
Intel Core i9-7900X et Core i7-7740X en test : déjà-vus ?



Une nouvelle architecture de caches
C'est une des plus grosses surprises, Intel a décidé de changer drastiquement l'implémentation de la mémoire cache dans ses puces.
Au niveau du L1, en apparence rien ne change. On trouve toujours un cache de données de 32 Ko (avec une associativité 8-way). Un cache d'instruction de 32 Ko est également toujours présent, sans changement.
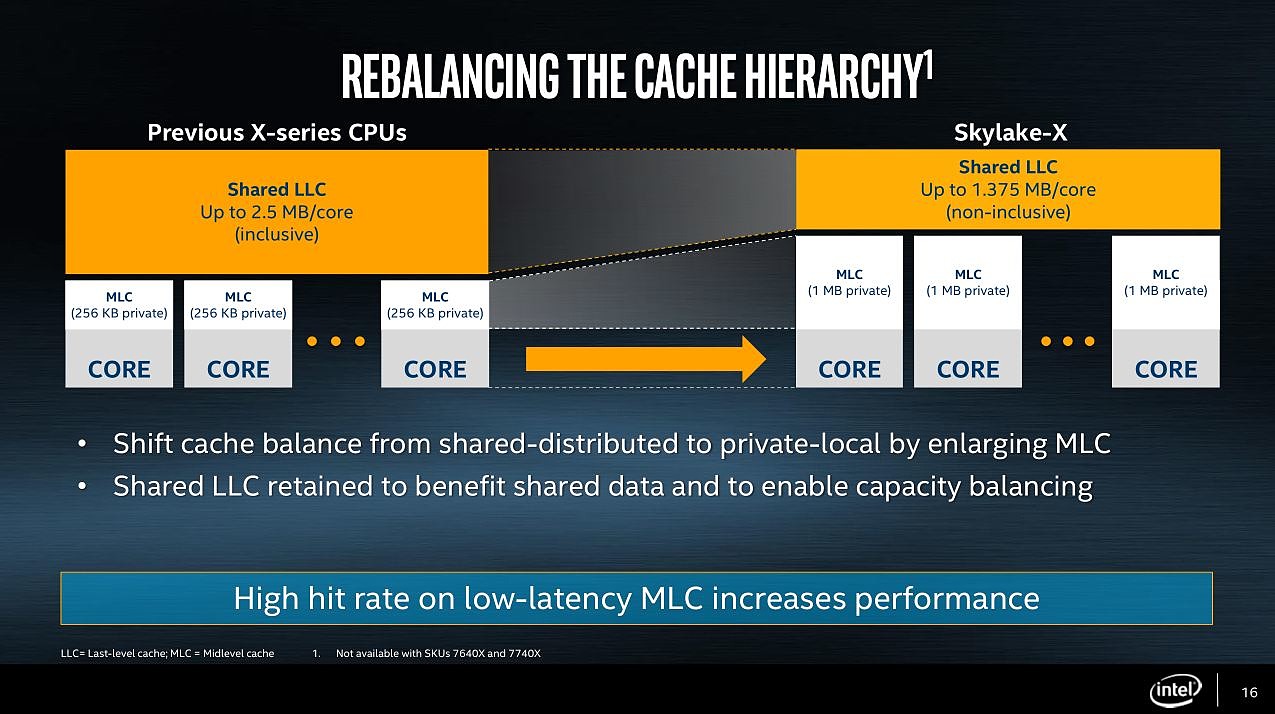
Augmenter la taille du L2 sur le papier est un moyen assez simple d'augmenter les performances, s'il permet d'éviter un saut jusqu'au L3 (dont la latence est plus élevée et la bande passante plus basse). A latence/bande passante égale, quadrupler la taille du L2 serait donc une excellente chose.
Mais avant de parler de vitesse, parlons du L3...
Un L3... victime ?!
C'est clairement une des plus grosses surprises de ce lancement, Intel a décidé de mettre de côté son système de cache L3 inclusif pour passer... à un cache type victime. Pour rappel, historiquement les caches L3 d'Intel étaient de type inclusif. Cela veut dire qu'une donnée présente dans le L2 était copiée dans le cache L3. Il y a de multiples avantages à cette approche qu'Intel mettait en avant. Un exemple simple est lorsqu'un coeur a besoin de données placées dans le L2 d'un autre coeur : les données sont déjà dans le L3, évitant de devoir aller les récupérer dans le L2 de l'autre coeur (ou en mémoire).
