
Influence du PCI Express sur les GPU
Publié le 10/06/2011 par Guillaume Louel



Bande passante, mesures théoriques
Dans le cas de l'utilisation en jeu, les transactions sur le bus PCI Express se font principalement entre le CPU et le GPU. Certains chargements sont ponctuels, comme le chargement de textures ou de données sur la scène graphique, d'autres sont liées au calcul de chaque image (informations/instructions envoyées par les drivers). A moteur graphique égal, plus une carte graphique est capable de calculer d'images et plus le PCI Express peut avoir un impact, s'il en a un.
Mais avant de mesurer l'impact en pratique, nous avons tenus à mesurer la bande passante de manière plus théorique. Nous avons pour cela utilisé les tests de bande passante PCI Express inclus dans les kits de développement CUDA de Nvidia (le CUDA Toolkit 4.0 ) et APP d'AMD (la version 2.4 ). Nos scores ne sont donc pas directement comparables entre GeForce et Radeon. En pratique c'est surtout l'évolution d'un mode à l'autre qui nous intéresse ici plus qu'une comparaison entre les deux marques.
En parlant des modes, nous avons testés ceux-ci :
- Mode x16 (carte graphique dans le slot 1)
- Mode x8 (carte graphique dans le slot 2)
- Mode x4 (carte graphique dans le slot 1 en désactivant les broches supplémentaires)
- Mode x4 chipset (carte graphique dans le slot 3)
Bande passante théorique (mémoire non-paginable)
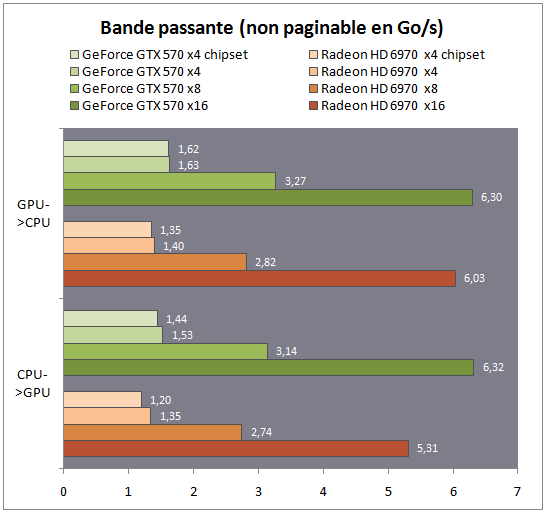
Pour rappel, la bande passante théorique du PCI Express 2.0 est de 5 GT/seconde et par ligne, codé sur 10 bits (pour 8 bits utiles). En pratique cela nous donne 4 GT/s, soit 500 Mo/s par ligne. On arrive donc à une bande passante théorique de 8 Go/sec pour 16 lignes, sans pour autant prendre en compte le cout du protocole de transaction.
En mode x16, on atteint environ les 75% d'efficacité, ce qui correspond aux normes admises. Chez Nvidia on colle d'ailleurs à ce schéma de prêt avec dans les modes inferieurs. Chez AMD, la taille des buffers différente rajoute un overhead plus important, ce qui explique que le mode x16 est plus de deux fois plus rapide que le mode x8.
Deux remarques d'importances cependant. La première est qu'assez généralement, le transfert GPU vers CPU est plus rapide qu'en sens inverse. La seconde est que si l'impact sur le transfert GPU vers CPU est léger entre le mode x4 chipset et le mode x4 processeur, l'impact est plus élevé entre le CPU et le GPU. Sachant qu'il s'agit du sens le plus utilisé en pratique dans les jeux, il va être intéressant de voir comment cela se traduit en pratique. Notez que la perte est quasiment double chez AMD dans ce sens, on perd 11% de performances entre le mode x4 southbridge et le mode x4 processeur, là ou l'on n'en perd que 5.5% chez Nvidia
Dernier point, pour atteindre ces vitesses, les outils réservent côté système des espaces mémoires non paginables, le système d'exploitation bloque les pages mémoires pour qu'elles ne puissent pas se retrouver en mémoire swap. En clair, on est sur à 100% que la mémoire sera en RAM. Si en théorie les performances devraient être identiques si l'on dispose de suffisamment de mémoire, en pratique le fait d'être certain que le bloc mémoire est en RAM permet aux pilotes Nvidia/AMD d'utiliser des algorithmes de copie plus efficaces.
