
Kaveri : AMD A10-7850K et A10-7700K en test



La HSALa HSA, ou Heterogeneous System Architecture, a pour mission de rendre le calcul hétérogène plus efficace et plus simple à exploiter du point de vues des développeurs. Par calcul hétérogène, il faut comprendre ici l'utilisation combinée de différents types de processeur pour remplir une tâche donnée, par exemple des curs CPU et GPU.
Pour rappel, la HSA est un standard ouvert qui découle d'une initiative d'AMD mais qui rassemble maintenant un large pan de l'industrie à travers la HSA Foundation. ARM, Imagination Technologies, Mediatek, Qualcomm, Samsung, Texas Instruments ont ainsi répondu à l'appel d'AMD pour contribuer à définir la HSA, contrairement à Intel et Nvidia qui ont préféré bouder l'initiative.
Compte tenu de la diversité de ces acteurs, la HSA peut englober une large variété de curs CPU (x86, ARM, MIPS), GPU (Radeon GCN, Adreno, PowerVR ) ou encore de DSP. Les spécifications de la HSA font en sorte de permettre à tout ce petit monde, appelés "agents HSA" de pouvoir travailler ensemble à travers quelques points communs tant au niveau matériel que logiciel. La HSA n'est pas un langage mais plutôt une manière plus stricte d'implémenter le support d'un langage donné, par exemple OpenCL.
Tous les agents HSA doivent respecter la même mécanique de gestion des files d'attente et de lancement des tâches ainsi que le même modèle mémoire. Deux variantes existent, Small Machine Model et Large Machine Model qui se distinguent principalement par le support ou non du 64-bit. Un APU tel que Kaveri supporte bien entendu le second.

