
AMD Radeon RX 480 8 Go : 14nm et Polaris en test



Polaris 10 : 5.7 milliards de transistors en 14 nm
Ce n'est pas par le haut de gamme qu'AMD a décidé de débuter l'utilisation du process 14nm, mais bien par le milieu de gamme avec une puce relativement petite. Pour plus de clarté, AMD lui a attribué un nom commercial, Polaris 10, qui fait clairement référence à sa génération. Un nom de code traditionnel existe également et est notamment utilisé en interne par ses partenaires. Il s'agit d'Ellesmere, en référence à une île comme pour les précédents GPU AMD.
A noter que s'attaquer à un nouveau process avec une puce milieu de gamme n'est pas inédit dans le chef d'AMD. Il y a un précédent avec la Radeon HD 4770 et le GPU RV740 qui a inauguré le 40nm avant que la génération HD 5000 ne le généralise.
Les GPU Polaris 10, et son petit frère le Polaris 11, sont fabriqués par GlobalFoundries dans sa nouvelle usine américaine sur base d'un process 14nm LPP développé par Samsung. Tout comme le 16nm FF+ exploité par Nvidia pour les GeForce GTX 10, ce process fait appel à des transistors de type FinFET ("transistors 3D") qui permettent de réduire les courants de fuite et la tension. Lors d'une présentation à laquelle nous avons assisté, un représentant de GlobalFoundries a expliqué que ce process 14nm LPP avait un avantage de 8% sur la concurrence au niveau de la densité.
 Polaris P10 est interfacé en 256-bit.
Polaris P10 est interfacé en 256-bit.Avant de rentrer dans les détails de son architecture, un petit rappel s'impose pour situer le Polaris 10 parmi les GPU récents :
- GP100 : 15.3 milliards de transistors pour 610 mm²
- Fiji : 8.9 milliards de transistors pour 598 mm²
- GM200 : 8.0 milliards de transistors pour 601 mm²
- GP104 : 7.2 milliards de transistors pour 314 mm²
- GK110 : 7.1 milliards de transistors pour 561 mm²
- Hawaii : 6.2 milliards de transistors pour 438 mm²
- Polaris 10 : 5.7 milliards de transistors pour 232 mm²
- GM204 : 5.2 milliards de transistors pour 398 mm²
- Tonga : 5.0 milliards de transistors pour 368 mm²
- GP106 : ???
- GK104 : 3.5 milliards de transistors pour 294 mm²
- Polaris 11 : ???
- GM206 : 2.9 milliards de transistors pour 228 mm²
- Pitcairn : 2.8 milliards de transistors pour 212 mm²
- GK106 : 2.5 milliards de transistors pour 214 mm²
- Bonaire : 2.1 milliards de transistors pour 158 mm²
Avec 232 mm², Polaris 10 est clairement un GPU milieu de gamme, qui s'inscrit dans la lignée de Pitcairn, qui était lui-même le milieu de gamme lors de l'introduction du 28nm (HD 7800). Entre temps AMD a sorti Tonga sur ce segment, un GPU un peu plus gros que Polaris P10 va venir remplacer avantageusement en étant à la fois plus petit et un peu plus complexe.
Le passage au 14 nm permet évidemment de faire exploser la densité de transistors par rapport au 28 nm. Il ne faut cependant pas se fier à ces chiffres qui sont plus des noms commerciaux des procédés de fabrication que des mesures de la géométrie qui définissent leur densité. Ainsi, contrairement à ce qui a pu être vrai par le passé, le 14 nm ne permet pas de quadrupler le nombre de transistors par mm² par rapport au 28 nm. Ces technologies sont très complexes et la densité réelle est déterminée par de nombreux paramètres qui dépassent le cadre de cet article. Voici les densités relevées sur quelques GPU :
- Polaris 10 : 24.6 millions de transistors par mm²
- Tonga : 13.6 millions de transistors par mm²
- Pitcairn : 13.2 millions de transistors par mm²
- GP104 : 22.9 millions de transistors par mm²
- GM204 : 13.1 millions de transistors par mm²
