
L'architecture AMD K10
Publié le 13/09/2007 par Franck Delattre



PrefetchersLe sous-système de cache du K10 bénéficie également de prefetchers hardware plus performants que celui du K8. A titre de rappel, le fonctionnement du prefetcher repose sur le principe qu'un échec de lecture en cache a de fortes probabilités de se reproduire, ce qui déclenche donc la remontée d'instructions ou de données depuis la mémoire centrale.
Le K10 possède deux prefetchers hardware qui alimentent ses caches L1, alors que ceux du K8 opèrent dans le cache L2. Le K10 bénéficie en outre d'un nouveau dispositif de prefetch dans le contrôleur mémoire qui possède un buffer de stockage dédié.
Optimisations diversesLe K10 s'efforce de corriger les quelques défauts de son prédécesseur. Le K8 souffre ainsi d'une division entière passablement lente en comparaison à l'architecture Core de son concurrent (et en particulier face à la version 45 nm qui, rappelons-le, bénéficie d'une optimisation spécifique à ce type d'opération). Le K10 corrige le tir, sans pour autant atteindre la performance de la version 45 nm du Core 2.
L'adoption de la gestion out-of-order des instructions de lecture mémoire est beaucoup plus intéressante. Présent sur le Core 2 et appelé Memory Disambiguation par Intel, ce mécanisme spéculatif a pour objectif de prédire si une instruction de lecture est susceptible de dépendre des écritures en cours ; dans le cas contraire, la lecture est traitée sans délai.
Notons également une gestion de la pile améliorée (les instructions de gestion de la pile sont désormais prises en charge par une unité dédiée), ainsi que quelques mises à niveau dans le support des instructions étendues, en particulier quelques instructions SSE3 absentes du K8 et une nouvelle série d'instructions SIMD regroupées sous la dénomination SSE4A (mais qui n'ont rien à voir avec les SSE4.1 et SSE4.2 d'Intel, ce serait trop facile).
Support amélioré de la virtualisation
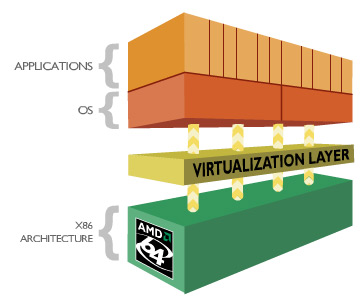
Le K10 propose une série d'optimisations visant à accélérer le traitement des machines virtuelles, citons par exemple une gestion mémoire améliorée, ou la réduction du temps de transition entre l'hyperviseur et les machines virtuelles.
Sommaire
Vos réactions
Contenus relatifs
- [+] 09/05: AMD Ryzen 7 2700, Ryzen 5 2600 et I...
- [+] 04/05: Un Coffee Lake 8 coeurs en préparat...
- [+] 27/04: Le 10nm d'Intel (encore) retardé, l...
- [+] 26/04: Jim Keller rejoint... Intel !
- [+] 23/04: MAJ de notre test des Ryzen 7 2700X...
- [+] 20/04: MAJ de notre comparatif CPU géant
- [+] 19/04: AMD Ryzen 2700X et 2600X : Les même...
- [+] 19/04: 2008-2018 : tests de 62 processeurs...
- [+] 13/04: Les AMD Ryzen Pinnacle Ridge en pré...
- [+] 10/04: LGA4189 pour les Xeon Ice Lake !