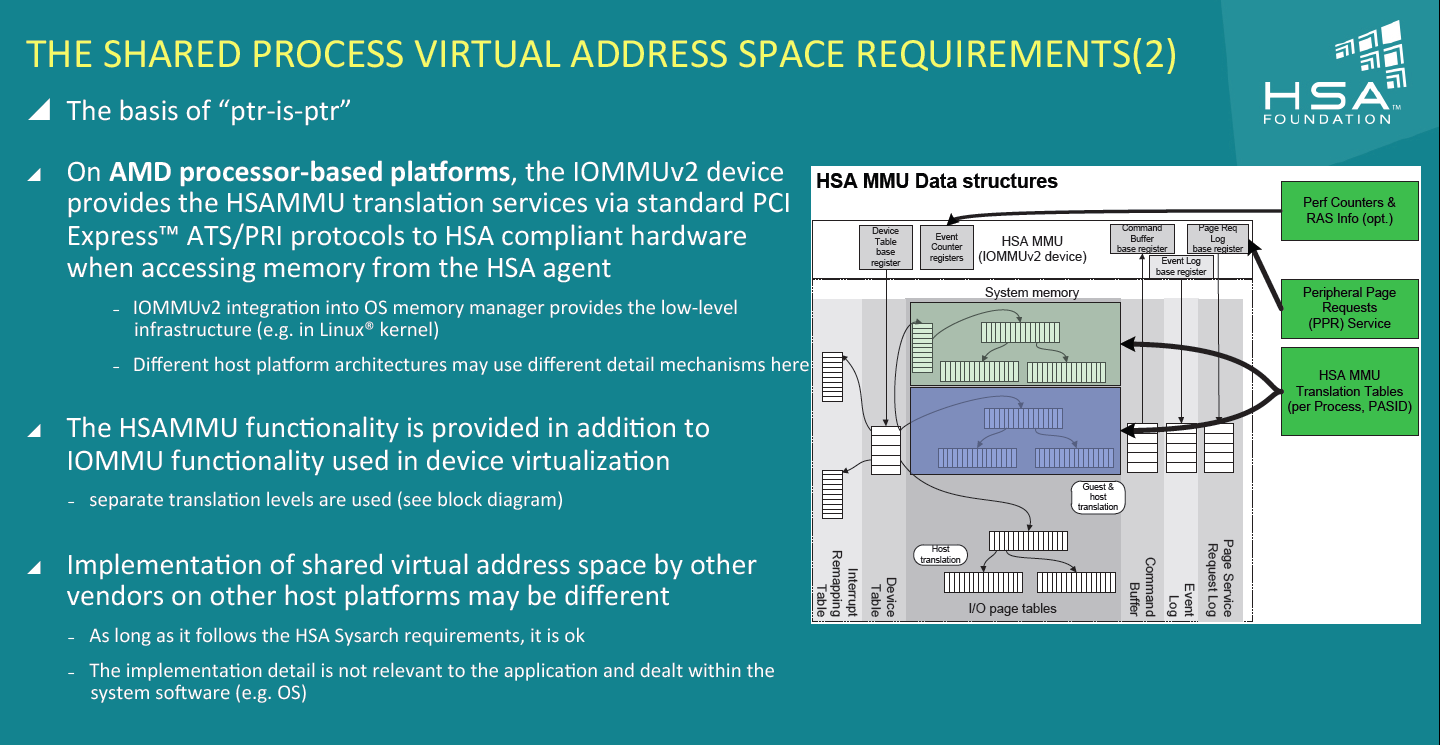

Le modèle mémoire est probablement le premier point essentiel de la HSA. Il impose le support d'une mémoire virtuelle unifiée qui permet aux différents agents de partager des données simplement, sans copies inutiles, coûteuses en termes de performances (et de consommation) et qui rendent le code moins naturel pour le développeur. Pour tous les agents, un pointeur donné fait référence à la même zone mémoire, à laquelle ils peuvent tous accéder. Cela implique la mise en place de mécaniques de préservation de la cohérence des caches entre les différents agents pour éviter tout problème de synchronisation.


Pouvoir exécuter efficacement tout type de tâche via l'agent HSA le plus approprié est le second point essentiel. Les agents HSA doivent pour cela être tous capables de lancer de nouvelles tâches et de supporter de multiples files d'attente. Il revient alors au développeur et/ou au compilateur de profiter au mieux de cette flexibilité.


La HSA définit également la manière dont les agents HSA peuvent interagir avec d'autres agents non-HSA, un horodatage commun à la plateforme et une manière d'exposer la topologie du système.
La HSA par AMD et KaveriPour parler des différents points de la HSA, AMD utilise sa propre nomenclature, ce qui lui permet de préserver des marques pour des technologies qui reposent sur des standards ouverts. L'implémentation d'AMD de la mémoire virtuelle unifiée se nomme ainsi hUMA (Heterogeneous Unified Memory Architecture) alors que celle de la gestion des tâches se nomme hQ (Heterogeneous Queuing).