- GM206 : 12.7 millions de transistors par mm²
La densité est un petit peu plus élevée sur les plus gros GPU, probablement parce qu'une partie des E/S (entrées/sorties, I/O) à faible densité est identique et représente moins d'espace en proportion alors qu'à l'inverse ils intègrent en général plus de mémoire qui représente des structures plus denses, nous n'avons donc pas inclus les énormes GP100 et Fiji dans cette comparaison.
Entre le GP104 et le GM204, la densité progresse de 75%. Du côté d'AMD, entre le Polaris 10 et Tonga elle progresse de 81%, des chiffres qui semblent confirmer le petit avantage au niveau de la densité entre le 14nm LPP et le 16nm FF+, même s'il y a de nombreux autres paramètres à prendre en compte.
Polaris 10 : 36 CU et bus 256-bit
Passons maintenant à la configuration retenue par AMD pour ses GPU Polaris qui restent basés sur l'architecture GCN (Graphics Core Next) introduite fin 2011. Nous avons pour cela repris le schéma traditionnel fournis par AMD, corrigé d'une petite erreur et que nous avons modifié pour vous proposer une comparaison avec Tonga et Polaris 11 :
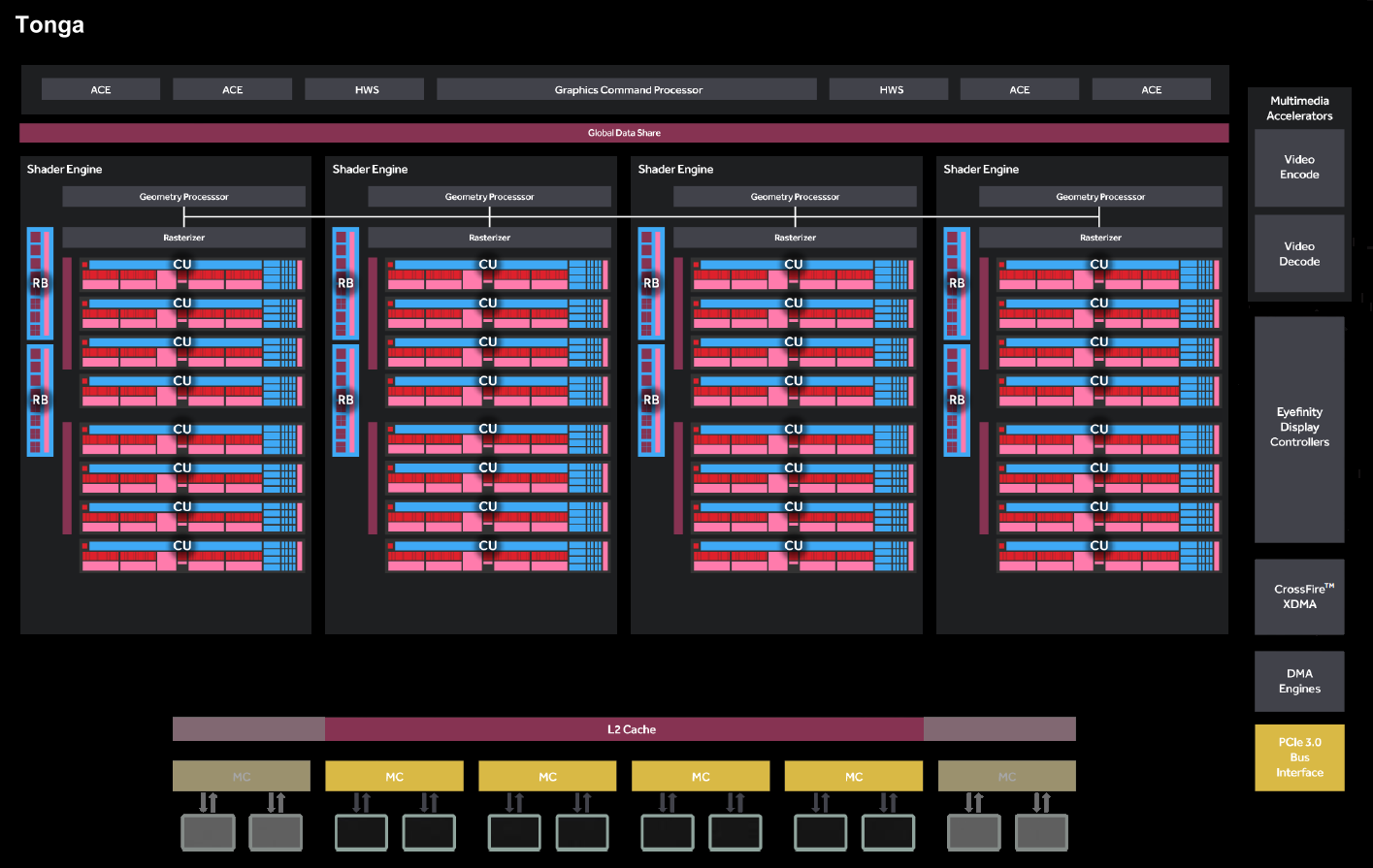
[ Tonga ] [ Polaris 10 ] [ Polaris 11 ]
Tout comme pour Tonga, Hawaii et Fiji, AMD a opté pour 4 Shader Engines pour Polaris 10. La différence entre ces puces concerne le nombre de Compute Units (CU) par Shader Engine : 16 pour Fiji, 11 pour Hawaii, 9 pour Polaris 10 et 8 pour Tonga. Rappelons que chaque CU embarque 64 unités de calcul ainsi que 4 unités de texturing. Par rapport à Tonga, la progression à ce niveau est ainsi de 12.5% à fréquence égale.
En passant de Tonga à Polaris 10, AMD a par contre réduit le bus mémoire de 384 à 256-bit mais cette possibilité n'a été exploitée sur aucune carte graphique : les R9 285, 380 et 380X se contentent toutes d'un bus de 256-bit. En pratique la configuration mémoire est ainsi similaire mais l'interface GDDR5 a été prévue pour monter plus haut en fréquence et le cache L2 par contrôleur mémoire de 64-bit a été multiplié par 4 pour atteindre 2 Mo.
De son côté Polaris 11 est un demi Polaris 10 avec un CU de moins par Shader Engine. Il se contente d'un petit bus de 128-bit mais là aussi capable de monter plus haut en fréquence et associé à un cache L2 de 1 Mo.
Voici pour comparaisons les spécificités des GPU GCN :
- Fiji : GCN 3, 64 CU, 4 triangles par cycle, 64 ROP, L2 2048 Ko, 4096 bits HBM
- Hawaii : GCN 2, 44 CU, 4 triangles par cycle, 64 ROP, L2 1024 Ko, 512 bits
- Polaris 10 : GCN 4, 36 CU, 4 triangles par cycle, 32 ROP, L2 2048 Ko, 256 bits
- Tonga : GCN 3, 32 CU, 4 triangles par cycle, 32 ROP, L2 768 Ko, 384 bits
- Tahiti : GCN 1, 32 CU, 2 triangles par cycle, 32 ROP, L2 768 Ko, 384 bits
- Pitcairn : GCN 1, 20 CU, 2 triangles par cycle, 32 ROP, L2 512 Ko, 256 bits
- Polaris 11 : GCN 4, 16 CU, 2 triangles par cycle, 16 ROP, L2 1024 Ko, 128 bits
- Bonaire : GCN 2, 14 CU, 2 triangles par cycle, 16 ROP, L2 512 Ko, 128 bits
- Cape Verde : GCN 1, 10 CU, 1 triangle par cycle, 16 ROP, L2 512 Ko, 128 bits
- Oland : GCN 1, 6 CU, 1 triangle par cycle, 8 ROP, L2 256 Ko, 128 bits
Pour accompagner un bus mémoire qui reste à 256-bit, comme Tonga, mais qui est divisé par 2 par rapport aux 512-bit de Hawaii et à la Radeon R9 290 à laquelle AMD aime comparer la Radeon RX 480, il était important pour AMD de pouvoir tirer plus de bande passante effective par bit. Pour cela, en plus des interfaces mémoire retravaillées pour monter plus haut en fréquence (support de la GDDR5 jusque 8 Gbps) et du cache L2 quadruplé par contrôleur 64-bit, les techniques de compression du framebuffer ont été améliorées.