Bande passante théorique (mémoire paginable)
Sachant qu'il n'est pas toujours possible aux développeurs d'utiliser de l'espace mémoire non paginable, nous avons réalisé un second test en réservant la mémoire côté système de manière classique. Nous avons utilisé cette fois ci OpenCL pour créer un test qui soit fonctionnel sur les deux cartes, via la bibliothèque Cloo (version 0.9 ). Notez à titre informatif que si les pilotes grand public AMD sont compatibles OpenCL 1.1, les pilotes grand public Nvidia sont encore limités à l'OpenCL 1.0. Un pilote 1.1 est disponible (depuis un an ), mais uniquement pour les développeurs enregistrés.
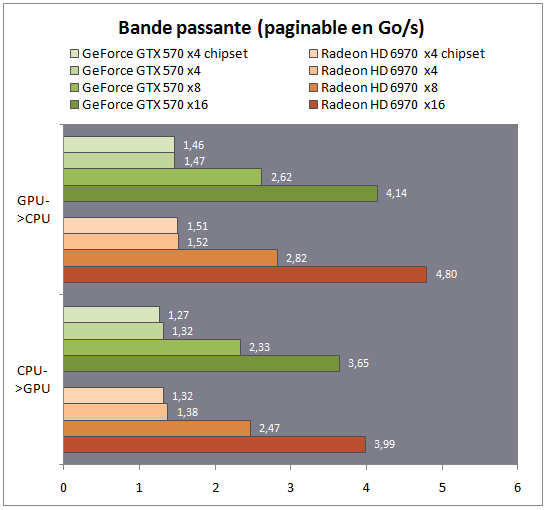
Nous montons moins haut cette fois-ci, particulièrement en mode 16x, mais les tendances restent les mêmes. Le transfert GPU vers CPU reste plus rapide que l'inverse, et en mode 4x chipset, on retrouve toujours une baisse de bande passante plus notable sur le transfert CPU vers GPU.
Notez que nous avons également essayé de mesurer les latences, quelque chose qui s'est rêvelé impossible de manière logicielle. En effet, mesurer les différences de latences par exemple en mesurant le temps nécessaire à des transferts de données se heurte à des variances qui vont bien au-delà de la latence du bus en lui-même. Que ce soit la couche de transaction (le PCI Express fonctionne via un système de crédits entre les paires de périphériques) ou le pilote en lui-même, en pratique la variabilité reste très grande avec des écarts sur plusieurs centaines de tests qui peuvent dépasser les 100 microsecondes. C'est quelque chose que l'on retiendra, malgré une implémentation simple et une grande flexibilité, le bus PCI Express reste complexe à mesurer de manière purement logicielle, la faute au multiples couches logicielles qui imposent elles mêmes leurs couts, bien plus elevés que ceux de l'interface en elle-même.
Passons maintenant aux tests pratiques dans les jeux.
Sommaire
Vos réactions
Contenus relatifs
- [+] 15/01: NZXT lance une carte mère ! (MAJ)
- [+] 20/11: Intel 100% UEFI 0% BIOS d'ici 2020
- [+] 26/10: La norme PCI Express 4.0 finalisée
- [+] 18/10: Le Z270 aurait pu supporter Coffee ...
- [+] 09/10: Coffee Lake : avalanche de cartes m...
- [+] 04/10: ASUS se lance dans le mini-ITX AM4
- [+] 04/10: Le RAID NVMe disponible sur X399 en...
- [+] 02/10: La spécification de l'USB 3.2 a été...
- [+] 19/09: Z370 incompatible avec les Core de ...
- [+] 23/08: 19 slots PCIe sur une carte ASUS !