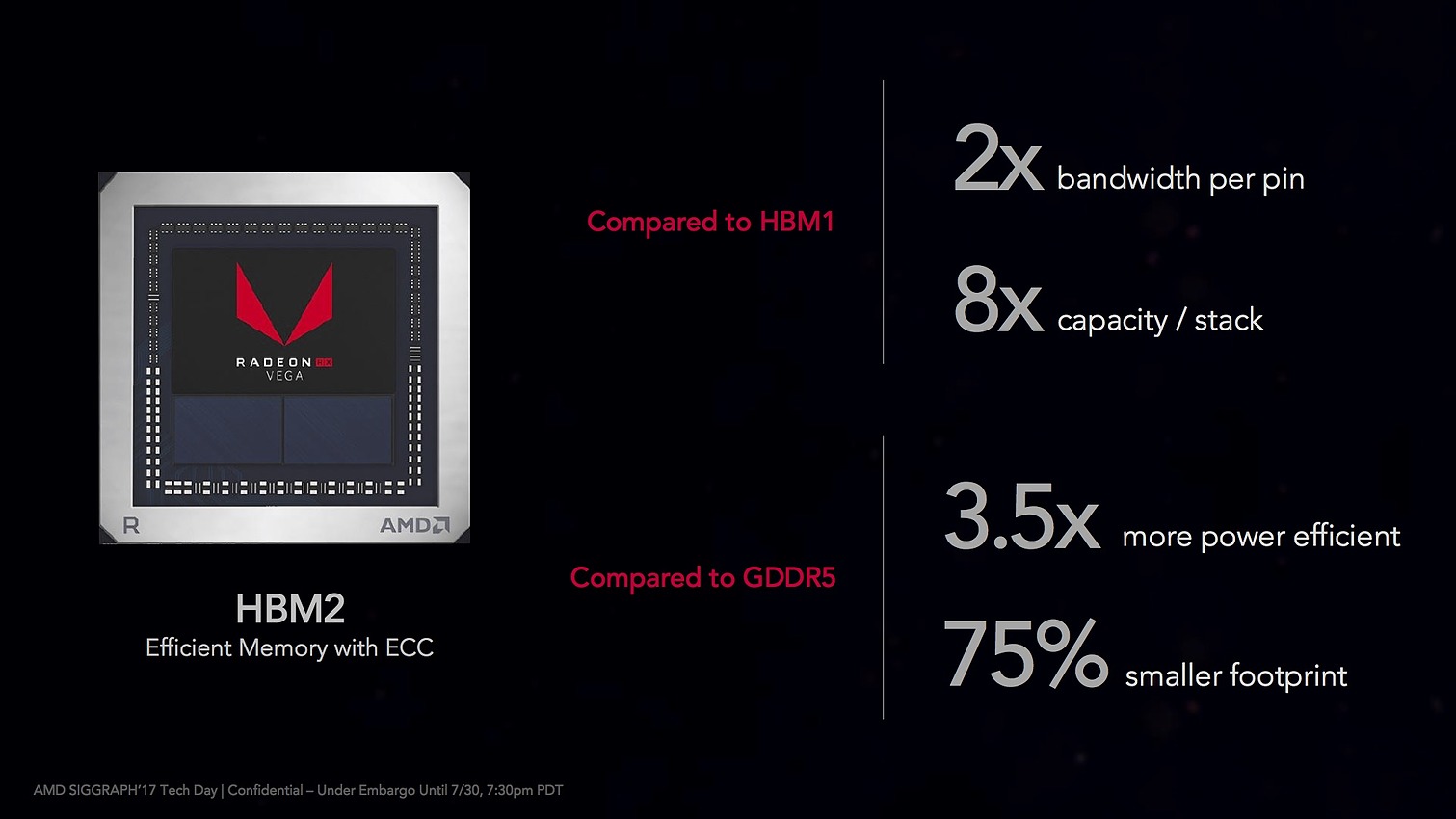
Là où Fiji utilisait quatre dies interfacés 4096 bits pour 512 Go/s de bande passante, Vega 10 se contente de deux puces interfacées en 2048 bits, tout en proposant une bande passante mémoire très légèrement inférieure de 484 Go/s. Pas de gain donc de ce côté, et on notera que la concurrence propose désormais un niveau de bande passante équivalent de 484 Go/s sur les GTX 1080 Ti qui utilisent, elles, de la GDDR5X.