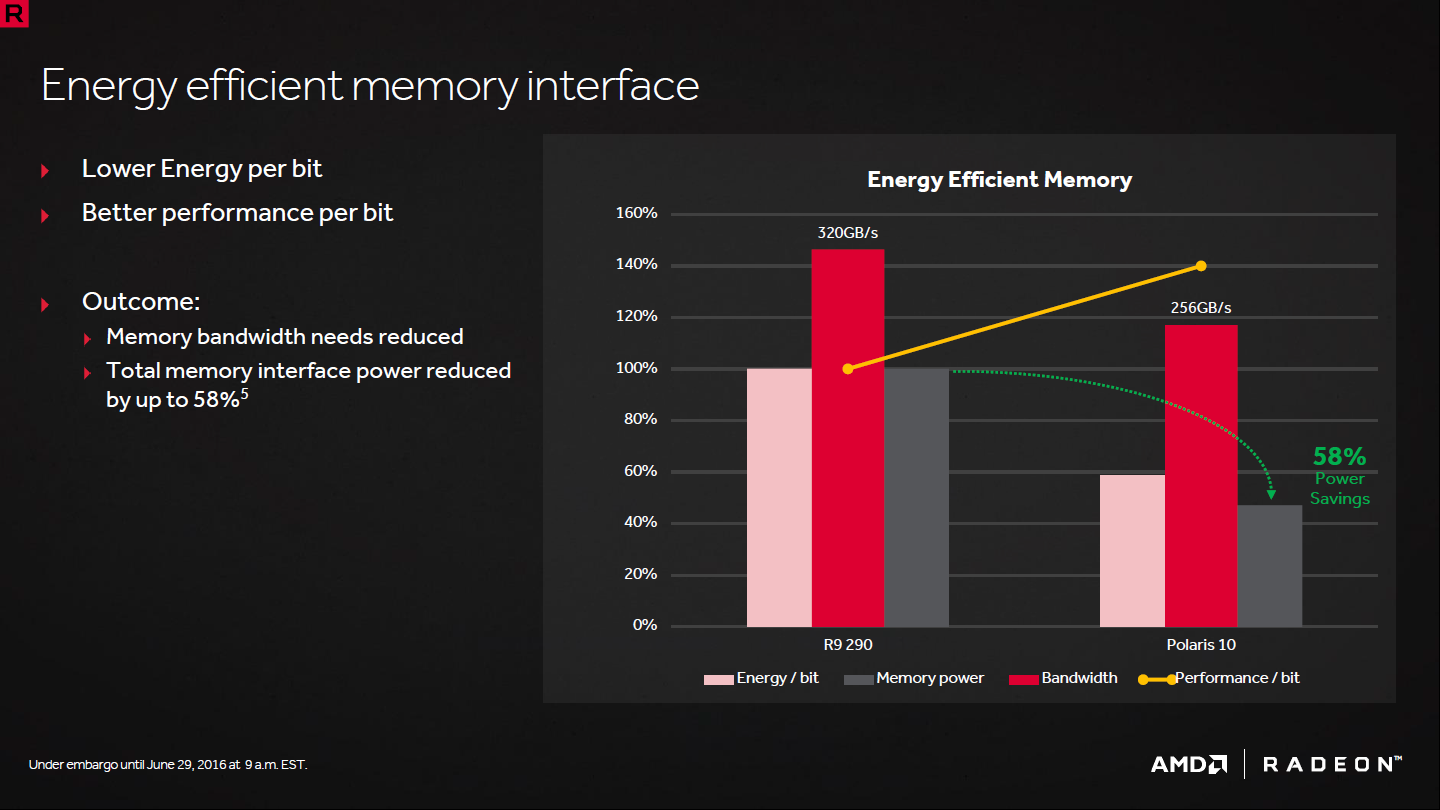
Pour être précis, il s'agit d'un codage différentiel des couleurs (delta color compression, DCC) qui représente une compression sans perte. Cette technique permet de réduire les besoins en bande passante mémoire en augmentant légèrement l'espace mémoire nécessaire.
Alors que la DCC des GPU Fiji et Tonga permettait de gagner près de 20%, cela monte à près de 40% pour les GPU Polaris 10 et 11 qui supportent les compressions de type 2:1, 4:1 et 8:1, comme le fait Nvidia avec les GPU Pascal même si nous ne savons pas si les implémentations des deux spécialistes du GPU sont aussi efficaces l'une que l'autre.
D'après les chiffres communiqués par AMD, une Radeon R9 290X, qui ne dispose pas de DCC, atteint une bande passante maximale en pratique de 263 Go/s alors que la RX 480 monte à 251 Go/s grâce à la DCC, à la fréquence en hausse et au cache L2 plus important.
Toujours selon les chiffres communiqués par AMD, l'interface mémoire de Polaris 10 ne consommerait que 42% de l'énergie nécessaire à celle de Hawaii, ce qui est également lié au passage au 14nm FinFET. A largeur de bus identique, la consommation est ainsi légèrement inférieure pour Polaris alors que la GDDR5 exploitée monte fortement en fréquence. Attention, AMD n'a probablement pas choisi la comparaison avec la R9 290X par hasard, celle-ci utilisant de la mémoire faiblement cadencée (5 Gbps) au vu de sa tension de 1.5V. En pratique il existe de la GDDR5 jusqu'à 6 Gbps à 1.35V alors que la RX 480 8 Go utilise de la GDDR5 8 Gbps à 1.5V.
FinFET, fréquence et réduction de la tension
Un changement majeur de procédé de fabrication apporte en général plusieurs bénéfices, parmi lesquels une montée de la fréquence et donc des performances qui sur de nombreux aspects en dépendent directement. C'est bien entendu le cas ici pour la 14nm LPP de GlobalFoundries :
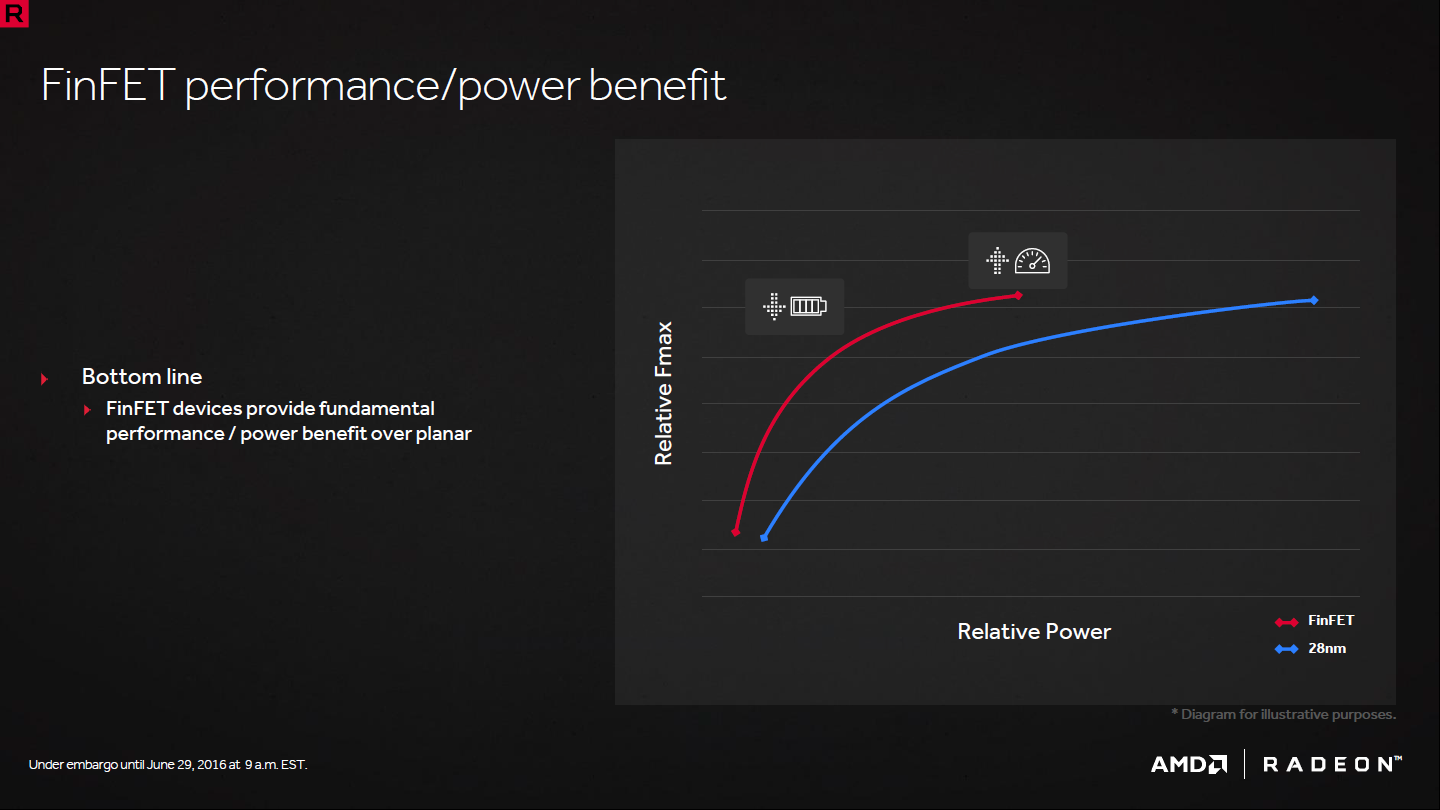
Il faut cependant rappeler que l'on ne peut pas tout avoir. Il est possible d'exploiter le process pour réduire la consommation à fréquence égale (le 14nm LPP est annoncé 65% plus efficace), pour augmenter la fréquence à consommation égale (il est alors question d'une fréquence 55% supérieure) ou pour trouver un compromis plus intéressant entre fréquence et consommation.
