
L'architecture AMD K10
Publié le 13/09/2007 par Franck Delattre



Latences, associativité et dissipationLes latences mesurées des caches du K10 affichent 3 cycles pour le L1, 15 cycles pour le L2 et entre 30 et 45 cycles pour le L3. Ces valeurs méritent quelques éclaircissements.
La latence du L1 n'a pas changé par rapport au K8, et c'est tant mieux car elle contribue aux bonnes performances de ce dernier. La mesure de la latence du L2 est un soulagement suite à la "surprise" que nous avait réservée la version 65 nm de l'Athlon 64 (core Brisbane) dont la latence du L2 a subi une augmentation véritablement néfaste aux performances. Point de cela sur le K10 heureusement, et la latence des L2 reflète la valeur que l'on observe sur l'Athlon 64 90 nm (core Windsor).
La latence mémoire est légèrement augmentée par la présence du cache L3, dans la mesure où un accès mémoire a lieu dès lors que chacun des trois niveaux de cache n'a pas répondu positivement à la requête. Certes, cela prend un peu plus de temps pour accéder à la mémoire, mais il ne faut pas en conclure pour autant que l'ajout d'un niveau de cache ralentit les accès mémoire ! C'est même l'inverse qui se produit, car la présence du L3 diminue de façon significative le nombre d'accès à la mémoire.
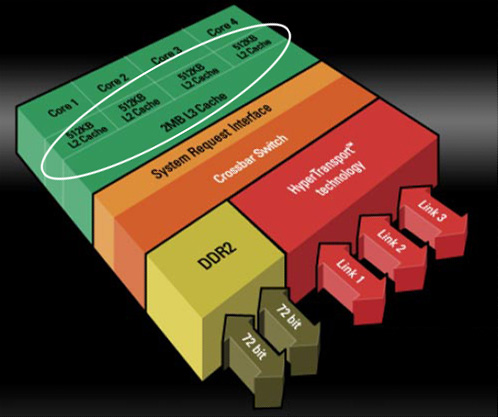
Enfin, sachez que si la latence du L3 du K10 est exprimée en cycles processeurs, cee cache est solidaire du "power plane" du contrôleur mémoire, ce qui signifie qu'il ne fonctionne pas à la fréquence du processeur mais à celle du contrôleur mémoire (soit entre 200 et 400 MHz de moins que le noyau).
Pour finir, nous pouvons supposer que la latence élevée du L3 du K10 peut refléter la volonté de réduire la dissipation thermique du cache. Pour bien comprendre le lien entre la latence et la dissipation thermique, il faut se pencher un peu sur les mécanismes régissant le cache.
Lorsqu'une donnée (ou une instruction) est lue en mémoire et écrite dans le cache, celle-ci est placée à une adresse à laquelle le contrôleur sait pouvoir la retrouver, et définie à partir de l'adresse originale de la donnée en mémoire. Le cache étant moins volumineux que la mémoire, les adresses de cache sont comprises dans une fourchette bien plus petite que les adresses mémoire, et l'adresse de cache est souvent générée à partir des premières unités de l'adresse mémoire concernée.
A titre d'exemple, si l'adresse mémoire vaut 0xF01C0123, l'adresse de cache est 0xC0123. Ainsi, les données situées aux adresses 0xF01C0123 et 0xF2C0123 partagent la même adresse de cache, et si les deux données sont mises en cache il y a conflit d'adresses. Pour régler ce conflit, un cache peut réserver non pas un emplacement pour l'adresse de cache 0xC0123, mais deux, quatre, huit .... on parle alors de cache associatif à 2, 4 ou 8 voies. De cette façon, plus l'associativité du cache est élevée, plus le risque de conflit est faible. Tout se passe comme si le cache était organisé en autant de blocs qu'il y a de voies d'associativité, et plus les blocs sont de faible taille, moins ils peuvent contenir de données ou d'instructions contigües en mémoire. Il s'agit donc de trouver le compromis idéal entre taille et associativité du cache, mais de façon générale, plus un cache est volumineux et associatif, meilleures sont les performances.
Une associativité élevée pose un problème cependant. Une requête dans le cache à partir d'une adresse déclenche la lecture de toutes les données partageant la même adresse, soit autant que le nombre de voies. Bien entendu, une seule de ces données est celle recherchée, les autres ayant été activées pour rien. Hélas, chacune de ces lectures active une partie du cache, et provoque un dégagement de chaleur. Ainsi, plus le cache est associatif, plus sa dissipation thermique est importante à chaque requête.
Comment conserver une associativité élevée tout en réduisant le dégagement de chaleur ? La solution consiste à ne plus activer toutes les voies simultanément en cas de lecture, mais seulement quelques-unes à la fois (voire une seule), jusqu'à ce la donnée recherchée soit trouvée. Cette sérialisation de la lecture se traduit par un cache économe en énergie et dissipant peu de chaleur, mais dont la latence apparente a été multipliée. Ce pourquoi la technique est utilisée principalement sur les processeurs mobiles.
Pour tout dire nous ignorons si le cache L3 du K10 utilise véritablement une associativité en série telle que celle que nous avons décrite. Cela étant, nous sommes confortés dans cette hypothèse par la latence mesurée assez élevée, eu égard à la taille du cache (les caches Intel sont deux fois plus volumineux mais affichent une latence bien inférieure), mais également par le fait que la relative lenteur du L2 du Brisbane s'explique probablement par l'emploi de la même technique.
Sommaire
1 - Rester dans la course
2 - Quatre cores, enfin
3 - Un IPC boosté
4 - Les caches du K10
5 - Les caches, suite
2 - Quatre cores, enfin
3 - Un IPC boosté
4 - Les caches du K10
5 - Les caches, suite
Vos réactions
Contenus relatifs
- [+] 09/05: AMD Ryzen 7 2700, Ryzen 5 2600 et I...
- [+] 04/05: Un Coffee Lake 8 coeurs en préparat...
- [+] 27/04: Le 10nm d'Intel (encore) retardé, l...
- [+] 26/04: Jim Keller rejoint... Intel !
- [+] 23/04: MAJ de notre test des Ryzen 7 2700X...
- [+] 20/04: MAJ de notre comparatif CPU géant
- [+] 19/04: AMD Ryzen 2700X et 2600X : Les même...
- [+] 19/04: 2008-2018 : tests de 62 processeurs...
- [+] 13/04: Les AMD Ryzen Pinnacle Ridge en pré...
- [+] 10/04: LGA4189 pour les Xeon Ice Lake !