Le L3 de Skylake-X est donc de type exclusif, on parle aussi de cache victime puisqu'il se remplit des données qui ont été éjectées des L2 des coeurs. Si cette description vous rappelle quelque chose, c'est peut-être parce que c'est exactement le même type de cache L3 que l'on retrouve sur... Ryzen.
Et en pratique ?
Avant de vous donner les chiffres de bande passante ci-dessous, nous devons vous indiquer que nous ne sommes pas les seuls à avoir eu peu de temps pour travailler sur notre article. Les auteurs des outils de tests que nous utilisons régulièrement, que ce soit Hwinfo64 ou Aida64 ont également eu assez peu de temps pour s'adapter aux particularités de Skylake-X qui change beaucoup de choses, particulièrement dans la manière de détecter correctement la fréquence du processeur et de la BCLK.
Intel a ajouté de nouveaux mécanismes qui font que le processeur doit rapporter lui-même ces informations, mais ces dernières sont assez mal documentées ce qui peut générer des erreurs dans certains outils qui ne lisent pas forcément correctement les fréquences. Nous tenons une fois de plus à remercier la persistance et la patience des auteurs des dits logiciels, qui nous ont amplement aidés une fois de plus !
De la même manière, les tests de bande passante n'ont pas forcément été "optimisés" même s'ils semblent corrects à première vue.
Pour ce test, nous avons configuré le 7900X en mode "8 coeurs" en désactivant deux de ses coeurs. Nous désactivons l'HyperThreading, et la fréquence des puces est réglée à 3 GHz. Cela nous permet d'obtenir une comparaison directe avec le Core i7-6900K et le Ryzen 1800X.
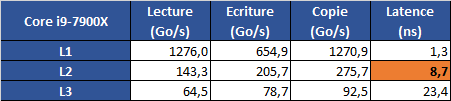
Regardons donc ce qu'il en est des caches de Skylake-X :
[ Skylake-X ] [ Broadwell-E ] [ Zen ]
Mettons de côté un instant la latence que nous avons marqué en orange pour comparer les bandes passantes en lecture entre 7900X et 6900K.
En terme de bande passante, sur le L1, on est en pratique plus lent de 11% en lecture et un tout petit peu plus en écriture. Rien de grave, si l'on compare à Ryzen par exemple, Intel continue d'avoir des L1 excessivement rapides.
Par contre quand on regarde le L2, les choses sont toutes autres. Certes, la bande passante en écriture/copie ne baisse que de 12/13%, mais la bande passante en lecture est divisée par trois ! Nous ne l'avons pas remis sur ce graphique, mais ce chiffre de bande passante en lecture est même inférieur à... Piledriver. On restera prudent, nous le verrons un peu plus bas le L2 semble avoir un fonctionnement différent de ce que les caractéristiques brutes fournies par Intel peuvent laisser penser, et cela impacte probablement cette valeur de bande passante.
Mais si l'on regarde maintenant le L3, les choses sont dans la même lignée. Cette fois les opérations de lecture/copie sont deux fois plus lentes sur Skylake-X que sur Broadwell-E, et en lecture on divise une fois de plus par trois les performances.
Autant dire que ces chiffres ne sont pas bons, et si une fois de plus nous vous rappellerons qu'il est possible que les outils de mesures d'Aida64 ne détectent pas correctement certains détails, ou ne soient pas adaptés à certaines particularités de Skylake-X, l'ordre de grandeur général semble bien être celui-ci.
Pour ce qui est de la latence, là aussi on est circonspect. La latence du L1 est semblable, mais celle du L2 augmente, s'alignant un peu plus sur Zen que sur Broadwell-E. Et pour le L3, là aussi, la latence est très élevée, presque 50% supérieure à celle de Broadwell-E.