Alors qu'en passant au 16nm FF+ Nvidia a pu faire profiter ses GPU Pascal d'un bond de 40% au niveau de leur fréquence (de 1200 à 1700 MHz), du côté d'AMD les GPU Polaris se contentent d'une évolution de 20% en passant au 14nm LPP (de 1050 à 1250 MHz).
En conclure que l'un ou l'autre process est plus performant sur base de ces chiffres serait cependant un raccourci trop rapide. L'architecture est différente et peut avoir été plus ou moins optimisée pour favoriser la montée en fréquence. Nvidia explique d'ailleurs avoir fortement travaillé cet aspect. Ceci étant dit il n'est probablement pas délirant de penser que si le 14nm LPP autorise une densité un peu supérieure, il est un petit peu moins performant que le 16nm FF+.
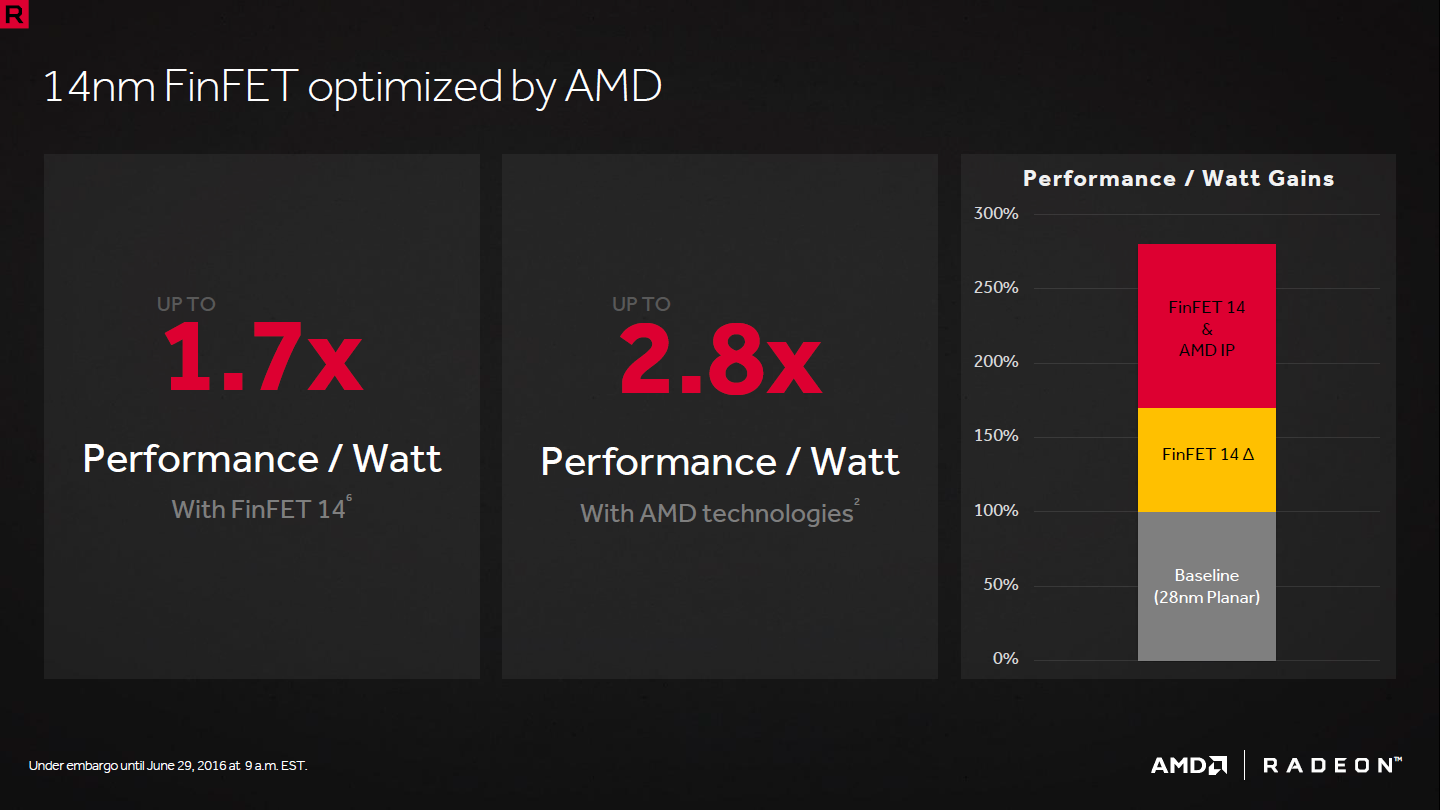
AMD explique ensuite que la 14nm LPP permet d'augmenter l'efficacité énergétique de 70% d'après des mesures internes spécifiques. Mais couplé aux améliorations de l'architecture, la progression monterait à 180%. Un bond énorme qu'il convient de relativiser.
Il s'agit en effet d'une comparaison très favorable entre la future RX 470 limitée à 110W et la R9 270X qui monte à 180W, sur base de mesures de performances dans 3DMark Fire Strike, Ashe of the SIngularity, Hitman et Overwatch avec des paramètres qui évitent des options gourmandes en bande passante telles que le MSAA. Entre une RX 480 et une R9 290, AMD revoit ce chiffre à la baisse et annonce une progression moitié moindre avec 90% de mieux, ce qui reste une évolution importante.
Pour accompagner les transistors FinFET et atteindre ces chiffres, AMD exploite plusieurs techniques, dont certaines sont également en action sur ses APU :
- Adaptive clocking
- Adaptive voltage and frequency scaling
- Boot time power supply calibration
- Adaptive aging compensation
- Multi-bit flip-flop

Que se cache derrière tout cela ?
