
Radeon RX 460 vs GeForce GTX 1050 / GTX 1050 Ti : le test de cartes Asus, Gigabyte, MSI, Sapphire et Zotac



Polaris 11 vs GP107 : match en 14nm
Pour cette première génération 16/14 nm, AMD s'est attaqué au milieu et à l'entrée de gamme avec 2 GPU Polaris. De son côté, Nvidia a décidé de couvrir toutes ses gammes avec pas moins de 5 GPU Pascal.
Le GP107 reprend la même architecture Pascal que les GP102 / GP104 /GP106 et vous pourrez retrouver les détails la concernant dans les premières pages du dossier consacré à la GeForce GTX 1080. Il en va de même pour le Polaris 11 qui reprend la même architecture que le Polaris 10 que nous avions décrite lors du test de la Radeon RX 480.

Les GPU Polaris 11 et GP107 sont fabriqués en 14 nm LPP, un process développé par Samsung, qui fabrique le second, et repris par Global Foundries qui fabrique le premier. Après plus de 4 ans de GPU fabriqués en 28 nm chez TSMC, le passage au 16 ou 14 nm représente une évolution significative qui permet de nouveaux compromis plus avantageux en termes de consommation énergétique, de performances et de fonctionnalités. De toute évidence AMD et Nvidia n'ont pas voulu trop attendre pour en faire profiter l'entrée de gamme qui a tendance à évoluer moins vite.

Voici comment se situe les GP107 et Polaris 11 parmi les GPU récents :
- GP100 : 15.3 milliards de transistors pour 610 mm²
- GP102 : 12.0 milliards de transistors pour 471 mm²
- Fiji : 8.9 milliards de transistors pour 598 mm²
- GM200 : 8.0 milliards de transistors pour 601 mm²
- GP104 : 7.2 milliards de transistors pour 314 mm²
- GK110 : 7.1 milliards de transistors pour 561 mm²
- Hawaii : 6.2 milliards de transistors pour 438 mm²
- Polaris 10 : 5.7 milliards de transistors pour 232 mm²
- GM204 : 5.2 milliards de transistors pour 398 mm²
- Tonga : 5.0 milliards de transistors pour 368 mm²
- GP106 : 4.4 milliards de transistors pour 200 mm²
- GK104 : 3.5 milliards de transistors pour 294 mm²
- GP107 : 3.3 milliards de transistors pour 135 mm²
- Polaris 11 : 3.0 milliards de transistors pour 123 mm²
- GM206 : 2.9 milliards de transistors pour 228 mm²
- Pitcairn : 2.8 milliards de transistors pour 212 mm²
- GK106 : 2.5 milliards de transistors pour 214 mm²
- Bonaire : 2.1 milliards de transistors pour 158 mm²
- GM107 : 1.9 milliards de transistors pour 148 mm²
Le GP107 est 10% plus gros que le Polaris 11 et va en toute logique pouvoir viser des performances supérieures.
GP107 : le petit Pascal
Pour comprendre l'architecture du GP107, quelques rappels s'imposent concernant la manière dont Nvidia schématise l'organisation interne de ses GPU. A un niveau élevé, ils se composent de un ou plusieurs GPC (Graphics Processing Cluster). Chacun contient un moteur de rastérisation chargé de projeter les primitives et de le découper en pixels.
A l'intérieur de ces GPC, nous retrouvons un ou plusieurs TPC (Texture Processor Cluster). Ne vous fiez pas à ce nom, vestige de précédentes architectures, le TPC est aujourd'hui décrit comme la structure qui représente le Polymorph Engine, nom donné à l'ensemble des petites unités fixes dédiées au traitement de la géométrie (chargement des vertices, tessellation etc.).
Enfin, au plus bas niveau, ces TPC intègrent un ou plusieurs SM (Streaming Multiprocessor) qui représentent le coeur de l'architecture. C'est à leur niveau que prennent place les unités de calcul (affreusement appelées "CUDA cores" par le marketing), les unités de texturing, les registres ou encore la mémoire partagée utile au GPU computing.
