
Nvidia GeForce GTX 280 & 260
Publié le 16/06/2008 par Damien Triolet



GeForce GTX 200Avec le GT200 qui équipe les GeForce GTX 200, Nvidia s'était bien entendu fixé comme objectif de proposer un GPU plus performant. Que faire donc sur base de l'architecture GeForce 8 ? Mettre 2 G80 sur une même puce ? 256 processeurs scalaires au total, 128 unités de texturing. Simple, non ?
Ce n'est jamais aussi simple. Doubler l'existant résulte rarement en des performances doublées, d'autant plus que des inconvénients tels que la consommation et donc la chaleur dégagée peuvent devenir tels qu'ils vont pousser à réduire les fréquences à la baisse, et donc réduire le gain de performances.
Nvidia a donc tout d'abord cherché à savoir ce qui était le facteur limitant sur GeForce 8/9 et essayer d'estimer ce qui le serait à l'avenir. La conclusion en a visiblement été qu'il fallait plus de puissance de calcul et plus de registres et que les unités de texturing ne devaient pas obligatoirement croître énormément en nombre.
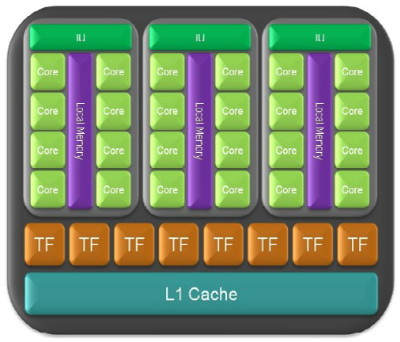
Les partitions du GT200 recoivent un multiprocesseur de plus par rapport à celles des GeForce 8 et 9, portant leur nombre à 3.
Du coup, Nvidia a ajouté un multiprocesseur par partition, qui en contiennent maintenant 3 et a doublé le nombre de registres de chaque multiprocesseur qui passe à 16384. Plus de registres veut dire que le compilateur a plus de flexibilité pour produire une suite d'instructions optimale et que le GPU peut masquer plus efficacement les divers latences, par exemple lors de l'accès aux textures. Pour rappel, le GPU jongle avec de nombreux threads (pixels, vertices etc) pour masquer la latence et les données de tous ceux-ci doivent rester dans les registres. Ensuite, Nvidia est passé de 8 partitions à 10, pour un total donc de 240 processeurs scalaires. Au niveau des registres généraux, sur l'ensemble du GPU, on passe de 131072 à 393216 x 32 bits !
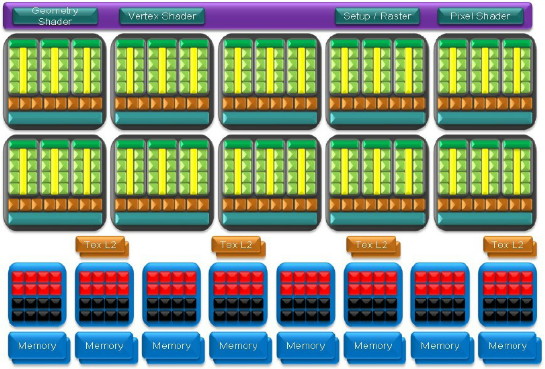
L'architecture du GT200.
Une unité supplémentaire vient prendre place dans les multiprocesseurs du GT200 : un FMAD 64 bits. Cette unité permet au GT200 de supporter la précision de calcul sur 64 bits en flottant. Etant donné qu'une seule unité est présente, le débit est 8x moindre par rapport à l'unité SIMT composée de 8 processeurs scalaires 32 bits. Qui plus est, en 64 bits, 2 registres 32 bits doivent être utilisés, ce qui limite encore un petit peu plus les performances. Ce support n'est donc pas destiné à être le plus efficace possible, mais avant tout à être là pour les développeurs qui en ont besoin avec CUDA.
Pas de changements pour les unités de texturing qui profitent simplement du passage à 10 partitions. Par contre Nvidia a indiqué avoir amélioré le scheduler et quelques autres détails de manière à maximiser l'utilisation de ces unités.
Les petits changements de cette nature sont par ailleurs nombreux. La dual issue a été améliorée et il est maintenant plus facile d'exploiter en parallèle FMADs et FMULs. Les ROPs sont maintenant capables de faire du blending à pleine vitesse sur les formats 32 bits (4x 8 bits), alors qu'ils le faisaient à demi vitesse auparavant.
Le buffer de sortie des geometry shaders a été agrandi et est maintenant 6x plus gros. Pour rappel il s'agissait d'un des points faibles des GeForce 8 et 9 qui voyaient leurs performances s'écraser lorsqu'un geometry shader était utilisé pour créer beaucoup de géométrie, par exemple en faisant de la tesselation.
Le GT200 dispose tout comme les Radeon HD 2000 et 3000 d'un processeur dédié à la gestion des transferts PCI Express, il peut donc recevoir ou envoyer des données en même temps qu'il travaille au rendu 3D ou sur un programme divers via CUDA.
Enfin le bus mémoire à été étendu à 512 bits avec 8 contrôleurs 64 bits. De quoi permettre d'alimenter le GPU avec beaucoup de bande passante, sans pour autant devoir utiliser de la mémoire très chère.
Par contre, là où Nvidia n'innove pas, c'est en se bornant à ne pas supporter DirectX 10.1. Comme nous l'avons expliqué à plusieurs reprises il y a un aspect stratégique dans ce choix qui est de ne pas dévaloriser ses autres GPUs par rapport à la concurrence. Un autre aspect est que, si Nvidia supporte certaines parties de DirectX 10.1 (telles que l'accès direct au depth buffer quand l'antialiasing est utilisé) et aide les développeurs à contourner DirectX 10 pour y accéder, d'autres points requièrent des changements plus importants. Par exemple, Nvidia ne dispose pas de grille programmable pour la position des samples en multisampling, ce qui est obligatoire pour supproter DirectX 10.1 et demanderait de revoir en profondeur la partie antialiasing de ses GPUs.
Sommaire
Vos réactions
Contenus relatifs
- [+] 04/05: Nvidia abandonne son GeForce Partne...
- [+] 27/04: AMD Vega 7nm en labo, Zen 2 échanti...
- [+] 18/04: ASUS AREZ, l'effet GeForce Partner ...
- [+] 10/04: Nvidia : fin du support Fermi et 32...
- [+] 27/03: Pilotes Radeon et GeForce pour Far ...
- [+] 20/03: Pilotes GeForce 391.24 pour Sea of ...
- [+] 20/03: Microsoft annonce DirectX Raytracin...
- [+] 20/03: Radeon Software 18.3.3 beta avec Vu...
- [+] 08/03: 3 millions de GPU vendus pour le mi...
- [+] 08/03: Radeon Software 18.3.1 optimisé pou...