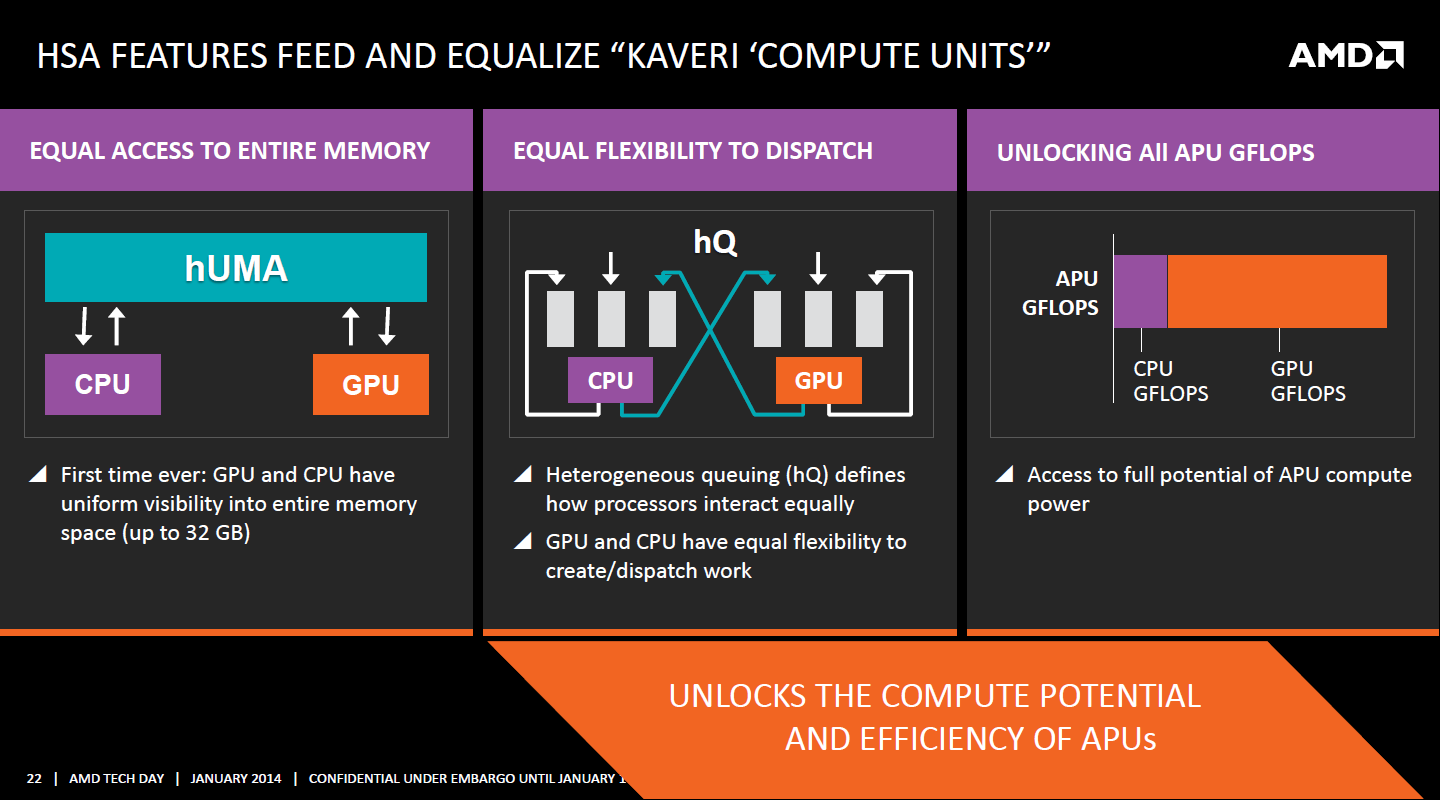
Kaveri est le premier APU d'AMD à implémenter complètement la HSA. Cette évolution s'est faite progressivement, à partir de Llano qui a implémenté des interfaces spéciales pour déplacer les données entre la partie CPU et GPU. Trinity/Richland a été un peu plus loin avec un northbridge unifié et l'arrivée de l'IOMMU alors que Kaveri finalise le support de la mémoire unifiée et cohérente.

