
Nvidia GeForce GTX 750 Ti & GTX 750 : Maxwell fait ses débuts
Publié le 26/02/2014 par Damien Triolet



Le SMM en détailDans sa communication globale, Nvidia présente Kepler comme architecturé autour de SMX monolithiques face à Maxwell dont les SMM ont été partitionnés pour plus d'efficacité :
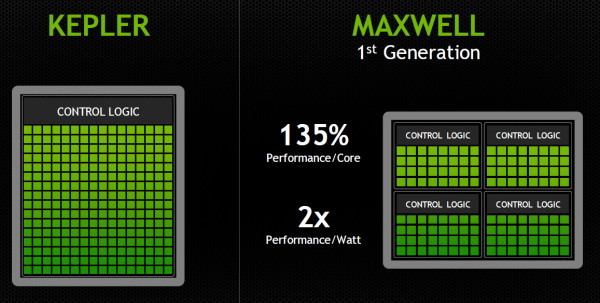
Cette présentation des choses n'est cependant pas tout à fait correcte. Plus que d'une réalité technique, il s'agit en fait d'une histoire technique simplifiée, facile à vendre et préparée par les services de marketing et de communication de Nvidia pour aider les journalistes à illustrer leurs différents articles, quitte à les induire en erreur. La réalité est différente et plus complexe puisque les SMX des GPU Kepler sont en fait eux-aussi partitionnés en 4, avec à chaque fois un fichier registre et des ordonnanceurs distincts.
Si les SMX des GPU Kepler sont déjà partitionnés en 4 comme les SMM Maxwell, la différence principale à leur niveau est alors à chercher du côté des ressources que se partagent ces partitions. Nvidia a en effet revu l'organisation interne des SMM de manière à augmenter leur rendement aussi bien énergétique que par unité de surface. Pour cela, le ratio d'unités de calcul par unité de texturing augmente, une évolution logique depuis quelques années qui permet de s'adapter aux algorithmes de rendu graphique de plus en plus complexe sur le plan arithmétique.
Ensuite, Nvidia se sépare de certains blocs d'unités de calcul qui en pratique étaient peu utilisés, ce qui fait mécaniquement augmenter le rendement des unités restantes. Au final nous passons de 24 flops par unité de texturing sur Kepler (excepté GK208) à 32 flops par unité de texturing sur Maxwell, avec, qui plus est, une meilleure utilisation de cette puissance de calcul.
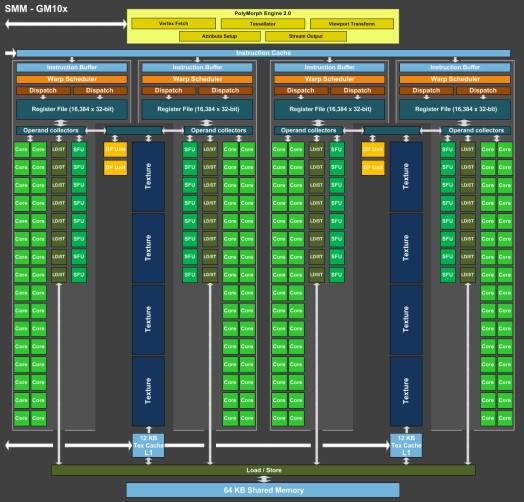
Pour représenter cela plus en détail, nous avons modifié des diagrammes d'architecture de Nvidia de façon à nous rapprocher de la réalité, au mieux de nos connaissances actuelles des différentes architectures :
| [ SMX GK110 ] [ SMX GK10x ] [ SMX GK20x ] [ SMM GM10x ] |
En plus grand :
Comme le montrent ces illustrations, Nvidia a en réalité simplifié le SMM sur 2 points principaux. Premièrement, les blocs de 4 unités de texturing ont été mis en commun par paire de partitions, comme c'était déjà le cas sur le GK208 et le GK20A (Tegra K1) et contrairement aux autres GPU Kepler pour lesquels chaque partition d'un SMX dispose de son propre bloc. C'est ce point qui fait augmenter automatiquement le ratio d'unités de calcul par unité de texturing. Ces dernières sont gourmandes notamment parce qu'elles ont besoin de voies d'accès royales au sous-système mémoire du GPU.
Deuxièmement, le nombre d'unités de calcul est réduit, mais dans une moindre mesure. Pour rappel, chaque paire de partitions d'un SMX Kepler dispose de trois unités vectorielles SIMD 32-way (ou SIMT en langage Nvidia), capables de traiter les opérations simples de type FMA, FADD, FMUL etc. Une unité SIMD 32-way correspond à "32 CUDA cores" dans le langage marketing officiel, une notion du "core" bien entendu questionnable, mais ce n'est pas nouveau. Nous présumons que l'une de ces unités SIMD est rattachée à une partition et donc à un ordonnanceur particulier alors que la troisième est partagée. Il est cependant possible que physiquement les 3 SIMD 32-way soient en fait partagées, Nvidia ne veut pas communiquer ce détail, mais dans tous les cas il semble évident que compilateurs et ordonnanceurs ne profitent pas réellement de cette flexibilité, d'où notre supposition.
Exploiter ces unités de calcul SIMD 32-way supplémentaires s'est avéré difficile sur Kepler, probablement parce que le fichier registre n'offre pas suffisamment de bande passante et/ou de flexibilité au niveau des accès à ses différentes banques. Il est dès lors difficile de pouvoir obtenir toutes les opérandes nécessaires pour alimenter l'ensemble de ces unités, et en pratique elles le sont rarement. D'après les chiffres communiqués par Nvidia, ces 50% d'unités de calcul supplémentaires, qui permettent d'afficher une puissance de calcul brute en nette hausse, n'apportent qu'un gain pratique d'un peu plus de 10%.
