
ATI Radeon X1800 XT & XL
Publié le 05/10/2005 par Damien Triolet et Marc Prieur



Des pixel shaders revus et corrigésATI avait indéniablement pris pas mal de retard sur les capacités en pixel shading des GPU Nvidia, ce qui est logique puisque le précédant shader core d´ATI date de plus de 3 ans, bien qu´il ait légèrement été amélioré avec les X800.
Le shader core des 9700/X800 fonctionnait d´une manière relativement fixe ce qui limitait ses capacités. Lorsqu´un thread, c´est-à-dire un groupe de pixels à traiter, arrivait dans le shader core il passait tout d´abord dans le bloc de texturing et toutes ses instructions de texturing étaient traitées et stockées dans des registres. Ensuite il passait dans le pipeline de pixel shader pour que les instructions soient exécutées, en ayant déjà les résultats du texturing en mémoire. La gestion de ces threads est pipelinée, c´est-à-dire que dès qu´un thread sort du bloc de texturing, un autre y rentre, pendant que le second passe à la suite. Ce système est intéressant au niveau des performances et est en partie responsable de la forte efficacité des Radeon 9700/X800 puisqu´il implique que le facteur limitant est soit les accès aux textures, soit les instructions mathématiques, alors que chez Nvidia c´est la somme des 2. C´est également ce qui permet à ATI d´être plus efficace sur le filtrage anisotrope puisqu´il est plus facile de masquer le temps requis par celui-ci par des instructions mathématiques que chez Nvidia qui doit essayer d´optimiser au mieux l´ordre des instructions pour y arriver mais jamais aussi efficacement.
Là où ça se complique, c´est lorsqu´une indirection est présente dans le shader. Une indirection est un accès à une texture dont la coordonnée à été calculée dynamiquement dans le pixel shader, et qui n´est donc pas connue dès le départ, ce qui est utilisé relativement souvent aujourd´hui. Etant donné que l´accès aux textures se fait avant, il n´est pas possible d´accéder directement à la texture et il faut donc mettre le thread en pause et le réenvoyer dans le bloc de texturing dès que possible. Etant donné que d´autres threads étaient déjà prêts à rentrer dans le shader core, le nombre de threads dans celui-ci va augmenter. Par exemple s´il est de 2 threads effectifs (nous précisons effectif étant donné que le nombre réel peut être plus important, mais multiple de ce nombre) en temps normal (un dans le bloc de texturing, un dans le bloc de pixel shading), il va passer à 4 avec une indirection, à 6 avec 2 indirections et à 8 avec 3 indirections, ce qui était le maximum supporté et une forte limitation.
On a souvent parlé de la limitation du nombre de registres chez Nvidia puisque seulement 2 registres FP32 existaient réellement par pixel dans les GeForce FX et 4 dans les GeForce 6 et 7, alors que chez ATI, les 12 registres requis par les Pixel Shader 2.0 étaient bel et bien présents et pas "émulés" à partir d´un nombre plus réduit. Par contre ce qui est moins connu, c´est que ces 12 registres n´étaient accessibles qu´avec 2 threads effectifs, si 4 étaient utilisés, ils devaient se partager l´espace des registres, ce qui revenait à 6 registres par pixels, et à 3 registres par pixel avec 8 threads effectifs.
L´approche de Nvidia pour éviter ces limitations au niveau des indirections et pour pouvoir offrir plus de flexibilité avec des branchements etc, a été d´utiliser un très long pipeline, de 256 cycles, dont la plupart des étages ne servent à rien si ce n´est à attendre les résultats de l´unité de texturing. Il n´y a donc pas 2 parties distinctes chez Nvidia, le tout est fusionné. Dès qu´une instruction de texturing arrive, elle est exécutée directement et son résultat est disponible un peu plus tard dans le pipeline, mais dans le même cycle effectif. Nvidia ne doit donc pas utiliser en même temps plusieurs threads pour obtenir un résultat efficace, et peut accéder à un nombre illimité de textures dépendantes d´un résultat du pixel shader, mais en contrepartie ne peut pas masquer la latence du texturing aussi bien au-dessus d´une certaine limite et doit travailler sur de gros threads, qui font 1024 pixels voir parfois plus sur les GeForce 6.La solution de Nvidia : le long pipeline
Cette approche pose problème avec les branchements dynamiques puisque dans un GPU, le flux d´instructions est géré par threads, soit par groupe de pixels et non pas par pixel. Autrement dit, chaque pixel dans un thread doit passer par le même chemin et se voir appliquer les mêmes instructions. Dans le cas où le résultat du branchement ne serait pas identique pour tous les pixels d´un thread, les 2 branches doivent être exécutées pour tous ! Dans ce cas il n´est plus possible d´utiliser le branchement dynamique pour augmenter les performances, par exemple en évitant le rendu d´une grosse partie du shader et les performances vont baisser au lieu d´augmenter.