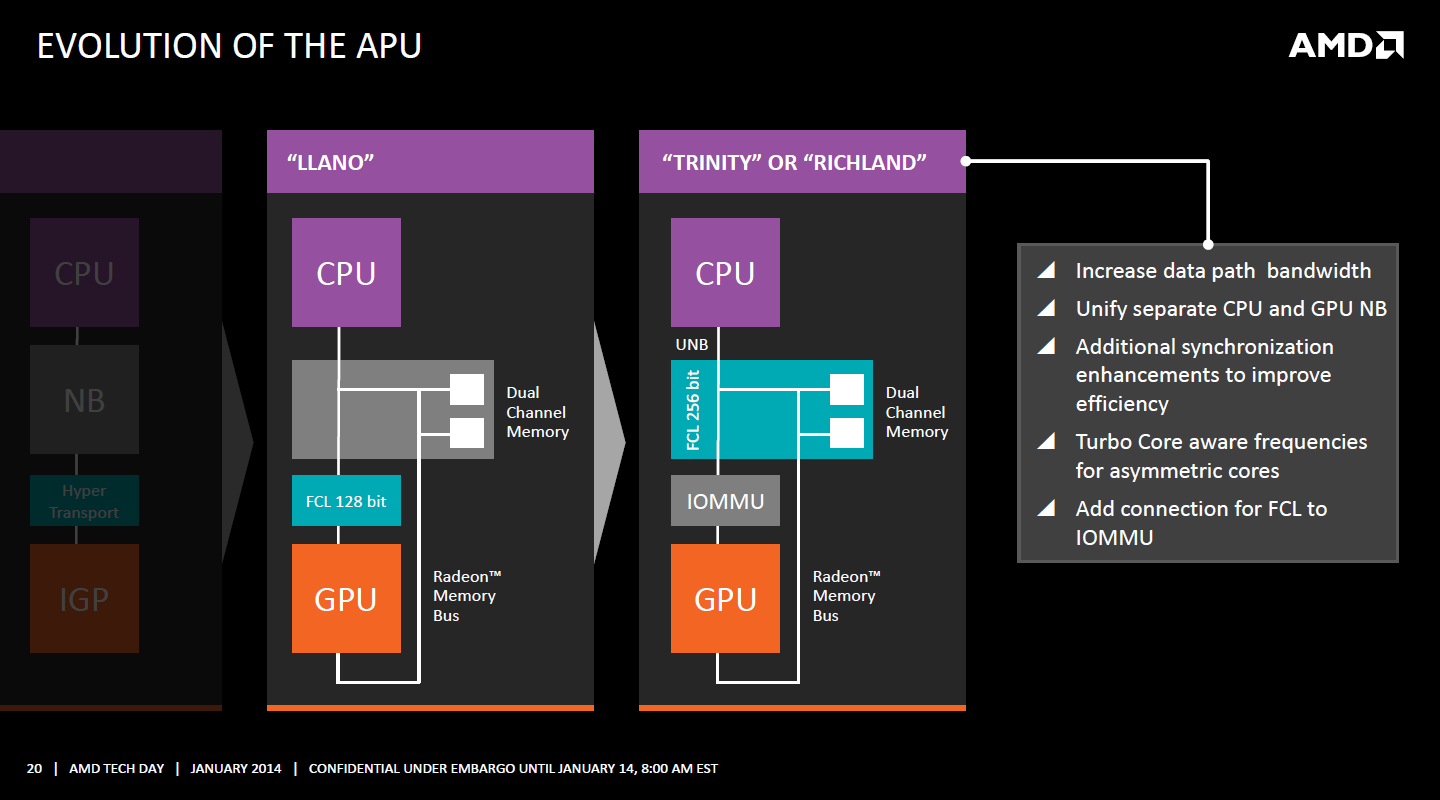
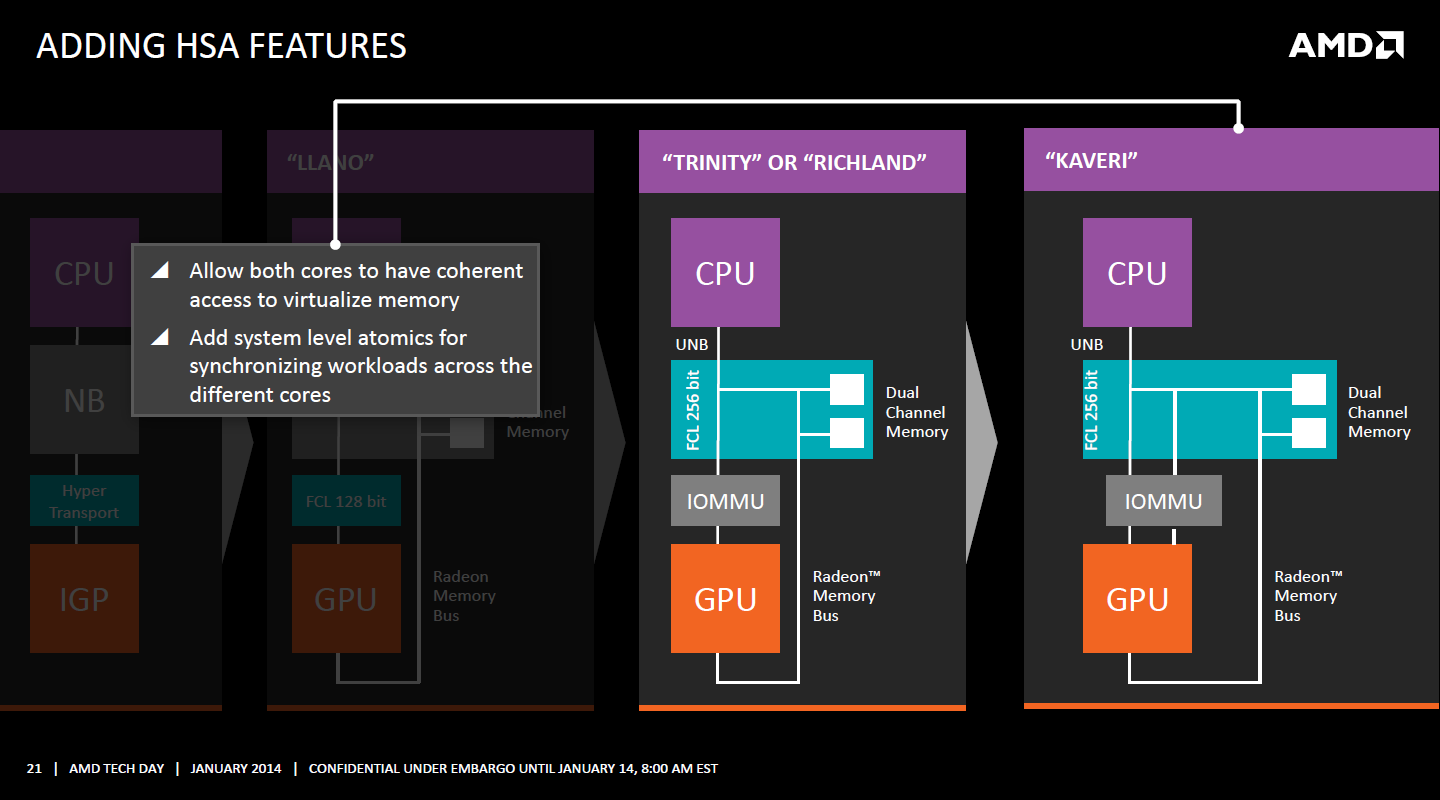
Avec Trinity/Richland, il était déjà possible d'éviter les copies entre les curs GPU et CPU, à travers le mode Zero-Copy optionnel. Le support de la mémoire virtuelle unifiée de Kaveri simplifie l'accès à cette possibilité.
AMD conserve l'implémentation de deux bus entre les curs GPU et la mémoire : Garlic (Radeon memory Bus) et Onion (Compute Link Bus). Le bus Garlic est le plus performant, il offre un lien à pleine vitesse vers la mémoire DDR de manière à permettre au GPU dans le cadre du rendu 3D de profiter de la totalité de la bande passante mémoire. Il n'est par contre pas possible d'accéder directement à une zone mémoire exploitée par les curs CPU, une copie est nécessaire.
Le bus Onion permet dans la plupart des cas d'éviter ces copies mais se contente avec Kaveri d'une bande passante qui correspond suivant les dérivés à 50-60% de la bande passante maximale. Il s'agit malgré tout d'une nette progression par rapport à Trinity/Richland, puisqu'elle correspond à un débit doublé.