64 CU et 4096 Stream processors
Si AMD n'a pas prononcé une fois l'acronyme GCN durant sa présentation, en pratique on retrouve bien une architecture similaire aux GPU précédents du constructeurs. On retrouve donc 64 Compute Unit, affublées d'un très marketing « Next Gen » pour 4096 unités de calculs (ce qu'AMD appelle Stream processors). C'est deux fois plus d'unités qu'une Radeon 470, mais autant que Fiji. De la même manière on retrouvera aussi 256 unités de textures et 64 ROPs.
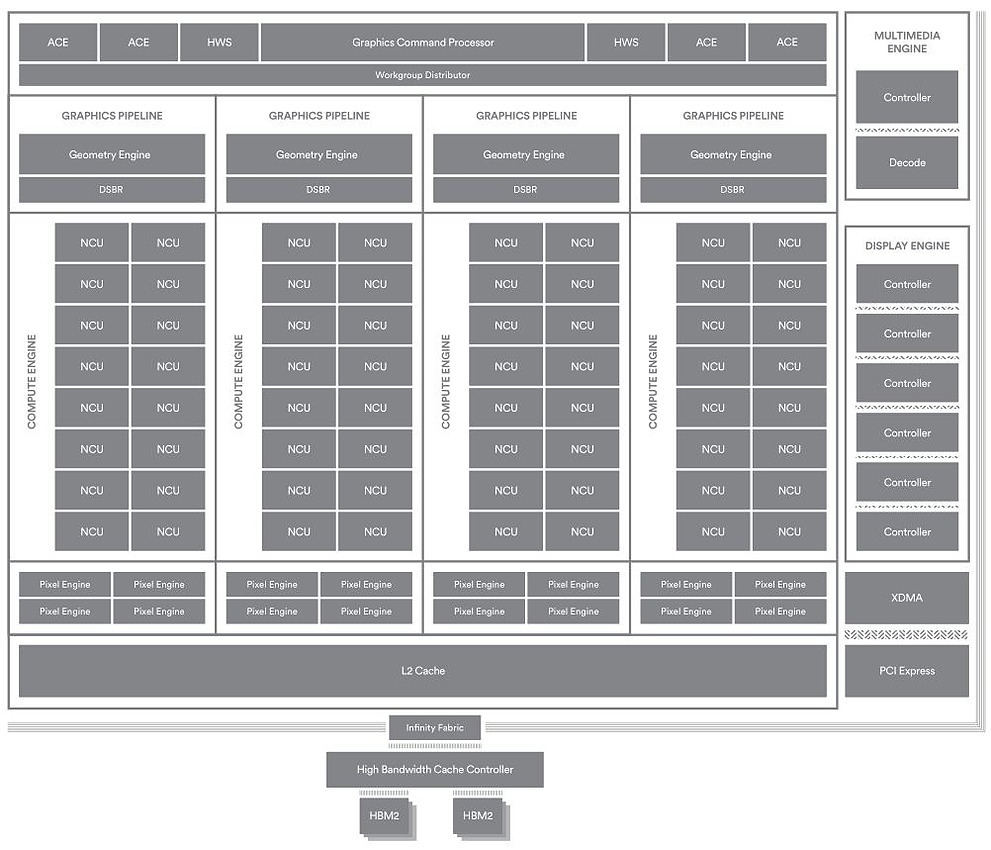
A l'intérieur des CU AMD a procédé a de petites améliorations par rapport à Polaris avec de nouvelles instructions de texturing capables de stocker deux données 16 bits dans un registre 32 bits.