Afin d'y voir plus clair, nous avons utilisé le benchmark de latence avancé d'Aida64 qui nous permet de mesurer la latence en fonction de la taille des accès. Pour rappel, on regardera l'évolution sur le graphique en trois morceaux :
- 0 à 32 Ko (L1)
- 32 Ko à 1 Mo (L2)
- 1 Mo à 12 Mo (L3)
Voyons ce que cela donne en pratique :
[ Core i7-7900X ] [ Core i7-6900K ] [ Ryzen 7 1800X ]
Sur le L1, on ne voit pas de surprise, on se retrouve à un niveau cohérent et qui ne bouge pas (la latence est de 4 cycles). Sur le L2 par contre, nous nous posons quelques questions. Le benchmark "rapide" d'AIDA64 nous indiquait une valeur assez élevée, qui correspond peu ou prou à des accès sur un peu moins d'un Mo. Normal, c'est bien la taille du L2 avancée par Intel. Sauf que ce qui est surprenant, c'est que ce L2 ait une latence variable en fonction de la taille des accès. Les 256 premiers Ko (taille historique du L2 Intel) ont une latence très basse tandis qu'au-delà la latence monte. C'est intriguant, et montre peut être que ce L2 aurait un fonctionnement un peu plus complexe qu'a l'habitude.
Pour ce qui est du L3, on voit là aussi que la latence n'est pas la même à 1.5 Mo qu'au-delà, à 12 Mo cette latence augmentant assez nettement (passé 14 Mo, on est en mémoire centrale). Il y aurait donc un effet, bien qu'avec un impact très léger, sur la latence.
Terminons par ce que l'on devine en bas de notre graphique, à savoir la bande passante et la latence mémoire. Dans ce test, nos plateformes modernes utilisent 4 barrettes de DDR4-2400 CL15 (et DDR3-1600 CL9 pour le FX), en quadruple canal sur les Intel. Nous utilisons le test intégré d'Aida64 :
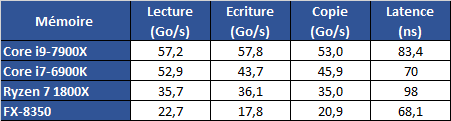
Sur la bande passante mémoire, Intel semble progresser dans ce test qui reste on le rappellera très théorique. La bande passante en écriture s'aligne sur celle en lecture ce qui semble intéressant. Mais l'on notera que la latence semble là aussi largement supérieure à ce qu'elle était sous Broadwell-E !
Essayons de garder ces détails à l'esprit pour appréhender l'autre gros changement effectué par Intel sur Skylake-X...
2 - Kaby Lake-X et Skylake-X, diamétralement opposés
3 - Nouveaux caches et nouvelle... interconnexion ?
4 - Sortie de ring : place au mesh !
5 - X299, Asus Prime X299-A, gamme LGA 2066
6 - Piledriver, Zen, Broadwell-E et Skylake-X à 3 GHz
7 - Impact du SMT/HT
8 - Overclocking en pratique
9 - Consommation, efficacité énergétique
10 - Protocole de test
11 - Compression : 7-Zip et WinRAR
13 - Encodage vidéo : x264 et x265
14 - IA d'échecs : Stockfish et Komodo
15 - Traitement photos : Lightroom et DxO Optics Pro
16 - Rendu 3D : Mental Ray et V-Ray
17 - Jeux 3D : Project Cars et F1 2016
18 - Jeux 3D : Civilization VI et Total War : Warhammer
19 - Jeux 3D : GTA V et Watch Dogs 2
20 - Jeux 3D : Battlefield 1 et The Witcher 3
21 - Indices de performance
22 - Un air de déjà vu...
Contenus relatifs
- [+] 09/05: AMD Ryzen 7 2700, Ryzen 5 2600 et I...
- [+] 05/04: Pas de MAJ Microcode pour les Gulft...
- [+] 22/12: Samsung grave de la DRAM en ''1ynm'...
- [+] 05/10: Intel Core i7-8700K, Core i5-8600K,...
- [+] 04/10: La DDR4 toujours en hausse, pénurie...
- [+] 14/09: Les prix de la DDR4 ont doublé en u...
- [+] 12/09: Core i7-7820X : Un Skylake-X mieux ...
- [+] 07/09: Les Skylake en fin de vie chez Inte...
- [+] 23/08: Coffee Lake incompatible avec les L...
- [+] 10/08: AMD Threadripper 1950X et 1920X en ...