Sur base de ces éléments, voici comment est organisé le GP107 dans ses deux versions commerciales :
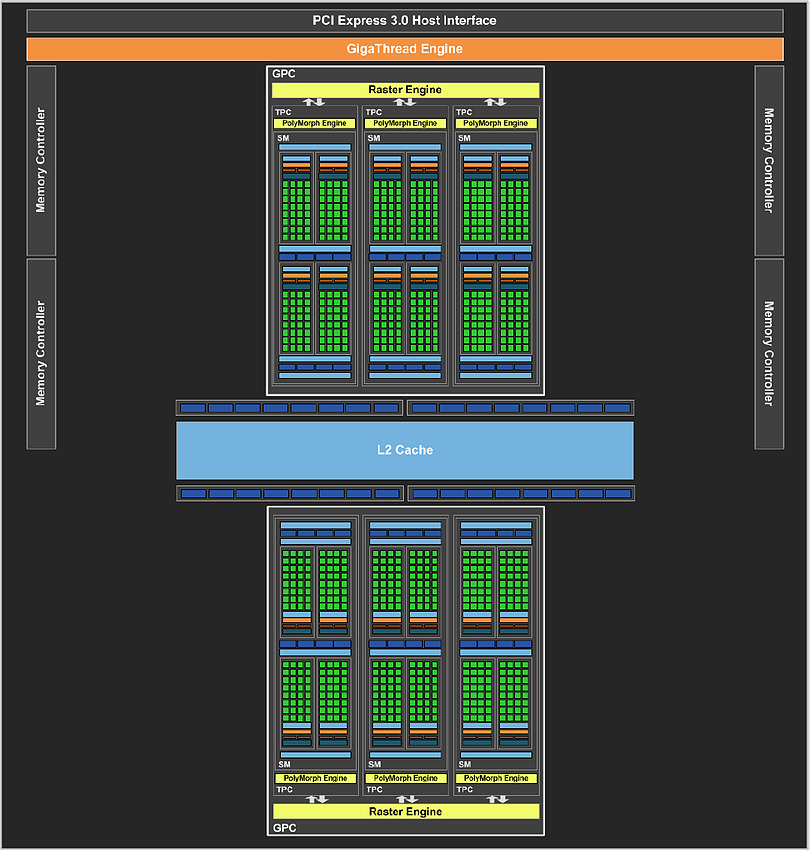
[ GP107 ] [ GP107 sur GTX 1050 ]
Nous pouvons observer que le GP107 intègre 2 GPC, comme le GP106. Ils se contentent par contre de 3 SM contre 5 pour les GPC des autres GPU Pascal. Le nombre d'unité de calcul est donc en retrait de 40% par rapport au GP106. L'interface mémoire a de son côté été limitée à 128-bit et 32 ROP, ce qui représente cette fois 33% de moins mais à peu près 40% de moins si nous prenons en compte sa fréquence.
Pour la GeForce GTX 1050, Nvidia a désactivé l'un des 6 SM mais conserve la totalité de l'interface mémoire. A noter que sur les GPU Maxwell et Pascal, le débit de pixel peut être limité par le nombre de SM, ceux-ci ne pouvant transférer que 4 pixels par cycle vers les ROP. Dans le cas du GP107 cela aurait ainsi pu être une limitation mais selon nos mesures, ce n'est pas le cas et il est possible d'atteindre un débit de 32 pixels par cycle et non pas de 24 ou 20. Nvidia a donc visiblement apporté une petite modification.
Voici pour comparaisons les spécificités de quelques GPU Nvidia sur 3 générations :
- GP100 : 6 GPC, 60 SM, 3840 FP32, 128 ROP ?, bus 4096-bit, 4096 Ko de L2
- GP102 : 6 GPC, 30 SM, 3840 FP32, 96 ROP, bus 384-bit, 3072 Ko de L2
- GM200 : 6 GPC, 24 SM, 3072 FP32, 96 ROP, bus 384-bit, 3072 Ko de L2
- GK110 : 5 GPC, 15 SM, 2880 FP32, 48 ROP, bus 384-bit, 1536 Ko de L2
- GP104 : 4 GPC, 20 SM, 2560 FP32, 64 ROP, bus 256-bit, 2048 Ko de L2
- GM204 : 4 GPC, 16 SM, 2048 FP32, 64 ROP, bus 256-bit, 2048 Ko de L2
- GK104 : 4 GPC, 8 SM, 1536 FP32, 32 ROP, bus 256-bit, 512 Ko de L2
- GP106 : 2 GPC, 10 SM, 1280 FP32, 48 ROP, bus 192-bit, 1536 Ko de L2
- GM206 : 2 GPC, 8 SM, 1024 FP32, 32 ROP, bus 128-bit, 1024 Ko de L2
- GK106 : 3 GPC, 5 SM, 960 FP32, 24 ROP, bus 192-bit, 384 Ko de L2
- GP107 : 2 GPC, 6 SM, 768 FP32, 32 ROP, bus 128-bit, 1024 Ko de L2
- GM107 : 1 GPC, 5 SM, 640 FP32, 16 ROP, bus 128-bit, 2048 Ko de L2
A noter que si le nombre d'unités de calcul n'est pas impressionnant, il ne faut pas oublier qu'avec Pascal Nvidia a particulièrement travaillé sur la fréquence qui fait un bond important. Ses GPU fabriqués en 16nm chez TSMC sont capables d'atteindre 2 GHz, et si le GP107 fabriqué chez Samsung en 14nm se contente plutôt de 1850 ou 1900 MHz, cela reste très élevé. Par ailleurs, chez Nvidia, les unités de calcul généraliste sont épaulées par des unités dédiées aux opérations plus complexes (SFU).