AMD illustrait cela avec une version spécifique de la démo Time Spy de 3D Mark ou l'application d'instructions 16 bits (AMD regroupe cela derrière le nom Rapid Packed Math) permet de voir des gains assez intéressants, dans le cas de la génération de bruit, le passage d'instructions INT32 à des INT16 permet un gain pratique de 25% de performances sur cet algorithme, et le passage en FP16 des FFT utilisées pour les effets de bloom permet un gain de 20% de performance sur cette partie du rendu. Reste à voir si les développeurs suivront, ce n'est pas la première fois qu'AMD met en avant le FP16 avec des résultats pratiques limités.
On notera que le jeu d'instruction interne gagne 40 nouvelles instructions, qui incluent aussi de nouvelles instructions pour les crypto-monnaies.
Une gestion mémoire « façon CPU »
Un des changements les plus originaux apporté par Vega concerne la gestion de la mémoire. De manière historique, la mémoire embarquée par les GPU doit être gérée manuellement par les développeurs (avec plus ou moins de facilité en fonction des API utilisées) qui doivent remplir (et faire de la place si nécessaire) eux même la mémoire graphique. Un système de fonctionnement très basique, et très différent de ce que l'on connaît sur les CPU.
Sans rentrer trop dans les détails, les CPU et les systèmes d'exploitation comme Windows utilisent ce que l'on appelle un système dit de pagination mémoire. Un programme n'accède jamais vraiment à la mémoire système de manière directe, il alloue de la mémoire sous la forme de blocs (des pages mémoires) qui utilisent un système d'adressage virtuel. En pratique, le programme ne sait pas à quel endroit exact ses données sont stockées, une possibilité exploitée par les systèmes d'exploitation avec la gestion de mémoire virtuelle qui permet d'étendre la quantité mémoire disponible en stockant des pages mémoires dans un fichier (sous Windows, le fameux pagefile.sys). Le système s'occupe alors lui-même de stocker les pages les moins utilisées sur disque, et les pages les plus utilisées sont gardées en mémoire centrale.
Avec Vega, AMD s'est inspiré de cela en proposant un mode de fonctionnement alternatif baptisé HBCC (High Bandwidth Cache Controller). Pour s'en servir, on activera ce mode dans le driver d'AMD où l'on définira la taille de l'espace virtuel (par exemple, 32 Go).
Par la suite, un jeu qui se lancera se verra rapporté par le driver le fait que (dans notre exemple) 32 Go de mémoire sont disponible (au lieu de 8). Il pourra allouer comme à l'habitude sa mémoire, mais de manière transparente, le GPU va paginer la mémoire. Les pages pourront ainsi être placées au choix en HBM2, ou en mémoire système.




C'est le GPU (et son driver) qui gèrera ainsi la mémoire, la HBM2 étant vue comme un cache exclusif par rapport à l'espace virtuel. En pratique, cela permet de faire tourner des applications qui ont besoin de plus de mémoire que ce dont dispose la carte graphique, on est alors uniquement limité par la bande passante PCI Express lorsqu'il faut transférer des pages d'un endroit à l'autre (l'équivalent du swap).
Sur le papier, l'idée d'amener les GPU dans la modernité pour la gestion mémoire peut sembler intéressante. Le fait que les jeux doivent gérer eux même leur mémoire fait qu'en pratique, cette gestion est rarement fine, pour ne pas dire grossière. La majorité des données allouées sont rarement nécessaires en simultanée pour le rendu d'une frame et disposer d'un mécanisme de swap de ce type pourrait permettre, dans un temps long, de faire tourner des jeux avec des niveaux de textures plus élevés qui ne rentreraient pas dans les 8 Go présents sur la carte.
