
OpenCL : le GPU Computing enfin démocratisé ?
Publié le 12/12/2008 par Damien Triolet



OpenCUDAEn parcourant la documentation complète d'OpenCL, il apparaît d'une manière très évidente que la base d'OpenCL est C pour CUDA. Rien ne sert en effet de réinventer une roue qui tourne. D'une manière simplifiée nous pouvons donc dire que le consortium a repris l'API de Nvidia et l'a étendue pour y intégrer tout ce que ses membres désiraient.
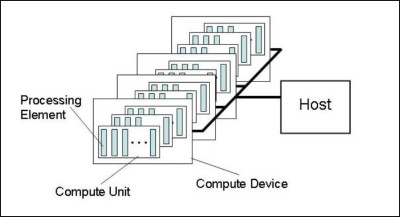
Le fonctionnement de base est exactement le même qu'avec C pour CUDA : un kernel est envoyé à l'accélérateur (Compute device) qui est composé de « compute units » dont les « processing elements » travaillent sur des « work items ». La similitude est complète et il est évident que le groupe Khronos a opté pour des noms différents de ceux de C pour CUDA pour des raisons politiques. Voici ce que donne le traduction si vous êtes familiers avec les termes « CUDA » :
Multiprocessor -> Compute unit
Processor -> Processing Element
Block -> Work-group
Thread -> Work-item
Texture -> Image object
Shared Memory -> Local Memory
Si OpenCL reprend le principe de mémoire partagée entre les éléments d'un même groupe de travail il n'en définit cependant pas le comportement. Cette mémoire étant très spécifique, pour l'exploiter d'une manière utile il faudra donc se référer aux documentations des fabricants. Petite différence, alors que C pour CUDA définit une mémoire locale (sur la carte graphique) et globale (dans le système), OpenCL regroupe ces 2 mémoires sous le terme Global memory.
OpenCL ne fixe pas réellement de spécifications. Il permet par contre d'obtenir toutes les spécifications de l'accélérateur qui va être utilisé Le développeur devra se baser sur celles-ci et s'assurer de la compatibilité entre son code et l'accélérateur car dans certains cas le code sera purement incompatible avec certains accélérateurs puisque, par exemple, l'endianness est libre. Nous pouvons également imaginer un code auto-adaptatif suivant les spécifications de l'accélérateur, mais en dehors de quelques cas simples cela devrait à priori rester un exercice de style.
Les différences principalesOpenCL est une API légèrement de plus bas niveau que C pour CUDA. Pour être précis, il est utile de rappeler que C pour CUDA peut être exploité en mode runtime, classique, ou driver, un peu plus complexe. C'est grossièrement à cette dernière version que correspond OpenCL qui impose donc au développeur de gérer manuellement la mémoire alors qu'en version runtime de C pour CUDA tout cela est transparent.
Ensuite OpenCL, tout comme le langage Ct d'Intel, supporte 2 modèles de parallélisme : au niveau des données et au niveau des tâches. Le parallélisme au niveau des données est celui utilisé par les GPUs (même si Nvidia parle de threads il s'agit en fait d'un programme identique exécuté sur différentes données) alors que le parallélisme des tâches correspond à ce qui se passe dans une unité SSE par exemple. Ce second modèle est moins efficace sur un GPU.
OpenCL supporte des extensions, comme OpenGL, qui peuvent être propriétaires et permet même d'inclure dans un programme des kernels natifs qui sont des bouts de code destinés à tourner sur l'accélérateur sans être écrits et compilés via OpenCL. Chaque fabriquant peut donc faire ce qu'il veut à ce niveau. L'utilisation d'une API propriétaire ou d'un kernel natif empêchera directement le code de tourner sur un matériel différent.
Enfin, OpenCL supporte un mode « ES » avec un minimum requis revu à la baisse, notamment sur le respect des standards en terme de précision de calcul, destiné aux périphériques mobiles.
Vos réactions
Contenus relatifs
- [+] 09/02: Nvidia lance les Quadro Pascal dont...
- [+] 05/04: GTC: Nvidia Tesla P100: 10 Tflops, ...
- [+] 15/12: GPUOpen, la réponse d'AMD à GameWor...
- [+] 16/11: AMD et HPC: nouveaux outils, suppor...
- [+] 09/07: AMD lance la FirePro S9170: Hawaii ...
- [+] 03/03: GDC: Khronos annonce OpenCL 2.1
- [+] 08/12: Nvidia lance la Tesla K80: double G...
- [+] 02/12: IBM Power9 et Nvidia Volta : 100+ p...
- [+] 07/04: AMD FirePro W9100 : 2.6 Tflops DP, ...
- [+] 25/11: Nvidia annonce la Tesla K40 et CUDA...