La nouveauté avec Kaveri est le mode Onion+ qui rend cohérent ce second bus à travers la possibilité offerte aux curs GPU d'exécuter des opérations atomiques sur la mémoire système. Il souffre cependant d'une limitation importante dans son implémentation sur Kaveri : le cache L2 du GPU se trouve désactivé ce qui peut avoir un impact sur les performances.
Pour profiter de performances maximales, il revient toujours au développeur d'utiliser le type de mémoire le plus adapté à chaque utilisation : "Device Memory" pour profiter du bus Garlic dans le cadre de tâches purement graphiques, "Host Memory" (Onion) pour éviter les copies inutiles et "Coherent Host Memory" (Onion+) quand préserver la cohérence est réellement nécessaire.
Voici un exemple de gains qui peuvent être rendu possibles en exploitant OpenCL 1.2 sur Kaveri en respectant les spécifications plus strictes de la HSA :
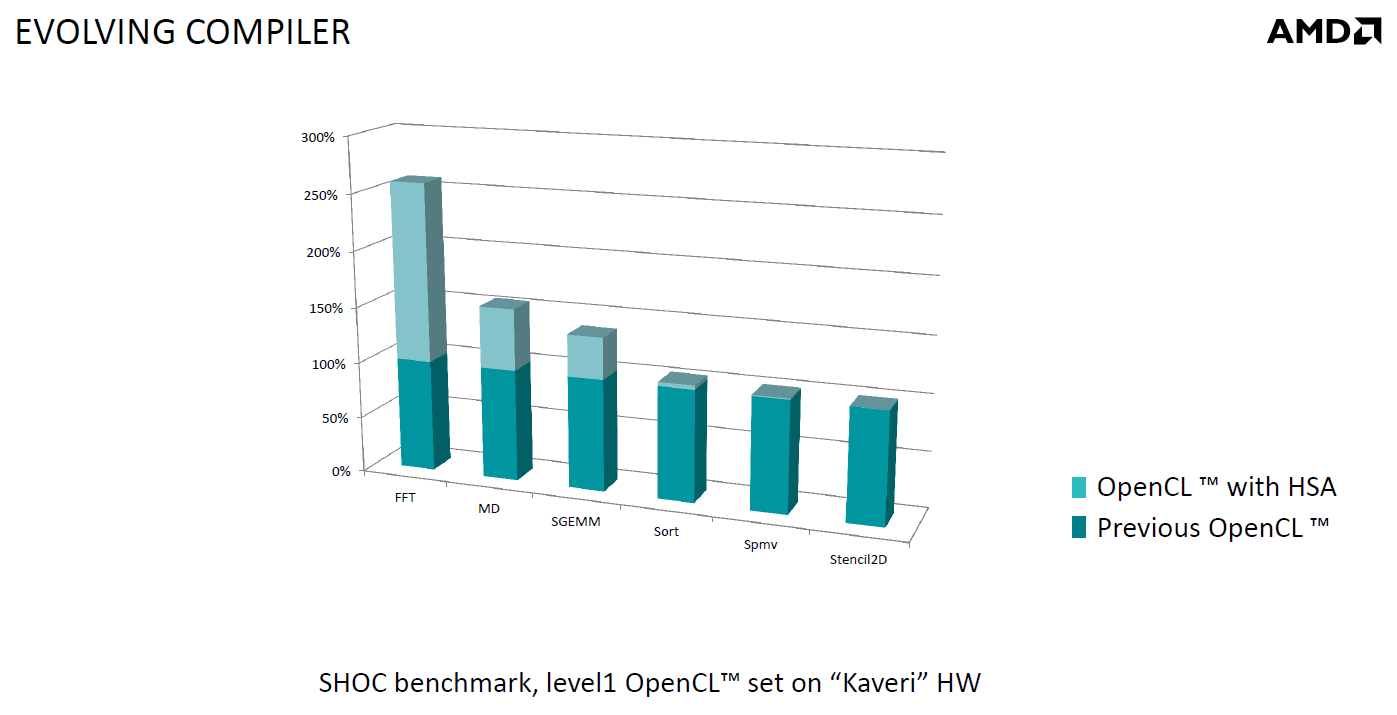
Comme vous pouvez le voir ici, les gains peuvent être inexistants ou très faibles dans certains cas, mais très importants dans d'autres. Typiquement, plus une application est complexe, plus les gains directs ou indirects de la HSA vont pouvoir se manifester, ne serait-ce que parce qu'il sera plus facile pour les développeurs d'optimiser leur code. Représenter cela à travers des benchmarks synthétiques peut ainsi être difficile alors que le support logiciel est actuellement presqu'inexistant. Pour les gains pratiques, il faudra donc attendre encore un petit peu, d'autant plus que le support logiciel n'est pas encore totalement prêt :

AMD parle ainsi du second semestre de cette année pour l'intégration finale de la HSA dans son compilateur OpenCL avec support de la version 1.2 de l'API associé à des extensions propriétaires pour les fonctionnalités additionnelles nécessaires. Pour le support de la HSA via OpenCL 2.0 il faudra attendre début 2015 et c'est probablement à partir de cette version que l'intérêt des développeurs pour la HSA progressera réellement.
