
AMD Radeon HD 4870 & 4850
Publié le 25/06/2008 par Damien Triolet



Performances branchementsL'une des principales nouveautés qui a été introduite avec l'évolution de la programmabilité des GPUs est le branchement dynamique. Cela permet de rendre l'écriture de certains shaders plus naturelle et d'augmenter l'efficacité d'autres shaders en évitant de calculer une partie de ceux-ci sur les pixels qui n'en ont pas besoin. Par exemple pourquoi appliquer le filtrage très coûteux de l'adoucissement de bordure d'une ombre si le pixel est au milieu de l'ombre ? Un branchement dynamique permet de détecter si le pixel en a besoin ou pas.
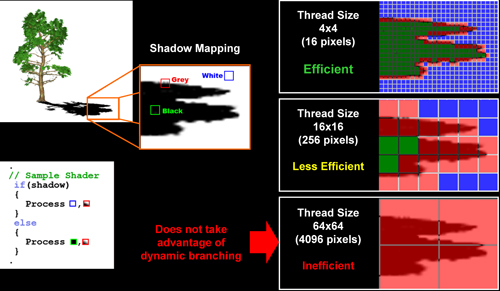
Mais tout n'est pas si rose puisque ceux-ci ne sont efficaces que dans des cas bien précis. Les branchements ont une réputation d'être difficile à gérer, c'est particulièrement le cas dans les CPUs qui doivent prédire le résultat du branchement à l'avance pour masquer la latence du calcul de celui-ci. Dans un GPU, les pixels sont traités par groupes de dizaines, de centaines voire de milliers de pixels, ce qui permet de masquer automatiquement cette latence. Le problème des CPUs n'existe donc pas réellement. Par contre un autre problème se pose. Les GPUs exécutent leurs instructions sur des groupes d'éléments ou threads. Lors d'un branchement, tous les threads doivent prendre la même branche sans quoi les 2 branches doivent être calculées pour tous, avec des masques pour n'écrire que le résultat de la branche requise.
Dans le cas des GeForce 8, 9 et GTX 200, le GPU travaille sur des groupes de 16 ou 32 threads (vertices, pixels etc.). Pourquoi ces 2 possibilités ? Tout d'abord ce sont des unités SIMT 8-way qui sont utilisées. Il faut donc des groupes d'au moins 8 threads. Ensuite rappelez-vous que les unités de calcul sont double pumped et fonctionnent à la fréquence double du scheduler. Il ne peut donc envoyer une commande qu'un cycle sur 2 du point de vue des unités de calcul. Travailler sur des groupes de 16 threads permet aux unités de calcul d'avoir assez de travail et de ne pas attendre un scheduler plus lent qu'elles. Enfin, travailler sur 32 threads autorise la dual issue. Un coup le scheduler va envoyer une instruction à l'unité SIMT 8-way, un autre coup il va envoyer une instruction aux unités spéciales. Il peut gérer les 2 en alternance et à plein débit grâce aux groupes de 32 threads.
Nvidia peut configurer ses GPUs pour 16 ou 32 threads. Dans le premier cas, les performances en branchement sont améliorées, dans le second cas la puissance de calcul est améliorée grâce à la dual issue. Les groupes de 16 sont activés pour les vertex et geometry shader alors que les groupes de 32 le sont pour les pixel shaders et pour CUDA.
Nous avons développé un petit test qui nous permet de modifier la granularité du branchement, c'est-à-dire le nombre moyen, dans notre exemple, de pixels consécutifs qui vont prendre une même branche. Nous spécifions la branche à prendre par colonne de pixels, une colonne sur 2 doit afficher un shader complexe et l'autre peut passer cette partie du rendu. Des triangles de taille moyenne en mouvement sont affichés à l'écran et traversent ces zones qui utilisent différentes branches, ce qui implique que tant les triangles et leur position que la taille de la colonne influent sur l'efficacité du branchement ce qui est proche d'une situation réelle.