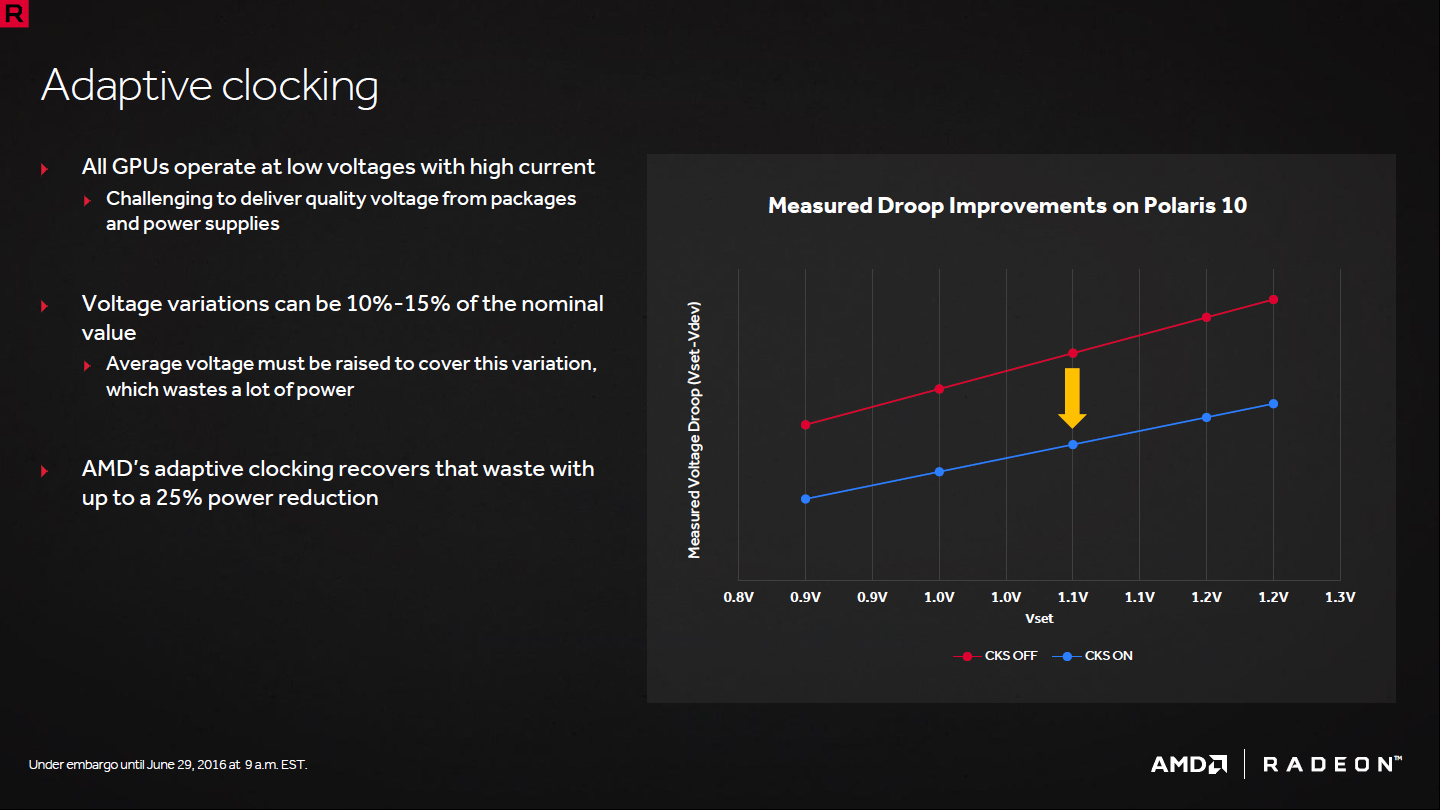
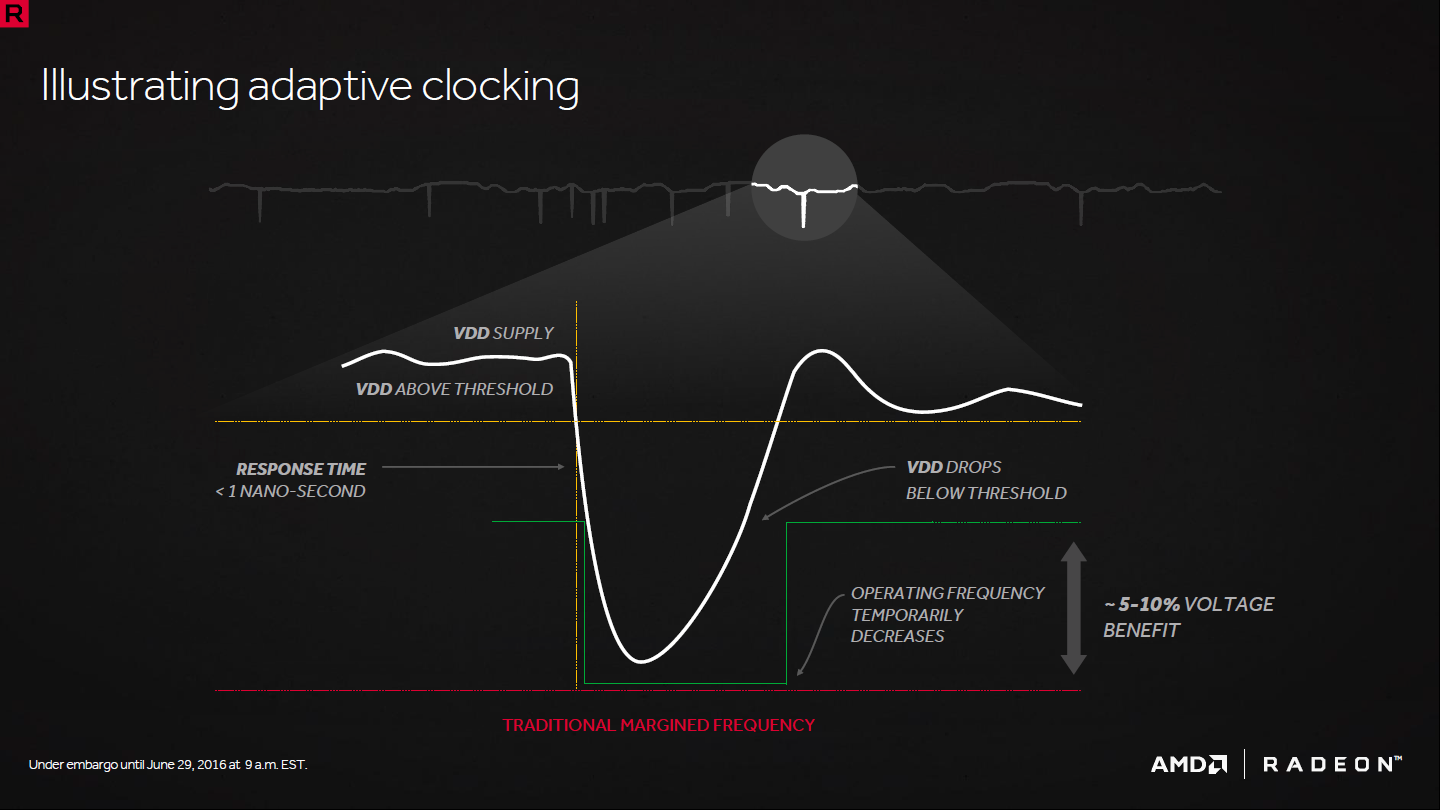
L'adaptative clocking tout d'abord est une technique qui permet de gérer les petites baisses de tension sans devoir prendre en compte de marge de sécurité importante. Comme vous le savez, les étages d'alimentation délivrent rarement une tension stable, ce qui est rendu difficile par l'intensité élevée délivrée aux GPU. Cette tension varie constamment avec de petites baisses qui peuvent atteindre 10 à 15% selon AMD. Grâce à des capteurs de tension internes, le GPU peut réduire brièvement sa fréquence avec un délai d'une nanoseconde dès qu'il détecte une petite baisse de la tension. De quoi pouvoir réduire la marge de sécurité et la tension de 5 à 10% avec une économie d'énergie conséquente à la clé.