A l'heure actuelle, AMD fourni une version alpha de son compilateur OpenCL 1.2 avec support de la HSA. Cette version souffre de plusieurs limitations telles que l'utilisation exclusive d'espaces mémoire de type "Coherent Host Memory", les plus flexibles mais également les moins performants puisqu'ils ne peuvent pas profiter du cache L2 du GPU.
Les agents HSA d'AMD : les Compute CoresSi pour les développeurs, AMD parle d'agents HSA, pour le grand public, une autre nomenclature vient d'être dévoilée par AMD : les Compute Cores. Chaque Compute Core est une structure capable de supporter la HSA et donc de prendre en charge son modèle mémoire et d'exécution/gestion des tâches.

Dans le cadre d'un APU, chaque module SMT représente 2 Compute Cores et chaque Compute Unit du GPU représente 1 Compute Core. Avec 2 modules SMT (4 curs CPU) et un GPU composé de 8 Compute Units, Kaveri supporte ainsi dans sa configuration maximale 12 Compute Cores.
Parler du nombre de curs d'un composant est généralement tendancieux tant il s'agit d'un argument dont abusent de nombreux acteurs de l'industrie pour convaincre l'utilisateur final des bienfaits de leurs produits. Si considérer qu'une Compute Unit correspond à un cur est largement plus pertinent que de parler de GPU de plus de 1000 curs en comptant chaque ligne d'une unité vectorielle, cette façon de simplifier les choses ouvre la porte à de nouveaux abus. Il serait ainsi malvenu qu'AMD simplifie sa communication au point de vendre les APU Kaveri au grand public comme des processeurs à 12 curs c'est pourtant le chemin qui semble être pris quand on regarde une boite d'A10-7850K :

Sommaire
Vos réactions
Contenus relatifs
- [+] 17/03: AMD baisse ses prix AM3+/FM2+
- [+] 06/04: AMD pré-annonce Bristol Ridge
- [+] 02/02: Excavator FM2+ et nouveaux ventirad...
- [+] 11/01: AMD A10-7890K pour fêter les 2 ans ...
- [+] 20/07: AMD lance l'A8-7670K
- [+] 28/05: AMD lance l'A10-7870K, le premier '...
- [+] 13/05: AMD baisse les prix des Kaveri
- [+] 17/03: Godavari confirmé par ASRock
- [+] 28/01: AMD A10-8850K Godavari, un A10-7850...
- [+] 15/01: Pas d'AMD Carrizo en FM2+ ?!