Cela reste cependant un avantage très théorique qui dépendra de la qualité de l'implémentation du système. Car le cout d'un échange de données entre la mémoire centrale et celle du GPU n'est pas nul et l'on risque de se retrouver, au-delà de démonstrations savamment choisies avec des lags dues à ces transferts. Quelque chose de tout à fait acceptable dans un cas d'utilisation d'applications professionnelles ou un ralentissement vaut mieux qu'une impossibilité de fonctionner.
Si l'idée sur le fond nous semble bonne, nous resterons donc prudents sur ce qu'elle pourrait apporter en pratique pour la déclinaison « jeu » de Vega car si AMD aime mettre en parallèle cela avec le concept de « megatexture » utilisé par id Software, l'implémentation, d'un peu plus haut niveau, demandera à être jugée en pratique avec des applications adéquates.
Un support DirectX 12 plus complet
Avec Vega, AMD améliore son support de DirectX 12 par rapport à Polaris :

Le premier sur lequel AMD n'a pas vraiment communiqué dans sa présentation est la gestion du standard swizzle, un mode spécifique d'alignement des données pour les textures qui permet d'améliorer la rapidité de certains algorithmes . La fonctionnalité n'est gérée que par Vega aujourd'hui.
L'autre changement concerne la rasterization, la transformation d'un triangle en pixels. DX12 ajoute le concept de conservative rasterization qui permet d'améliorer la manière dont cette transformation s'opère en ajoutant des règles plus claires sur les algorithmes utilisés pour éviter les incertitudes dans le rendu.
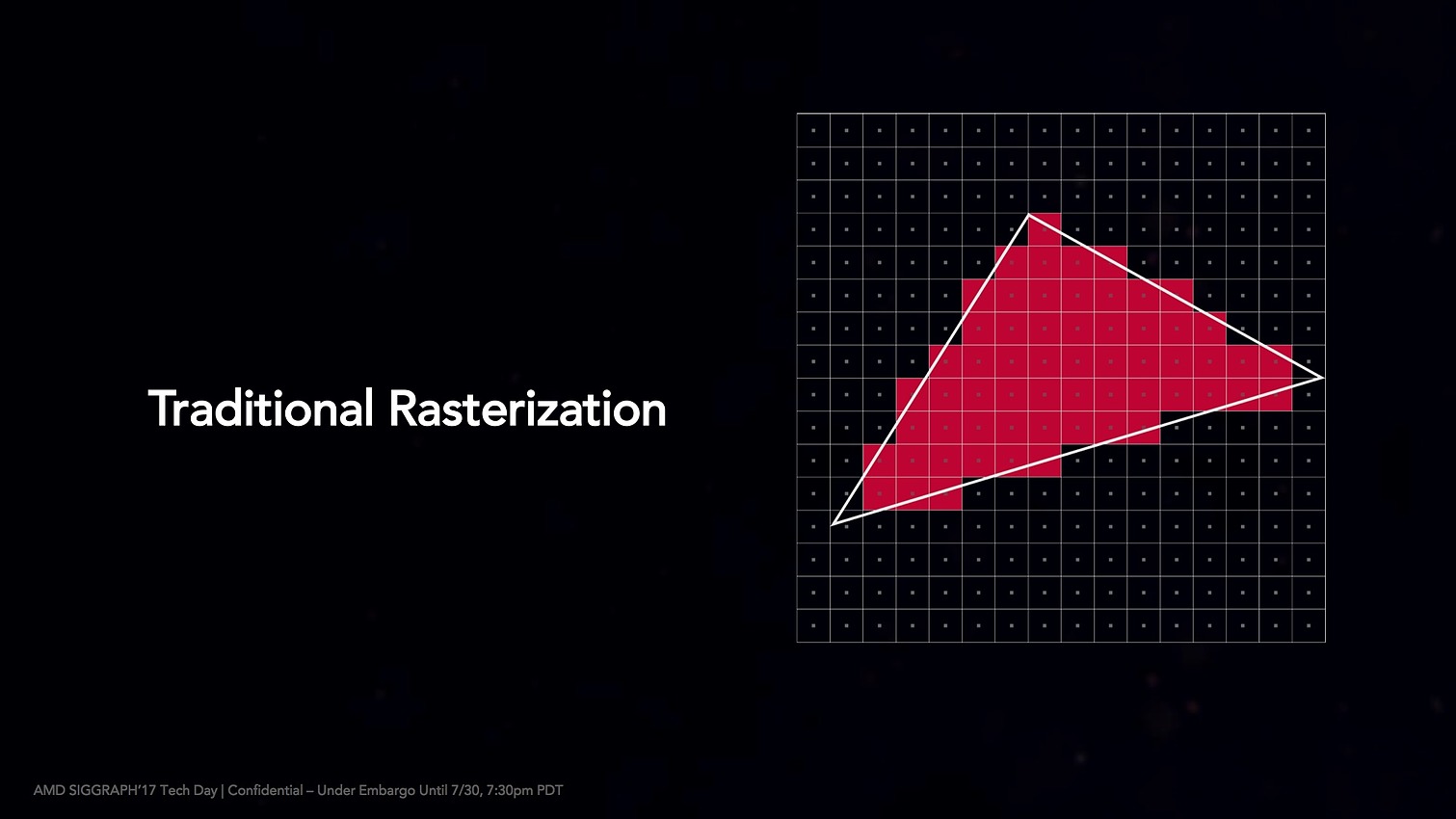


Pascal chez Nvidia supportait déjà les deux premiers tiers de cette fonctionnalité, le premier est surtout utile au tiled rendering, la génération de light maps et des shadow maps. Le second réduit un peu plus l'incertitude ce qui est surtout utile pour les rendus types voxel. Le troisième niveau que supporte Vega ajoute une variable dans le langage des shaders de DirectX (HLSL) qui permet de régler finement le niveau de sous-estimation que l'on désire, une fonctionnalité qui permet d'optimiser l'occlusion.