La solution d´ATI : l´Ultra ThreadingAvec les Radeon X1000, ATI devait revoir sa copie et proposer des pixel shader sans limite d´indirections et capable de traiter des branchements. La solution retenue n´a pas été de s´orienter vers l´architecture de Nvidia mais plutôt de pousser plus loin le concept de celle des 9700/X800 en augmentant le nombre de threads. Celui-ci passe donc à un maximum de 512 dans les Radeon X1800 ce qui est nettement plus élevé qu´auparavant, bien que nous n´en connaissions pas le nombre exact.
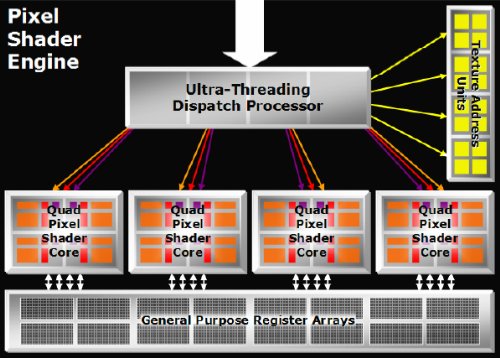
La taille des threads est très petite, 16 pixels, ce qui est très différent des 1024 pixels de Nvidia. Les Radeon X1000 supportent 32 registres réels par pixel mais ce nombre baisse d´après le nombre de threads en activité. Nous n´avons pas pu obtenir le nombre de threads maximum avec lequel les 32 registres restent accessibles mais nous l´estimons à 64 soit 1024 pixels ce qui représenterait 32768 registres généraux de 128 bits, contre 24576 dans le GeForce 7800, mais celui-ci est moins flexible dans leur utilisation et les pixels n´en ont jamais plus de 4.
Le principe de l´Ultra Threading est assez simple bien que ses implications soient, elles, très complexes. Dès qu´un thread arrive dans un des 4 shader cores (qui disposent chacun d´un bloc de 4 unités de texturing et de 4 blocs de pixel shading), il commence à être traité et les instructions mathématiques sont exécutées jusqu´à arriver à une opération qui implique de la latence, comme l´accès à une texture. Dans ce cas, le thread est envoyé au bloc de texturing, ses résultats restent dans les registres temporaires et un nouveau thread entre dans le shader core, puis dès que celui-ci arrive à l´instruction de texturing, il passe dans le bloc adapté et un nouveau thread rentre, etc., jusqu´à ce que le résultat du texturing du premier thread soit connus. A ce moment il repasse dans le bloc de pixel shading pour se voir appliquer la suite des instructions, jusqu´à ce qu´à nouveau une opération qui implique de la latence arrive. Le cycle continue jusqu´à ce que le shader soit complètement traité. A ce moment, le thread sort du shader core et un nouveau y rentre.
Autrement dit, au lieu de masquer la latence via un long pipeline comme Nvidia, ou via une architecture fixe comme auparavant, ATI utilise un nombre élevé de threads dont une grosse partie restent en veille en attendant un résultat des unités de texturing, ce qui permet de combiner les avantages des 2 architectures.
Sur le plan des branchements dynamiques, le fait qu´ATI utilise des threads très petits, lui permet d´éviter plus souvent que Nvidia de calculer les 2 branches pour tous les pixels, ce qui pourrait devenir un avantage significatif à l´avenir. Toujours à ce niveau, ATI dispose, en plus du bloc pixel shading et du bloc texturing, d´un troisième bloc en parallèle qui s´occupe des instructions de branchements qui n´ont donc pas vraiment de coût sur les performances alors qu´elles nécessitent plusieurs cycles chez Nvidia.