C'est donc logiquement que Nvidia a supprimé cette SIMD 32-way supplémentaire des SMM. Ainsi quand Nvidia annonce un rendement par "cur" en hausse de 35% pour Maxwell, cela ne veut pas dire que les unités de calcul principales ont été améliorées, mais que ce bloc mal utilisé a été supprimé. Le travail de l'ordonnanceur et du compilateur s'en trouve simplifié, ce qui permet des gains énergétique du côté du premier et la possibilité de pousser plus loin certaines optimisations du côté du second.
Par ailleurs, Nvidia laisse penser - mais sans vouloir le confirmer clairement - que les SIMD SFU 16-way d'assistance pour le traitement des opérations spéciales, qui déchargent les SIMD 32-way principales lorsqu'il s'agit de traiter des opérations de type SINCOS, EXP, LOG etc., étaient partagées sur Kepler mais ont été scindées en deux sur Maxwell. Chacune des partitions du SMM disposerait ainsi de sa propre SIMD SFU 8-way.
Les unités LD/ST (load/store) qui s'occupent des chargements / écritures de données (typiquement des registres supplémentaires via le L1 quand le fichier registre principal déborde, de la mémoire partagée ou des constantes) ont elles aussi été scindées en deux et liées à une partition particulière. Nvidia nous précise cependant que seule la première partie de ces unités, celle qui initie les commandes, est locale aux partitions, l'autre partie de ces unités étant globale et plus proche du sous-système mémoire.
Enfin, Nvidia nous indique que dans le SMM, les unités de calcul double précision sont distinctes des SIMD 32-way principales et se trouvent sur le côté, ce qui nous laisse penser qu'il s'agit d'un bloc de 2 unités 64-bit partagé entre 2 partitions. Le débit en double précision est donc équivalent à 1/32ème du débit en simple précision, un ratio inférieur à celui de 1/24ème des SMX Kepler et qui par ailleurs ne prend pas en compte le fait que les SFU n'assistent pas les unités principales en 64-bit.
Au final, en passant du SMX au SMM nettement plus petit, Nvidia a donc supprimé la moitié des unités de texturing, la moitié des unités de calcul 64-bit et un tiers des unités de calcul 32-bit. Malgré cela, en ne conservant que le plus utile aux charges modernes, le SMM conserverait des performances proches de celles du SMX, de l'ordre de 90% selon Nvidia. Bien entendu, en jeu et quand le texturing prend beaucoup d'importance, ce nouveau SMM pourra être amené à se contenter de 50% des performances du SMX.
Sommaire
1 - Introduction
2 - Maxwell 1st gen: 28nm, aperçu global
3 - Maxwell 1st gen: le SMM en détails
4 - Maxwell 1st gen: du mieux pour le GPU computing
5 - Performances théoriques : pixels
6 - Performances théoriques : géométrie
7 - Spécifications, la GTX 750 Ti de référence
8 - Consommation, efficacité énergétique
9 - Protocole de test
10 - Benchmark : Anno 2070
11 - Benchmark : Batman Arkham Origins
2 - Maxwell 1st gen: 28nm, aperçu global
3 - Maxwell 1st gen: le SMM en détails
4 - Maxwell 1st gen: du mieux pour le GPU computing
5 - Performances théoriques : pixels
6 - Performances théoriques : géométrie
7 - Spécifications, la GTX 750 Ti de référence
8 - Consommation, efficacité énergétique
9 - Protocole de test
10 - Benchmark : Anno 2070
11 - Benchmark : Batman Arkham Origins
12 - Benchmark : Battlefield 4
13 - Benchmark : Crysis 3
14 - Benchmark : Far Cry 3
15 - Benchmark : GRID 2
16 - Benchmark : Hitman Absolution
17 - Benchmark : Metro Last Light
18 - Benchmark : Splinter Cell Blacklist
19 - Benchmark : Tomb Raider
20 - Récapitulatif des performances
21 - Overclocking
22 - Conclusion
13 - Benchmark : Crysis 3
14 - Benchmark : Far Cry 3
15 - Benchmark : GRID 2
16 - Benchmark : Hitman Absolution
17 - Benchmark : Metro Last Light
18 - Benchmark : Splinter Cell Blacklist
19 - Benchmark : Tomb Raider
20 - Récapitulatif des performances
21 - Overclocking
22 - Conclusion
Vos réactions
Contenus relatifs
- [+] 08/03: GDC: Nvidia parle du Tile Caching d...
- [+] 01/08: Tile rendering pour Maxwell et Pasc...
- [+] 24/03: GDC: VR: Nvidia Multi-Res Shading e...
- [+] 23/03: GDC: Async Compute : ce qu'en dit N...
- [+] 22/09: Nvidia dévoile une 'vraie' GTX 980 ...
- [+] 09/09: Les GTX 900 supportent-elles correc...
- [+] 22/08: Nvidia GeForce GTX 950, MSI Gaming ...
- [+] 22/07: Nvidia baisse le prix de la GTX 750...
- [+] 02/06: Computex: Nvidia: pas besoin de wat...
- [+] 01/06: Nvidia GeForce GTX 980 Ti 6 Go : la...