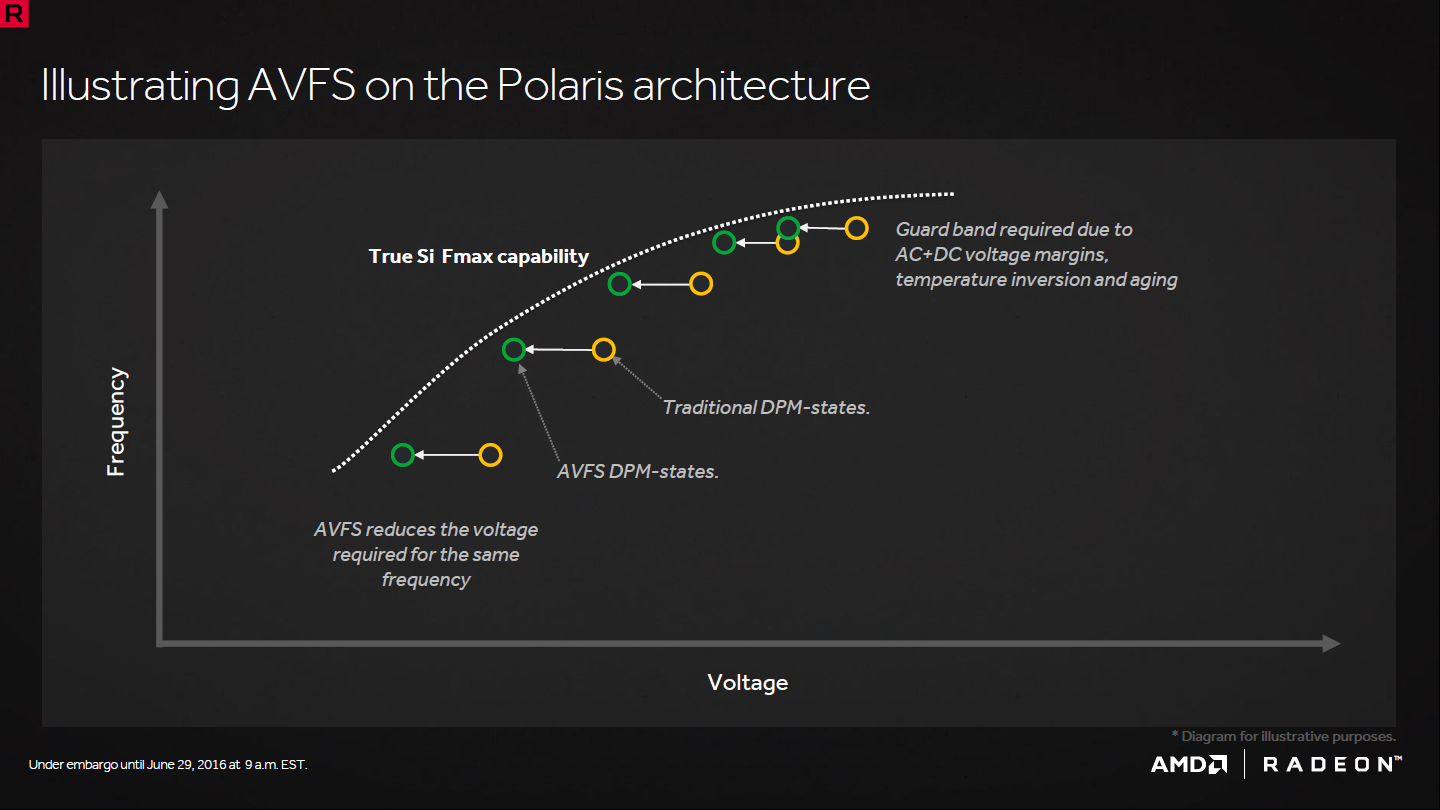
L'adaptive voltage and frenquency scaling (AVFS) permet pour sa part de tirer le meilleur de chaque puce produite en leur donnant la capacité d'autodéterminer la tension idéale pour chaque p-state. Cela se fait via l'ajoute de capteurs de fréquence aux capteurs de consommation et de température. Au lieu d'appliquer une tension identique à toutes les puces, ou un nombre limité de variations, la tension peut être adaptée plus finement et se rapprocher de la tension minimale à laquelle chaque puce peut fonctionner.