Là où ATI n´a pas amélioré fortement son architecture, c´est au niveau des unités de calcul puisqu´elles restent globalement identiques à celles des Radeon 9700/X800 : une grosse unité vec3 + 1 et une petite unité vec3 +1 qui traite des opérations simples comme les modifiers, alors que Nvidia dispose de 2 grosses unités et de 2 petites. Notez cependant que les grosses unités de Nvidia ne peuvent pas traiter toutes les instructions et qu´il faut donc dans certains cas que leur ordre leur corresponde pour pouvoir les utiliser en même temps. Nvidia est également capable de traiter les opérations en vec2 + vec2 bien qu´en pratique le compilateur ait du mal à utiliser cette possibilité. Et enfin, Nvidia gère nativement l´instruction NRM (normalisation) en FP16 alors qu´ATI n´a aucune unité en FP16 et utilise donc la version décomposée de l´instruction qui nécessite plusieurs cycles.
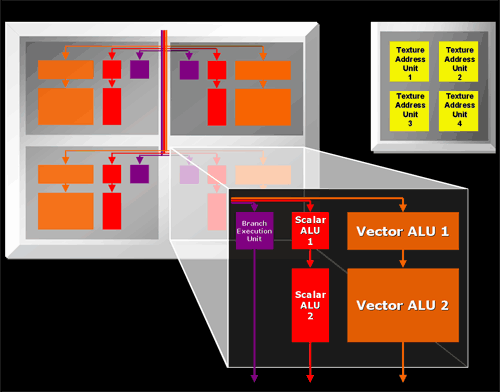
Par rapport aux 9700/X800, ATI a malgré tout fait des petites améliorations, notamment avec la gestion native de l´instruction sincos, mais globalement, Nvidia conserve un avantage au niveau de la puissance de calcul. ATI se défend à ce sujet en expliquant que son architecture permet de maximiser l´utilisation de ses unités de calcul ce qui permet de compenser.
L´architecture X1000 dispose au niveau des pixel shader d´une fonctionnalité assez innovante, appelée "scater" qui permet à n´importe quel moment d´enregistrer n´importe quelle valeur directement dans la mémoire de la carte graphique, ce qui est un pas en avant gigantesque par rapport aux accès très limité à la mémoire des autres GPUs. Ceci est rendu possible par la nouvelle architecture mémoire qui est très flexible. Grossièrement cette fonction permet de disposer d´un nombre de registres illimité et offre énormément de nouvelles possibilités lors de l´utilisation du GPU comme unité de calcul général en GPGPU. Cette fonction est cependant très en avance sur son temps et ne peut pas être utilisée à travers DirectX 9 mais, fait sans précédant dans l´industrie du GPU, ATI a déclaré avoir l´intention de publier les informations de bas niveau de ses GPU X1000 courant 2006, ce qui permettra aux développeurs sur GPGPU d´accéder à la puce sans passer par une API et donc d´en utiliser toutes les possibilités !
Sommaire
1 - L'architecture en bref
2 - Pixel shader revus et corrigés
3 - Perf Pixel Shader, Branchements, Vertex Shader
4 - Perf HDR, Texturing
5 - Filtrage et anti-crénelage
2 - Pixel shader revus et corrigés
3 - Perf Pixel Shader, Branchements, Vertex Shader
4 - Perf HDR, Texturing
5 - Filtrage et anti-crénelage
Vos réactions
Contenus relatifs
- [+] 04/05: Nvidia abandonne son GeForce Partne...
- [+] 27/04: AMD Vega 7nm en labo, Zen 2 échanti...
- [+] 18/04: ASUS AREZ, l'effet GeForce Partner ...
- [+] 10/04: Nvidia : fin du support Fermi et 32...
- [+] 27/03: Pilotes Radeon et GeForce pour Far ...
- [+] 20/03: Pilotes GeForce 391.24 pour Sea of ...
- [+] 20/03: Microsoft annonce DirectX Raytracin...
- [+] 20/03: Radeon Software 18.3.3 beta avec Vu...
- [+] 08/03: 3 millions de GPU vendus pour le mi...
- [+] 08/03: Radeon Software 18.3.1 optimisé pou...