
AMD Radeon HD 4870 & 4850
Publié le 25/06/2008 par Damien Triolet



Performances Pixel ShaderNous avons testé 2 shaders d'éclairage relativement simples qui représentent un bon compromis entre des débits théoriques et pratiques :

La GeForce GTX 280 est ici la plus véloce, mais la Radeon HD 4870 affiche un gain énorme par rapport à la génération précédente.
Performances Vertex ShaderNous avons testé les performances en T&L, VS 1.1, VS 2.0 et VS 3.0 dans RightMark :
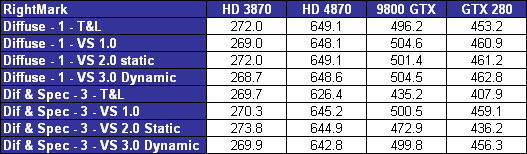
L'architecture unifiée permet aux GPUs récents d'attribuer toutes les ressources au traitement des vertex shader, ce qui entraîne un gain qui peut être conséquent. Il pourrait d'ailleurs être plus important mais est limité par le débit en triangle des GPUs qui sur toutes les GeForce testées ici est de 1 triangle par cycle. Par contre il est de 0.5 par cycle pour la Radeon HD 3870, alors qu'il était de 1 par cycle sur la Radeon HD 2900 XT, débit auquel la Radeon HD 4870 revient. La fréquence plus élevée de cette dernière joue donc ici en son avantage et fait de ce GPU le plus puissant que nous ayons pu avoir entre nos mains en matière de traitement géométrique (simple).
Performances Geometry ShaderContrairement à Nvidia, AMD a intégré un cache généralisé pour les lectures/écritures en mémoire à partir du shader core. Celui-ci peut être utilisé d'une manière classique pour le Stream Output qui consiste, comme le requiert DirectX 10 à pouvoir écrire les données qui sortent du shader core sans passer par les ROPs. Il permet également de virtualiser les registres généraux qui peuvent ainsi être illimités.
Une autre utilité est d'utiliser la mémoire vidéo à travers ce cache pour stocker temporairement la masse potentiellement énorme de données créées par les Geometry Shaders lors d'amplification de la géométrie sans quoi les unités de calcul pourraient être bloquées par manque de mémoire pour stocker ces nouvelles données.
Nvidia prend le problème dans l'autre sens et au lieu de proposer une mémoire registres étendue, réduit le nombre d'éléments traités en parallèle à un nombre qui permette toujours d'avoir assez de mémoire dans le GPU pour stocker les nouvelles données. Autrement dit au lieu de pouvoir utiliser 128 ou 240 processeurs pour traiter un geometry shader, si Nvidia détecte qu'il peut y avoir un problème ce nombre doit être réduit. Nous ne savons pas exactement à quel point Nvidia doit réduire le traitement en parallèle, mais il est évident qu'il y a là une grosse différence entre Nvidia et AMD, à l'avantage de ce dernier, même si les développeurs font attention à ne pas utiliser de cas problématique.
Pour compenser cela, avec les GeForce GTX 200, Nvidia a augmenté fortement la taille de son cache interne en sortie des geometry shaders : x6. AMD a également augmenté la taille de ce cache puisqu'il est nettement plus efficace de garder le tout sur le GPU au lieu de passer par la mémoire vidéo. Nous avons observé les performances à travers une démo de tesselation à base de geometry shader fournie par AMD au lancement des Radeon HD 2900 XT :
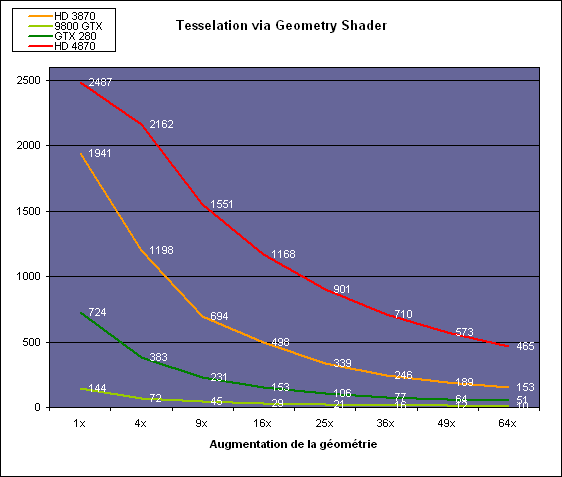
Comme vous pouvez le constater, même si les GeForce GTX 200 améliorent grandement les performances par rapport aux GeForce 8 et 9, les Radeon restent nettement devant. Nvidia indique avoir augmenté son cache en correspondance avec ce dont les développeurs utilisent et vont utiliser à moyen terme. De son côté AMD précise avoir implémenté un "fast path" pour l'amplification géométrique.
En plus de cela les Radeon HD 4800 conservent bien entendu l'unité de tesselation, même si celle-ci n'est toujours utilisée par aucun jeu
Sommaire
1 - Introduction
2 - Architecture : SIMT, SIMD, MIMD, Radeon HD
3 - Architecture : Radeon HD 4800
4 - AMD premier sur la GDDR5
5 - Performances Pixel, Vertex et Geometry Shaders
6 - Performances Texturing et ROPs
7 - Performances Branchements
8 - Les Radeon HD 4800
9 - Réaction de Nvidia
10 - DirectX 10, GPGPU, Vidéo HD
11 - Spécifications, consommation, le test
12 - Enemy Territory : Quake Wars
2 - Architecture : SIMT, SIMD, MIMD, Radeon HD
3 - Architecture : Radeon HD 4800
4 - AMD premier sur la GDDR5
5 - Performances Pixel, Vertex et Geometry Shaders
6 - Performances Texturing et ROPs
7 - Performances Branchements
8 - Les Radeon HD 4800
9 - Réaction de Nvidia
10 - DirectX 10, GPGPU, Vidéo HD
11 - Spécifications, consommation, le test
12 - Enemy Territory : Quake Wars
Vos réactions
Contenus relatifs
- [+] 04/05: Nvidia abandonne son GeForce Partne...
- [+] 27/04: AMD Vega 7nm en labo, Zen 2 échanti...
- [+] 18/04: ASUS AREZ, l'effet GeForce Partner ...
- [+] 10/04: Nvidia : fin du support Fermi et 32...
- [+] 27/03: Pilotes Radeon et GeForce pour Far ...
- [+] 20/03: Pilotes GeForce 391.24 pour Sea of ...
- [+] 20/03: Microsoft annonce DirectX Raytracin...
- [+] 20/03: Radeon Software 18.3.3 beta avec Vu...
- [+] 08/03: 3 millions de GPU vendus pour le mi...
- [+] 08/03: Radeon Software 18.3.1 optimisé pou...