Polaris 11 : moins que la moitié d'un Polaris 10
Du côté d'AMD, le langage est évidemment différent pour caractériser l'architecture. Nous retrouvons au niveau le plus élevé des Shader Engines (SE). Chacun contient un moteur de rastérisation chargé de projeter les primitives et de le découper en pixels mais également une ou plusieurs partitions de ROP.
A l'intérieur de ces SE, nous retrouvons un ou plusieurs CU (Compute Units). C'est à leur niveau que prennent place les unités de calcul organisées en SIMD, les unités de texturing, les registres ou encore la mémoire partagée utile au GPU computing.
Sur base de ces éléments, voici comment est organisé le Polaris 11 ainsi que sa version commerciale :

[ Polaris 11 ] [ Polaris 11 sur RX 460 ]
Nous pouvons observer que le Polaris 11 intègre 2 SE, soit la moitié du Polaris 10. Chaque SE se contente par contre de 8 CU au lieu de 9, raison pour laquelle Polaris 11 représente moins que la moitié d'un Polaris 10. Son interface mémoire a logiquement été réduite à 128-bit.
Assez étrangement, AMD a décidé de ne pas commercialiser de version complète de Polaris 11 pour l'instant. Dans le cadre de la Radeon RX 460, 1 CU par SE est désactivé, ce qui en limite le nombre à 14.
Voici pour comparaisons les spécificités des GPU GCN :
- Fiji : GCN 3, 64 CU, 4 triangles par cycle, 64 ROP, L2 2048 Ko, 4096 bits HBM
- Hawaii : GCN 2, 44 CU, 4 triangles par cycle, 64 ROP, L2 1024 Ko, 512 bits
- Polaris 10 : GCN 4, 36 CU, 4 triangles par cycle, 32 ROP, L2 2048 Ko, 256 bits
- Tonga : GCN 3, 32 CU, 4 triangles par cycle, 32 ROP, L2 768 Ko, 384 bits
- Tahiti : GCN 1, 32 CU, 2 triangles par cycle, 32 ROP, L2 768 Ko, 384 bits
- Pitcairn : GCN 1, 20 CU, 2 triangles par cycle, 32 ROP, L2 512 Ko, 256 bits
- Polaris 11 : GCN 4, 16 CU, 2 triangles par cycle, 16 ROP, L2 1024 Ko, 128 bits
- Bonaire : GCN 2, 14 CU, 2 triangles par cycle, 16 ROP, L2 512 Ko, 128 bits
- Cape Verde : GCN 1, 10 CU, 1 triangle par cycle, 16 ROP, L2 512 Ko, 128 bits
- Oland : GCN 1, 6 CU, 1 triangle par cycle, 8 ROP, L2 256 Ko, 128 bits
Il est intéressant d'observer que Polaris 11 tel qu'exploité sur la Radeon RX 460 est configuré de manière similaire au GPU Bonaire de la Radeon R7 360.
2 - Polaris 11 vs GP107 : match en 14nm
3 - Spécifications complètes et Direct3D 12
4 - Les Radeon RX 460 : Asus, Gigabyte et Sapphire
5 - Les GeForce GTX 1050 et 1050 Ti : MSI et Zotac
6 - Protocole de test
7 - Performances théoriques : pixels
8 - Performances théoriques : géométrie
9 - Fréquences, GPU Boost et overclocking
10 - Consommation, efficacité énergétique
11 - Nuisances sonores et température GPU
12 - Benchmark : 3DMark Fire Strike et Time Spy
13 - Benchmark : Anno 2205
14 - Benchmark : Ashes of the Singularity
15 - Benchmark : Battlefield 4
16 - Benchmark : Crysis 3
18 - Benchmark : DOOM
19 - Benchmark : Dying Light
20 - Benchmark : Fallout 4
21 - Benchmark : Far Cry Primal
22 - Benchmark : Grand Theft Auto V
23 - Benchmark : Hitman
24 - Benchmark : Project Cars
25 - Benchmark : Rise of the Tomb Raider
26 - Benchmark : Star Wars Battlefront
27 - Benchmark : The Division
28 - Benchmark : The Witcher 3 Wild Hunt
29 - Récapitulatif des performances
30 - Multi-Resolution Shading : petit coup de boost
31 - Conclusion
Contenus relatifs
- [+] 09/05: AMD Ryzen 7 2700, Ryzen 5 2600 et I...
- [+] 04/05: Nvidia abandonne son GeForce Partne...
- [+] 27/04: AMD Vega 7nm en labo, Zen 2 échanti...
- [+] 26/04: Jim Keller rejoint... Intel !
- [+] 23/04: MAJ de notre test des Ryzen 7 2700X...
- [+] 19/04: AMD Ryzen 2700X et 2600X : Les même...
- [+] 19/04: 2008-2018 : tests de 62 processeurs...
- [+] 18/04: ASUS AREZ, l'effet GeForce Partner ...
- [+] 13/04: Les AMD Ryzen Pinnacle Ridge en pré...
- [+] 10/04: Nvidia : fin du support Fermi et 32...