
Nvidia GeForce GTX 460
Publié le 12/07/2010 par Damien Triolet



Plus de triangles, moins de pixelsDepuis le lancement de la GeForce GTX 480, nous avons eu un peu de temps pour observer certains détails de larchitecture. Tout dabord au niveau géométrique où nous avons pu constater plusieurs choses bien que certains aspects de larchitecture conservent toujours quelques secrets.
Le culling est très rapide sur le GF100 et sur le GF104. Cette opération consiste par exemple à rejeter un triangle qui tourne le dos à la caméra (back face culling), ce qui signifie quil nest pas visible. Imaginez une sphère composée de multiples facettes affichée à lécran. En réalité vous nen voyez que la moitié des polygones, celle qui vous fait face. Lautre moitié nest pas visible et peut donc être éjectée du rendu. Pour les objets et personnages plus complexes affichés dans un jeu, le principe est le même et statistiquement la moitié des polygones qui les composent peuvent être rejetés. Le faire rapidement est donc intéressant. Les GPUs AMD ainsi que le GT200 et ses prédécesseurs sont capables de rejeter un triangle par cycle. Dans le GF100 et le GF104, cette opération est distribuée et parallélisée. Elle prend place dans le Polymorph Engine de chaque SM. Nous avons pu observer que chaque SM est ainsi capable de rejeter un triangle tous les 4 cycles (fréquence GPU). Avec 16 SMs le GF100 peut donc en rejeter 4 par cycles et avec 8 SMs, le GF104 peut en rejeter 2 par cycle.
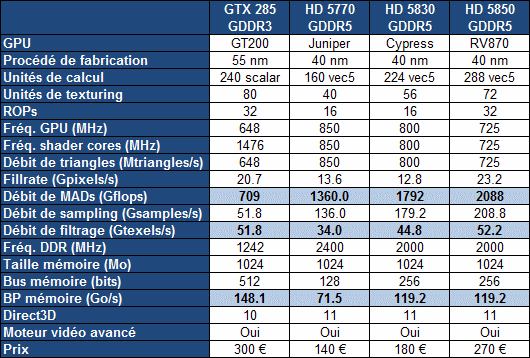
Au niveau de la rastérisation, soit de la découpe des triangles en pixels, le GT200 et ses prédécesseurs étaient capable de traiter un triangle tous les 2 cycles alors que les Radeon atteignaient 1 triangle par cycle. Là aussi le GF100 a parallélisé cette étape du rendu puisque chacun des 4 GPCs dispose dun rasterizer. En principe chacun de ceux-ci peut traiter un triangle par cycle et générer 8 pixels par cycle. En pratique sils peuvent bien générer 8 pixels par cycles, leur débit en triangles est limité artificiellement sur les GeForce pour laisser un avantage aux Quadro à ce niveau. Les tests que nous avons pu effectuer laissent penser quils peuvent en pratique sur GeForce traiter un triangle tous les deux cycles. Si le GF100 était donc en pratique deux fois plus véloce que les Radeon, le GF104 ne fait que se mettre à leur niveau.
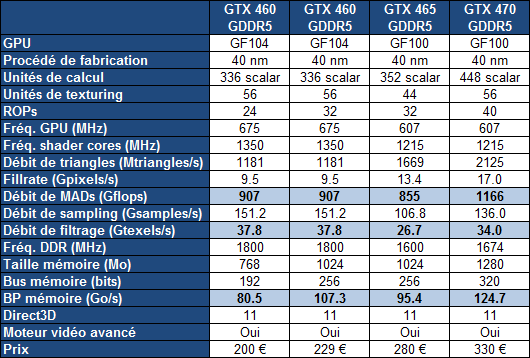
Nous avons également pu en apprendre plus sur la limitation du fillrate du GF100 et du GF104 qui la partage. Elle se situe au niveau de la communication entre les SMs et les ROPs qui est limitée à 64 bits par cycle. Ainsi, en rendu classique, chaque SM peut débiter 2 pixels par cycle soit 32 au total pour le GF100 et 16 au total pour le GF104. Peu importe que le premier soit équipé de 48 ROPs et le second de 32 ROPs, la limite sera de 32 et 16 pixels par cycle. Les rasterizers offrent dailleurs un même débit. Nous pourrions nous dire que les ROPs étant plus lents en rendu FP16 (64 bits par pixel) et FP32 (128 bits par pixel), ils vont pouvoir tous être utiles avec ces rendus. Mais il nen est rien puisque, encore une fois, le datapath entre les SMs et les ROPs est limité à 64 bits.
Nous ne savons pas sil sagit là dune limitation voulue dès le départ par Nvidia, sil sagit dun compromis fait en court de route ou dune solution de secours mise en place suite à un problème. Quoi quil en soit il sagit selon nous dune limitation importante de larchitecture qui empêche de profiter pleinement de la totalité des ROPs et dans une moindre mesure de la bande passante mémoire disponible. Lot de consolation, les ROPs « inutiles » sont mis à contribution lorsque lantiliasing est utilisé puisque ce filtre augmente la charge sur les ROPs sans trop augmenter la quantité de données à transmettre entre les SMs et les ROPs.
SpécificationsTout comme pour les GeForce GTX 400 basées sur le GF100, les GeForce GTX 460 exploitent un GF104 partiellement castré. Un de ses 8 SMs est donc désactivé. Par ailleurs, et cest regrettable, Nvidia a décidé de lancer sous le même nom, GeForce GTX 460, une version 192 bits en plus de la version 256 bits. Alors que la version 256 bits est équipée de 1 Go de mémoire et de 32 ROPs, la version 192 bits nest équipée que de 768 Mo de mémoire et de 24 ROPs, en plus de voir sa bande passante chuter de 25%. Selon nous il sagit de 2 produits différents et en les proposant sous un même nom, Nvidia ajoute inutilement de la confusion. Certes il est possible de les identifier suivant la quantité de mémoire, mais que va-t-il se passer quand une version 192 bits et 1.5 Go va débarquer ? Il ne sera pas spécialement évident pour tous les acheteurs de comprendre quelle sera moins performante quune version 1 Go
Sommaire
1 - Introduction
2 - Architecture Fermi pour les joueurs
3 - Architecture (suite), spécifications
4 - Tests théoriques - pixels
5 - Tests théoriques - géométrie
6 - Les cartes
7 - Consommation, bruit
8 - Températures
9 - Overclocking, protocole de test
10 - Need for Speed Shift
11 - ArmA 2
12 - Anno 1404
2 - Architecture Fermi pour les joueurs
3 - Architecture (suite), spécifications
4 - Tests théoriques - pixels
5 - Tests théoriques - géométrie
6 - Les cartes
7 - Consommation, bruit
8 - Températures
9 - Overclocking, protocole de test
10 - Need for Speed Shift
11 - ArmA 2
12 - Anno 1404
Vos réactions
Contenus relatifs
- [+] 10/04: Nvidia : fin du support Fermi et 32...
- [+] 12/03: Nvidia lance les GeForce 800M avec ...
- [+] 08/10: Comparatif : les super GeForce GTX ...
- [+] 24/03: Nvidia répond à AMD avec la GeForce...
- [+] 17/03: Nvidia GeForce GTX 550 Ti et Asus D...
- [+] 11/03: EVGA lance une bi-GTX 460
- [+] 28/02: Nvidia annonce CUDA 4.0
- [+] 01/02: Nvidia lance une autre GeForce GT 4...
- [+] 25/01: GeForce GTX 560 Ti contre Radeon HD...
- [+] 24/01: Comparatif : 14 GeForce GTX 460 1 G...