Vega gère également de nouveaux types de shaders, baptisés primitive shaders qui peuvent remplacer les vertex/geometry shaders pour réaliser de nouveaux types de rendus plus efficaces avec la possibilité d'éliminer beaucoup plus efficacement des primitives. Là encore cela demandera un travail important aux développeurs ce qui fait qu'on peut douter qu'elle soit exploitée, mais AMD disposerait d'un path alternatif dans ses pilotes qui permettrait au cas par cas d'obtenir des gains.
Sorties vidéo améliorées

Pour terminer sur les détails de la puce, notez qu'au-delà de l'architecture, la gestion des sorties vidéos a été améliorée. Par rapport à Polaris on peut désormais piloter deux écrans 4K 120 Hz en simultanée. Pour les modes HDR, on passe de un à trois écrans 4K 60 Hz, et le support d'un écran 4K 120 Hz ou 5K 60 Hz.
D'autres petits détails ont aussi été améliorés, le décodage hardware H.264 par exemple fonctionne désormais pour les vidéo 4K 60 Hz (cette résolution n'était gérée que pour H.265 par Polaris). Du côté de la virtualisation, VCE (les fonctionnalités de décodage/encodage vidéo) sont désormais également disponibles dans les machines virtuelles.
Contenus relatifs
- [+] 19/12: Sapphire lance ses Vega 64 et 56 NI...
- [+] 14/11: Bientôt (enfin !) des RX Vega 56 cu...
- [+] 18/10: Nouvelle offre AMD sur les RX Vega
- [+] 12/10: RX Vega Custom, l'arlésienne ?
- [+] 27/09: RX Vega : les prix de lancement bie...
- [+] 14/09: Pour quand les RX Vega Custom ? Oct...
- [+] 14/08: Preview : AMD RX Vega64 et RX Vega5...
- [+] 01/08: L'ASUS ROG Strix RX Vega 64 en sept...
- [+] 31/07: AMD lève le voile sur les RX Vega
- [+] 30/07: RX Vega se montre au Siggraph