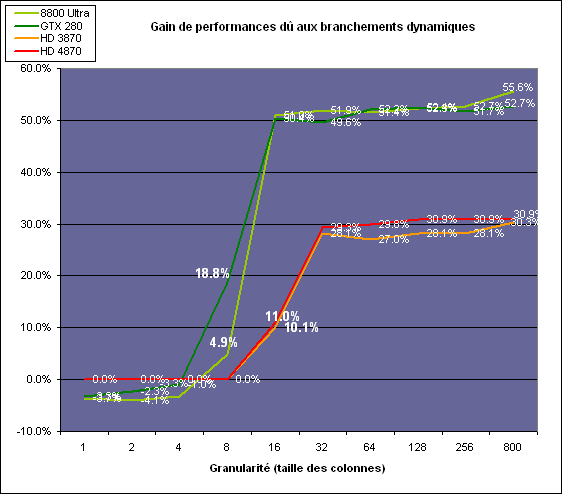
Avec des colonnes étroites, les GPUs ne peuvent pas profiter du branchement pour éviter la partie complexe sur la moitié des pixels, mais par contre doivent traiter les instructions de branchement, ce qui fait baisser légèrement les performances au lieu de les augmenter. Tout du moins sur les GeForce 8, 9 et GTX 280. Tous ces GPUs disposent d'une unité dédiée aux branchements qui travaille en parallèle et masque le coût des instructions de branchement. Les Radeon semblent cependant les seules à masquer complètement la latence des branchements.
La taille des groupes de pixels sur le GeForce 8800 est de 32 contre 64 pour le Radeon HD3870 et 4870, ce qui permet aux puces de Nvidia de prendre les devants. Nous avons mis en évidence une différence surprenante entre le GeForce 9800 GTX et le GeForce GTX 280 qui avec une colonne de 8 pixels est beaucoup plus efficace. Il est probable que le découpage des triangles en pixels se fassent de manière à mieux grouper les pixels proches (et donc susceptibles de prendre la même branche) entre eux, ce qui est bénéfique dans ce cas.
Sommaire
1 - Introduction
2 - Architecture : SIMT, SIMD, MIMD, Radeon HD
3 - Architecture : Radeon HD 4800
4 - AMD premier sur la GDDR5
5 - Performances Pixel, Vertex et Geometry Shaders
6 - Performances Texturing et ROPs
7 - Performances Branchements
8 - Les Radeon HD 4800
9 - Réaction de Nvidia
10 - DirectX 10, GPGPU, Vidéo HD
11 - Spécifications, consommation, le test
12 - Enemy Territory : Quake Wars
2 - Architecture : SIMT, SIMD, MIMD, Radeon HD
3 - Architecture : Radeon HD 4800
4 - AMD premier sur la GDDR5
5 - Performances Pixel, Vertex et Geometry Shaders
6 - Performances Texturing et ROPs
7 - Performances Branchements
8 - Les Radeon HD 4800
9 - Réaction de Nvidia
10 - DirectX 10, GPGPU, Vidéo HD
11 - Spécifications, consommation, le test
12 - Enemy Territory : Quake Wars
Vos réactions
Contenus relatifs
- [+] 04/05: Nvidia abandonne son GeForce Partne...
- [+] 27/04: AMD Vega 7nm en labo, Zen 2 échanti...
- [+] 18/04: ASUS AREZ, l'effet GeForce Partner ...
- [+] 10/04: Nvidia : fin du support Fermi et 32...
- [+] 27/03: Pilotes Radeon et GeForce pour Far ...
- [+] 20/03: Pilotes GeForce 391.24 pour Sea of ...
- [+] 20/03: Microsoft annonce DirectX Raytracin...
- [+] 20/03: Radeon Software 18.3.3 beta avec Vu...
- [+] 08/03: 3 millions de GPU vendus pour le mi...
- [+] 08/03: Radeon Software 18.3.1 optimisé pou...