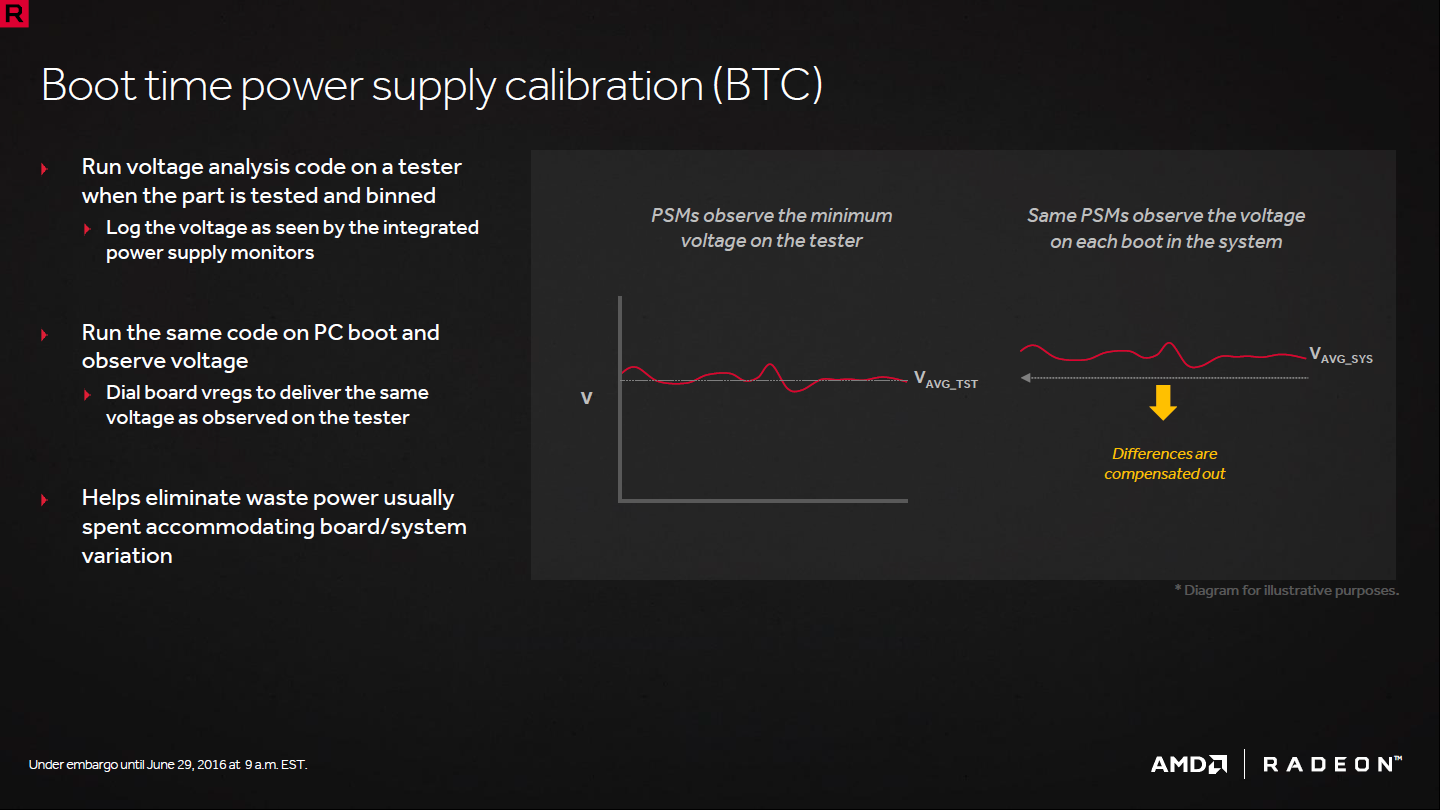
Le boot time power supply calibration (BTC) est également une technique d'auto-calibration mais cette fois plutôt de la carte dans son ensemble que de la puce. Lorsqu'un GPU demande une tension particulière au contrôleur de son étage d'alimentation, il reçoit rarement exactement la valeur demandée. Pour éviter de prendre une marge de sécurité trop importante à ce niveau, à chaque boot, le GPU va vérifier la tension exacte sur quelques points de repère et compenser la différence. Là aussi il s'agit de se rapprocher de la tension minimale de fonctionnement en fournissant une information de plus à l'AVFS.
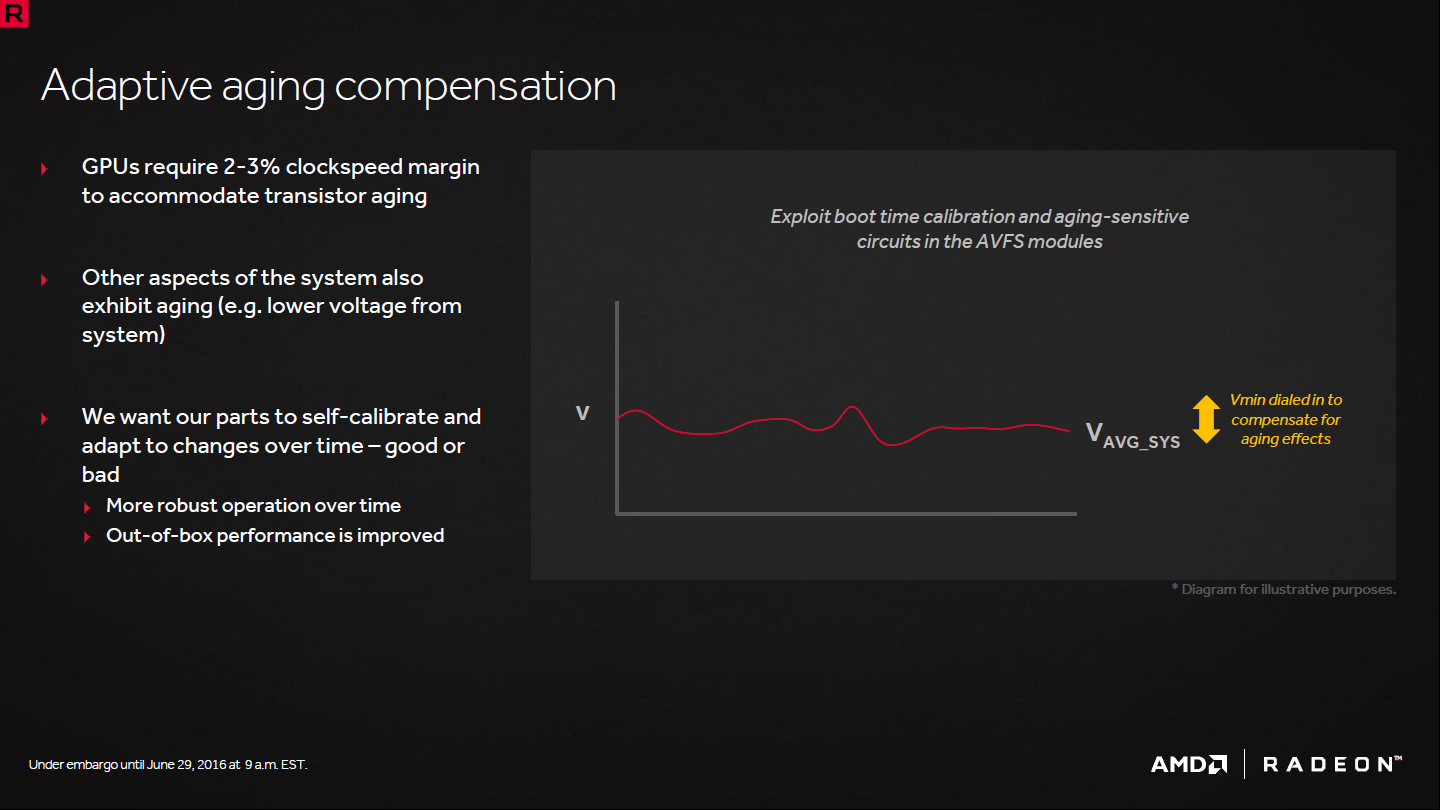
L'adaptive aging compensation reste dans la même optique. Cette fois il s'agit d'éviter de prendre une marge de sécurité par rapport au vieillissement des transistors ou des composants de l'étage d'alimentation qui peuvent se détériorer légèrement. A la place le GPU va se tester et s'auto-calibrer en apportant une information de plus à l'AVFS. Après quelques années, la tension moyenne pourrait par exemple être très légèrement supérieure.
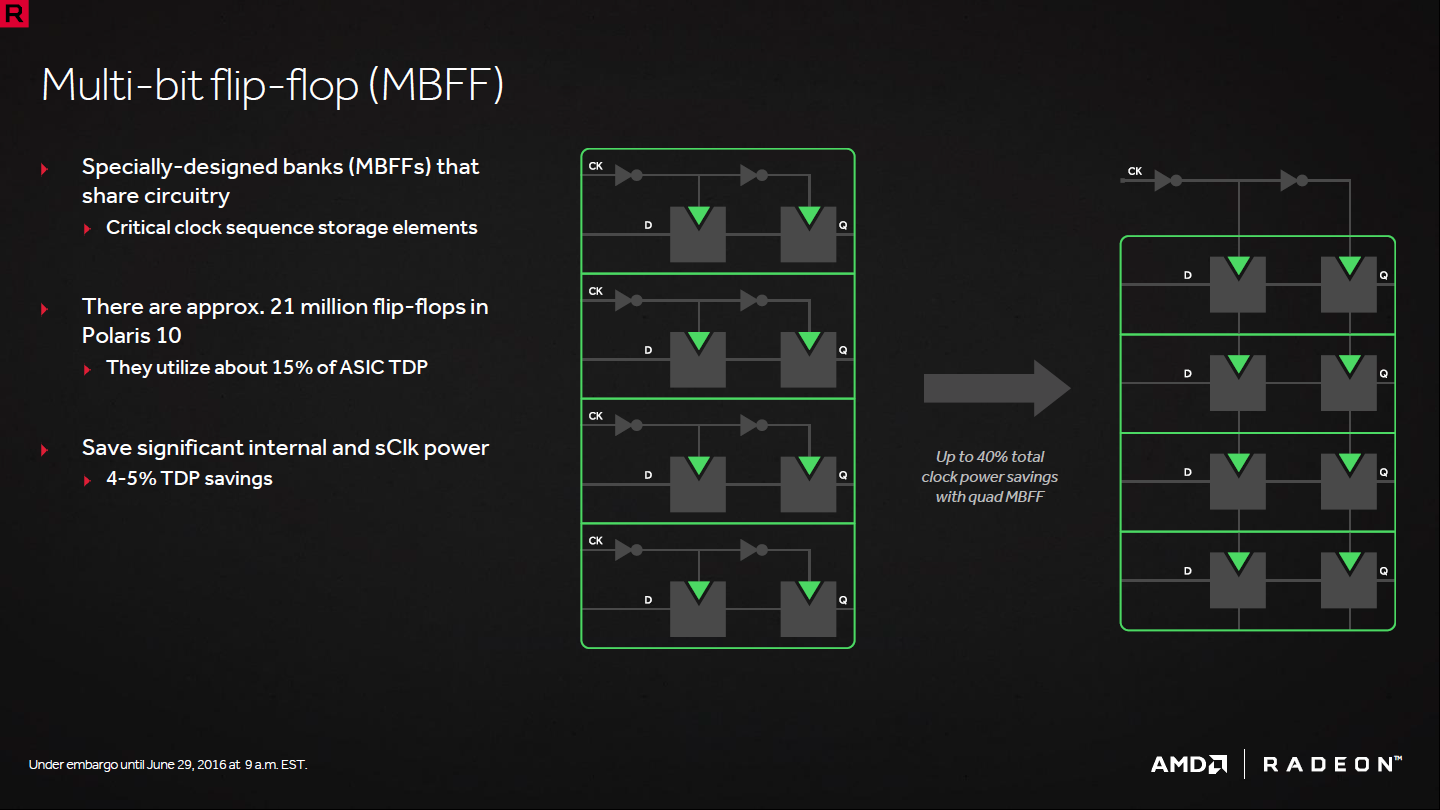
Enfin, le multi-bit flip-flop est une implémentation plus efficaces des flip-flops, ou bascules en français, qui sont de petits circuits utilisés pour mémoriser un état le temps d'un cycle d'horloge. Ils sont présents en masse, AMD parle de 21 millions de bascules pour Polaris 10 qui représentent 15% de la consommation du GPU. Polaris exploite des structures plus complexes qui combinent plusieurs bascules avec une seule source de distribution du signal d'horloge pour un gain qui peut atteindre 4 à 5% au niveau de la consommation du GPU.

Le 14nm LPP combiné à toutes ces techniques de réduction de la consommation laisse augurer d'une excellente efficacité énergétique pour Polaris. Et pourtant, comme nous allons le voir, la Radeon RX 480 est décevante sur ce point. Pourquoi ? Entre la prestation réelle du process, de l'architecture GCN et de ces optimisations, il est difficile de dégager un coupable.
Par ailleurs, chaque dérivé de Polaris, comme de tout autre GPU est configuré de manière à atteindre certains objectifs. Il est possible que la Radeon RX 480 ait été configurée pour pousser Polaris 10 le plus haut possible en terme de fréquence, quitte à sacrifier la consommation.
AMD nous a d'ailleurs indiqué que tous les leviers n'ont pas été activés sur la RX 480, sans préciser si c'est par choix stratégique ou par manque de temps. Par exemple, le boot time power supply calibration et l'anti aging compensation ne sont pas actifs sur cette carte graphique. Ils pourraient par contre l'être sur d'autres ou sur des déclinaisons mobiles.
2 - Polaris 10 : 5.7 milliards de transistors en 14 nm
3 - Polaris 10 : GCN 4, affichage et vidéo
4 - Spécifications et Direct3D 12
5 - La Radeon RX 480 de référence, Sapphire et XFX
6 - Protocole de test
7 - Performances théoriques : pixels
8 - Performances théoriques : géométrie
9 - Consommation, efficacité énergétique
10 - Nuisances sonores, températures, photos IR
11 - Benchmark : 3DMark Fire Strike
12 - Benchmark : Anno 2205
13 - Benchmark : Ashes of the Singularity
14 - Benchmark : Battlefield 4
15 - Benchmark : Crysis 3
16 - Benchmark : DiRT Rally
18 - Benchmark : Dying Light
19 - Benchmark : Evolve
20 - Benchmark : Fallout 4
21 - Benchmark : Far Cry Primal
22 - Benchmark : Grand Theft Auto V
23 - Benchmark : Hitman
24 - Benchmark : Project Cars
25 - Benchmark : Rise of the Tomb Raider
26 - Benchmark : Star Wars Battlefront
27 - Benchmark : The Division
28 - Benchmark : The Witcher 3 Wild Hunt
29 - Récapitulatif des performances
30 - Overclocking : quelle marge pour la RX 480 ?
31 - Conclusion
Contenus relatifs
- [+] 07/06: L'Ethereum vide les stocks de RX 58...
- [+] 16/03: AMD RX 580, 570 et 560 en vue
- [+] 14/03: Bundle AMD pour les FX-6 et FX-8
- [+] 25/11: AMD dégaine ses offres de fin d'ann...
- [+] 29/07: RX 480 Sapphire Nitro+ vs GTX 1060 ...
- [+] 21/07: Les Sapphire RX 480 Nitro+ en appro...
- [+] 08/07: RX 480 et pilotes 16.7.1: quelle di...
- [+] 06/07: RX 480 et conso : vers un nouveau p...
- [+] 05/07: La Radeon RX 480 4 Go existe-t-elle...
- [+] 29/06: AMD Radeon RX 480 8 Go : 14nm et Po...